
Пошаговое руководство по созданию веб-сканера
Опубликовано: 2023-12-05В сложной сети Интернета, где информация разбросана по бесчисленным веб-сайтам, веб-сканеры выступают в роли незамеченных героев, усердно работающих над организацией, индексированием и обеспечением доступа к этому богатству данных. Эта статья посвящена исследованию веб-сканеров, проливает свет на их фундаментальную работу, различает веб-сканирование и веб-скрапинг, а также предоставляет практические идеи, такие как пошаговое руководство по созданию простого веб-сканера на основе Python. По мере того, как мы копнем глубже, мы раскроем возможности передовых инструментов, таких как Scrapy, и узнаем, как PromptCloud поднимает сканирование веб-страниц до промышленных масштабов.
Что такое веб-краулер
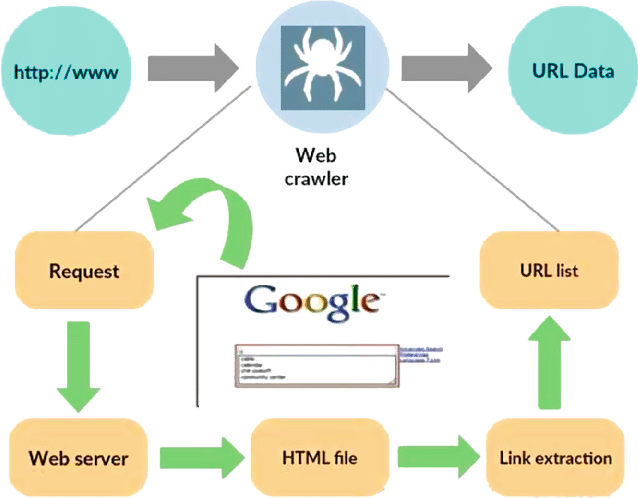
Источник: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973.
Веб-сканер, также известный как паук или бот, представляет собой специализированную программу, предназначенную для систематического и автономного перемещения по обширным просторам Всемирной паутины. Его основная функция — просматривать веб-сайты, собирать данные и индексировать информацию для различных целей, таких как поисковая оптимизация, индексирование контента или извлечение данных.
По своей сути веб-сканер имитирует действия пользователя-человека, но гораздо быстрее и эффективнее. Он начинает свое путешествие с назначенной отправной точки, часто называемой начальным URL-адресом, а затем следует по гиперссылкам с одной веб-страницы на другую. Этот процесс перехода по ссылкам является рекурсивным, что позволяет сканеру исследовать значительную часть Интернета.
Когда сканер посещает веб-страницы, он систематически извлекает и сохраняет соответствующие данные, которые могут включать текст, изображения, метаданные и многое другое. Извлеченные данные затем систематизируются и индексируются, что упрощает поисковым системам поиск и представление соответствующей информации пользователям при запросе.
Веб-сканеры играют ключевую роль в работе поисковых систем, таких как Google, Bing и Yahoo. Постоянно и систематически сканируя Интернет, они обеспечивают актуальность индексов поисковых систем, предоставляя пользователям точные и релевантные результаты поиска. Кроме того, веб-сканеры используются в различных других приложениях, включая агрегирование контента, мониторинг веб-сайтов и интеллектуальный анализ данных.
Эффективность веб-сканера зависит от его способности перемещаться по разнообразным структурам веб-сайтов, обрабатывать динамический контент и соблюдать правила, установленные веб-сайтами через файл robots.txt, в котором указано, какие части сайта можно сканировать. Понимание того, как работают веб-сканеры, имеет основополагающее значение для понимания их важности в обеспечении доступности и организации огромной сети информации.
