
Выбор и настройка механизмов вывода для LLM
Опубликовано: 2024-04-02Введение в машины вывода
Существует множество методов оптимизации, разработанных для уменьшения неэффективности, возникающей на разных этапах процесса вывода. Трудно масштабировать вывод в масштабе с помощью ванильного преобразователя/методов. Механизмы вывода объединяют оптимизации в один пакет и упрощают процесс вывода.
Для очень небольшого набора специальных тестов или быстрого ознакомления мы можем использовать код ванильного преобразователя, чтобы сделать вывод.
Среда механизмов вывода быстро развивается, поскольку у нас есть множество вариантов, поэтому важно протестировать и составить краткий список лучших из лучших для конкретных случаев использования. Ниже приведены некоторые эксперименты с механизмами вывода, которые мы провели, и причины, по которым мы выяснили, почему они сработали в нашем случае.
Для нашей доработанной модели Викуна-7Б мы постарались
- ТГИ
- vLLM
- Афродита
- Оптимум-Nvidia
- PowerInfer
- ЛЛАМАКПП
- Ctranslate2
Мы просмотрели страницу GitHub и краткое руководство по настройке этих движков. PowerInfer, LlaamaCPP, Ctranslate2 не очень гибки и не поддерживают многие методы оптимизации, такие как непрерывная пакетная обработка, постраничное внимание и удержание производительности на низком уровне по сравнению с другими упомянутыми движками. .
Чтобы получить более высокую пропускную способность, механизм вывода/сервер должен максимально использовать память и вычислительные возможности, а клиент и сервер должны работать параллельным/асинхронным способом обслуживания запросов, чтобы сервер всегда работал. Как упоминалось ранее, без помощи таких методов оптимизации, как PagedAttention, Flash Attention, Continuous Batching, это всегда приведет к неоптимальной производительности.
TGI, vLLM и Aphrodite являются более подходящими кандидатами в этом отношении, и, проведя несколько экспериментов, описанных ниже, мы нашли оптимальную конфигурацию, позволяющую выжать максимальную производительность из вывода. Такие методы, как непрерывная пакетная обработка и постраничное внимание, включены по умолчанию. Для приведенных ниже тестов спекулятивное декодирование необходимо включить вручную в механизме вывода.
Сравнительный анализ машин вывода
ТГИ
Чтобы использовать TGI, мы можем пройти через раздел «Начало работы» на странице github. Здесь докер — это самый простой способ настроить и использовать движок TGI.
Аргументы средства запуска генерации текста -> этот список различных настроек, которые мы можем использовать на стороне сервера. Несколько важных,
- --max-input-length : определяет максимальную длину ввода в модель, в большинстве случаев это требует изменений, по умолчанию — 1024.
- --max-total-tokens: макс. общее количество токенов, т.е. длина входного + выходного токена.
- –speculate, –quantiz, –max-concurrent-requests -> по умолчанию только 128, что явно меньше.
Чтобы запустить локальную точно настроенную модель,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Чтобы запустить модель из хаба,
модель = «lmsys/vicuna-7b-v1.5»; объем = $ PWD/данные; token="<hf_token>"; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Вы можете попросить ChatGPT объяснить приведенную выше команду для более детального понимания. Здесь мы запускаем сервер вывода на порту 9091. И мы можем использовать клиент любого языка для отправки запроса на сервер. API вывода генерации текста -> упоминает все конечные точки и параметры полезной нагрузки для запроса.
Например
payload="<подсказка здесь>"
Curl -XPOST "0.0.0.0:9091/generate" -H "Content-Type: application/json" -d "{"входные данные": $payload, "параметры": {"max_new_tokens": 400",do_sample":false «best_of»: ноль, «repetition_penalty»: 1, «return_full_text»: false, «seed»: ноль, «stop_sequences»: ноль, «температура»: 0,1, «top_k»: 100, «top_p»: 0,3», truncate»: null, «типичный_p»: null, «водяной знак»: false, «decoder_input_details»: false}}»
Немного наблюдений,
- Задержка увеличивается с увеличением max-token-tokens, поэтому очевидно, что если мы обрабатываем длинный текст, общее время увеличится.
- Спекуляция помогает, но это зависит от варианта использования и распределения ввода-вывода.
- Квантование Eetq больше всего помогает увеличить пропускную способность.
- Если у вас несколько графических процессоров, запуск одного API на каждом графическом процессоре и наличие этих API с несколькими графическими процессорами за балансировщиком нагрузки приводит к более высокой пропускной способности, чем сегментирование самим TGI.
vLLM
Чтобы запустить сервер vLLM, мы можем использовать сервер/докер REST API, совместимый с OpenAI. Начать очень просто, следуйте инструкциям «Развертывание с помощью Docker — vLLM», если вы собираетесь использовать локальную модель, затем подключите том и используйте путь в качестве имени модели.
