
Как работает веб-сканер
Опубликовано: 2023-12-05Веб-сканеры выполняют жизненно важную функцию по индексированию и структурированию обширной информации, представленной в Интернете. Их роль заключается в просмотре веб-страниц, сборе данных и предоставлении их для поиска. В этой статье подробно рассматривается механизм веб-сканера, дается представление о его компонентах, операциях и различных категориях. Давайте окунемся в мир веб-сканеров!
Что такое веб-краулер
Веб-сканер, называемый пауком или ботом, представляет собой автоматизированный сценарий или программу, предназначенную для методической навигации по интернет-сайтам. Он начинается с начального URL-адреса, а затем следует по ссылкам HTML для посещения других веб-страниц, образуя сеть взаимосвязанных страниц, которые можно индексировать и анализировать.
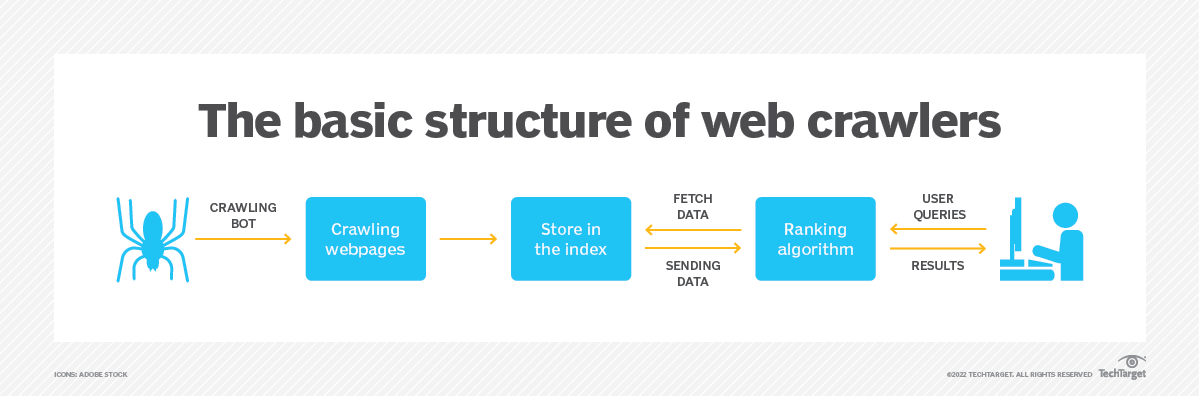
Источник изображения: https://www.techtarget.com/
Цель веб-сканера
Основная цель веб-сканера — сбор информации с веб-страниц и создание индекса с возможностью поиска для эффективного поиска. Крупнейшие поисковые системы, такие как Google, Bing и Yahoo, в значительной степени полагаются на веб-сканеров при создании своих поисковых баз данных. Путем систематического изучения веб-контента поисковые системы могут предоставлять пользователям актуальные и актуальные результаты поиска.
Важно отметить, что применение веб-сканеров выходит за рамки поисковых систем. Они также используются различными организациями для таких задач, как интеллектуальный анализ данных, агрегирование контента, мониторинг веб-сайтов и даже кибербезопасность.
Компоненты веб-сканера
Веб-сканер состоит из нескольких компонентов, работающих вместе для достижения своих целей. Вот ключевые компоненты веб-сканера:
- URL Frontier: этот компонент управляет коллекцией URL-адресов, ожидающих сканирования. Он определяет приоритет URL-адресов на основе таких факторов, как релевантность, актуальность или важность веб-сайта.
- Загрузчик. Загрузчик извлекает веб-страницы на основе URL-адресов, предоставленных границей URL-адресов. Он отправляет HTTP-запросы на веб-серверы, получает ответы и сохраняет полученный веб-контент для дальнейшей обработки.
- Парсер: парсер обрабатывает загруженные веб-страницы, извлекая полезную информацию, такую как ссылки, текст, изображения и метаданные. Он анализирует структуру страницы и извлекает URL-адреса связанных страниц, которые необходимо добавить в границу URL-адресов.
