
Роль парсинга веб-страниц в повышении точности модели ИИ
Опубликовано: 2023-12-27Искусственный интеллект постоянно развивается, чему способствуют огромные данные, необходимые для совершенствования машинного обучения. Этот процесс обучения включает в себя распознавание закономерностей и принятие обоснованных решений.
Введите парсинг веб-страниц — жизненно важный игрок в сборе данных. Он включает в себя извлечение обширной информации с веб-сайтов — сокровищницы для обучения моделей ИИ. Гармония между искусственным интеллектом и парсингом веб-страниц подчеркивает суть современного машинного обучения, основанную на данных. По мере развития ИИ растет потребность в разнообразных наборах данных, в результате чего парсинг веб-страниц становится незаменимым активом для разработчиков, создающих более точные и эффективные системы ИИ.
Эволюция веб-скрапинга: от ручного к искусственному интеллекту
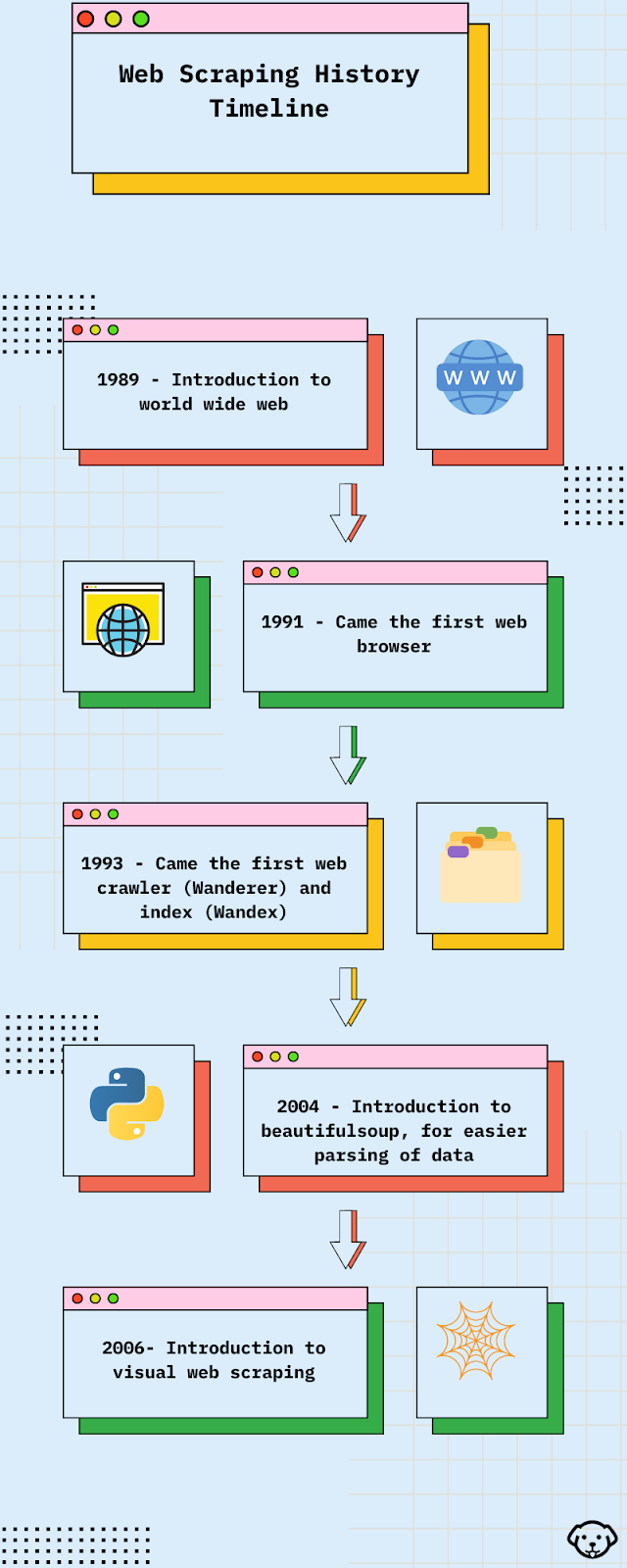
Развитие парсинга веб-страниц отражает технологические достижения. Ранние методы были базовыми и требовали ручного извлечения данных — задача, зачастую отнимающая много времени и подверженная ошибкам. Поскольку Интернет быстро расширялся, эти методы не могли идти в ногу с растущим объемом данных. Для автоматизации парсинга были введены скрипты и боты, но им не хватало сложности.
