
Базар Голос
Опубликовано: 2024-04-24Эта статья о модернизации устаревших систем является дополнением к докладу, который я недавно представил на саммите AWS Data Summit для компаний-разработчиков программного обеспечения, о создании ценности из данных путем использования наших лучших практик для обеспечения успеха в проектах машинного обучения. Если хотите, вы можете прыгнуть вниз и посмотреть это.
Давайте посмотрим правде в глаза: программное обеспечение легче писать, чем поддерживать. Вот почему мы, как инженеры-программисты, предпочитаем просто «вырвать это и начать заново», вместо того, чтобы пытаться понять, о чем думал другой разработчик (или мы сами в прошлом). Кажется, мы коллективно забыли, что «программы должны быть написаны для того, чтобы их читали люди, и лишь вскользь для того, чтобы их могли выполнять машины».
Вы знаете, это правда — нам всем приходилось кропотливо пробираться сквозь кашу из спагетти-кода и тонких абстракций в старомодном стиле, выкапывая суть программы, только чтобы не найти ничего, кроме беспорядка на дне наших тарелок.
Легко кричать «WTF» и обвинять предыдущего разработчика, но правда часто оказывается сложнее. Мы не можем видеть будущее, поэтому невозможно понять, как будут расти требования, технологии или бизнес-цели, когда мы проектируем совершенно новую систему. В результате системы могут стать нечитаемыми, поскольку их объем увеличивается вместе с зависимостью от них бизнеса. Это немного парадоксально: старые и сложные в обслуживании системы часто приносят наибольшую пользу. Над ними сложно работать, потому что они выросли вместе с компанией, и страшно работать, потому что нарушение их может обернуться катастрофой.
Вот к чему я вас призываю: если вам нравятся сложные, но полезные задачи… попробуйте. Возьмите самую старую систему, которая у вас есть, и сделайте ее ремонтопригодной. Вы знаете тот, о котором я говорю, — тот, которым никто не будет «владеть». От него зависят другие отделы, но его ненавидят инженеры. Тот, который вам нужно было сначала пропатчить Log4Shell. Сделай это. Попробуй.
Недавно у меня появилась возможность обновить систему машинного обучения десятилетней давности в Bazaarvoice. На первый взгляд это звучало неинтересно : у этой штуки даже не было нейронных сетей! Какая разница! Ну… это имело значение. Эта система обрабатывает почти каждый пользовательский обзор продукта, полученный Bazaarvoice — почти 9 миллионов в месяц — и делает это с помощью 90 миллионов вызовов моделей машинного обучения. Ага, 90 миллионов выводов! Это огромный масштаб, и мне не терпелось погрузиться в него.
В этом посте я расскажу, как модернизация этой устаревшей системы посредством изменения архитектуры вместо переписывания позволила нам сделать ее масштабируемой и экономически эффективной без необходимости вырывать весь код и начинать заново. Полученная система является бессерверной, контейнеризованной и удобной в обслуживании, при этом наши затраты на хостинг сокращаются почти на 80%.
Что такое устаревшая система?
Унаследованная система — это устаревшее компьютерное программное обеспечение и/или аппаратное обеспечение, которое продолжает работать. Хотя он все еще может выполнять свою первоначальную цель, ему не хватает масштабируемости для будущего роста.
Старые устаревшие системы
Во-первых, давайте посмотрим, с чем мы здесь имеем дело. Устаревшая система, которую моя команда обновляла, модерирует пользовательский контент для всего Bazaarvoice. В частности, он определяет, подходит ли каждый фрагмент контента для веб-сайтов наших клиентов.

Звучит просто: устранить очевидные нарушения, такие как разжигание ненависти, нецензурная лексика или предложения, — но на практике все гораздо сложнее. У каждого клиента есть уникальные требования к тому, что он считает подходящим. Например, пивные бренды ожидают обсуждения алкоголя, а детские бренды — нет. Мы фиксируем эти параметры, специфичные для клиента, когда подключаем новых клиентов, а наша команда по обслуживанию клиентов кодирует их в базу данных управления.
Для некоторой дополнительной сложности мы также отбираем часть нашего контента, который будет модерироваться модераторами-людьми. Это позволяет нам постоянно измерять производительность наших моделей и обнаруживать возможности для создания новых моделей.