- Хранение данных. Компонент хранения данных хранит собранные данные, включая веб-страницы, извлеченную информацию и данные индексирования. Эти данные могут храниться в различных форматах, таких как база данных или распределенная файловая система.
Как работает веб-сканер
Получив представление о задействованных элементах, давайте углубимся в последовательную процедуру, объясняющую работу веб-сканера:
- Исходный URL-адрес: сканер начинается с исходного URL-адреса, которым может быть любая веб-страница или список URL-адресов. Этот URL-адрес добавляется к границе URL-адресов, чтобы инициировать процесс сканирования.
- Извлечение: сканер выбирает URL-адрес из границы URL-адресов и отправляет HTTP-запрос на соответствующий веб-сервер. Сервер отвечает содержимым веб-страницы, которое затем загружается компонентом загрузчика.
- Анализ: анализатор обрабатывает полученную веб-страницу, извлекая соответствующую информацию, такую как ссылки, текст и метаданные. Он также идентифицирует и добавляет новые URL-адреса, найденные на странице, к границе URL-адресов.
- Анализ ссылок: сканер определяет приоритетность и добавляет извлеченные URL-адреса к границе URL-адресов на основе определенных критериев, таких как релевантность, актуальность или важность. Это помогает определить порядок, в котором сканер будет посещать и сканировать страницы.
- Повторить процесс: сканер продолжает процесс, выбирая URL-адреса из границы URL-адресов, извлекая их веб-контент, анализируя страницы и извлекая дополнительные URL-адреса. Этот процесс повторяется до тех пор, пока не останется URL-адресов для сканирования или пока не будет достигнут заранее определенный предел.
- Хранение данных. На протяжении всего процесса сканирования собранные данные сохраняются в компоненте хранения данных. Эти данные позже можно использовать для индексации, анализа или других целей.
Типы веб-сканеров
Веб-сканеры бывают разных видов и имеют конкретные варианты использования. Вот несколько часто используемых типов веб-сканеров:

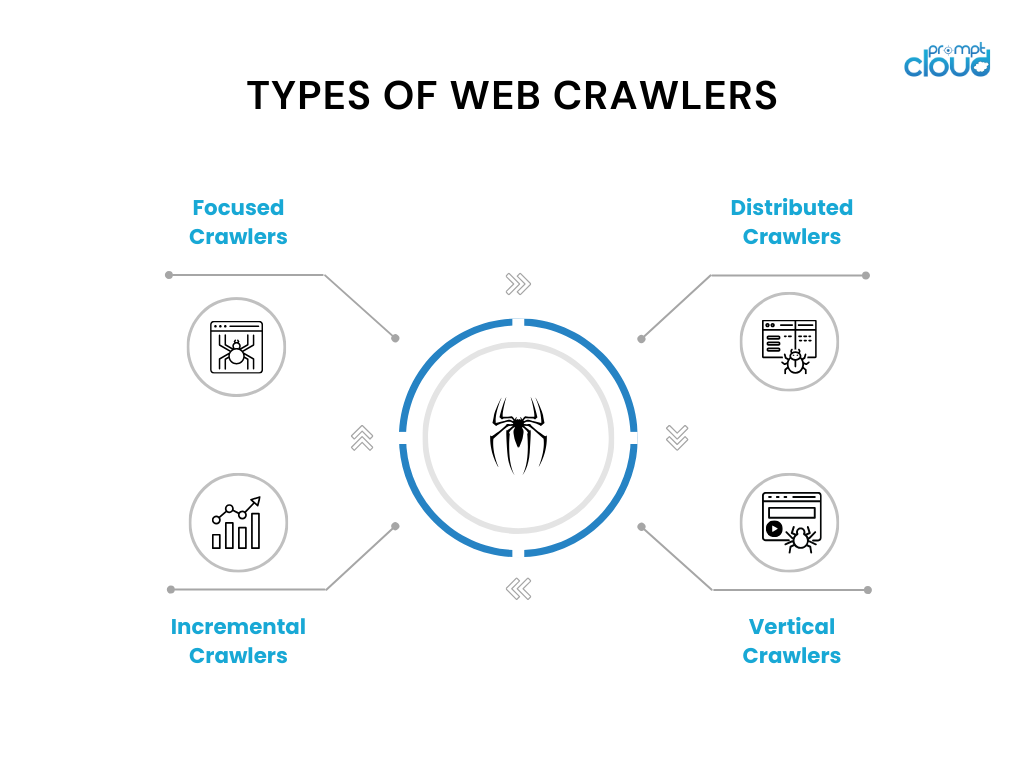
- Целенаправленные сканеры: эти сканеры работают в определенном домене или теме и сканируют страницы, относящиеся к этому домену. Примеры включают тематические сканеры, используемые для новостных веб-сайтов или исследовательских работ.