Познакомьтесь с искусственным интеллектом для парсинга веб-страниц, который произведет революцию в сборе данных. Машинное обучение теперь позволяет анализировать сложные, неструктурированные данные и эффективно их осмысливать. Этот сдвиг не только ускоряет сбор данных, но и повышает качество извлекаемых данных, позволяя использовать более сложные приложения и обеспечивая более богатую питательную среду для моделей ИИ, которые постоянно учатся на обширных, детализированных наборах данных.
Источник изображения: https://www.scrapingdog.com/
Понимание технологий искусственного интеллекта в парсинге веб-страниц
Благодаря искусственному интеллекту инструменты парсинга веб-страниц стали более мощными. ИИ автоматизирует распознавание образов при извлечении данных, что делает процесс более быстрым и точным в выявлении соответствующей информации. Веб-парсеры, управляемые искусственным интеллектом, могут:
- Адаптируйтесь к различным макетам веб-сайтов с помощью машинного обучения, тем самым уменьшая необходимость в разработке шаблонов вручную.
- Используйте обработку естественного языка (NLP) для понимания и классификации текстовых данных, повышая качество собранных данных.
- Используйте возможности распознавания изображений для извлечения визуального контента, что может иметь решающее значение в определенных контекстах анализа данных.
- Внедряйте алгоритмы обнаружения аномалий для выявления выбросов и ошибок извлечения данных и управления ими, обеспечивая целостность данных.
Благодаря возможностям ИИ парсинг веб-страниц становится более мощным и адаптируемым, удовлетворяя обширные требования к данным современных передовых моделей ИИ.
Роль машинного обучения в интеллектуальном извлечении данных
Машинное обучение совершает революцию в извлечении данных, позволяя системам независимо распознавать, понимать и извлекать соответствующую информацию. Ключевые вклады включают:
- Распознавание образов . Алгоритмы машинного обучения превосходно распознают закономерности и аномалии в больших наборах данных, что делает их идеальными для выявления соответствующих точек данных во время парсинга веб-страниц.
- Обработка естественного языка (НЛП) . Используя НЛП, машинное обучение может понимать и интерпретировать человеческий язык, облегчая извлечение информации из неструктурированных источников данных, таких как социальные сети.
- Адаптивное обучение . Поскольку модели машинного обучения подвергаются воздействию большего количества данных, они обучаются и повышают свою точность, гарантируя, что процесс извлечения данных со временем станет более эффективным.
- Уменьшение человеческих ошибок . Благодаря машинному обучению вероятность ошибок, связанных с извлечением данных вручную, значительно снижается, что повышает качество набора данных для моделей ИИ.
Источник изображения: https://research.aimultiple.com/
Распознавание образов на основе искусственного интеллекта для эффективного парсинга
Парсинг веб-страниц играет жизненно важную роль в удовлетворении растущего спроса на данные в моделях машинного обучения. На переднем плане находится распознавание образов на основе искусственного интеллекта, оптимизирующее извлечение данных с поразительной эффективностью. Этот передовой метод идентифицирует и классифицирует огромные объемы данных с минимальным участием человека.
Используя сложные алгоритмы, ИИ, очищающий веб-страницы, быстро перемещается по веб-страницам, распознавая закономерности и извлекая структурированные наборы данных. Эти автоматизированные системы не только работают быстрее, но и значительно повышают точность, сводя к минимуму ошибки по сравнению с ручными методами очистки. По мере развития ИИ его способность распознавать сложные закономерности будет продолжать менять ландшафт веб-скрапинга и сбора данных.
Обработка естественного языка для агрегирования контента
Важнейшая функция обработки естественного языка (NLP) выходит на первый план при агрегации контента, позволяя системам искусственного интеллекта эффективно понимать, интерпретировать и организовывать данные. Он даёт парсерам возможность отличать важную информацию от ненужной болтовни. Анализируя семантику и синтаксику текста, НЛП классифицирует контент, извлекает ключевые сущности и обобщает информацию.

Эти очищенные данные становятся основополагающим учебным материалом для моделей, которые учатся распознавать закономерности, предугадывать запросы пользователей и давать содержательные ответы. Следовательно, агрегирование контента на основе НЛП имеет решающее значение для разработки более умных, контекстно-зависимых моделей ИИ. Это облегчает целенаправленный подход к сбору данных, улучшая исходные данные, которые удовлетворяют ненасытный аппетит современного ИИ.