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – модель /модель
Выше будет запущен сервер vLLM на упомянутом порту 8000, как всегда, вы можете поиграть с аргументами.
Сделайте запрос на публикацию с помощью,
«ракушка
payload="<подсказка здесь>"
Curl -XPOST -m 1200 "0.0.0.0:8000/v1/completions" -H "Тип контента: application/json" -d "{"prompt": $payload",model":"/model" ,max_tokens «: 400», «top_p»: 0,3, «top_k»: 100, «температура»: 0,1}»
«`
Афродита
«ракушка
pip установить aphrodite-engine
python -m aphrodite.endpoints.openai.api_server –модель PygmalionAI/pygmalion-2-7b
«`
Или
«`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc хост alpindale/aphrodite-engine
«`
Aphrodite обеспечивает установку как pip, так и docker, как указано в разделе «Начало работы». Docker, как правило, относительно проще развернуть и протестировать. Параметры использования и параметры сервера помогают нам делать запросы.

- И Aphrodite, и vLLM используют полезные нагрузки на основе сервера openAI, поэтому вы можете проверить их документацию.
- Мы попробовали deepspeed-mii, так как он находится в переходном состоянии (когда мы пробовали) от устаревшего кода к новой, он не выглядит надежным и простым в использовании.
- Optimum-NVIDIA не поддерживает другие основные оптимизации и приводит к неоптимальной производительности, ссылка по ссылке.
- Добавлена суть кода, который мы использовали для выполнения специальных параллельных запросов.
Метрики и измерения
Мы хотим попробовать и найти:
- Оптимально нет. потоков для клиента/сервера механизма вывода.
- Как растет пропускная способность за счет увеличения памяти
- Как растет пропускная способность по отношению к тензорным ядрам.
- Влияние потоков на параллельные запросы клиента.
Самый простой способ наблюдать за использованием — это наблюдать за ним с помощью Linux utils nvidia-smi, nvtop, это покажет нам занятую память, использование вычислительных ресурсов, скорость передачи данных и т. д.
Другой способ — профилировать процесс с помощью графического процессора с помощью nsys.
| С.Нет | графический процессор | виртуальная оперативная память | Механизм логического вывода | Потоки | Время (с) | Спекулировать |
| 1 | А6000 | 48/48 ГБ | ТГИ | 24 | 664 | – |
| 2 | А6000 | 48/48 ГБ | ТГИ | 64 | 561 | – |
| 3 | А6000 | 48/48 ГБ | ТГИ | 128 | 554 | – |
| 4 | А6000 | 48/48 ГБ | ТГИ | 256 | 568 | – |
Основываясь на приведенных выше экспериментах, поток 128/256 лучше, чем поток с меньшим номером, а накладные расходы, превышающие 256, начинают способствовать снижению пропускной способности. Установлено, что это зависит от процессора и графического процессора и требует собственного эксперимента. | ||||||
| 5 | А6000 | 48/48 ГБ | ТГИ | 128 | 596 | 2 |
| 6 | А6000 | 48/48 ГБ | ТГИ | 128 | 945 | 8 |
Более высокое спекулятивное значение приводит к большему количеству отклонений для нашей точно настроенной модели и, следовательно, к снижению пропускной способности. 1/2 в качестве спекулятивного значения — это нормально, это зависит от модели и не гарантируется, что будет работать одинаково в разных вариантах использования. Но вывод таков: спекулятивное декодирование повышает пропускную способность. | ||||||
| 7 | 3090 | 24/24 ГБ | ТГИ | 128 | 741 | 2 |
| 7 | 4090 | 24/24 ГБ | ТГИ | 128 | 481 | 2 |
Несмотря на то, что 4090 имеет меньше видеопамяти по сравнению с A6000, он превосходит его по производительности за счет большего количества тензорных ядер и скорости полосы пропускания памяти. | ||||||
| 8 | А6000 | 24/48 ГБ | ТГИ | 128 | 707 | 2 |
| 9 | А6000 | 2 х 24/48 ГБ | ТГИ | 128 | 1205 | 2 |
Установка и настройка TGI для высокой пропускной способности
Настройте асинхронные запросы на выбранном языке сценариев, например Python/Ruby, и используя тот же файл для конфигурации, который мы нашли:
- Затраченное время увеличивается относительно максимальной выходной длины генерации последовательности.
- 128/256 потоков на клиенте и сервере лучше, чем 24, 64, 512. При использовании нижних потоков вычислительные ресурсы используются недостаточно, а за порогом, например 128, накладные расходы становятся выше, и, следовательно, пропускная способность снижается.
