
Динамический парсинг веб-страниц с помощью Python – практическое руководство
Опубликовано: 2024-06-08Динамический парсинг веб-страниц предполагает получение данных с веб-сайтов, которые генерируют контент в режиме реального времени с помощью JavaScript или Python. В отличие от статических веб-страниц, динамический контент загружается асинхронно, что делает традиционные методы очистки неэффективными.
Динамический парсинг веб-страниц использует:
- Веб-сайты на основе AJAX
- Одностраничные приложения (SPA)
- Сайты с элементами отложенной загрузки
Ключевые инструменты и технологии:
- Selenium – автоматизирует взаимодействие с браузером.
- BeautifulSoup – анализирует HTML-контент.
- Запросы — извлекает содержимое веб-страницы.
- lxml — анализирует XML и HTML.
Python для динамического парсинга веб-страниц требует более глубокого понимания веб-технологий для эффективного сбора данных в реальном времени.
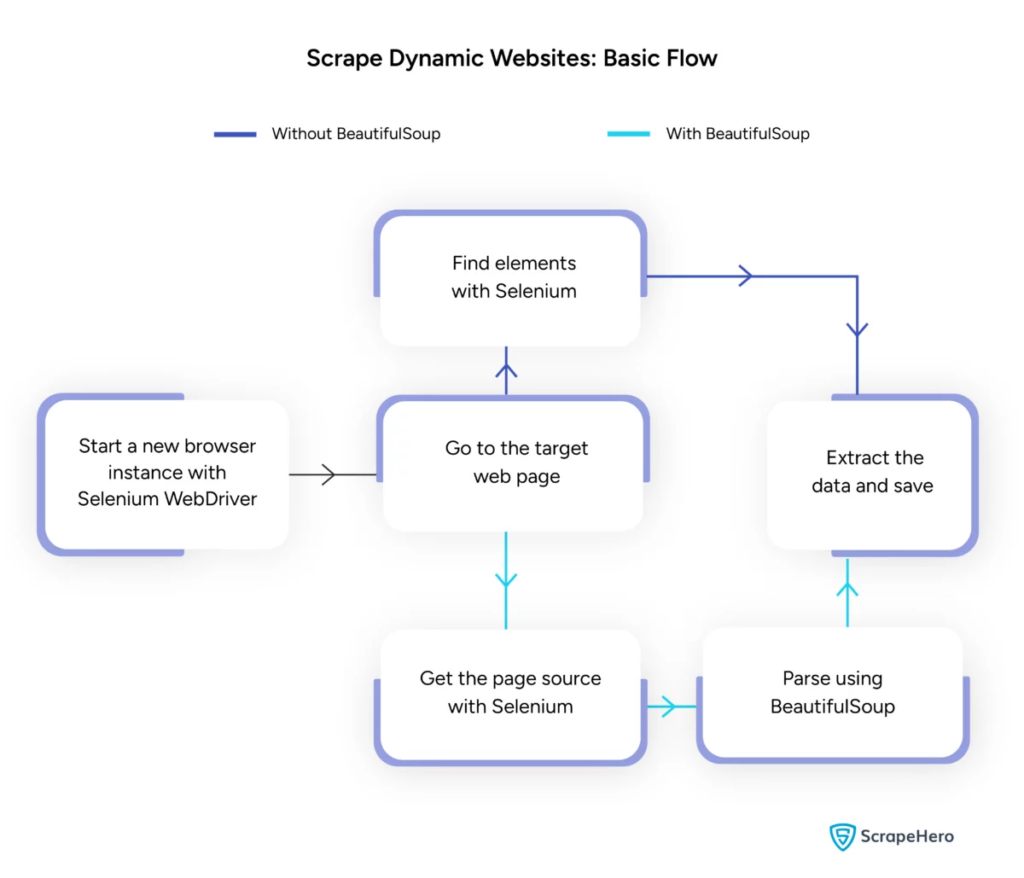
Источник изображения: https://www.scrapehero.com/scrape-a-dynamic-website/
Настройка среды Python
Чтобы начать динамический парсинг веб-страниц Python, важно правильно настроить среду. Следуй этим шагам:
- Установите Python : убедитесь, что Python установлен на компьютере. Последнюю версию можно скачать с официального сайта Python.
- Создайте виртуальную среду :

Активируйте виртуальную среду:

- Установите необходимые библиотеки :

