
Освоение парсеров веб-страниц: руководство для начинающих по извлечению онлайн-данных
Опубликовано: 2024-04-09Что такое парсеры веб-страниц?
Парсер веб-страниц — это инструмент, предназначенный для извлечения данных с веб-сайтов. Он имитирует навигацию человека для сбора определенного контента. Новички часто используют эти парсеры для различных задач, включая исследование рынка, мониторинг цен и сбор данных для проектов машинного обучения.
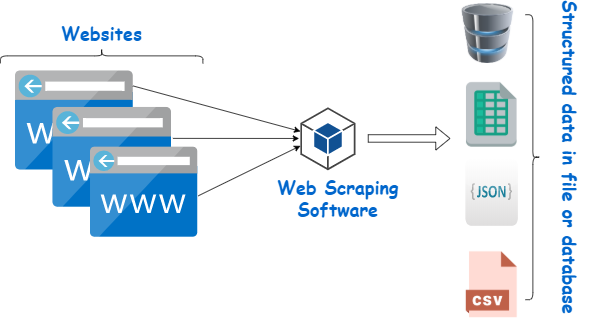
Источник изображения: https://www.webharvy.com/articles/what-is-web-scraping.html.
- Простота использования: они удобны для пользователя и позволяют людям с минимальными техническими навыками эффективно собирать веб-данные.
- Эффективность: парсеры могут быстро собирать большие объемы данных, что значительно превосходит усилия по сбору данных вручную.
- Точность: автоматический сбор данных снижает риск человеческой ошибки, повышая точность данных.
- Экономичность: они устраняют необходимость ручного ввода, экономя трудозатраты и время.
Понимание функциональности парсеров веб-страниц имеет решающее значение для всех, кто хочет использовать возможности веб-данных.
Создание простого парсера веб-страниц с помощью Python
Чтобы начать создавать парсер веб-страниц на Python, необходимо установить определенные библиотеки, а именно запросы для выполнения HTTP-запросов к веб-странице и BeautifulSoup из bs4 для анализа документов HTML и XML.
- Инструменты для сбора:
- Библиотеки: используйте запросы для получения веб-страниц и BeautifulSoup для анализа загруженного HTML-контента.
- Таргетинг на веб-страницу:
- Определите URL-адрес веб-страницы, содержащей данные, которые мы хотим очистить.
- Загрузка контента:
- С помощью запросов загрузите HTML-код веб-страницы.
- Разбор HTML:
- BeautifulSoup преобразует загруженный HTML в структурированный формат для удобной навигации.
- Извлечение данных:
- Определите конкретные HTML-теги, содержащие нужную нам информацию (например, названия продуктов в тегах <div>).
- Используя методы BeautifulSoup, извлекайте и обрабатывайте нужные вам данные.
Не забудьте указать конкретные элементы HTML, относящиеся к информации, которую вы хотите очистить.
Пошаговый процесс очистки веб-страницы
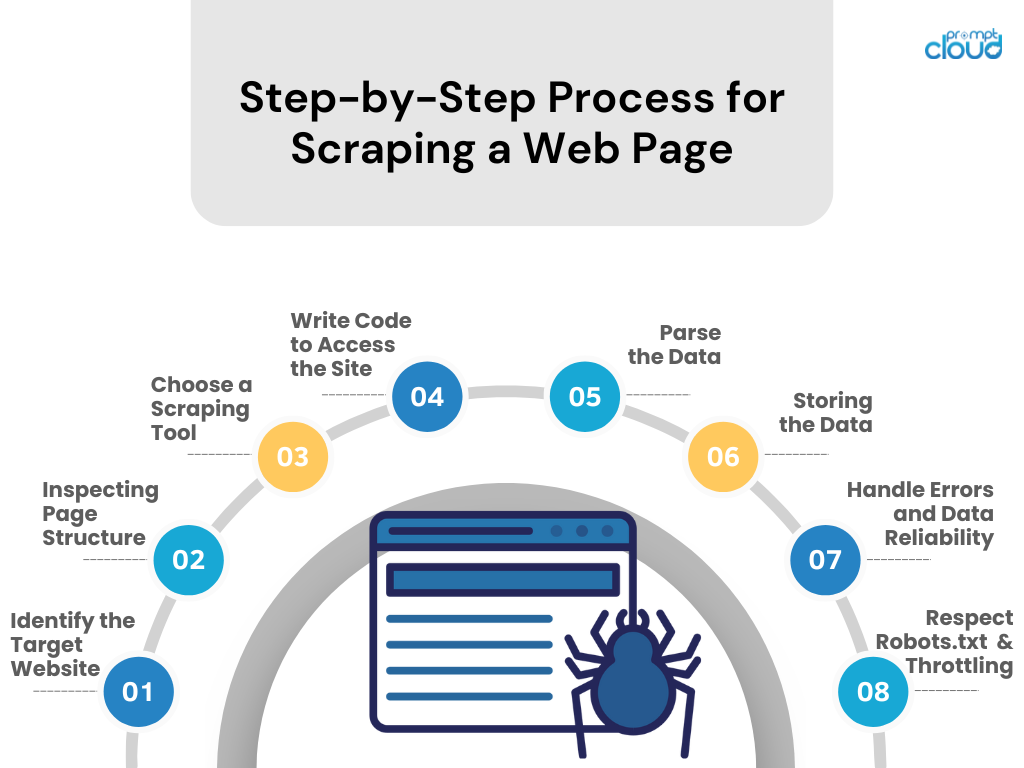
- Определите целевой веб-сайт
Изучите веб-сайт, который вы хотите парсить. Убедитесь, что это законно и этично. - Проверка структуры страницы
Используйте инструменты разработчика браузера для изучения структуры HTML, селекторов CSS и содержимого, управляемого JavaScript. - Выберите инструмент для очистки
Выберите инструмент или библиотеку на удобном для вас языке программирования (например, BeautifulSoup или Scrapy Python). - Напишите код для доступа к сайту
Создайте сценарий, который запрашивает данные с веб-сайта, используя вызовы API, если они доступны, или HTTP-запросы. - Анализ данных
Извлеките соответствующие данные с веб-страницы путем анализа HTML/CSS/JavaScript. - Хранение данных
Сохраните очищенные данные в структурированном формате, например CSV, JSON, или непосредственно в базе данных. - Обработка ошибок и надежность данных