Как работают веб-сканеры
Веб-сканеры, также известные как пауки или боты, осуществляют систематический процесс навигации по Всемирной паутине для сбора информации с веб-сайтов. Вот обзор того, как работают веб-сканеры:
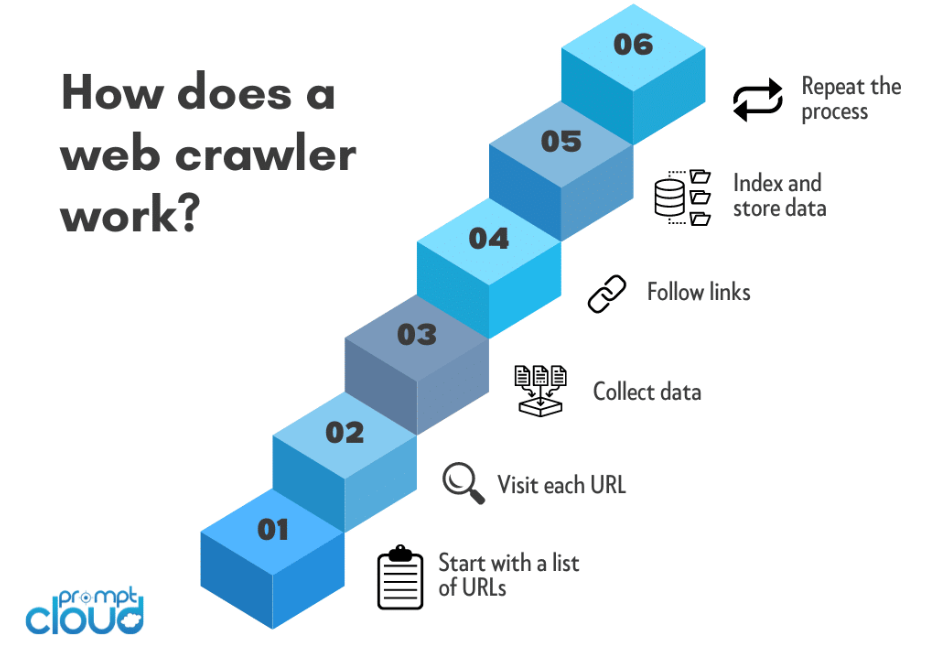
Выбор начального URL-адреса:
Процесс веб-сканирования обычно начинается с начального URL-адреса. Это начальная веб-страница или веб-сайт, с которого сканер начинает свой путь.
HTTP-запрос:
Сканер отправляет HTTP-запрос на исходный URL-адрес, чтобы получить HTML-содержимое веб-страницы. Этот запрос аналогичен запросам веб-браузеров при доступе к веб-сайту.
HTML-парсинг:
После получения содержимого HTML сканер анализирует его для извлечения соответствующей информации. Это предполагает разбиение HTML-кода на структурированный формат, по которому сканер может перемещаться и анализировать.
Извлечение URL-адреса:
Сканер идентифицирует и извлекает гиперссылки (URL), присутствующие в содержимом HTML. Эти URL-адреса представляют собой ссылки на другие страницы, которые сканер посетит впоследствии.
Очередь и планировщик:
Извлеченные URL-адреса добавляются в очередь или планировщик. Очередь гарантирует, что сканер посещает URL-адреса в определенном порядке, часто сначала отдавая приоритет новым или непосещенным URL-адресам.
Рекурсия:
Сканер следует по ссылкам в очереди, повторяя процесс отправки HTTP-запросов, анализа содержимого HTML и извлечения новых URL-адресов. Этот рекурсивный процесс позволяет сканеру перемещаться по нескольким слоям веб-страниц.
Извлечение данных:
Когда сканер перемещается по сети, он извлекает соответствующие данные с каждой посещенной страницы. Тип извлекаемых данных зависит от цели сканера и может включать текст, изображения, метаданные или другой конкретный контент.
Индексирование контента:
Собранные данные систематизируются и индексируются. Индексирование предполагает создание структурированной базы данных, которая упрощает поиск, получение и представление информации, когда пользователи отправляют запросы.
Уважая Robots.txt:
Веб-сканеры обычно придерживаются правил, указанных в файле robots.txt веб-сайта. В этом файле содержатся рекомендации о том, какие области сайта можно сканировать, а какие следует исключить.
Задержки сканирования и вежливость:
Чтобы избежать перегрузки серверов и сбоев, сканеры часто включают механизмы задержки сканирования и вежливости. Эти меры гарантируют, что сканер взаимодействует с веб-сайтами уважительно и без помех.
Веб-сканеры систематически перемещаются по сети, переходя по ссылкам, извлекая данные и создавая организованный индекс. Этот процесс позволяет поисковым системам предоставлять пользователям точные и релевантные результаты на основе их запросов, что делает веб-сканеры фундаментальным компонентом современной интернет-экосистемы.

Веб-сканирование против веб-скрапинга

Источник: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Хотя веб-сканирование и веб-скрапинг часто используются взаимозаменяемо, они служат разным целям. Сканирование веб-страниц предполагает систематическое перемещение по сети для индексации и сбора информации, тогда как парсинг веб-страниц направлен на извлечение конкретных данных с веб-страниц. По сути, веб-сканирование — это исследование и картирование сети, тогда как веб-скрапинг — это сбор целевой информации.
Создание веб-сканера
Создание простого веб-сканера на Python включает в себя несколько шагов: от настройки среды разработки до написания логики сканера. Ниже приведено подробное руководство, которое поможет вам создать базовый веб-сканер с помощью Python, используя библиотеку запросов для создания HTTP-запросов и BeautifulSoup для анализа HTML.
