
Ce este Robots.txt în SEO: Cum să îl creați și să îl optimizați
Publicat: 2022-04-22Subiectul de astăzi nu este direct legat de monetizarea traficului. Dar robots.txt poate afecta SEO site-ului dvs. și, eventual, cantitatea de trafic pe care o primește. Mulți administratori web au distrus clasamentul site-urilor lor din cauza intrărilor robots.txt greșite. Acest ghid vă va ajuta să evitați toate aceste capcane. Ai grijă să citești până la sfârșit!
- Ce este un fișier robots.txt?
- Cum arată un fișier robots.txt?
- Cum să vă găsiți fișierul robots.txt
- Cum funcționează un fișier Robots.txt?
- Sintaxa Robots.txt
- Directive acceptate
- Agent utilizator*
- Permite
- Nu permiteți
- Harta site-ului
- Directive neacceptate
- Întârzierea târârii
- Noindex
- Nofollow
- Aveți nevoie de un fișier robots.txt?
- Crearea unui fișier robots.txt
- Fișier Robots.txt: cele mai bune practici SEO
- Utilizați o nouă linie pentru fiecare directivă
- Utilizați metacaracterele pentru a simplifica instrucțiunile
- Utilizați semnul dolar „$” pentru a specifica sfârșitul unei adrese URL
- Utilizați fiecare user-agent o singură dată
- Utilizați instrucțiuni specifice pentru a evita erorile neintenționate
- Introduceți comentarii în fișierul robots.txt cu un hash
- Utilizați fișiere robots.txt diferite pentru fiecare subdomeniu
- Nu blocați conținutul bun
- Nu abuzați de întârzierea accesării cu crawlere
- Acordați atenție sensibilității cu majuscule și minuscule
- Alte bune practici:
- Utilizarea robots.txt pentru a preveni indexarea conținutului
- Folosind robots.txt pentru a proteja conținutul privat
- Utilizarea robots.txt pentru a ascunde conținut duplicat rău intenționat
- Acces integral pentru toți roboții
- Nu există acces pentru toți roboții
- Blocați un subdirector pentru toți roboții
- Blocați un subdirector pentru toți roboții (cu un fișier permis)
- Blocați un fișier pentru toți roboții
- Blocați un tip de fișier (PDF) pentru toți roboții
- Blocați toate adresele URL parametrizate numai pentru Googlebot
- Cum să testați fișierul robots.txt pentru erori
- Adresa URL trimisă a fost blocată de robots.txt
- Blocat de robots.txt
- Indexat, deși blocat de robots.txt
- Robots.txt vs meta roboți vs x-roboți
- Lectură în continuare
- Încheierea
Ce este un fișier robots.txt?
Robots.txt, sau protocolul de excludere a roboților, este un set de standarde web care controlează modul în care roboții motoarelor de căutare accesează cu crawlere fiecare pagină web, până la marcajele schemei de pe pagina respectivă. Este un fișier text standard care poate împiedica chiar crawlerele web să obțină acces la întregul site web sau la părți ale acestuia.
În timp ce ajustați SEO și rezolvați problemele tehnice, puteți începe să obțineți venituri pasive din reclame. O singură linie de cod pe site-ul dvs. returnează plăți regulate!
La Cuprins ↑Cum arată un fișier robots.txt?
Sintaxa este simplă: dați reguli boților specificând agentul utilizator și directivele acestora. Fișierul are următorul format de bază:
Harta site-ului: [Locația URL a hărții site-ului]
Agent utilizator: [identificator bot]
[directiva 1]
[directiva 2]
[directiva...]
User-agent: [un alt identificator de bot]
[directiva 1]
[directiva 2]
[directiva...]