Полная архитектура нашей устаревшей системы показана ниже:
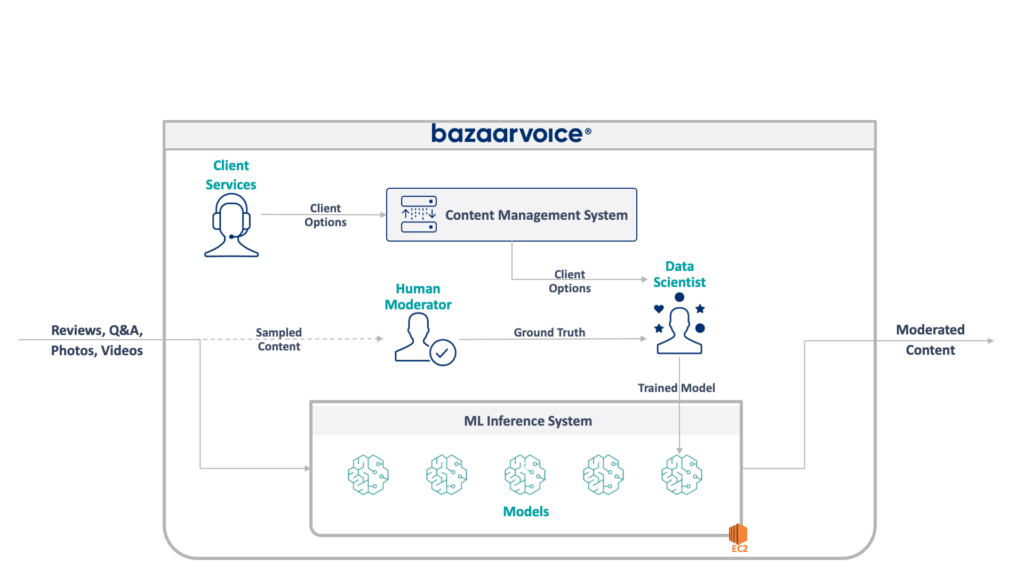
Эта система имеет ряд серьезных недостатков. В частности, все модели размещаются на одном экземпляре EC2. Это произошло не из-за плохой разработки, а просто из-за неспособности первоначальных программистов предвидеть масштаб, желаемый компанией. Никто не думал, что он вырастет так сильно.
Кроме того, система пострадала от неприятия разработчиков: она была написана на языке Scala, который понимали немногие инженеры. Таким образом, его часто упускали из виду для улучшения, поскольку никто не хотел его трогать.
В результате система продолжала расти, сохраняя свет включенным. Как только мы приступили к его перепроектированию, он работал на одном экземпляре x1e.8xlarge. Эта штука имела почти терабайт оперативной памяти, а ее эксплуатация обходилась примерно в 5000 долларов в месяц (без резервирования). Не волнуйтесь, мы только что запустили второй для резервирования и третий для контроля качества.
Эксплуатация этой системы была дорогостоящей и имела высокий риск сбоя (одна-единственная плохая модель могла вывести из строя весь сервис). Более того, база кода активно не развивалась и, следовательно, значительно устарела по сравнению с современными пакетами обработки данных и не соответствовала нашим стандартным практикам для сервисов, написанных на Scala.
Новая система
При перепроектировании этой системы у нас была четкая цель: сделать ее масштабируемой. Снижение эксплуатационных расходов было второстепенной целью, равно как и упрощение управления моделями и кодом.
Новый дизайн, который мы придумали, показан ниже:

Наш подход к решению всех этих проблем заключался в размещении каждой модели машинного обучения на изолированной конечной точке SageMaker Serverless. Как и функции AWS Lambda, бессерверные конечные точки отключаются, когда они не используются, что экономит нам затраты времени на выполнение редко используемых моделей. Они также могут быстро масштабироваться в ответ на увеличение трафика.

Кроме того, мы предоставили параметры клиента одному микросервису, который направляет контент в соответствующие модели. Это была основная часть нового кода, который нам пришлось написать: небольшой API, который было легко поддерживать и который позволял нашим специалистам по данным легче обновлять и развертывать новые модели.
Этот подход имеет следующие преимущества:
- Время восстановления уменьшено более чем в 6 раз. В частности, маршрутизация трафика к существующим моделям происходит мгновенно, а развертывание новых моделей можно выполнить менее чем за 5 минут вместо 30.
