
Как создать резервную копию данных Universal Analytics в BigQuery с помощью R
Опубликовано: 2023-09-26Universal Analytics (UA) наконец прекратила свое существование, и наши данные теперь свободно передаются в наши ресурсы Google Analytics 4 (GA4). Может возникнуть соблазн никогда больше не просматривать наши настройки UA, однако, прежде чем мы оставим UA позади, важно сохранить уже обработанные данные, если нам понадобится проанализировать их в будущем. Для хранения ваших данных мы, конечно же, рекомендуем BigQuery, службу хранилища данных Google, и в этом блоге мы собираемся показать вам, какие данные нужно копировать из UA и как это делать!
Чтобы загрузить наши данные, мы собираемся использовать API Google Analytics. Мы собираемся написать скрипт, который будет скачивать необходимые данные из UA и загружать их в BigQuery сразу. Для этой задачи мы настоятельно рекомендуем использовать R, поскольку пакеты googleAnalyticsR и bigQueryR делают эту работу очень простой, и по этой причине мы написали наше руководство для R!
В этом руководстве не рассматриваются более сложные шаги по настройке аутентификации, такие как загрузка файла учетных данных. Информацию об этом и дополнительную информацию о том, как загружать данные в BigQuery, можно найти в нашем блоге о загрузке данных в BigQuery из R и Python!
Резервное копирование данных UA с помощью R
Как обычно для любого сценария R, первым шагом является загрузка наших библиотек. Для этого скрипта нам понадобится следующее:
библиотека (googleAuthR)
библиотека (googleAnalyticsR)
библиотека (bigQueryR)
Если вы раньше не использовали эти библиотеки, запустите install.packages(<ИМЯ ПАКЕТА>) в консоли, чтобы установить их.
Затем нам нужно будет отсортировать все наши различные разрешения. Для этого вам нужно запустить следующий код и следовать всем инструкциям:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client(“C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = «<ваш адрес электронной почты>»)
ga_id <- <ВАШ ИДЕНТИФИКАТОР GA VIEW ЗДЕСЬ>
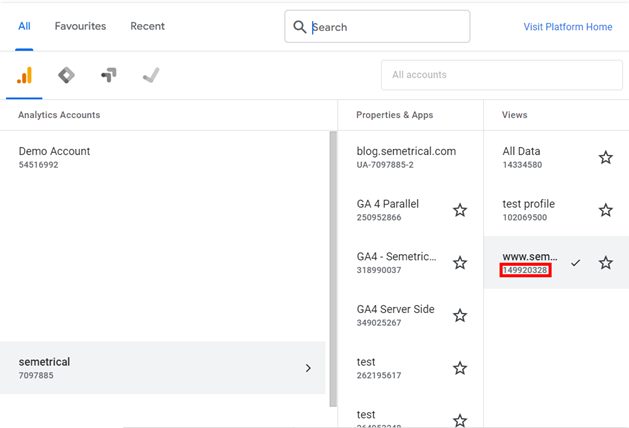
ga_id можно найти под именем представления, когда вы выбираете его в UA, как показано ниже:
Далее нам предстоит решить, какие данные на самом деле брать из UA. Мы рекомендуем вытащить следующее:
| Измерения на уровне сеанса | Измерения на уровне событий | Размеры с учетом просмотров страниц |
| ID клиента | ID клиента | Путь к странице |
| Временная метка | Временная метка | Временная метка |
| Источник/Средство | Категория события | Источник/Средство |
| Категория устройства | Действие по событию | Категория устройства |
| Кампания | Метка события | Кампания |
| Группировка каналов | Источник/Средство | Группировка каналов |
| Кампания |
Помещения их в три таблицы в BigQuery должно быть достаточно для всех ваших потенциальных будущих потребностей в данных UA. Чтобы получить эти данные из UA, сначала вам нужно указать диапазон дат. Зайдите на платформу UA и посмотрите в одном из своих отчетов, чтобы узнать, когда впервые начался сбор данных. Затем укажите диапазон дат, который длится с этого дня до дня перед запуском сценария, то есть последнего дня, за который у вас будут полные 24-часовые данные (и если вы делаете это после того, как UA был Sunset, в любом случае будет включать 100 % ваших доступных данных). Наш сбор данных начался в мае 2017 года, поэтому я написал:

даты <- c("2017-05-01", Sys.Date()-1)
Теперь нам нужно указать, что нужно вытащить из UA согласно таблице выше. Для этого нам нужно будет запустить метод google_analytics() три раза, поскольку вы не можете запрашивать измерения разных областей вместе. Вы можете точно скопировать следующий код:
sessionpull <- google_analytics(ga_id,
диапазон_даты = даты,
метрики = c («сессии»),
размеры = c («clientId», «dateHourMinute»,
«sourceMedium», «deviceCategory», «campaign», «channelGrouping»),
анти_образец = ИСТИНА)
eventpull <- google_analytics(ga_id,
диапазон_даты = даты,
метрики = c («totalEvents», «eventValue»),
Dimensions = c («clientId», «dateHourMinute», «eventCategory», «eventAction», «eventLabel», «sourceMedium», «campaign»),
анти_образец = ИСТИНА)
pvpull <- google_analytics(ga_id,
диапазон_даты = даты,
метрики = c («просмотры страниц»),
Dimensions = c («pagePath», «dateHourMinute», «sourceMedium», «deviceCategory», «campaign», «channelGrouping»),
анти_образец = ИСТИНА)
Это должно аккуратно поместить все ваши данные в три фрейма данных с названием sessionpull для измерений на уровне сеанса, eventpull для измерений на уровне событий и pvpull для измерений на уровне просмотра страниц.