Cum să vă găsiți fișierul robots.txt
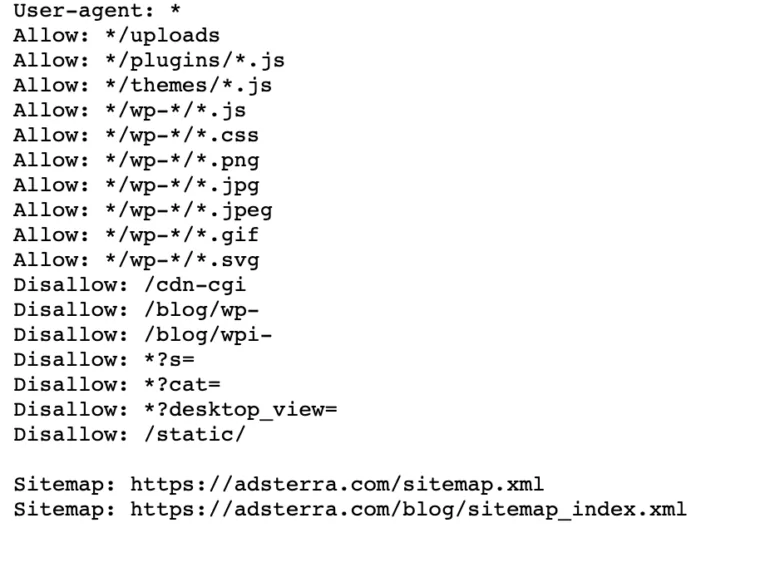
Dacă site-ul dvs. are deja un fișier robot.txt, îl puteți găsi accesând această adresă URL: https://yourdomainname.com/robots.txt în browser. De exemplu, iată fișierul nostru
Cum funcționează un fișier Robots.txt?
Un fișier robots.txt este un fișier text simplu care nu conține niciun cod de markup HTML (de unde și extensia .txt). Acest fișier, ca toate celelalte fișiere de pe site, este stocat pe serverul web. Este puțin probabil ca utilizatorii să viziteze această pagină, deoarece nu este legată de niciuna dintre paginile dvs., dar majoritatea robotilor de crawler web o caută înainte de a accesa cu crawlere întregul site.
Un fișier robots.txt poate oferi instrucțiuni roboților, dar nu poate aplica acele instrucțiuni. Un bot bun, cum ar fi un crawler web sau un bot de flux de știri, va verifica fișierul și va urma instrucțiunile înainte de a vizita orice pagină de domeniu. Dar roboții rău intenționați fie vor ignora, fie vor procesa fișierul pentru a găsi pagini web interzise.
Într-o situație în care un fișier robots.txt conține comenzi conflictuale, botul va folosi cel mai specific set de instrucțiuni.
La Cuprins ↑Sintaxa Robots.txt
Un fișier robots.txt este format din mai multe secțiuni de „directive”, fiecare începând cu un user-agent. Agentul utilizator specifică botul de accesare cu crawlere cu care comunică codul. Puteți fie să vă adresați simultan tuturor motoarelor de căutare, fie să gestionați motoarele de căutare individuale.
Ori de câte ori un bot accesează cu crawlere un site web, acesta acționează asupra părților site-ului care îl apelează.
Agent utilizator: *
Nu permite: /
Agent utilizator: Googlebot
Nu permiteți:
Agent utilizator: Bingbot
Nu permite: /not-for-bing/
Directive acceptate
Directivele sunt linii directoare pe care doriți să le urmeze agenții utilizator pe care declarați. Google acceptă în prezent următoarele directive.
Agent utilizator*
Când un program se conectează la un server web (un robot sau un browser web obișnuit), acesta trimite un antet HTTP numit „user-agent” care conține informații de bază despre identitatea sa. Fiecare motor de căutare are un user-agent. Roboții Google sunt cunoscuți ca Googlebot, Yahoo - ca Slurp și Bing - ca BingBot. Agentul utilizator inițiază o secvență de directive, care se poate aplica anumitor agenți utilizator sau tuturor agenților utilizator.
Permite
Directiva allow le spune motoarele de căutare să acceseze cu crawlere o pagină sau un subdirector, chiar și un director restricționat. De exemplu, dacă doriți ca motoarele de căutare să nu poată accesa toate postările blogului dvs., cu excepția uneia, fișierul robots.txt ar putea arăta astfel:
Agent utilizator: *
Nu permiteți: /blog
Permite: /blog/allowed-post
Cu toate acestea, motoarele de căutare pot accesa /blog/allowed-post, dar nu pot obține acces la:
/blog/other-post
/blog/yet-nother-post
/blog/download-me.pd
Nu permiteți
Directiva disallow (care este adăugată la fișierul robots.txt al unui site web) le spune motoarele de căutare să nu acceseze cu crawlere o anumită pagină. În cele mai multe cazuri, acest lucru va împiedica și o pagină să apară în rezultatele căutării.