- Настройте редактор кода . Используйте IDE, например PyCharm, VSCode или Jupyter Notebook, для написания и запуска сценариев.
- Ознакомьтесь с HTML/CSS . Понимание структуры веб-страницы помогает эффективно перемещаться по ним и извлекать данные.
Эти шаги создают прочную основу для проектов Python с динамическим парсингом веб-страниц.
Понимание основ HTTP-запросов
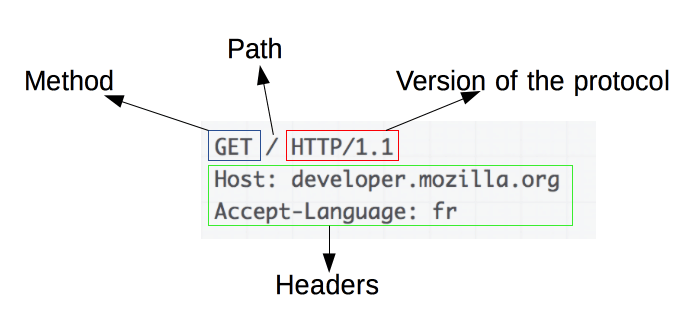
Источник изображения: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview.
HTTP-запросы являются основой парсинга веб-страниц. Когда клиент, например веб-браузер или веб-скребок, хочет получить информацию с сервера, он отправляет HTTP-запрос. Эти запросы имеют определенную структуру:
- Метод : действие, которое необходимо выполнить, например GET или POST.
- URL : адрес ресурса на сервере.
- Заголовки : метаданные о запросе, такие как тип контента и пользовательский агент.
- Тело : необязательные данные, отправляемые вместе с запросом, обычно используемые с POST.
Понимание того, как интерпретировать и создавать эти компоненты, необходимо для эффективного парсинга веб-страниц. Библиотеки Python, такие как запросы, упрощают этот процесс, обеспечивая точный контроль над запросами.
Установка библиотек Python
Источник изображения: https://ajaytech.co/what-are-python-libraries/
Для динамического парсинга веб-страниц с помощью Python убедитесь, что Python установлен. Откройте терминал или командную строку и установите необходимые библиотеки с помощью pip:
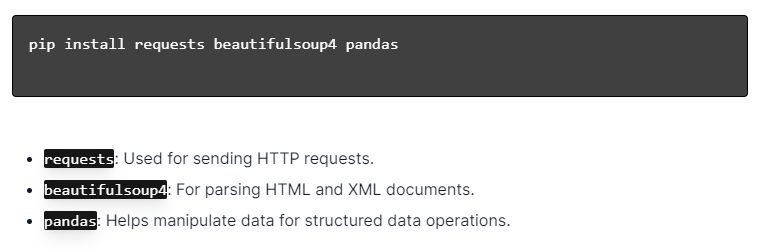
Затем импортируйте эти библиотеки в свой скрипт:

Таким образом, каждая библиотека будет доступна для выполнения задач веб-скрапинга, таких как отправка запросов, анализ HTML и эффективное управление данными.
Создание простого скрипта парсинга веб-страниц
Чтобы создать базовый скрипт динамического парсинга веб-страниц на Python, необходимо сначала установить необходимые библиотеки. Библиотека «запросы» обрабатывает HTTP-запросы, а «BeautifulSoup» анализирует HTML-контент.
Шаги, которые необходимо выполнить:
- Установите зависимости:

- Импортировать библиотеки:

- Получить HTML-контент:
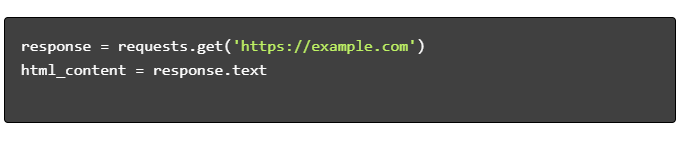
- Разобрать HTML:

- Извлечь данные:

Обработка динамического парсинга веб-страниц с помощью Python
Динамические веб-сайты генерируют контент «на лету», часто требуя более сложных методов.

Рассмотрим следующие шаги:
- Определите целевые элементы . Проверьте веб-страницу на предмет обнаружения динамического контента.
- Выберите платформу Python : используйте такие библиотеки, как Selenium или Playwright.
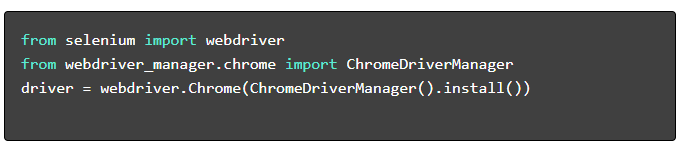
- Установите необходимые пакеты :
- Настройте веб-драйвер :