Теперь нам нужно загрузить данные в BigQuery, код для которого должен выглядеть примерно так, повторяясь три раза для каждого кадра данных:
bqr_upload_data("<ваш проект>", "<ваш набор данных>", "<ваша таблица>", <ваш фрейм данных>)
В моем случае это означает, что мой код гласит:
bqr_upload_data («мой-проект», «test2», «bloguploadRSess», sessionpull)
bqr_upload_data («мой-проект», «test2», «bloguploadREvent», eventpull)
bqr_upload_data("мой-проект", "test2", "bloguploadRpv", pvpull)
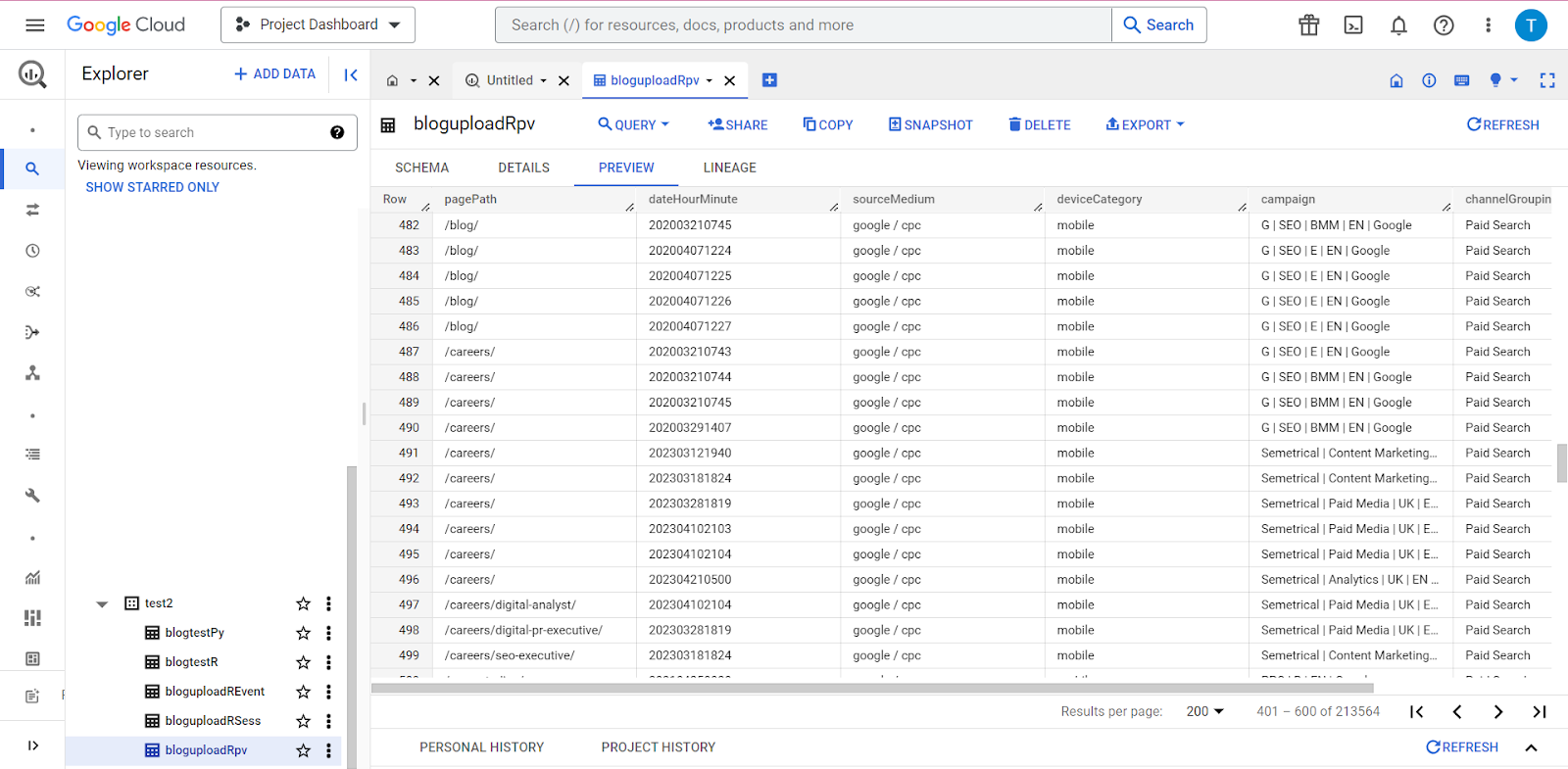
Как только все это будет написано, вы можете запустить свой скрипт, расслабиться и отдохнуть! Как только это будет сделано, вы сможете перейти в BigQuery и увидеть все свои данные там, где они сейчас находятся!
Когда ваши данные UA надежно спрятаны на черный день, вы можете полностью сосредоточиться на максимальном раскрытии потенциала вашей настройки GA4 – и Semetrical здесь, чтобы помочь в этом! Посетите наш блог для получения дополнительной информации о том, как максимально эффективно использовать ваши данные. Или, чтобы получить дополнительную поддержку по всем аспектам аналитики, воспользуйтесь нашими услугами веб-аналитики и узнайте, как мы можем вам помочь.