Puteți folosi această directivă pentru a instrui motoarele de căutare să nu acceseze cu crawlere fișierele și paginile dintr-un anumit folder pe care îl ascundeți publicului larg. De exemplu, conținut la care încă lucrați, dar publicat din greșeală. Fișierul dvs. robots.txt ar putea arăta astfel dacă doriți să împiedicați toate motoarele de căutare să vă acceseze blogul:
Agent utilizator: *
Nu permiteți: /blog
Aceasta înseamnă că toate subdirectoarele din directorul /blog nu vor fi accesate cu crawlere. Acest lucru ar bloca, de asemenea, Google să acceseze adrese URL care conțin /blog.
La Cuprins ↑Harta site-ului
Sitemapurile sunt o listă de pagini pe care doriți ca motoarele de căutare să le acceseze cu crawlere și să le indexeze. Dacă utilizați directiva sitemap, motoarele de căutare vor ști locația sitemap-ului dvs. XML. Cea mai bună opțiune este să le trimiteți la instrumentele pentru webmasteri ale motoarelor de căutare, deoarece fiecare poate oferi vizitatorilor informații valoroase despre site-ul dvs.
Este important să rețineți că repetarea directivei sitemap pentru fiecare user-agent nu este necesară și nu se aplică unui singur agent de căutare. Adăugați directivele pentru sitemap la începutul sau la sfârșitul fișierului robots.txt.
Un exemplu de directivă de hartă site în fișier:
Harta site-ului: https://www.domain.com/sitemap.xml
Agent utilizator: Googlebot
Nu permiteți: /blog/
Permite: /blog/post-title/
Agent utilizator: Bingbot
Nu permiteți: /services/
La Cuprins ↑Directive neacceptate
Următoarele sunt directive pe care Google nu le mai acceptă – unele dintre ele nu au fost niciodată aprobate din punct de vedere tehnic.
Întârzierea târârii
Yahoo, Bing și Yandex răspund rapid la indexarea site-urilor web și reacționează la directiva crawl-delay, care le ține sub control pentru o perioadă.
Aplicați această linie blocului dvs.:
Agent utilizator: Bingbot
Întârziere crawler: 10
Înseamnă că motoarele de căutare pot aștepta zece secunde înainte de a accesa cu crawlere site-ul web sau zece secunde înainte de a reaccesa site-ul după accesare cu crawlere, ceea ce este același lucru, dar ușor diferit în funcție de user-agent utilizat.
Noindex
Metaeticheta noindex este o modalitate excelentă de a împiedica motoarele de căutare să indexeze una dintre paginile dvs. Eticheta permite roboților să acceseze paginile web, dar îi informează și pe roboți să nu le indexeze.
- Antet de răspuns HTTP cu etichetă noindex. Puteți implementa această etichetă în două moduri: un antet de răspuns HTTP cu o etichetă X-Robots sau o etichetă <meta> plasată în secțiunea <head>. Iată cum ar trebui să arate eticheta ta <meta>:
<meta name="roboți” content="noindex”>
- Cod de stare HTTP 404 și 410. Codurile de stare 404 și 410 indică faptul că o pagină nu mai este disponibilă. După accesarea cu crawlere și procesarea paginilor 404/410, acestea le elimină automat din indexul Google. Pentru a reduce riscul apariției paginilor de eroare 404 și 410, accesați cu crawlere site-ul în mod regulat și utilizați redirecționări 301 pentru a direcționa traficul către o pagină existentă acolo unde este necesar.
Nofollow
Nofollow direcționează motoarele de căutare să nu urmeze legăturile de pe pagini și fișiere dintr-o anumită cale. De la 1 martie 2020, Google nu mai consideră atributele nofollow drept directive. În schimb, vor fi indicii, la fel ca etichetele canonice. Dacă doriți un atribut „nofollow” pentru toate linkurile dintr-o pagină, utilizați metaeticheta robotului, antetul x-robots sau atributul link rel= „nofollow” .