- Масштабирование без ограничений — в настоящее время у нас есть 400 моделей, но мы планируем масштабировать их до тысяч, чтобы продолжать увеличивать объем контента, который мы можем автоматически модерировать.
- Заметили снижение затрат на 82 % при переходе с EC2, поскольку функции отключаются, когда они не используются, и мы не платим за машины высшего уровня, которые используются недостаточно эффективно.
Однако простое проектирование идеальной архитектуры — не самая интересная и сложная часть восстановления устаревшей системы — вам придется перейти на нее.
Нашей первой задачей при миграции было выяснить, как, черт возьми, перенести модель Java WEKA для работы на SageMaker, не говоря уже о SageMaker Serverless.
К счастью, SageMaker развертывает модели в контейнерах Docker, так что, по крайней мере, мы можем заморозить версии Java и зависимостей, чтобы они соответствовали нашему старому коду. Это поможет гарантировать, что модели, размещенные в новой системе, будут давать те же результаты, что и устаревшая.

Чтобы сделать контейнер совместимым с SageMaker, все, что вам нужно сделать, — это реализовать несколько конкретных конечных точек HTTP:
-
POST /invocation— принимает входные данные, выполняет логический вывод и возвращает результаты. -
GET /ping— возвращает 200, если сервер JVM исправен.
(Мы решили игнорировать всю ерунду, связанную с многомодельными контейнерами BYO и набором инструментов вывода SageMaker.)
Несколько быстрых абстракций вокруг com.sun.net.httpserver.HttpServer, и мы были готовы к работе.
И знаешь, что? На самом деле это было довольно весело. Игра с контейнерами Docker и внедрение чего-то 10-летней давности в SageMaker Serverless было чем-то вроде мастерства. Было очень интересно, когда мы заставили это работать — особенно когда мы получили устаревший системный код для его сборки в нашем новом стеке sbt вместо maven.
Новый стек sbt упростил работу, а контейнеризация гарантировала правильное поведение при работе в среде SageMaker.
Миграция на новую систему
Итак, у нас есть модели в контейнерах, и мы можем развернуть их в SageMaker — почти готово, верно? Не совсем.
Сложный урок перехода на новую архитектуру заключается в том, что вам придется построить в три раза больше реальной системы только для поддержки миграции. Помимо новой системы нам пришлось построить:
- Конвейер сбора данных в старой системе для записи входных и выходных данных модели. Мы использовали их, чтобы подтвердить, что новая система будет возвращать те же результаты.
- Конвейер обработки данных в новой системе для вычисления результатов и сравнения их с данными из старой системы. Это включало в себя большое количество измерений с помощью Datadog и необходимость предоставления возможности воспроизводить данные, когда мы обнаруживали расхождения.
- Полная система развертывания моделей, чтобы не влиять на пользователей старой системы (которая просто загружала модели в S3). Мы знали, что в конечном итоге хотим перенести их на API, но для первоначального выпуска нам нужно было сделать это без проблем.
Мы знали, что все это был одноразовый код, который можно было бы выбросить, как только закончим миграцию всех пользователей, но нам все равно нужно было его создать и убедиться, что выходные данные новой системы соответствуют старой.
Ожидайте этого заранее.
Хотя создание инструментов и систем миграции, безусловно, заняло более 60% нашего инженерного времени в этом проекте, это тоже был интересный опыт. Модульное тестирование стало больше похоже на эксперименты по науке о данных: мы писали целые пакеты, чтобы гарантировать, что наши выходные данные точно совпадают. Это был другой образ мышления, который делал работу намного веселее. Шаг за пределы наших обычных рамок, если хотите.
Модернизация устаревших систем посредством реархитектуры
В следующий раз, когда у вас возникнет желание перестроить систему с нуля, я бы посоветовал вам попробовать перенести архитектуру вместо кода. Вы столкнетесь с интересными и полезными техническими задачами и, вероятно, получите от этого гораздо больше удовольствия, чем отладка неожиданных крайних случаев вашего нового кода.
Хотите узнать больше? Посмотрите выступление, которое я сделал на AWS Data Summit ниже, в котором подробно рассматривается сторона MLOps.