
Исследовательский факторный анализ в R
Опубликовано: 2017-02-16Что такое исследовательский факторный анализ в R?
Исследовательский факторный анализ (EFA), или, грубо говоря, факторный анализ в R, представляет собой статистический метод, который используется для выявления скрытой реляционной структуры среди набора переменных и сужения ее до меньшего числа переменных. По существу это означает, что дисперсия большого числа переменных может быть описана несколькими суммарными переменными, т. е. факторами. Вот обзор исследовательского факторного анализа в R.
Как следует из названия, EFA носит исследовательский характер — мы на самом деле не знаем скрытые переменные, и шаги повторяются до тех пор, пока мы не получим меньшее количество факторов. В этом руководстве мы рассмотрим EFA с использованием R. Теперь давайте сначала получим основную идею набора данных.
1. Данные
Этот набор данных содержит 90 ответов для 14 различных переменных, которые клиенты учитывают при покупке автомобиля. Вопросы опроса были сформулированы с использованием 5-балльной шкалы Лайкерта, где 1 — очень низкий уровень, а 5 — очень высокий. Переменные были следующие:
- Цена
- Безопасность
- Внешний вид
- Простор и комфорт
- Технологии
- Послепродажное обслуживание
- Стоимость перепродажи
- Тип топлива
- Эффективность топлива
- Цвет
- Обслуживание
- Тест-драйв
- Обзоры продуктов
- Отзывы
Нажмите здесь, чтобы загрузить закодированный набор данных.
2. Импорт веб-данных
Теперь мы прочитаем набор данных в формате CSV в R и сохраним его как переменную.
[язык кода = «r»] data <- read.csv(file.choose( ),заголовок=ИСТИНА) [/код]
Откроется окно для выбора CSV-файла, а параметр «заголовок» гарантирует, что первая строка файла будет считаться заголовком. Введите следующее, чтобы просмотреть первые несколько строк фрейма данных и убедиться, что данные сохранены правильно.
[язык кода = «r»] голова (данные) [/код]
3. Установка пакета
Теперь мы установим необходимые пакеты для проведения дальнейшего анализа. Это пакеты psych и GPArotation. В приведенном ниже коде мы вызываем install.packages() для установки.
[code language=”r”] install.packages('psych') install.packages('GPArotation') [/code]
4. Количество факторов
Далее мы узнаем количество факторов, которые мы будем выбирать для факторного анализа. Это оценивается с помощью таких методов, как «параллельный анализ», «собственное значение» и т. д.
Параллельный анализ
Мы будем использовать функцию fa.parallel пакета `Psych` для выполнения параллельного анализа. Здесь мы указываем фрейм данных и факторный метод (в нашем случае «minres»). Запустите следующее, чтобы найти приемлемое количество факторов и создать «график осыпи»:
[язык кода = "r"] parallel <- fa.parallel(data, fm = 'минрес', фа = 'фа') [/code]
Консоль покажет максимальное количество факторов, которые мы можем учесть. Вот как это будет выглядеть.
«Параллельный анализ предполагает, что количество факторов = 5, а количество компонентов = нет данных».
Приведенный ниже на «графике осыпи», сгенерированном из приведенного выше кода:
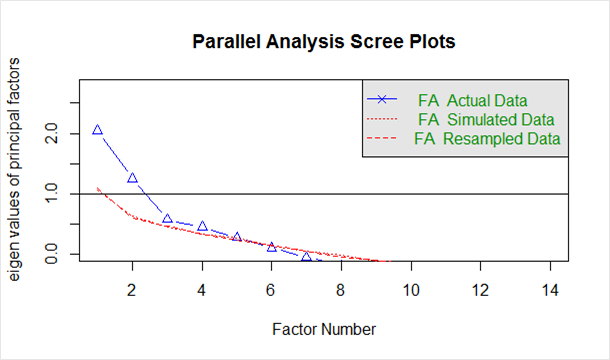
Синяя линия показывает собственные значения фактических данных, а две красные линии (расположенные друг над другом) показывают смоделированные данные и данные после повторной выборки. Здесь мы смотрим на большие падения фактических данных и определяем точку, где они выравниваются вправо. Кроме того, мы находим точку перегиба — точку, где разрыв между смоделированными данными и фактическими данными стремится быть минимальным.