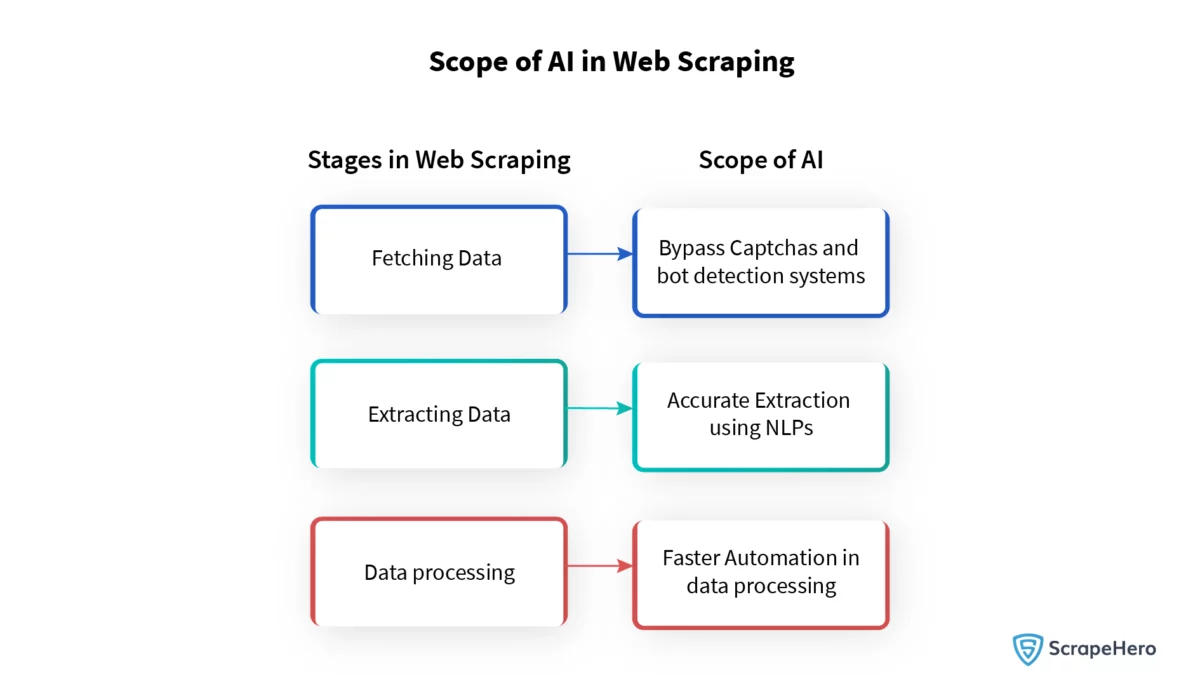
Преодоление проблем с капчами и динамическим контентом с помощью ИИ
Капчи и динамический контент представляют собой серьезные препятствия для эффективного парсинга веб-страниц. Эти механизмы предназначены для того, чтобы различать пользователей-людей и автоматизированные сервисы, что часто мешает сбору данных. Однако достижения в области искусственного интеллекта привели к появлению сложных решений:
- Алгоритмы машинного обучения значительно улучшили интерпретацию визуальных капч, имитируя способности распознавания образов человека.
- Инструменты на основе искусственного интеллекта теперь могут адаптироваться к динамическому контенту, изучая структуры страниц и прогнозируя изменения местоположения данных.
- Некоторые системы используют генеративно-состязательные сети (GAN) для обучения моделей, способных решать сложные капчи.
- Методы обработки естественного языка (NLP) помогают понять семантику динамически генерируемых текстов, способствуя точному извлечению данных.
По мере того, как между создателями капч и разработчиками ИИ разворачивается продолжающаяся борьба, каждому шагу в технологии капчи противостоят более проницательные и ловкие контрмеры, основанные на искусственном интеллекте. Такое динамическое взаимодействие обеспечивает бесперебойный поток данных, способствуя неустанному расширению индустрии искусственного интеллекта.
Повышение качества и точности данных за счет возможностей приложений искусственного интеллекта
Приложения искусственного интеллекта (ИИ) значительно повышают качество и точность данных, что имеет решающее значение для обучения эффективных моделей. Используя сложные алгоритмы, ИИ может:
- Обнаруживайте и устраняйте несоответствия в больших наборах данных.
- Отфильтровывайте ненужную информацию, концентрируясь на подмножествах данных, жизненно важных для понимания модели.
- Проверка данных на соответствие заранее установленным критериям качества.
- Выполняйте очистку данных в режиме реального времени, что гарантирует актуальность и точность наборов обучающих данных.
- Используйте обучение без учителя, чтобы выявить закономерности или аномалии, которые могут ускользнуть от внимания человека.
