
Преодоление технических проблем при парсинге веб-страниц: экспертные решения
Опубликовано: 2024-03-29Парсинг веб-страниц — это практика, которая сопряжена с многочисленными техническими проблемами даже для опытных майнеров данных. Это влечет за собой использование методов программирования для получения и извлечения данных с веб-сайтов, что не всегда легко из-за сложной и разнообразной природы веб-технологий.
Более того, на многих веб-сайтах предусмотрены защитные меры для предотвращения сбора данных, поэтому парсерам необходимо согласовывать механизмы защиты от парсинга, динамический контент и сложные структуры сайта.
Несмотря на то, что цель быстрого получения полезной информации кажется простой, ее достижение требует преодоления ряда серьезных препятствий, требующих сильных аналитических и технических способностей.
Обработка динамического контента
Динамический контент, который относится к информации веб-страницы, которая обновляется в зависимости от действий пользователя или загружается после первоначального просмотра страницы, обычно создает проблемы для инструментов веб-скрапинга.
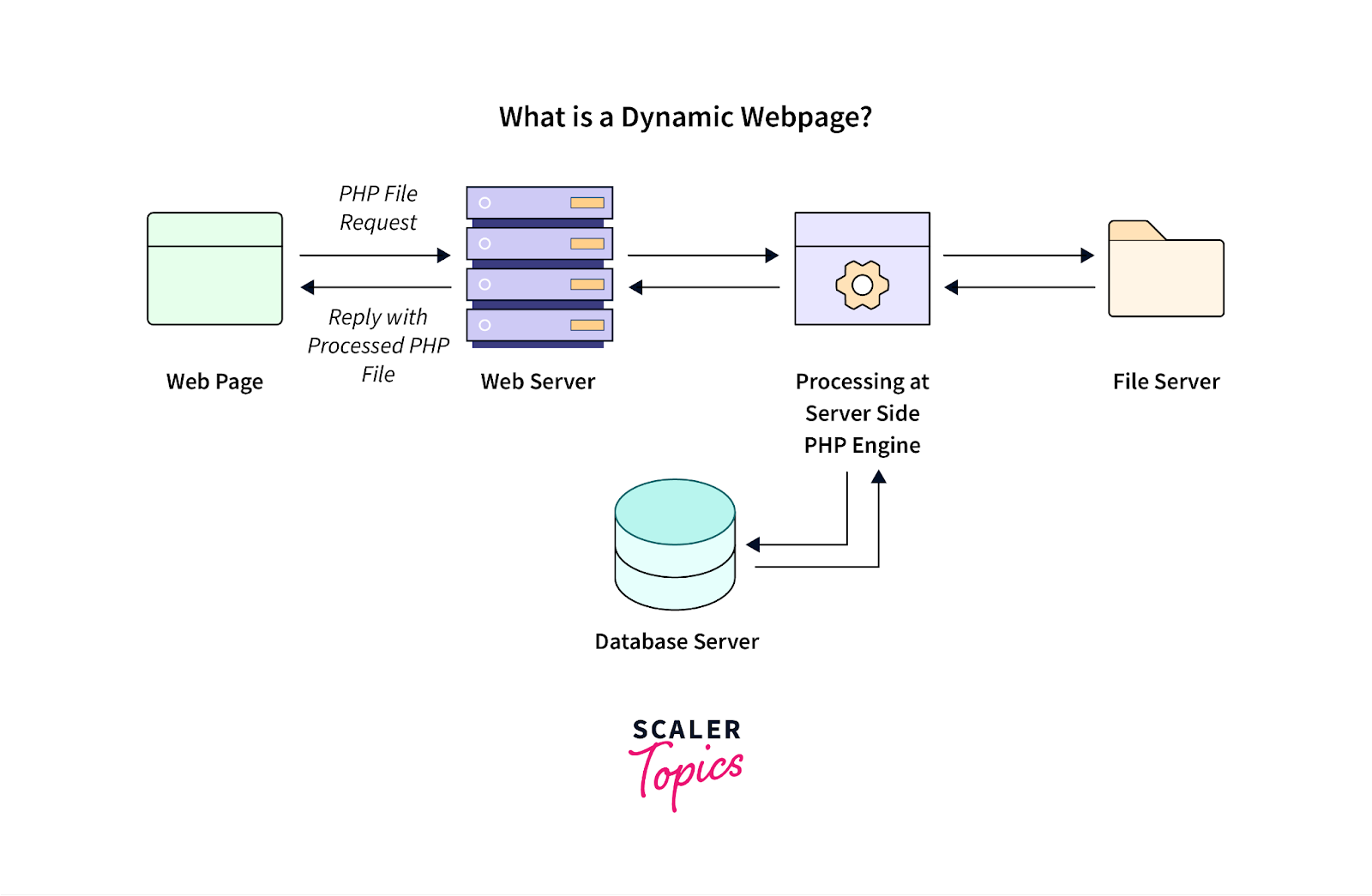
Источник изображения: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Такой динамический контент часто используется в современных веб-приложениях, созданных с использованием фреймворков JavaScript. Чтобы успешно управлять и извлекать данные из такого динамически генерируемого контента, рассмотрите следующие рекомендации:
- Рассмотрите возможность использования инструментов веб-автоматизации, таких как Selenium, Puppeteer или Playwright, которые позволяют вашему парсеру вести себя на веб-странице так же, как это сделал бы настоящий пользователь.