Глядя на этот график и параллельный анализ, хорошим выбором будет от 2 до 5 факторов.
Факторный анализ
Теперь, когда мы пришли к вероятному количеству факторов, давайте начнем с 3 в качестве количества факторов. Для проведения факторного анализа мы будем использовать функцию fa() пакетов psych. Ниже приведены аргументы, которые мы предоставим:
- r - Исходные данные или корреляционная или ковариационная матрица
- nfactors — количество факторов для извлечения
- ротация – несмотря на то, что существуют различные типы ротации, «Варимакс» и «Облимин» являются наиболее популярными.
- fm — один из методов извлечения факторов, таких как «Минимальный остаток (МНК)», «Максимальное правдоподобие», «Основная ось» и т. д.
В этом случае мы выберем наклонное вращение (rotate = «oblimin»), так как считаем, что существует корреляция между факторами. Обратите внимание, что вращение Varimax используется в предположении, что факторы полностью некоррелированы. Мы будем использовать факторинг «Обычный метод наименьших квадратов/минрес» (fm = «minres»), поскольку известно, что он дает результаты, аналогичные «Максимальному правдоподобию», без предположения о многомерном нормальном распределении и выводит решения посредством итеративного собственного разложения, такого как главная ось.
Запустите следующее, чтобы начать анализ.
[code language="r"] threefactor <- fa(data,nfactors = 3, rotate = «oblimin», fm = «minres») print(threefactor) [/code]
Вот вывод, показывающий факторы и нагрузки:
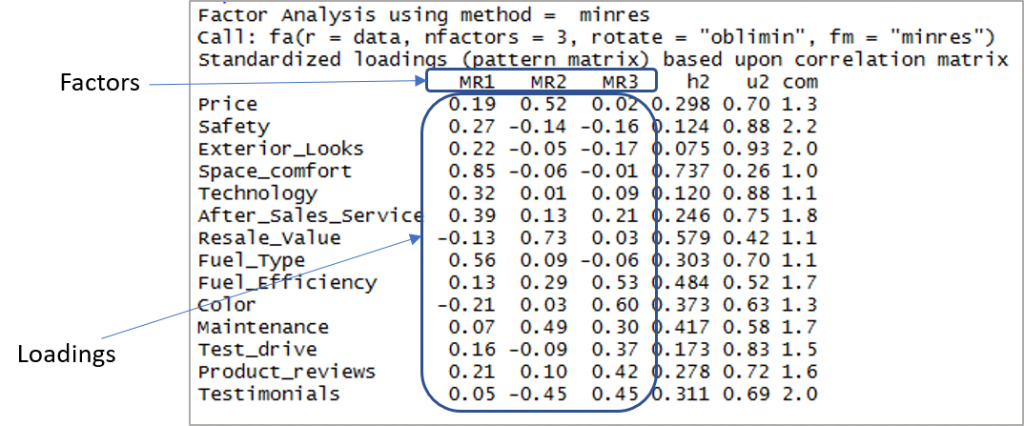
Теперь нам нужно учитывать нагрузки более 0,3 и не нагружать более чем по одному фактору. Обратите внимание, что здесь допустимы отрицательные значения. Итак, давайте сначала установим отсечку, чтобы улучшить видимость.
[язык кода = «r»] print (три фактора загрузки, отсечка = 0,3) [/ код]
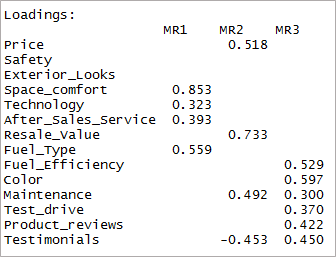
Как видите, две переменные стали незначимыми, а две другие имеют двойную загрузку. Далее мы рассмотрим «4» фактора.
[язык кода = "r"] fourfactor <- fa(data,nfactors = 4, rotate = «oblimin», fm = «minres») print (fourfactor $ loadings, cutoff = 0,3) [/code]
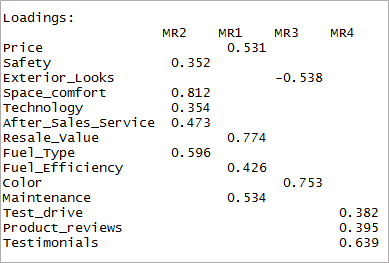
Мы видим, что это приводит только к однократной загрузке. Это известно как простая структура.
Нажмите следующее, чтобы посмотреть факторное сопоставление.
[code language="r"] fa.diagram(fourfactor) [/code]
Тест на адекватность
Теперь, когда мы получили простую структуру, пришло время проверить нашу модель. Давайте посмотрим на результаты факторного анализа, чтобы продолжить.

Корень означает, что квадрат остатков (RMSR) равен 0,05. Это допустимо, так как это значение должно быть ближе к 0. Далее мы должны проверить индекс RMSEA (среднеквадратичная ошибка аппроксимации). Его значение 0,001 показывает хорошее соответствие модели, поскольку оно ниже 0,05. Наконец, индекс Такера-Льюиса (TLI) составляет 0,93 — приемлемое значение, учитывая, что он превышает 0,9.
Именование факторов

После установления адекватности факторов пришло время назвать факторы. Это теоретическая сторона анализа, где мы формируем коэффициенты в зависимости от переменных нагрузок. В этом случае, вот как могут быть созданы факторы.
Вывод
В этом руководстве по анализу в r мы обсудили основную идею EFA (исследовательский факторный анализ в R), рассмотрели параллельный анализ и интерпретацию графика осыпи. Затем мы перешли к факторному анализу в R, чтобы получить простую структуру и проверить ее, чтобы убедиться в адекватности модели. Наконец-то пришли к названиям факторов от переменных. Теперь вперед, попробуйте и опубликуйте свои выводы в разделе комментариев.