Использование ИИ при подготовке данных не только делает процесс более плавным; это повышает качество понимания, полученного на основе данных, что приводит к созданию более умных и надежных моделей ИИ.
Расширение операций по парсингу веб-страниц за счет интеграции искусственного интеллекта
Интеграция искусственного интеллекта в методы очистки веб-страниц значительно повышает эффективность и масштабируемость процессов сбора данных. Системы на базе искусственного интеллекта могут адаптироваться к различным макетам веб-сайтов и точно извлекать данные, даже если сайт претерпевает изменения. Эта адаптивность обусловлена алгоритмами машинного обучения, которые изучают закономерности и аномалии в процессе очистки.
Более того, ИИ может расставлять приоритеты и классифицировать точки данных, быстро распознавая ценную информацию. Навыки обработки естественного языка (НЛП) позволяют использовать инструменты для понимания и обработки человеческого языка, что позволяет извлекать настроения или намерения из текстовых данных. Поскольку задания по парсингу становятся все сложнее и объемнее, интеграция ИИ гарантирует, что эти задачи выполняются с меньшим ручным контролем, что приводит к более оптимизированной и экономически эффективной работе. Внедрение таких интеллектуальных систем способствует:
- Автоматизация идентификации и извлечения соответствующих данных
- Постоянное обучение и адаптация к новым веб-структурам.
- Анализ и интерпретация неструктурированных данных с помощью методов НЛП.
- Повышение точности и снижение необходимости вмешательства человека
Предстоящие тенденции: будущее искусственного интеллекта для парсинга веб-страниц
По мере того, как мы ориентируемся в постоянно развивающейся сфере искусственного интеллекта, в центре внимания становятся замечательные достижения в области искусственного интеллекта, очищающего веб-страницы. Изучите эти ключевые тенденции, формирующие будущее:
- Всеобъемлющее понимание: искусственный интеллект расширяется, чтобы понимать видео, изображения и аудио в контексте.
- Адаптивное обучение: ИИ корректирует стратегии парсинга на основе структуры веб-сайта, сокращая вмешательство человека.
- Точное извлечение данных. Алгоритмы точно настроены для точного и актуального извлечения данных.
- Бесшовная интеграция: инструменты парсинга на базе искусственного интеллекта легко интегрируются с платформами анализа данных.
- Этический сбор данных: ИИ включает этические принципы в отношении согласия пользователей и защиты данных.
Источник изображения: https://www.scrapehero.com/
Испытайте синергию парсинга веб-страниц и искусственного интеллекта для удовлетворения ваших потребностей в данных. Обратитесь в PromptCloud по адресу sales@promptcloud.com, чтобы получить передовые услуги по очистке веб-страниц, которые повысят точность ваших моделей искусственного интеллекта.
Часто задаваемые вопросы:
Может ли ИИ выполнять парсинг веб-страниц?
Конечно, ИИ хорошо справляется с задачами по парсингу веб-страниц. Оснащенные передовыми алгоритмами, системы искусственного интеллекта могут самостоятельно просматривать веб-сайты, выявлять закономерности и извлекать соответствующие данные с заметной эффективностью. Эта возможность знаменует собой значительный прогресс, повышая скорость, точность и гибкость процедур извлечения данных.
Является ли парсинг веб-страниц незаконным?
Когда дело доходит до законности парсинга веб-страниц, здесь возникает множество нюансов. Сам по себе парсинг веб-страниц не является незаконным по своей сути, но законность зависит от того, как он выполняется. Ответственный и этичный сбор данных, соответствующий условиям обслуживания целевых веб-сайтов, имеет решающее значение во избежание юридических осложнений. Очень важно подходить к парсингу веб-страниц осознанно и с пониманием.
Может ли ChatGPT выполнять парсинг веб-страниц?
Что касается ChatGPT, он не занимается сбором веб-страниц. Его сильная сторона заключается в понимании и генерации естественного языка, обеспечивая ответы на основе получаемых входных данных. Для реальных задач по парсингу веб-страниц необходимы специализированные инструменты и программы.
Сколько стоит парсер AI?
При рассмотрении стоимости услуг парсинга ИИ важно учитывать такие переменные, как сложность задачи парсинга, объем извлекаемых данных и конкретные потребности в настройке. Модели ценообразования могут включать единовременную плату, планы подписки или плату в зависимости от использования. Чтобы получить индивидуальное предложение, соответствующее вашим требованиям, рекомендуется обратиться к поставщику услуг веб-скрапинга, например PromptCloud.