- Внедрите методы обработки WebSockets или AJAX , если веб-сайт использует эти технологии для динамической загрузки контента.
- Подождите, пока элементы загрузятся, используя явные ожидания в коде очистки, чтобы убедиться, что контент полностью загружен, прежде чем пытаться его очистить.
- Исследуйте возможности безголовых браузеров , которые могут выполнять JavaScript и отображать всю страницу, включая динамически загружаемый контент.
Овладев этими стратегиями, парсеры смогут эффективно извлекать данные даже с самых интерактивных и динамически меняющихся веб-сайтов.
Технологии защиты от царапин
Веб-разработчики обычно принимают меры, направленные на предотвращение несанкционированного сбора данных для защиты своих веб-сайтов. Эти меры могут создать серьезные проблемы для парсеров. Вот несколько методов и стратегий для навигации по технологиям защиты от парсинга:

Источник изображения: https://kinsta.com/knowledgebase/what-is-web-scraping/
- Динамический факторинг : веб-сайты могут генерировать контент динамически, что затрудняет прогнозирование URL-адресов или структур HTML. Используйте инструменты, которые могут выполнять JavaScript и обрабатывать запросы AJAX.
- Блокировка IP : частые запросы с одного и того же IP могут привести к блокировке. Используйте пул прокси-серверов для ротации IP-адресов и имитации моделей трафика людей.
- CAPTCHA : они предназначены для различения людей и ботов. Примените службы решения CAPTCHA или выберите ручной ввод, если это возможно.
- Ограничение скорости . Чтобы избежать превышения ограничений скорости, ограничите скорость запросов и внедрите случайные задержки между запросами.
- User-Agent : веб-сайты могут блокировать известные пользовательские агенты-скребки. Меняйте пользовательские агенты, чтобы имитировать разные браузеры или устройства.
Преодоление этих проблем требует сложного подхода, который учитывает условия обслуживания веб-сайта и обеспечивает эффективный доступ к необходимым данным.
Работа с CAPTCHA и ловушками Honeypot
Веб-скраперы часто сталкиваются с проблемами CAPTCHA, призванными отличить пользователей-людей от ботов. Для преодоления этого необходимо:
- Использование сервисов решения CAPTCHA, использующих возможности человека или искусственного интеллекта.
- Внедрение задержек и рандомизация запросов для имитации человеческого поведения.
Для ловушек-приманок, которые невидимы для пользователей, но перехватывают автоматические сценарии:
- Внимательно проверяйте код сайта, чтобы избежать взаимодействия со скрытыми ссылками.
- Использование менее агрессивных методов очистки, чтобы оставаться вне поля зрения.
Разработчики должны этически сбалансировать эффективность с уважением к условиям веб-сайта и пользовательскому опыту.
Эффективность парсинга и оптимизация скорости
Процессы парсинга веб-страниц можно улучшить за счет оптимизации эффективности и скорости. Чтобы преодолеть проблемы в этой области:
- Используйте многопоточность для одновременного извлечения данных и увеличения пропускной способности.
- Используйте автономные браузеры для более быстрого выполнения за счет устранения ненужной загрузки графического контента.
- Оптимизируйте код очистки для выполнения с минимальной задержкой.
- Внедрите соответствующее регулирование запросов, чтобы предотвратить блокировку IP-адресов, сохраняя при этом стабильный темп.
- Кэшируйте статический контент, чтобы избежать повторных загрузок, экономя пропускную способность и время.
- Используйте методы асинхронного программирования для оптимизации операций сетевого ввода-вывода.
- Выбирайте эффективные селекторы и библиотеки синтаксического анализа, чтобы снизить затраты на манипуляции с DOM.
Используя эти стратегии, веб-парсеры могут добиться высокой производительности с минимальными сбоями в работе.

Извлечение и анализ данных
Парсинг веб-страниц требует точного извлечения и анализа данных, что представляет собой определенные проблемы. Вот способы их решения:
- Используйте надежные библиотеки, такие как BeautifulSoup или Scrapy, которые могут обрабатывать различные структуры HTML.
- Используйте регулярные выражения осторожно, чтобы точно ориентироваться на конкретные шаблоны.
- Используйте инструменты автоматизации браузера, такие как Selenium, для взаимодействия с веб-сайтами с большим количеством JavaScript, гарантируя обработку данных перед их извлечением.
- Используйте селекторы XPath или CSS для точного определения элементов данных в DOM.
- Управляйте нумерацией страниц и бесконечной прокруткой, определяя и управляя механизмом загрузки нового контента (например, обновляя параметры URL-адреса или обрабатывая вызовы AJAX).
