
Как разработать эффективный процесс анализа данных B2C
Опубликовано: 2022-10-28Продуктивный процесс анализа данных позволяет маркетинговым командам правильно измерять свою эффективность, как текущую, так и историческую, а также делать надежные прогнозы и соответствующим образом оптимизировать стратегии.
Это стало ключевым фактором успеха ведущих брендов B2C, таких как Amazon, Netflix и Walmart. Поскольку потребители продолжают изучать цифровые возможности для удовлетворения своих повседневных потребностей, руководители B2C-маркетинга во всех отраслях признают важность анализа данных для обеспечения качественного обслуживания клиентов и повышения рентабельности инвестиций.
В этом руководстве мы обсудим важность настройки аналитики данных, а также проведем вас через процесс ее разработки и внедрения в вашей компании.
Рост сложности пути клиента
Необходимость в комплексной настройке анализа данных возникает из-за постоянно растущей сложности пути клиента и ожиданий клиентов в отношении персонализированного опыта.
На самом деле, 71% клиентов считают персонализированное взаимодействие стандартным, а 76% расстраиваются, когда не получают его. Согласно исследованию Gartner, бренды, которые терпят неудачу в персонализации, рискуют потерять 38% своих клиентов. Давайте разобьем его дальше.

В США и многих частях Европы в среднем домохозяйство имеет доступ как минимум к 7 подключенным устройствам, многие из которых можно использовать для взаимодействия с брендами через поиск, электронную почту и социальные сети. Хотя это дает компаниям B2C возможность привлечь больше клиентов, это также делает маркетинг и продажи более трудоемкими и сложными.
От этапа обнаружения до конверсии клиент проходит долгий путь, обычно достигая в среднем восьми точек взаимодействия. Представьте, 92% покупателей посещают интернет-магазины без первоначального намерения совершить покупку. На самом деле, 25% этих клиентов заходят, чтобы сравнить цены и характеристики конкурентов, а 45% посещают, чтобы узнать больше о конкретных продуктах и услугах. Маркетинговая деятельность продолжается даже за пределами интернет-магазина — в социальных сетях, сайтах сравнения, поисковых системах и других платформах. Даже после совершения покупки путешествие клиента продолжается, и эти люди жаждут персонализированных рекомендаций и предложений.
Тем не менее, маркетинг для клиентов через несколько точек взаимодействия требует и генерирует огромные объемы данных. Эти данные содержат информацию о поведении потребителей на разных этапах пути к конверсии, их уникальных потребностях и способах создания персонализированных предложений, которые, скорее всего, им понравятся.
Обработка больших объемов данных из нескольких источников может быть трудоемкой, дорогостоящей и подверженной ошибкам. Компании часто получают разрозненные и некачественные данные, что снижает качество обслуживания, которое они предоставляют своим клиентам. Это, в свою очередь, приводит к потере около 4,7 трлн долларов в глобальных потребительских продажах.
Чтобы разорвать порочный круг, компаниям необходимо использовать современные технологии и методы управления данными.
Операции, управляемые данными: доступность данных и чистые данные
На вебинаре InfoTrust и Forrester старший аналитик Ричард Джойс сказал: «Всего лишь 10-процентное увеличение доступности данных принесет более 65 миллионов долларов дополнительной чистой прибыли для типичной компании из списка Fortune 1000».
Доступность данных заключается в том, чтобы сделать данные доступными для использования внутри организации. Это означает, что люди из разных отделов и с разным опытом обработки данных знают, где и как они могут получить доступ или запросить данные и получить их в пригодном для использования состоянии.
Доступность чистых данных — один из основных аспектов компании B2C, ориентированной на данные. Это позволяет отделам, взаимодействующим с клиентами, получать критически важную информацию, что приводит к более высоким конверсиям и увеличению чистой прибыли, как указано выше. Многие преимущества доступности данных также включают следующее.
Улучшенное принятие решений
Когда данные доступны и могут использоваться руководителями из различных отделов, каждому руководителю легче понять общую эффективность бизнеса компании и то, как деятельность их команды способствует достижению конечной цели.
Эта информация имеет решающее значение для того, чтобы помочь им принимать решения и реализовывать стратегии, которые приносят положительные результаты, приближая компанию к ее целям. Важно подчеркнуть, что никогда нельзя игнорировать качество данных, используемых при принятии решений.
По данным Gartner, компании теряют в среднем 15 миллионов долларов в год из-за решений, основанных на некачественных данных.
Узнайте, как измерять и улучшать качество данных
Улучшенное качество данных
Разрозненные хранилища являются основной причиной некачественных данных в компаниях. Когда данные разбросаны по разным отделам, неизбежно возникновение дубликатов и несоответствий, и становится сложно построить целостное представление о клиентах, партнерах и продуктах компании. По данным Массачусетского технологического института, некачественные данные могут привести к тому, что компания потеряет от 15% до 25% своего дохода.
