
Ce tehnologie folosesc motoarele de căutare pentru a accesa cu crawlere site-urile web?
Publicat: 2023-03-02
Dacă v-ați întrebat vreodată ce tehnologie folosesc motoarele de căutare pentru a accesa cu crawlere site-urile web, atunci pregătiți-vă să primiți în sfârșit răspunsul la întrebările dvs. Veți afla ce este un crawler web, multe tipuri diferite de crawler-uri web utilizate de motoarele de căutare majore și despre ce este vorba despre procesul de indexare a căutării. Veți afla, de asemenea, cum toate acestea vor afecta rezultatele motoarelor de căutare și cum proprietarii de site-uri web le pot spune crawlerilor web ale motorului de căutare să indexeze conținutul în funcție de dorințele lor. Să aflăm mai multe despre această tehnologie pe care motoarele de căutare o folosesc pentru a furniza cu precizie miliarde de rezultate relevante de căutare persoanelor care caută informații pe World Wide Web.
Ce sunt crawlerele web sau roboții pentru motoarele de căutare?
Roboții web crawler cunoscuți și sub numele de păianjeni sunt programe automate pe care companii precum Google și Microsoft le folosesc pentru a-și învăța motoarele de căutare ce este prezent pe fiecare pagină web accesibilă a fiecărui site web pe care îl pot găsi pe internet. Doar prin învățarea informațiilor incluse pe o pagină web, aceste motoare de căutare pot prelua cu acuratețe aceste informații atunci când unul dintre utilizatorii lor tastează o interogare de căutare solicitând să știe despre un anumit subiect.
Tipurile de roboti cu crawler web
Fiecare motor de căutare are crawlerele sale web. Iată câteva dintre cele mai utilizate pe scară largă.
GoogleBot
Google este cel mai popular motor de căutare de pe planetă și folosește două versiuni de crawler-uri web pentru a indexa sute de miliarde de pagini web. GoogleBot Desktop va analiza pagini care imită comportamentul cuiva care utilizează un computer desktop pentru a naviga pe internet, în timp ce GoogleBot Mobile va face același lucru pentru utilizatorii de smartphone.
GoogleBot este unul dintre cele mai eficiente tipuri de roboți de căutare create vreodată și poate accesa rapid cu crawlere și indexa paginile web. Cu toate acestea, are unele probleme la accesarea cu crawlere a structurilor site-urilor web foarte complexe. În plus, GoogleBot poate dura adesea multe zile sau săptămâni pentru a accesa cu crawlere o pagină web care este recent publicată, ceea ce înseamnă că nu va apărea în rezultatele relevante pentru o perioadă.
Bingbot
Bingbot este răspunsul Microsoft la Google pe propriul motor de căutare Bing. Acest lucru funcționează similar cu crawler-ul web de la Google și include chiar și un instrument de preluare care indică modul în care bot-ul va accesa cu crawlere o pagină, permițându-vă să vedeți dacă există probleme aici.
Slurp Bot
Slurp Bot este crawler-ul web folosit de Yahoo, deși folosesc și Bingbot pentru a oferi rezultate ale motorului de căutare. Proprietarul site-ului trebuie să permită accesul Slurp Bot dacă dorește ca conținutul paginii lor web să apară în rezultatele căutării Yahoo Mobile. În plus, Slurp Bot poate accesa și site-urile partenere Yahoo pentru a adăuga conținut pe site-urile lor Yahoo News, Yahoo Sports și Yahoo Finance.
DuckDuckBot
Acesta este crawler-ul web folosit de DuckDuckGo, un motor de căutare cunoscut pentru că oferă un nivel inegalabil de confidențialitate pentru utilizatorii săi, prin faptul că nu le urmărește activitatea așa cum o fac mulți dintre cei populari. Ei furnizează rezultate de căutare obținute din DuckDuckBot-ul lor, precum și site-uri web aglomerate, cum ar fi Wikipedia și alte motoare de căutare.
Baiduspider și Yandex Bot
Aceștia sunt roboții cu crawler folosiți de motoarele de căutare Baidu din China și, respectiv, Yandex din Rusia. Baidu deține o cotă de peste 80% din piața motoarelor de căutare din China continentală.
