
Веб-сканер Python – пошаговое руководство
Опубликовано: 2023-12-07Веб-сканеры — это увлекательные инструменты в мире сбора данных и парсинга веб-страниц. Они автоматизируют процесс навигации по Интернету для сбора данных, которые можно использовать для различных целей, таких как индексирование поисковыми системами, интеллектуальный анализ данных или конкурентный анализ. В этом уроке мы отправимся в информативное путешествие по созданию базового веб-сканера с использованием Python, языка, известного своей простотой и мощными возможностями обработки веб-данных.
Python с его богатой экосистемой библиотек обеспечивает отличную платформу для разработки веб-сканеров. Являетесь ли вы начинающим разработчиком, энтузиастом данных или просто интересуетесь, как работают веб-сканеры, это пошаговое руководство предназначено для того, чтобы познакомить вас с основами веб-сканирования и дать вам навыки для создания собственного сканера. .
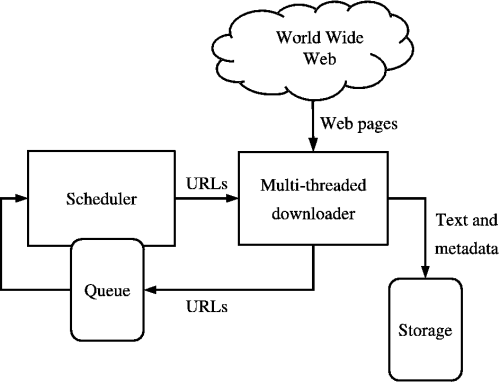
Источник: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659.
Веб-сканер Python – Как создать веб-сканер
Шаг 1: Понимание основ
Веб-сканер, также известный как паук, представляет собой программу, которая методично и автоматически просматривает Всемирную паутину. Для нашего сканера мы будем использовать Python из-за его простоты и мощных библиотек.
Шаг 2. Настройте среду
Установите Python : убедитесь, что у вас установлен Python. Вы можете скачать его с python.org.
Установите библиотеки : вам понадобятся запросы для выполнения HTTP-запросов и BeautifulSoup из bs4 для анализа HTML. Установите их с помощью pip:
Запросы на установку pip pip install beautifulsoup4
Шаг 3. Напишите базовый сканер
Импортировать библиотеки :
запросы на импорт из bs4 import BeautifulSoup
Получить веб-страницу :
Здесь мы получим содержимое веб-страницы. Замените «URL» на веб-страницу, которую вы хотите просканировать.
url = 'URL' ответ = запросы.получить(url) контент = ответ.контент
Разберите HTML-контент :
суп = BeautifulSoup(content, 'html.parser')
Извлечь информацию :
Например, чтобы извлечь все гиперссылки, вы можете сделать:
для ссылки в супе.find_all('a'): print(link.get('href'))
Шаг 4. Расширьте свой сканер
Обработка относительных URL-адресов :
Используйте urljoin для обработки относительных URL-адресов.
из urllib.parse импортировать URL-адрес
Избегайте сканирования одной и той же страницы дважды :
Поддерживайте набор посещенных URL-адресов, чтобы избежать избыточности.
Добавляем задержки :
Уважительное сканирование включает задержки между запросами. Используйте time.sleep().
Шаг 5: Соблюдайте Robots.txt
Убедитесь, что ваш сканер учитывает файл веб-сайтов robots.txt, в котором указано, какие части сайта не следует сканировать.
Шаг 6: Обработка ошибок
Внедрите блоки try-Exception для обработки потенциальных ошибок, таких как таймауты соединения или отказ в доступе.
Шаг 7: Идем глубже
Вы можете усовершенствовать свой сканер для выполнения более сложных задач, таких как отправка форм или рендеринг JavaScript. Для веб-сайтов с большим количеством JavaScript рассмотрите возможность использования Selenium.
Шаг 8: Сохраните данные
Решите, как хранить просканированные данные. Варианты включают простые файлы, базы данных или даже прямую отправку данных на сервер.