- Улучшение на 6 % при переходе от асинхронных запросов к параллельным с использованием «параллельного GNU» вместо многопоточности в таких языках, как Go, Python/Ruby.
- 4090 имеет пропускную способность на 12% выше, чем A6000. Несмотря на то, что 4090 имеет меньше видеопамяти по сравнению с A6000, он превосходит его по производительности за счет большего количества тензорных ядер и скорости полосы пропускания памяти.
- Поскольку A6000 имеет 48 ГБ видеопамяти, чтобы сделать вывод, помогает ли дополнительная оперативная память улучшить производительность или нет, мы попытались использовать части памяти графического процессора в эксперименте 8 таблицы. Мы видим, что дополнительная оперативная память помогает улучшить производительность, но не линейно. Кроме того, при попытке разделения, то есть размещения двух API на одном графическом процессоре с использованием половины памяти для каждого API, он ведет себя как два последовательных API вместо параллельного приема запросов.
Наблюдения и показатели
Ниже приведены графики некоторых экспериментов и времени, необходимого для завершения фиксированного набора входных данных. Чем меньше затраченное время, тем лучше.
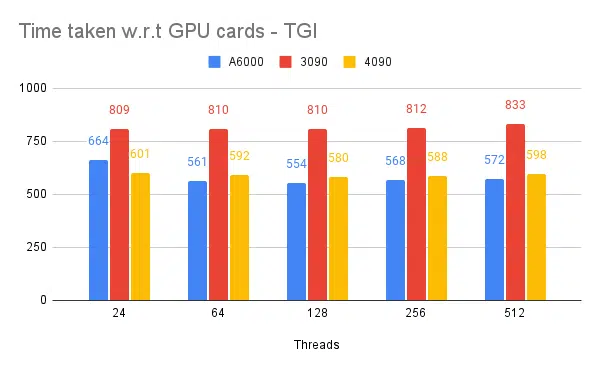
- Упоминаются потоки на стороне клиента. О серверной части нам нужно упомянуть при запуске механизма вывода.
Спекулятивное тестирование:

Тестирование нескольких машин вывода:
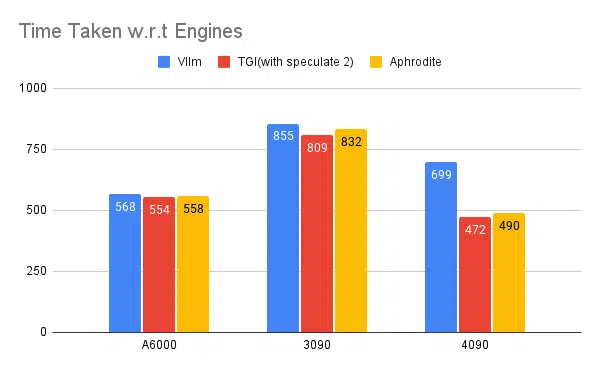
Аналогичные эксперименты, проведенные с другими движками, такими как vLLM и Aphrodite, мы наблюдаем аналогичные результаты: на момент написания этой статьи vLLM и Aphrodite еще не поддерживают спекулятивное декодирование, что заставляет нас выбрать TGI, поскольку он обеспечивает более высокую пропускную способность, чем остальная часть. к спекулятивному декодированию.
Кроме того, вы можете настроить профилировщики графического процессора для повышения наблюдаемости, помогая выявлять области с чрезмерным использованием ресурсов и оптимизируя производительность. Читайте далее: Инструменты разработчика Nvidia Nsight — Макс Кац
Заключение
Мы видим, что сфера генерации логических выводов постоянно развивается, и повышение пропускной способности в LLM требует хорошего понимания графического процессора, показателей производительности, методов оптимизации и проблем, связанных с задачами генерации текста. Это помогает правильно выбрать инструменты для работы. Понимая внутренние особенности графического процессора и то, как они соответствуют выводам LLM, например, задействуя тензорные ядра и максимизируя пропускную способность памяти, разработчики могут выбрать экономичный графический процессор и эффективно оптимизировать производительность.
Различные карты графического процессора предлагают разные возможности, и понимание различий имеет решающее значение для выбора наиболее подходящего оборудования для конкретных задач. Такие методы, как непрерывная пакетная обработка, постраничное внимание, объединение ядер и флэш-внимание, предлагают многообещающие решения для преодоления возникающих проблем и повышения эффективности. Судя по экспериментам и полученным результатам, TGI выглядит лучшим выбором для нашего варианта использования.
Прочтите другие статьи, связанные с большой языковой моделью:
Понимание архитектуры графического процессора для оптимизации вывода LLM
Передовые методы повышения производительности LLM