Овладение искусством парсинга веб-страниц
Парсинг веб-страниц — бесценный навык в мире, управляемом данными. Преодоление технических проблем — от динамического контента до обнаружения ботов — требует настойчивости и адаптивности. Успешный парсинг веб-страниц предполагает сочетание этих подходов:
- Внедрите интеллектуальное сканирование, чтобы обеспечить уважение к ресурсам веб-сайта и навигацию без обнаружения.
- Используйте расширенный анализ для обработки динамического контента, гарантируя устойчивость извлечения данных к изменениям.
- Стратегически используйте службы решения CAPTCHA, чтобы поддерживать доступ, не прерывая поток данных.
- Вдумчиво управляйте IP-адресами и заголовками запросов, чтобы скрыть действия по очистке данных.
- Управляйте изменениями структуры веб-сайта, регулярно обновляя сценарии парсера.
Освоив эти методы, можно умело ориентироваться в тонкостях сканирования веб-страниц и открывать огромные хранилища ценных данных.
Управление крупномасштабными проектами парсинга
Крупномасштабные проекты парсинга веб-страниц требуют надежного управления для обеспечения эффективности и соответствия требованиям. Сотрудничество с поставщиками услуг парсинга веб-страниц дает ряд преимуществ:

Доверив парсинг-проекты профессионалам, вы сможете оптимизировать результаты и минимизировать техническую нагрузку на свою команду.
Часто задаваемые вопросы
Каковы ограничения парсинга веб-страниц?
Парсинг веб-страниц сталкивается с определенными ограничениями, которые необходимо учитывать, прежде чем включать его в свою деятельность. Юридически некоторые веб-сайты запрещают сбор данных с помощью условий или файлов robot.txt; игнорирование этих ограничений может привести к тяжелым последствиям.
Технически веб-сайты могут применять меры противодействия парсингу, такие как CAPTCHA, IP-блоки и «приманки», тем самым предотвращая несанкционированный доступ. Точность извлеченных данных также может стать проблемой из-за динамического рендеринга и часто обновляемых источников. Наконец, парсинг веб-страниц требует технических ноу-хау, инвестиций в ресурсы и постоянных усилий, что представляет собой сложную задачу, особенно для нетехнических людей.
Почему сбор данных является проблемой?
Проблемы возникают в основном тогда, когда сбор данных происходит без необходимых разрешений или этического поведения. Извлечение конфиденциальной информации нарушает нормы конфиденциальности и законы, призванные защищать индивидуальные интересы.
Чрезмерное использование парсинга перегружает целевые серверы, отрицательно влияя на производительность и доступность. Кража интеллектуальной собственности представляет собой еще одну проблему, связанную с незаконным сбором информации из-за возможных судебных исков о нарушении авторских прав, инициированных потерпевшими сторонами.
Таким образом, соблюдение политических положений, соблюдение этических стандартов и получение согласия там, где это необходимо, по-прежнему имеет решающее значение при выполнении задач по сбору данных.
Почему парсинг веб-страниц может быть неточным?
Веб-скрапинг, который предполагает автоматическое извлечение данных с веб-сайтов с помощью специализированного программного обеспечения, не гарантирует полной точности из-за различных факторов. Например, изменения в структуре веб-сайта могут привести к сбоям в работе парсера или получению ошибочной информации.
Кроме того, на некоторых веб-сайтах реализованы меры защиты от парсинга, такие как тесты CAPTCHA, блоки IP или рендеринг JavaScript, что приводит к пропущенным или искаженным данным. Иногда недосмотр разработчиков во время создания также приводит к неоптимальным результатам.
Тем не менее, партнерство с опытными поставщиками услуг парсинга веб-страниц может повысить точность, поскольку они предоставляют необходимые ноу-хау и ресурсы для создания надежных и шустрых парсеров, способных поддерживать высокий уровень точности, несмотря на изменение макетов веб-сайтов. Квалифицированные эксперты тщательно тестируют и проверяют эти скребки перед внедрением, гарантируя правильность на протяжении всего процесса извлечения.
Парсинг веб-страниц — это утомительно?
Действительно, участие в веб-скрапинге может оказаться трудоемким и требовательным, особенно для тех, кому не хватает опыта программирования или понимания цифровых платформ. Такие задачи требуют создания индивидуальных кодов, исправления ошибочных парсеров, администрирования серверной архитектуры и отслеживания изменений, происходящих на целевых веб-сайтах – все это требует значительных технических навыков наряду со значительными инвестициями с точки зрения затрат времени.
Выход за пределы базовых операций по парсингу веб-страниц становится все более сложным, учитывая соображения, связанные с соблюдением нормативных требований, управлением полосой пропускания и внедрением распределенных вычислительных систем.
Напротив, выбор профессиональных услуг по парсингу веб-страниц существенно снижает сопутствующую нагрузку благодаря готовым предложениям, разработанным в соответствии с конкретными требованиями пользователя. Следовательно, клиенты концентрируются в первую очередь на использовании собранных данных, оставляя логистику сбора специализированным командам, состоящим из квалифицированных разработчиков и ИТ-специалистов, отвечающих за оптимизацию системы, распределение ресурсов и решение юридических вопросов, тем самым заметно уменьшая общее утомление, связанное с инициативами по очистке веб-страниц.