Anterior, puteai folosi următoarea directivă pentru a împiedica Google să urmărească toate linkurile de pe blogul tău:
Agent utilizator: Googlebot
Nofollow: /blog/
Aveți nevoie de un fișier robots.txt?
Multe site-uri web mai puțin complexe nu au nevoie de unul. Deși Google nu indexează de obicei paginile web blocate de robots.txt, nu există nicio modalitate de a garanta că aceste pagini nu apar în rezultatele căutării. Deținerea acestui fișier vă oferă mai mult control și securitate a conținutului de pe site-ul dvs. web față de motoarele de căutare.
Fișierele Robots vă ajută, de asemenea, să realizați următoarele:
- Preveniți accesarea cu crawlere a conținutului duplicat.
- Mențineți confidențialitatea pentru diferite secțiuni ale site-ului web.
- Restricționați accesarea cu crawlere a rezultatelor căutării interne.
- Preveniți supraîncărcarea serverului.
- Preveniți risipirea „bugetului cu crawl”.
- Păstrați imaginile, videoclipurile și fișierele de resurse departe de rezultatele căutării Google.
Aceste măsuri vă afectează în cele din urmă tactica SEO. De exemplu, conținutul duplicat încurcă motoarele de căutare și le obligă să aleagă care dintre cele două pagini să se claseze pe primul loc. Indiferent de cine a creat conținutul, este posibil ca Google să nu selecteze pagina originală pentru primele rezultate ale căutării.

În cazurile în care Google detectează conținut duplicat destinat să înșele utilizatorii sau să manipuleze clasamentele, va ajusta indexarea și clasarea site-ului dvs. Ca urmare, clasarea site-ului dvs. poate avea de suferit sau poate fi eliminată în întregime din indexul Google, dispărând din rezultatele căutării.
Menținerea confidențialității pentru diferite secțiuni ale site-ului web îmbunătățește, de asemenea, securitatea site-ului dvs. și îl protejează de hackeri. Pe termen lung, aceste măsuri vor face site-ul dvs. mai sigur, mai demn de încredere și mai profitabil.
Sunteți proprietarul unui site web care dorește să profite de trafic? Cu Adsterra, veți obține venituri pasive de pe orice site!
La Cuprins ↑Crearea unui fișier robots.txt
Veți avea nevoie de un editor de text, cum ar fi Notepad.
- Creați o foaie nouă, salvați pagina goală ca „robots.txt” și începeți să tastați directive în documentul .txt gol.
- Conectați-vă la cPanel, navigați la directorul rădăcină al site-ului, căutați folderul public_html .
- Trageți fișierul în acest folder și apoi verificați dacă permisiunea fișierului este setată corect.
Puteți scrie, citi și edita fișierul în calitate de proprietar, dar terții nu au voie. Un cod de permisiune „0644” ar trebui să apară în fișier. Dacă nu, faceți clic dreapta pe fișier și alegeți „permisiunea fișierului”.
Fișier Robots.txt: cele mai bune practici SEO
Utilizați o nouă linie pentru fiecare directivă
Trebuie să declarați fiecare directivă pe o linie separată. În caz contrar, motoarele de căutare vor fi confuze.
Agent utilizator: *
Nu permiteți: /directory/
Nu permiteți: /alt-director/
Utilizați metacaracterele pentru a simplifica instrucțiunile
Puteți utiliza caractere metalice (*) pentru toți agenții de utilizator și puteți potrivi modelele URL atunci când declarați directive. Wildcard funcționează bine pentru adresele URL care au un model uniform. De exemplu, este posibil să doriți să împiedicați accesarea cu crawlere a tuturor paginilor de filtrare cu un semn de întrebare (?) în adresele lor URL.
Agent utilizator: *
Disallow: /*?