Шаг 9: Будьте этичны
- Не перегружайте серверы; добавьте задержки в ваших запросах.
- Следуйте условиям обслуживания сайта.
- Не собирайте и не храните персональные данные без разрешения.
Блокировка — распространенная проблема при сканировании веб-страниц, особенно когда речь идет о веб-сайтах, на которых предусмотрены меры для обнаружения и блокировки автоматического доступа. Вот несколько стратегий и соображений, которые помогут вам решить эту проблему в Python:
Понимание того, почему вас блокируют
Частые запросы. Быстрые повторяющиеся запросы с одного и того же IP-адреса могут вызвать блокировку.
Нечеловеческие модели поведения. Боты часто демонстрируют поведение, отличное от поведения людей, например, слишком быстрый доступ к страницам или в предсказуемой последовательности.
Неправильное управление заголовками. Отсутствующие или неправильные HTTP-заголовки могут сделать ваши запросы подозрительными.
Игнорирование файла robots.txt. Несоблюдение директив в файле robots.txt сайта может привести к блокировке.
Стратегии, позволяющие избежать блокировки
Уважайте robots.txt : всегда проверяйте файл robots.txt на веб-сайте и соблюдайте его. Это этическая практика, которая может предотвратить ненужную блокировку.
Смена пользовательских агентов . Веб-сайты могут идентифицировать вас через ваш пользовательский агент. Вращая его, вы снижаете риск быть помеченным как бот. Для реализации этого используйте библиотеку fake_useragent.
из fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}

Добавление задержек . Реализация задержки между запросами может имитировать поведение человека. Используйте time.sleep(), чтобы добавить случайную или фиксированную задержку.
время импорта time.sleep(3) # Ожидание 3 секунды
Ротация IP : Если возможно, используйте прокси-сервисы для ротации вашего IP-адреса. Для этого существуют как бесплатные, так и платные сервисы.
Использование сеансов : объект Request.Session в Python может помочь поддерживать согласованное соединение и совместно использовать заголовки, файлы cookie и т. д. между запросами, делая ваш сканер более похожим на обычный сеанс браузера.
с запросами.Session() в качестве сеанса: session.headers = {'User-Agent': ua.random} ответ = session.get(url)
Обработка JavaScript . Некоторые веб-сайты в значительной степени полагаются на JavaScript для загрузки контента. Такие инструменты, как Selenium или Puppeteer, могут имитировать реальный браузер, включая рендеринг JavaScript.
Обработка ошибок . Внедрите надежную обработку ошибок для корректного управления блокировками или другими проблемами и реагирования на них.
Этические соображения
- Всегда соблюдайте условия обслуживания веб-сайта. Если сайт явно запрещает парсинг веб-страниц, лучше подчиниться.
- Помните о влиянии вашего сканера на ресурсы веб-сайта. Перегрузка сервера может вызвать проблемы у владельца сайта.
Передовые методы
- Платформы веб-скрапинга . Рассмотрите возможность использования таких платформ, как Scrapy, которые имеют встроенные функции для решения различных проблем сканирования.
- Услуги по решению CAPTCHA . Для сайтов с проблемами CAPTCHA существуют службы, которые могут решать CAPTCHA, хотя их использование вызывает этические проблемы.