- Дополнительные сканеры. Дополнительные сканеры сосредоточены на сканировании нового или обновленного контента с момента последнего сканирования. Они используют такие методы, как анализ временных меток или алгоритмы обнаружения изменений, для идентификации и сканирования измененных страниц.
- Распределенные сканеры. В распределенных сканерах несколько экземпляров сканера работают параллельно, разделяя рабочую нагрузку по сканированию огромного количества страниц. Такой подход обеспечивает более быстрое сканирование и улучшенную масштабируемость.
- Вертикальные сканеры. Вертикальные сканеры нацелены на определенные типы контента или данных на веб-страницах, такие как изображения, видео или информация о продукте. Они предназначены для извлечения и индексирования определенных типов данных для специализированных поисковых систем.
Как часто следует сканировать веб-страницы?
Частота сканирования веб-страниц зависит от нескольких факторов, включая размер и частоту обновления веб-сайта, важность страниц и доступные ресурсы. Некоторые веб-сайты могут требовать частого сканирования для обеспечения индексации самой последней информации, в то время как другие могут сканироваться реже.
Для веб-сайтов с высоким трафиком или с быстро меняющимся контентом более частое сканирование необходимо для поддержания актуальной информации. С другой стороны, небольшие веб-сайты или страницы с нечастыми обновлениями можно сканировать реже, что снижает рабочую нагрузку и необходимые ресурсы.
Собственный веб-сканер и инструменты веб-сканирования
Рассматривая создание веб-сканера, крайне важно оценить сложность, масштабируемость и необходимые ресурсы. Создание сканера с нуля может занять много времени и включать в себя такие действия, как управление параллелизмом, контроль распределенных систем и устранение инфраструктурных препятствий. С другой стороны, выбор инструментов или фреймворков для сканирования веб-страниц может предложить более быстрое и эффективное решение.
Альтернативно, использование инструментов или фреймворков веб-сканирования может обеспечить более быстрое и эффективное решение. Эти инструменты предлагают такие функции, как настраиваемые правила сканирования, возможности извлечения данных и варианты хранения данных. Используя существующие инструменты, разработчики могут сосредоточиться на своих конкретных требованиях, таких как анализ данных или интеграция с другими системами.
Однако крайне важно учитывать ограничения и затраты, связанные с использованием сторонних инструментов, такие как ограничения на настройку, владение данными и потенциальные модели ценообразования.
Заключение
Поисковые системы в значительной степени полагаются на веб-сканеров, которые играют важную роль в организации и каталогизации обширной информации, представленной в Интернете. Понимание механики, компонентов и различных категорий веб-сканеров позволяет глубже понять сложную технологию, лежащую в основе этого фундаментального процесса.
Независимо от того, решите ли вы создать веб-сканер с нуля или использовать уже существующие инструменты для веб-сканирования, становится обязательным принять подход, соответствующий вашим конкретным потребностям. Это влечет за собой рассмотрение таких факторов, как масштабируемость, сложность и ресурсы, находящиеся в вашем распоряжении. Принимая во внимание эти элементы, вы можете эффективно использовать веб-сканирование для сбора и анализа ценных данных, тем самым продвигая вперед свой бизнес или исследовательские усилия .
В PromptCloud мы специализируемся на извлечении веб-данных, получая данные из общедоступных онлайн-ресурсов. Свяжитесь с нами по адресу sales@promptcloud.com .