- Навигация и взаимодействие :
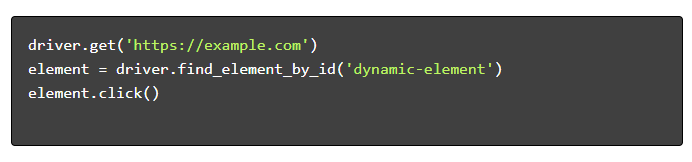
Лучшие практики веб-скрапинга
Рекомендуется следовать передовым методам очистки веб-страниц, чтобы обеспечить эффективность и законность. Ниже приведены основные рекомендации и стратегии обработки ошибок:
- Уважайте Robots.txt : всегда проверяйте файл robots.txt целевого сайта.
- Регулирование : внедрите задержки, чтобы предотвратить перегрузку сервера.
- User-Agent : используйте специальную строку User-Agent, чтобы избежать потенциальных блокировок.
- Логика повтора : используйте блоки try-кроме и настройте логику повтора для обработки тайм-аутов сервера.
- Ведение журнала : ведение полных журналов для отладки.
- Обработка исключений : конкретное обнаружение сетевых ошибок, ошибок HTTP и ошибок синтаксического анализа.
- Обнаружение капчи : используйте стратегии для обнаружения и решения или обхода капчи.
Распространенные проблемы динамического парсинга веб-страниц
Капчи
Многие веб-сайты используют CAPTCHA для предотвращения использования автоматических ботов. Чтобы обойти это:
- Используйте сервисы решения CAPTCHA, такие как 2Captcha.
- Реализуйте вмешательство человека для решения CAPTCHA.
- Используйте прокси, чтобы ограничить частоту запросов.
Блокировка IP
Сайты могут блокировать IP-адреса, отправляющие слишком много запросов. Противодействуйте этому:
- Использование ротационных прокси.
- Реализация регулирования запросов.
- Использование стратегий ротации пользовательских агентов.
JavaScript-рендеринг
Некоторые сайты загружают контент через JavaScript. Решите эту проблему следующим образом:
- Использование Selenium или Puppeteer для автоматизации браузера.
- Использование Scrapy-splash для рендеринга динамического контента.
- Изучение headless-браузеров для взаимодействия с JavaScript.
Правовые вопросы
Парсинг веб-страниц иногда может нарушать условия обслуживания. Обеспечить соблюдение путем:
- Консультации по юридическим вопросам.
- Парсинг общедоступных данных.
- Соблюдение директив robots.txt.
Анализ данных
Обработка противоречивых структур данных может оказаться сложной задачей. Решения включают в себя:
- Использование библиотек, таких как BeautifulSoup, для анализа HTML.
- Использование регулярных выражений для извлечения текста.
- Использование парсеров JSON и XML для структурированных данных.
Хранение и анализ очищенных данных
Хранение и анализ собранных данных являются важными этапами парсинга веб-страниц. Решение о том, где хранить данные, зависит от объема и формата. Общие варианты хранения включают в себя:
- Файлы CSV : удобно для небольших наборов данных и простого анализа.
- Базы данных : базы данных SQL для структурированных данных; NoSQL для неструктурированных.
После сохранения анализ данных можно выполнить с помощью библиотек Python:
- Pandas : идеально подходит для манипулирования и очистки данных.
- NumPy : эффективен для числовых операций.
- Matplotlib и Seaborn : подходят для визуализации данных.
- Scikit-learn : предоставляет инструменты для машинного обучения.
Правильное хранение и анализ данных улучшают доступность данных и их понимание.
Заключение и следующие шаги
Изучив динамический парсинг веб-страниц на Python, необходимо уточнить понимание выделенных инструментов и библиотек.
- Просмотрите код : ознакомьтесь с окончательным сценарием и, где это возможно, разделите его на модули, чтобы улучшить возможность повторного использования.
- Дополнительные библиотеки : изучите расширенные библиотеки, такие как Scrapy или Splash, для более сложных задач.
- Хранение данных . Рассмотрите надежные варианты хранения — базы данных SQL или облачное хранилище для управления большими наборами данных.
- Юридические и этические соображения . Следите за юридическими рекомендациями по очистке веб-страниц, чтобы избежать потенциальных нарушений.
- Следующие проекты : Выполнение новых проектов по парсингу веб-страниц различной сложности еще больше укрепит эти навыки.
Хотите интегрировать профессиональный динамический парсинг веб-страниц с Python в свой проект? Для тех команд, которым требуется крупномасштабное извлечение данных без сложности их внутренней обработки, PromptCloud предлагает индивидуальные решения. Изучите услуги PromptCloud, чтобы найти надежное и надежное решение. Свяжитесь с нами сегодня!