Внедрите обработку ошибок для управления сбоями запросов и обеспечения целостности данных. - Уважайте Robots.txt и регулирование
Соблюдайте правила файла robots.txt сайта и избегайте перегрузки сервера, контролируя частоту запросов.
Выбор идеальных инструментов веб-скрапинга для ваших нужд
При парсинге в Интернете решающее значение имеет выбор инструментов, соответствующих вашим навыкам и целям. Новичкам следует учитывать:
- Простота использования. Выбирайте интуитивно понятные инструменты с визуальной подсказкой и понятной документацией.
- Требования к данным: оцените структуру и сложность целевых данных, чтобы определить, требуется ли простое расширение или надежное программное обеспечение.
- Бюджет: сопоставьте стоимость с возможностями; многие эффективные парсеры предлагают бесплатные уровни.
- Кастомизация: убедитесь, что инструмент адаптируется к конкретным потребностям очистки.
- Поддержка: доступ к полезному сообществу пользователей помогает в устранении неполадок и улучшении.
Выбирайте с умом, чтобы процесс очистки прошел гладко.
Советы и рекомендации по оптимизации парсера веб-страниц
- Используйте эффективные библиотеки синтаксического анализа, такие как BeautifulSoup или Lxml в Python, для более быстрой обработки HTML.
- Внедрите кеширование, чтобы избежать повторной загрузки страниц и снизить нагрузку на сервер.
- Уважайте файлы robots.txt и используйте ограничение скорости, чтобы предотвратить блокировку целевого веб-сайта.
- Меняйте пользовательские агенты и прокси-серверы, чтобы имитировать поведение человека и избежать обнаружения.
- Запланируйте парсеры в непиковые часы, чтобы свести к минимуму влияние на производительность веб-сайта.
- Выбирайте конечные точки API, если они доступны, поскольку они предоставляют структурированные данные и, как правило, более эффективны.
- Избегайте очистки ненужных данных, применяя избирательные запросы, сокращая требуемую пропускную способность и объем хранилища.
- Регулярно обновляйте парсеры, чтобы адаптироваться к изменениям в структуре сайта и поддерживать целостность данных.
Решение распространенных проблем и устранение неполадок при парсинге веб-страниц
При работе со парсерами веб-страниц новички могут столкнуться с несколькими распространенными проблемами:

- Проблемы с селектором : убедитесь, что селекторы соответствуют текущей структуре веб-страницы. Такие инструменты, как инструменты разработчика браузера, могут помочь определить правильные селекторы.
- Динамический контент : некоторые веб-страницы динамически загружают контент с помощью JavaScript. В таких случаях рассмотрите возможность использования автономных браузеров или инструментов, отображающих JavaScript.
- Заблокированные запросы . Веб-сайты могут блокировать скраперы. Используйте такие стратегии, как ротация пользовательских агентов, использование прокси и уважение файла robots.txt, чтобы смягчить блокировку.
- Проблемы с форматом данных . Извлеченные данные могут нуждаться в очистке или форматировании. Используйте регулярные выражения и манипуляции со строками для стандартизации данных.
Не забудьте обратиться к документации и форумам сообщества для получения конкретных рекомендаций по устранению неполадок.