Шаг 1: Настройте среду
Убедитесь, что в вашей системе установлен Python. Вы можете скачать его с python.org. Дополнительно вам потребуется установить необходимые библиотеки:
pip install requests beautifulsoup4
Шаг 2. Импортируйте библиотеки
Создайте новый файл Python (например, simple_crawler.py) и импортируйте необходимые библиотеки:
import requests from bs4 import BeautifulSoup
Шаг 3. Определите функцию сканера
Создайте функцию, которая принимает URL-адрес в качестве входных данных, отправляет HTTP-запрос и извлекает соответствующую информацию из содержимого HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Шаг 4. Проверьте краулер
Предоставьте образец URL-адреса и вызовите функцию simple_crawler, чтобы протестировать сканер:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Шаг 5. Запустите сканер
Запустите скрипт Python в терминале или командной строке:
python simple_crawler.py
Сканер получит HTML-содержимое предоставленного URL-адреса, проанализирует его и распечатает заголовок. Вы можете расширить искатель, добавив дополнительные функции для извлечения различных типов данных.
Веб-сканирование с помощью Scrapy
Сканирование веб-страниц с помощью Scrapy открывает двери к мощной и гибкой среде, разработанной специально для эффективного и масштабируемого парсинга веб-страниц. Scrapy упрощает создание веб-сканеров, предлагая структурированную среду для создания пауков, которые могут перемещаться по веб-сайтам, извлекать данные и систематически хранить их. Вот более детальный взгляд на сканирование веб-страниц с помощью Scrapy:
Монтаж:
Прежде чем начать, убедитесь, что у вас установлен Scrapy. Вы можете установить его, используя:
pip install scrapy
Создание Scrapy-проекта:
Начать Scrapy-проект:
Откройте терминал и перейдите в каталог, в котором вы хотите создать проект Scrapy. Выполните следующую команду:
scrapy startproject your_project_name
Это создает базовую структуру проекта с необходимыми файлами.
Дайте определение пауку:
Внутри каталога проекта перейдите в папку Spiders и создайте файл Python для вашего паука. Определите класс паука, создав подкласс Scrapy.Spider и предоставив необходимые сведения, такие как имя, разрешенные домены и начальные URL-адреса.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Извлечение данных:
Использование селекторов:
Scrapy использует мощные селекторы для извлечения данных из HTML. Вы можете определить селекторы в методе синтаксического анализа паука для захвата определенных элементов.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
В этом примере извлекается текстовое содержимое тега <title>.
Следующие ссылки:
Scrapy упрощает процесс перехода по ссылкам. Используйте следующий метод для перехода на другие страницы.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Запуск паука:
Запустите своего паука, используя следующую команду из каталога проекта:
scrapy crawl your_spider
Scrapy запустит паука, перейдет по ссылкам и выполнит логику анализа, определенную в методе анализа.
Сканирование веб-страниц с помощью Scrapy предлагает надежную и расширяемую основу для решения сложных задач по сбору данных. Его модульная архитектура и встроенные функции делают его предпочтительным выбором для разработчиков, участвующих в сложных проектах по извлечению веб-данных.
Веб-сканирование в больших масштабах
Сканирование веб-страниц в больших масштабах представляет собой уникальные проблемы, особенно при работе с огромным объемом данных, распределенных по многочисленным веб-сайтам. PromptCloud — это специализированная платформа, предназначенная для упрощения и оптимизации процесса сканирования веб-страниц в любом масштабе. Вот как PromptCloud может помочь в реализации крупномасштабных инициатив по сканированию веб-страниц:
- Масштабируемость
- Извлечение и обогащение данных
- Качество и точность данных
- Управление инфраструктурой
- Простота использования
- Соблюдение требований и этика
- Мониторинг и отчетность в режиме реального времени
- Поддержка и обслуживание
PromptCloud — это надежное решение для организаций и частных лиц, стремящихся осуществлять масштабное сканирование веб-страниц. Решая ключевые проблемы, связанные с крупномасштабным извлечением данных, платформа повышает эффективность, надежность и управляемость инициатив по веб-сканированию.
В итоге
Сетевые сканеры являются незамеченными героями на огромном цифровом пространстве, усердно перемещаясь по сети для индексации, сбора и систематизации информации. По мере расширения масштабов проектов веб-сканирования PromptCloud выступает в качестве решения, предлагая масштабируемость, обогащение данных и соблюдение этических норм для оптимизации крупномасштабных инициатив. Свяжитесь с нами по адресу sales@promptcloud.com .