Однако когда данные становятся доступными, ситуация меняется. Команды получают более актуальные данные, устраняются дубликаты и несогласованная информация, создаются более точные аналитические данные, и компания получает больше прибыли.
Более эффективное распределение бюджета
Когда у вас есть доступ к правильно организованным данным, становится возможным определить каналы и стратегии, дающие наилучшие результаты. Зная это, вы сможете обосновать каждый расход и выделить больше бюджета на высокоэффективные области.
Лучшее качество обслуживания клиентов
Перекрестное опыление потребительских данных между командами, работающими с клиентами, позволяет различным отделам получать более глубокое представление о поведении клиентов и их уникальных потребностях на каждом этапе их пути. Это играет важную роль в создании контента для поддержки продаж, создании персонализированных предложений и установлении лучших отношений с клиентами.

Разработка процесса анализа данных для компаний B2C
Аналитика данных включает шесть основных этапов, широко называемых жизненным циклом аналитики данных.
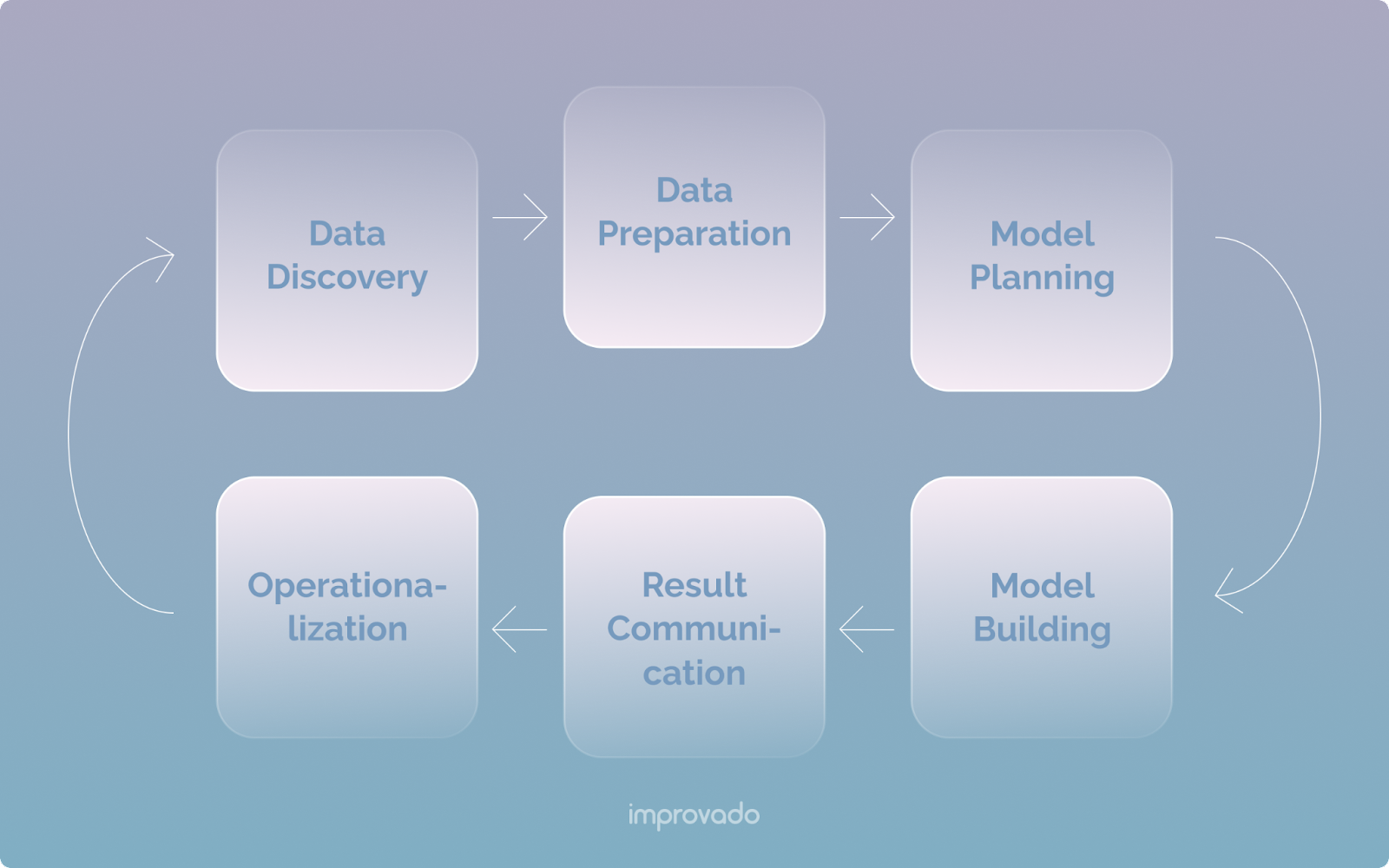
В этом разделе будет обсуждаться, как построить процесс аналитики B2C, используя различные этапы жизненного цикла аналитики данных.