Заключение
Новички теперь могут удобно собирать данные из Интернета с помощью парсера веб-страниц, что делает исследования и анализ более эффективными. Понимание правильных методов с учетом юридических и этических аспектов позволяет пользователям использовать весь потенциал веб-скрапинга. Следуйте этим рекомендациям, чтобы легко освоить парсинг веб-страниц, получить ценную информацию и принять обоснованные решения.
Часто задаваемые вопросы:
Что такое парсинг страницы?
Веб-сбор, также известный как сбор данных или веб-сбор, состоит из автоматического извлечения данных с веб-сайтов с помощью компьютерных программ, имитирующих поведение человека при навигации. С помощью парсера веб-страниц можно быстро отсортировать огромные объемы информации, сосредоточив внимание исключительно на важных разделах, а не компилируя их вручную.
Компании применяют парсинг веб-страниц для таких функций, как изучение затрат, управление репутацией, анализ тенденций и проведение конкурентного анализа. Реализация проектов парсинга веб-страниц требует проверки того, что посещаемые веб-сайты одобряют действия и соблюдают все соответствующие протоколы robots.txt и nofollow.
Как парсить всю страницу?
Для очистки всей веб-страницы обычно требуются два компонента: способ найти необходимые данные на веб-странице и механизм сохранения этих данных в другом месте. Многие языки программирования поддерживают парсинг веб-страниц, особенно Python и JavaScript.
Для обоих существуют различные библиотеки с открытым исходным кодом, что еще больше упрощает процесс. Некоторые популярные варианты среди разработчиков Python включают BeautifulSoup, Requests, LXML и Scrapy. Альтернативно, коммерческие платформы, такие как ParseHub и Octoparse, позволяют менее техническим специалистам визуально создавать сложные рабочие процессы очистки веб-страниц. После установки необходимых библиотек и понимания основных концепций выбора элементов DOM начните с определения интересующих точек данных на целевой веб-странице.
Используйте инструменты разработчика браузера для проверки тегов и атрибутов HTML, а затем преобразуйте эти результаты в соответствующий синтаксис, поддерживаемый выбранной библиотекой или платформой. Наконец, укажите предпочтения формата вывода: CSV, Excel, JSON, SQL или другой вариант, а также места назначения, где находятся сохраненные данные.
Как использовать парсер Google?
Вопреки распространенному мнению, Google не предлагает напрямую общедоступный инструмент для парсинга веб-страниц как таковой, несмотря на то, что предоставляет API и SDK для облегчения интеграции с несколькими продуктами. Тем не менее, опытные разработчики создали сторонние решения, основанные на основных технологиях Google, которые эффективно расширяют возможности за пределы встроенной функциональности. Примеры включают SerpApi, который абстрагирует сложные аспекты консоли поиска Google и представляет простой в использовании интерфейс для отслеживания рейтинга ключевых слов, оценки органического трафика и исследования обратных ссылок.
Хотя эти гибридные модели технически отличаются от традиционного парсинга веб-страниц, они стирают границы, разделяющие традиционные определения. Другие примеры демонстрируют усилия по обратному проектированию, применяемые для реконструкции внутренней логики платформы Google Maps, YouTube Data API v3 или Google Shopping Services, что обеспечивает функциональность, удивительно близкую к исходным аналогам, хотя и подверженную различной степени рисков законности и устойчивости. В конечном счете, начинающие парсеры веб-страниц должны изучить различные варианты и оценить преимущества относительно конкретных требований, прежде чем выбирать тот или иной путь.
Законен ли парсер Facebook?
Как указано в Политике разработчиков Facebook, несанкционированное парсинг веб-страниц представляет собой явное нарушение стандартов сообщества. Пользователи соглашаются не разрабатывать и не использовать приложения, скрипты или другие механизмы, предназначенные для обхода или превышения установленных ограничений скорости API, а также не пытаться расшифровывать, декомпилировать или реконструировать какой-либо аспект Сайта или Сервиса. Кроме того, он подчеркивает ожидания в отношении защиты данных и конфиденциальности, требуя явного согласия пользователя, прежде чем делиться личной информацией за пределами разрешенного контекста.
Любое несоблюдение изложенных принципов влечет за собой ужесточение дисциплинарных мер, начиная с предупреждений и постепенно переходя к ограничению доступа или полному лишению привилегий в зависимости от степени серьезности. Несмотря на исключения, предусмотренные для исследователей безопасности, работающих в рамках утвержденных программ вознаграждения за обнаружение ошибок, общее мнение выступает за то, чтобы избегать несанкционированных инициатив по очистке Facebook, чтобы избежать ненужных осложнений. Вместо этого рассмотрите возможность поиска альтернатив, совместимых с преобладающими нормами и конвенциями, одобренными платформой.