Лучшие практики веб-сканирования в Python
Участие в веб-сканировании требует баланса между технической эффективностью и этической ответственностью. При использовании Python для сканирования веб-страниц важно придерживаться лучших практик, учитывающих данные и веб-сайты, с которых они получены. Вот некоторые ключевые соображения и лучшие практики сканирования веб-страниц с помощью Python:
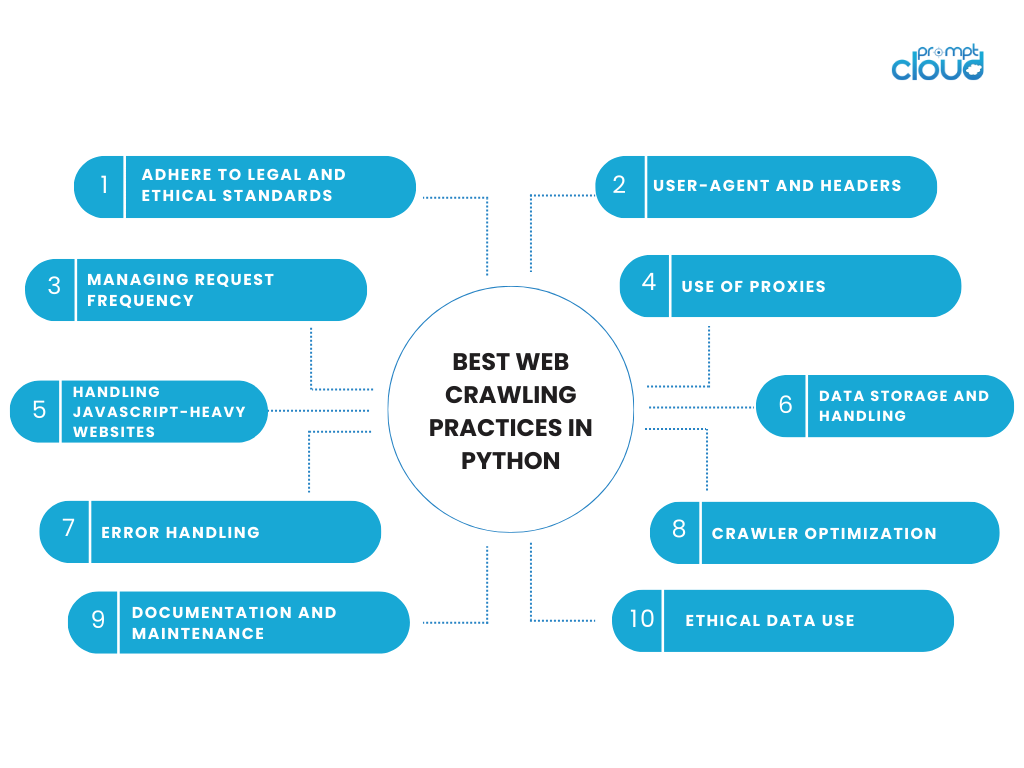
Соблюдайте правовые и этические стандарты
- Уважайте robots.txt: всегда проверяйте файл robots.txt на веб-сайте. В этом файле указаны области сайта, которые владелец сайта предпочитает не сканировать.
- Следуйте Условиям обслуживания. Многие веб-сайты включают в свои условия обслуживания положения о парсинге веб-страниц. Соблюдение этих условий является как этическим, так и юридически разумным.
- Избегайте перегрузки серверов: делайте запросы с разумной скоростью, чтобы избежать чрезмерной нагрузки на сервер веб-сайта.
Пользовательский агент и заголовки
- Идентифицируйте себя: используйте строку пользовательского агента, которая включает вашу контактную информацию или цель сканирования. Эта прозрачность может укрепить доверие.
- Используйте заголовки правильно: правильно настроенные HTTP-заголовки могут снизить вероятность блокировки. Они могут включать такую информацию, как пользовательский агент, язык принятия и т. д.
Управление частотой запросов
- Добавить задержки: реализовать задержку между запросами, чтобы имитировать шаблоны просмотра людьми. Используйте функцию Python time.sleep().
- Ограничение скорости: следите за тем, сколько запросов вы отправляете на веб-сайт в течение определенного периода времени.
Использование прокси
- Ротация IP-адресов. Использование прокси-серверов для ротации вашего IP-адреса может помочь избежать блокировки по IP-адресу, но это следует делать ответственно и этично.