Открытие и подготовка
Этап обнаружения больше фокусируется на потребностях вашего бизнеса, чем на самих данных. Здесь вам нужно будет установить четкие цели для вашей команды и разработать стратегию их достижения. Вам нужно будет изучить тенденции в вашей отрасли и провести оценку доступных ресурсов и требований к технологиям.
После этого вы определите, каковы источники данных вашей компании и какую историю вы хотите, чтобы ваши данные рассказали. Эти данные обычно проходят проверку гипотез, в ходе которой вы решаете свои бизнес-потребности на основе текущих рыночных сценариев.
После этапа открытия следует этап подготовки. Здесь акцент смещается с бизнес-целей на требования к данным. Подготовка данных включает сбор, обработку и очистку бизнес-данных, поступающих из внутренних и внешних источников. Собранные данные могут быть структурированными (с определенными шаблонами), полуструктурированными или неструктурированными.
Как бренд B2C, ваши источники данных могут включать Amazon Advertising, Facebook Ads и Shopify.
Планирование и построение модели
Теперь, когда вы получили необходимые данные, следующим шагом будет их загрузка и преобразование. Вот что такое фаза планирования модели.
Существует несколько методов, которые можно использовать для загрузки данных в изолированную программную среду аналитики. Два основных типа:
- Извлечение, преобразование и загрузка (ETL): эта процедура извлекает и преобразует данные с использованием предопределенных бизнес-правил перед их загрузкой в песочницу.
- Извлечение, загрузка и преобразование (ELT): здесь вы загружаете необработанные данные в песочницу и затем преобразуете данные.
Прочтите наше руководство для начинающих по процессам ETL
На этом этапе грязные данные могут быть либо отфильтрованы, либо полностью удалены. Другие методы, которые вы можете использовать, включают агрегацию данных, интеграцию и очистку.
Фаза построения включает в себя разработку наборов данных для обучения и производственных целей. Здесь вы будете полагаться на такие методы, как деревья решений, логистическая регрессия и нейронные сети. На этом этапе также выполняется выполнение разработанной модели, а характер среды выполнения определяется и подготавливается, чтобы ее было легче расширять, если требуется более надежная среда.
Сообщение о результатах
Этот этап включает в себя доведение результатов выполнения вашей модели до сведения заинтересованных сторон внутри компании. Заинтересованные стороны тщательно изучат ваш отчет, чтобы определить, соответствует ли он бизнес-критериям, указанным на этапе обнаружения. Это включает в себя выявление критических результатов анализа, измерение бизнес-целей, связанных с результатами, и создание удобоваримой сводки для заинтересованных сторон компании.
Операционализация
Этот этап включает перемещение данных из песочницы и реализацию модели в реальной среде. Данные постоянно отслеживаются и анализируются, чтобы гарантировать, что сгенерированные модели возвращают ожидаемые результаты. Вы всегда можете вернуться, чтобы внести коррективы, если результаты не соответствуют ожиданиям.
Автоматизация анализа данных с помощью Improvado
Ручное построение конвейеров данных и управление ими может быть трудоемким, ресурсоемким и подверженным ошибкам процессом, особенно для компаний корпоративного уровня с петабайтами данных.
В среднем дата-инженеры в компаниях корпоративного уровня тратят 40% своего рабочего дня на исправление неверных данных и неработающих конвейеров данных.
Подверженный ошибкам характер ручного ETL усугубляется медленным темпом, с которым инженеры данных обнаруживают инциденты в конвейере. По словам Уэйкфилда, инженерам требуется в среднем четыре часа на обнаружение ошибок и около девяти часов на их исправление.
Это приводит к частому появлению неверных данных, что, в свою очередь, влияет на 26% доходов этих компаний. Чтобы обуздать угрозу неверных данных, компаниям необходимо использовать автоматизированные платформы ETL, такие как Improvado.
Improvado — это платформа данных о доходах, которая автоматизирует омниканальную маркетинговую аналитику и отчетность в масштабе. Платформа автоматизирует важнейшие области жизненного цикла аналитики данных вашей компании (объединение, преобразование и очистка), доставляя чистые, готовые к анализу данные в нужное вам хранилище, BI, аналитику или инструмент визуализации.
Это экономит до 90 % времени на составление отчетов, дает вам больший контроль над данными вашей компании и, в конечном счете, повышает рентабельность инвестиций.
Опередить кривую
Поскольку потребительский ландшафт с каждым днем становится все более сложным, организации, работающие на данных, продолжают оставаться на шаг впереди, усиливая свой аналитический стек с помощью автоматизированных многоканальных платформ для получения доходов и оставляя позади ручной ETL.
Это позволяет им централизовать существующие данные, масштабировать их с помощью новых источников данных и сосредоточиться на раскрытии важных идей, ориентированных на рост.
Если вы хотите узнать больше о том, как Improvado может помочь создать надежный и масштабируемый процесс анализа данных для вашей компании, не стесняйтесь обращаться к нам. Будем рады помочь!