Utilizați semnul dolar „$” pentru a specifica sfârșitul unei adrese URL
Motoarele de căutare nu pot accesa adrese URL care se termină în extensii precum .pdf. Aceasta înseamnă că nu vor putea accesa /file.pdf, dar vor putea accesa /file.pdf?id=68937586, care nu se termină în „.pdf”. De exemplu, dacă doriți să împiedicați motoarele de căutare să acceseze toate fișierele PDF de pe site-ul dvs. web, fișierul dvs. robots.txt ar putea arăta astfel:
Agent utilizator: *
Nu permiteți: /*.pdf$
Utilizați fiecare user-agent o singură dată
În Google, nu contează dacă utilizați același user-agent de mai multe ori. Pur și simplu va compila toate regulile din diferitele declarații într-o singură directivă și o va urma. Cu toate acestea, declararea fiecărui user-agent o singură dată are sens, deoarece este mai puțin confuză.
Menținerea ordonată și simplă a directivelor reduce riscul erorilor critice. De exemplu, dacă fișierul dvs. robots.txt conține următorii agenți de utilizator și directive.
Agent utilizator: Googlebot
Nu permiteți: /a/
Agent utilizator: Googlebot
Nu permiteți: /b/
Utilizați instrucțiuni specifice pentru a evita erorile neintenționate
Când setați directive, lipsa de a furniza instrucțiuni specifice poate crea erori care vă pot afecta SEO. Să presupunem că aveți un site multilingv și că lucrați la o versiune în germană pentru subdirectorul /de/.
Nu doriți ca motoarele de căutare să-l poată accesa deoarece nu este încă gata. Următorul fișier robots.txt va împiedica motoarele de căutare să indexeze acel subdosar și conținutul acestuia:
Agent utilizator: *
Nu permite: /de
Cu toate acestea, va restricționa motoarele de căutare să acceseze cu crawlere orice pagini sau fișiere care încep cu /de. În acest caz, adăugarea unei bare oblice este soluția simplă.
Agent utilizator: *
Nu permiteți: /de/
La Cuprins ↑Introduceți comentarii în fișierul robots.txt cu un hash
Comentariile ajută dezvoltatorii și, eventual, chiar și pe dvs. să înțelegeți fișierul robots.txt. Începeți linia cu un hash (#) pentru a include un comentariu. Crawlerele ignoră liniile care încep cu un hash.
# Acest lucru îi indică botului Bing să nu acceseze cu crawlere site-ul nostru.
Agent utilizator: Bingbot
Nu permite: /
Utilizați fișiere robots.txt diferite pentru fiecare subdomeniu
Robots.txt afectează numai accesarea cu crawlere pe domeniul său gazdă. Veți avea nevoie de un alt fișier pentru a restricționa accesarea cu crawlere pe un alt subdomeniu. De exemplu, dacă vă găzduiți site-ul web principal pe example.com și blogul pe blog.example.com, veți avea nevoie de două fișiere robots.txt. Plasați unul în directorul rădăcină al domeniului principal, în timp ce celălalt fișier ar trebui să fie în directorul rădăcină al blogului.
Nu blocați conținutul bun
Nu utilizați un fișier robots.txt sau o etichetă noindex pentru a bloca orice conținut de calitate pe care doriți să îl faceți public pentru a evita efectele negative asupra rezultatelor SEO. Verificați cu atenție etichetele noindex și interziceți regulile de pe paginile dvs.
Nu abuzați de întârzierea accesării cu crawlere
Am explicat întârzierea accesării cu crawlere, dar nu ar trebui să o utilizați frecvent, deoarece limitează roboții să acceseze cu crawlere toate paginile. Poate funcționa pentru unele site-uri web, dar s-ar putea să vă afectați clasamentele și traficul dacă aveți un site web mare.
Acordați atenție sensibilității cu majuscule și minuscule
Fișierul Robots.txt face distincție între majuscule și minuscule, așa că trebuie să vă asigurați că creați un fișier robots în formatul corect. Fișierul roboți ar trebui să fie numit „robots.txt” cu toate literele mici. Altfel, nu va funcționa.
Alte bune practici:
- Asigurați-vă că nu blocați accesul cu crawlere a conținutului sau a secțiunilor site-ului dvs.
- Nu utilizați robots.txt pentru a păstra datele sensibile (informații private despre utilizator) din rezultatele SERP. Utilizați o metodă diferită, cum ar fi criptarea datelor sau directiva meta noindex , pentru a restricționa accesul dacă alte pagini leagă direct la pagina privată.