Обработка веб-сайтов с большим количеством JavaScript
- Динамический контент. Для сайтов, которые динамически загружают контент с помощью JavaScript, такие инструменты, как Selenium или Puppeteer (в сочетании с Pyppeteer для Python), могут отображать страницы как браузер.
Хранение и обработка данных
- Хранение данных: ответственно храните просканированные данные, соблюдая законы и правила о конфиденциальности данных.
- Минимизируйте извлечение данных: извлекайте только те данные, которые вам нужны. Избегайте сбора личной или конфиденциальной информации, за исключением случаев, когда это абсолютно необходимо и законно.
Обработка ошибок
- Надежная обработка ошибок. Внедрите комплексную обработку ошибок для управления такими проблемами, как тайм-ауты, ошибки сервера или контент, который не загружается.
Оптимизация сканера
- Масштабируемость: спроектируйте свой сканер так, чтобы он справлялся с увеличением масштаба, как с точки зрения количества сканируемых страниц, так и объема обрабатываемых данных.
- Эффективность: оптимизируйте свой код для повышения эффективности. Эффективный код снижает нагрузку как на вашу систему, так и на целевой сервер.
Документация и обслуживание
- Сохраняйте документацию: документируйте свой код и логику сканирования для дальнейшего использования и обслуживания.
- Регулярные обновления. Постоянно обновляйте код сканирования, особенно если структура целевого веб-сайта меняется.
Использование этических данных
- Этическое использование: используйте собранные вами данные этично, соблюдая нормы конфиденциальности пользователей и использования данных.
В заключение
Завершая исследование создания веб-сканера на Python, мы рассмотрели тонкости автоматического сбора данных и связанные с этим этические соображения. Это начинание не только повышает наши технические навыки, но и углубляет наше понимание ответственного обращения с данными в огромном цифровом мире.
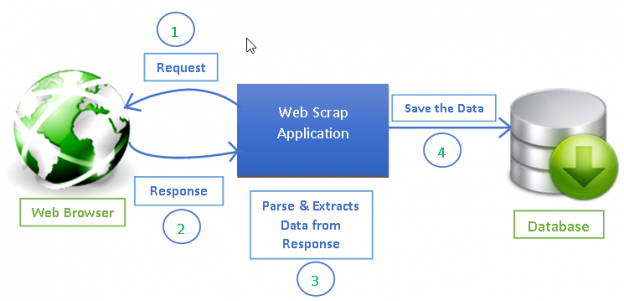
Источник: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python.
Однако создание и поддержка веб-сканера может оказаться сложной и трудоемкой задачей, особенно для компаний с особыми потребностями в крупномасштабных данных. Именно здесь в игру вступают пользовательские службы очистки веб-страниц PromptCloud. Если вы ищете индивидуальное, эффективное и этичное решение для ваших требований к веб-данным, PromptCloud предлагает ряд услуг, отвечающих вашим уникальным потребностям. От обработки сложных веб-сайтов до предоставления чистых, структурированных данных — они гарантируют, что ваши проекты по очистке веб-страниц будут простыми и соответствующими вашим бизнес-целям.
Для компаний и частных лиц, у которых может не быть времени или технических знаний для разработки и управления собственными веб-сканерами, передача этой задачи таким экспертам, как PromptCloud, может изменить правила игры. Их услуги не только экономят время и ресурсы, но и гарантируют получение наиболее точных и актуальных данных при соблюдении правовых и этических стандартов.
Хотите узнать больше о том, как PromptCloud может удовлетворить ваши конкретные потребности в данных? Свяжитесь с ними по адресу sales@promptcloud.com, чтобы получить дополнительную информацию и обсудить, как их специальные решения для парсинга веб-страниц могут помочь в развитии вашего бизнеса.
В динамичном мире веб-данных наличие надежного партнера, такого как PromptCloud, может расширить возможности вашего бизнеса, давая вам преимущество в принятии решений на основе данных. Помните, что в сфере сбора и анализа данных решающую роль играет правильный партнер.
Удачной охоты за данными!