Cum funcționează crawlingul web, indexarea căutării și clasarea în motoarele de căutare
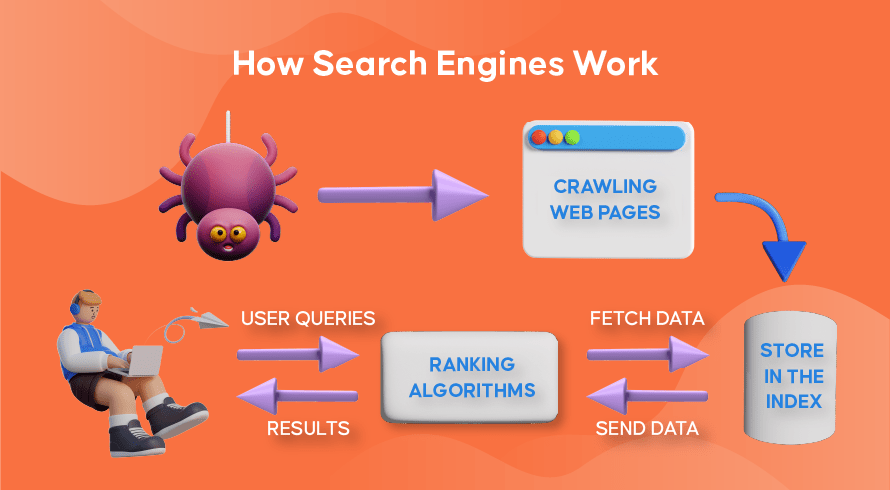
Acum haideți să explorăm modul în care majoritatea motoarelor de căutare folosesc crawlerele web pentru a găsi, stoca, organiza și prelua informațiile conținute de site-uri web.
Cum funcționează crawlerele web
Procesul de a găsi atât conținut nou, cât și actualizat pe site-uri web se numește „web crawling”, de unde și numele programelor software care îndeplinesc această funcție. Boții vor începe mai întâi să acceseze cu crawlere câteva pagini web, să îi găsească conținutul și apoi să urmeze hyperlinkurile incluse pe pagina respectivă pentru a descoperi noi adrese URL, ceea ce va duce la și mai mult conținut.
Cum funcționează indexarea motorului de căutare
După ce roboții descoperă conținut nou sau actualizat prin accesarea cu crawlere pe web, tot ceea ce găsesc este adăugat la o bază de date masivă numită „index al motorului de căutare”. Aceasta este ca o bibliotecă în care cărțile sunt ca niște pagini web, organizate pentru a fi recuperate mai târziu. Conținând în fiecare carte cea mai mare parte a textului conținut pe o pagină web, putem vedea (cu excepția cuvintelor precum „a”, „an” și „the”), precum și metadatele pe care le văd doar crawlerele. Metadatele sunt ceea ce motoarele de căutare folosesc pentru a înțelege conținutul unei pagini web. Meta-titlul și meta-descrierea sunt exemple de metadate.
Cum funcționează clasamentul de căutare
Ori de câte ori un utilizator introduce o interogare de căutare, motorul de căutare respectiv își va verifica indexul, va găsi cele mai relevante informații care se potrivește cu această solicitare, va organiza lista de link-uri web care conțin conținutul relevant și îl va prezenta utilizatorului în motorul de căutare. pagini de rezultate (SERP-uri).
Această organizare a SERP-urilor se numește „clasare de căutare” și este realizată de un algoritm de căutare care ia în considerare datele colectate inclusiv metadatele, credibilitatea site-ului web (autoritatea), precum și cuvintele cheie și linkurile. Site-urile care sunt considerate a fi surse foarte credibile și care conțin conținut extrem de relevant care va fi util utilizatorilor se vor clasa foarte bine, primind cele mai bune rezultate pe SERP-uri. De aceea, fiecare proprietar de site-uri web are strategii pentru a-și clasa site-ul pe SERP-uri.
Cum intră în imagine Optimizarea pentru motoarele de căutare (SEO).