- Unele motoare de căutare au mai mult de un user-agent. Google, de exemplu, folosește Googlebot pentru căutări organice și Googlebot-Image pentru imagini. Specificarea directivelor pentru crawlerele multiple ale fiecărui motor de căutare nu este necesară deoarece majoritatea agenților utilizatori din același motor de căutare urmează aceleași reguli.
- Un motor de căutare memorează în cache conținutul robots.txt, dar îl actualizează zilnic. Dacă modificați fișierul și doriți să îl actualizați mai repede, puteți trimite adresa URL a fișierului la Google.
Utilizarea robots.txt pentru a preveni indexarea conținutului
Dezactivarea unei pagini este cea mai eficientă modalitate de a împiedica roboții să o acceseze direct cu crawlere. Cu toate acestea, nu va funcționa în următoarele situații:
- Dacă o altă sursă are link-uri către pagină, roboții vor continua să acceseze cu crawlere și să o indexeze.
- Boții nelegitimi vor continua să acceseze cu crawlere și să indexeze conținutul.
Folosind robots.txt pentru a proteja conținutul privat
Unele conținuturi private, cum ar fi PDF-urile sau paginile de mulțumire, pot fi în continuare indexabile chiar dacă blocați roboții. Plasarea tuturor paginilor dvs. exclusive în spatele unei autentificări este una dintre cele mai bune modalități de a consolida directiva de respingere. Conținutul tău va rămâne disponibil, dar vizitatorii tăi vor face un pas suplimentar pentru a-l accesa.
Utilizarea robots.txt pentru a ascunde conținut duplicat rău intenționat
Conținutul duplicat este fie identic, fie foarte asemănător cu alt conținut în aceeași limbă. Google încearcă să indexeze și să arate pagini cu conținut unic. De exemplu, dacă site-ul dvs. are versiuni „obișnuite” și „de imprimantă” ale fiecărui articol și o etichetă noindex nu blochează niciunul, ei vor enumera una dintre ele.
Exemple de fișiere robots.txt
Următoarele sunt câteva exemple de fișiere robots.txt. Acestea sunt în primul rând pentru idei, dar dacă una dintre ele vă satisface nevoile, copiați și inserați-l într-un document text, salvați-l ca „robots.txt” și încărcați-l în directorul corespunzător.
Acces integral pentru toți roboții
Există mai multe moduri de a le spune motoarelor de căutare să acceseze toate fișierele, inclusiv dacă aveți un fișier robots.txt gol sau niciunul.
Agent utilizator: *
Nu permiteți:
Nu există acces pentru toți roboții
Următorul fișier robots.txt instruiește toate motoarele de căutare să evite accesarea întregului site:
Agent utilizator: *
Nu permite: /
Blocați un subdirector pentru toți roboții
Agent utilizator: *
Nu permiteți: /folder/
Blocați un subdirector pentru toți roboții (cu un fișier permis)
Agent utilizator: *
Nu permiteți: /folder/
Permite: /folder/page.html
Blocați un fișier pentru toți roboții
Agent utilizator: *
Nu permiteți: /this-is-a-file.pdf
Blocați un tip de fișier (PDF) pentru toți roboții
Agent utilizator: *
Nu permiteți: /*.pdf$
Blocați toate adresele URL parametrizate numai pentru Googlebot
Agent utilizator: Googlebot
Disallow: /*?
Cum să testați fișierul robots.txt pentru erori
Greșelile din Robots.txt pot fi grave, așa că este important să le monitorizați. Verificați periodic raportul „Acoperire” din Search Console pentru probleme legate de robot.txt. Unele dintre erorile pe care le puteți întâlni, ce înseamnă acestea și cum să le remediați sunt enumerate mai jos.
Adresa URL trimisă a fost blocată de robots.txt
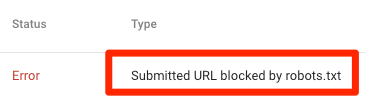
Indică faptul că robots.txt a blocat cel puțin una dintre adresele URL din sitemap-urile dvs. Dacă harta dvs. de site este corectă și nu include pagini canonizate, neindexate sau redirecționate, atunci robots.txt nu ar trebui să blocheze nicio pagină pe care o trimiteți. Dacă sunt, identificați paginile afectate și eliminați blocul din fișierul robots.txt.
Puteți utiliza testerul robots.txt de la Google pentru a identifica directiva de blocare. Fiți atenți când editați fișierul robots.txt, deoarece o greșeală poate afecta alte pagini sau fișiere.
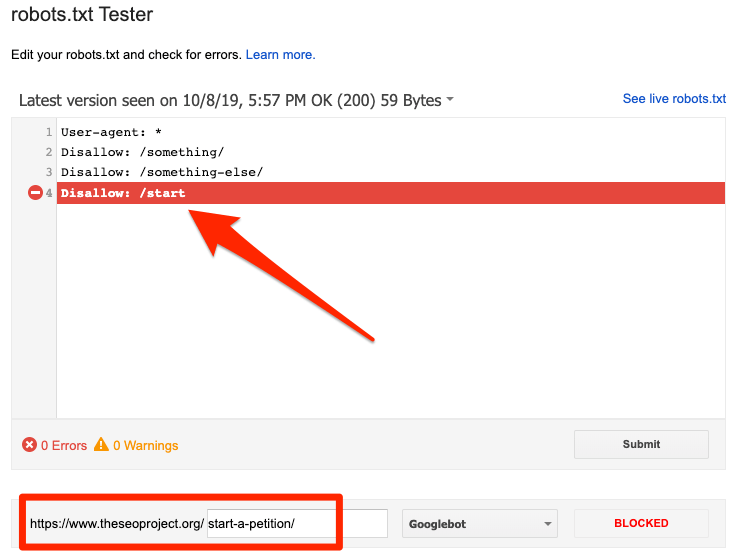
Blocat de robots.txt
Această eroare indică faptul că robots.txt a blocat conținut pe care Google nu îl poate indexa. Eliminați blocul de accesare cu crawlere din robots.txt dacă acest conținut este crucial și ar trebui indexat. (De asemenea, verificați dacă conținutul nu este indexat.)
Dacă doriți să excludeți conținut din indexul Google, utilizați metaeticheta robotului sau x-robots-header și eliminați blocul de accesare cu crawlere. Acesta este singurul mod de a păstra conținutul în afara indexului Google.
Indexat, deși blocat de robots.txt
Înseamnă că Google încă indexează o parte din conținutul blocat de robots.txt. Robots.txt nu este soluția pentru a împiedica afișarea conținutului dvs. în rezultatele căutării Google.
Pentru a preveni indexarea, eliminați blocul de accesare cu crawlere și înlocuiți-l cu o etichetă meta robots sau un antet HTTP x-robots-tag. Dacă ați blocat din greșeală acest conținut și doriți ca Google să-l indexeze, eliminați blocarea accesării cu crawlere din robots.txt. Poate ajuta la îmbunătățirea vizibilității conținutului în căutările Google.
Robots.txt vs meta roboți vs x-roboți
Ce diferențiază aceste trei comenzi de robot? Robots.txt este un fișier text simplu, în timp ce meta și x-roboții sunt meta directive. Dincolo de rolurile lor fundamentale, cele trei au funcții distincte. Robots.txt specifică comportamentul de accesare cu crawlere pentru întregul site web sau director, în timp ce meta și x-roboții definesc comportamentul de indexare pentru paginile individuale (sau elementele paginii).
Lectură în continuare
Resurse utile
- Wikipedia: Protocolul de excludere a roboților
- Documentația Google pe Robots.txt
- Documentația Bing (și Yahoo) pe Robots.txt
- Directivele explicate
- Documentația Yandex pe Robots.txt
Încheierea
Sperăm că ați înțeles pe deplin importanța fișierului robot.txt și contribuțiile acestuia la practica dvs. generală de SEO și profitabilitatea site-ului. Dacă încă vă lupți să obțineți venituri de pe site-ul dvs. web, nu veți avea nevoie de codare pentru a începe să câștigați cu reclamele Adsterra. Puneți un cod de anunț pe site-ul dvs. HTML, WordPress sau Blogger și începeți să obțineți profit astăzi!