Proprietarii de site-uri web pot optimiza conținutul paginilor lor astfel încât motoarele de căutare să le recunoască mai ușor ca fiind relevante și utile pentru utilizatorii lor. Acest lucru va împinge aceste pagini în partea de sus a SERP-urilor, aducând mai mult trafic organic pe site. Includerea strategică a cuvintelor cheie relevante în copierea paginii, crearea de linkuri și utilizarea imaginilor și videoclipurilor originale sunt câteva dintre modalitățile prin care tehnicile SEO pot fi utilizate.
În plus, site-urile web pot folosi, de asemenea, diverse instrumente, cum ar fi SEMrush, pentru a găsi și a remedia diverse probleme de pe paginile lor, cum ar fi link-uri întrerupte, ceea ce le va îmbunătăți și mai mult clasarea în ochii motoarelor de căutare.

Spuneți motoarelor de căutare cum să vă acceseze cu crawlere site-ul web

Uneori veți descoperi că crawlerele web nu și-au îndeplinit în mod adecvat funcția, ceea ce face ca pagini importante ale site-ului dvs. să lipsească din index. Aceasta înseamnă că interogările de căutare relevante nu vor fi prezentate împreună cu conținutul dvs., ceea ce face dificil pentru clienții potențiali să-și găsească drumul către paginile dvs. Din fericire, există modalități de a comunica cu motoarele de căutare, permițându-vă un pic de control asupra a ceea ce este indexat și a ceea ce este ignorat.
Fișierul robots.txt stocat în directorul rădăcină al site-ului dvs. web este cel care le spune crawlerilor web ce pagini doriți să fie accesate cu crawlere, pe care să le ignorați și cum este aranjată arhitectura site-ului dvs. Poate doriți să împiedicați indexarea anumitor pagini dacă sunt folosite pentru testare sau promoții speciale și adrese URL duplicat utilizate în comerțul electronic.
GoogleBot, de exemplu, va continua să acceseze cu crawlere un site web în întregime dacă nu există niciun fișier robots.txt prezent. Când detectează fișierul dvs. robots.txt, GoogleBot va urma instrucțiunile dvs. în timpul accesării cu crawlere. Dacă întâmpină probleme la detectarea fișierului sau întâmpină o eroare, este posibil să nu acceseze cu crawlere site-ul dvs. Trebuie să utilizați corect fișierul robots.txt, să vă organizați arhitectura site-ului și să utilizați cele mai bune practici SEO pe pagină pentru a evita orice probleme legate de accesarea cu crawlere. Puteți efectua un audit al site-ului web pentru a analiza și a identifica orice probleme care afectează site-ul dvs.
Aveți nevoie de servicii SEO pentru site-ul dvs.?
Dacă sunteți în căutarea unui furnizor de servicii care să înțeleagă cum funcționează crawlerele web și indexarea căutării pentru a îmbunătăți clasamentul site-ului dvs., atunci Inquivix este partenerul SEO pe care l-ați căutat. Oferim un set cuprinzător de servicii SEO on-page, de la crearea de conținut, la optimizarea arhitecturii site-ului și analiza performanței site-ului, pentru a îmbunătăți în continuare calitatea experienței site-ului dvs. Pentru a afla mai multe, vizitați astăzi Inquivix On-Page SEO Services!
Întrebări frecvente
Motoarele de căutare folosesc programe numite „crawler-uri web”, cunoscute și sub denumirea de „păianjeni” sau „boți” pentru a descoperi atât conținut nou, cât și actualizat pe paginile unui site web. Apoi va urma linkurile incluse în pagină pentru a găsi mai multe pagini. Conținutul găsit pe o pagină este salvat într-un index care este utilizat pentru a prelua informații pentru rezultatele căutării atunci când un utilizator o solicită.
GoogleBot Desktop și GoogleBot Mobile sunt cele mai populare crawler-uri web din majoritatea țărilor, urmate de Bingbot, Slurp Bot și DuckDuckBot. Baiduspider este folosit în principal în China, în timp ce Yandex Bot este folosit în Rusia.