
Понимание архитектуры графического процессора для оптимизации вывода LLM
Опубликовано: 2024-04-02Введение в LLM и важность оптимизации графического процессора
В современную эпоху достижений в области обработки естественного языка (NLP) модели больших языков (LLM) стали мощными инструментами для решения множества задач, от генерации текста до ответов на вопросы и обобщения. Это нечто большее, чем просто генератор токенов следующего вероятного уровня. Однако растущая сложность и размер этих моделей создают серьезные проблемы с точки зрения вычислительной эффективности и производительности.
В этом блоге мы углубляемся в тонкости архитектуры графического процессора, изучая, как различные компоненты способствуют выводу LLM. Мы обсудим ключевые показатели производительности, такие как пропускная способность памяти и использование тензорных ядер, а также выясним различия между различными графическими картами, что позволит вам принимать обоснованные решения при выборе оборудования для задач больших языковых моделей.
В быстро развивающейся среде, где задачи НЛП требуют постоянно растущих вычислительных ресурсов, оптимизация пропускной способности вывода LLM имеет первостепенное значение. Присоединяйтесь к нам, когда мы отправляемся в это путешествие, чтобы раскрыть весь потенциал LLM с помощью методов оптимизации графического процессора и углубиться в различные инструменты, которые позволяют нам эффективно повышать производительность.
Основы архитектуры графического процессора для студентов LLM — знайте внутренние компоненты своего графического процессора
Учитывая характер выполнения высокоэффективных параллельных вычислений, графические процессоры становятся предпочтительным устройством для выполнения всех задач глубокого обучения, поэтому важно понимать общий обзор архитектуры графических процессоров, чтобы понять основные узкие места, которые возникают на этапе вывода. Карты Nvidia являются предпочтительными благодаря CUDA (Compute Unified Device Architecture), собственной платформе параллельных вычислений и API, разработанному NVIDIA, который позволяет разработчикам задавать параллелизм на уровне потоков на языке программирования C, обеспечивая прямой доступ к набору виртуальных команд графического процессора и параллельным вычислительные элементы.
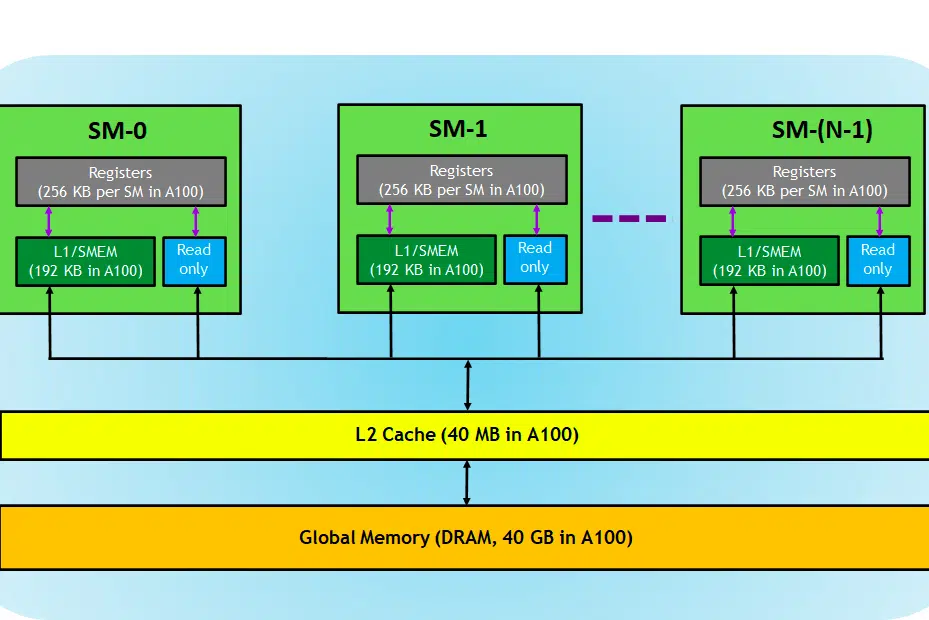
В контексте мы использовали карту NVIDIA для объяснения, поскольку она широко предпочтительна для задач глубокого обучения, как уже говорилось, и к этому применимы лишь немногие другие термины, такие как тензорные ядра.
Давайте посмотрим на карту графического процессора. Здесь, на изображении, мы видим три основные части и (еще одну важную скрытую часть) устройства графического процессора.
- SM (потоковые мультипроцессоры)
- Кэш L2
- Пропускная способность памяти
- Глобальная память (DRAM)
Точно так же, как ваш ЦП и ОЗУ играют вместе, ОЗУ — это место для хранения данных (т. е. памяти), а ЦП — для задач обработки (т. е. процессов). В графическом процессоре глобальная память с высокой пропускной способностью (DRAM) хранит веса модели (например, LLAMA 7B), которые загружаются в память, и при необходимости эти веса передаются в процессор (например, процессор SM) для вычислений.
Потоковые мультипроцессоры
Потоковый мультипроцессор или SM представляет собой набор меньших исполнительных блоков, называемых ядрами CUDA (собственная платформа параллельных вычислений NVIDIA), а также дополнительных функциональных блоков, отвечающих за выборку, декодирование, планирование и отправку инструкций. Каждый SM работает независимо и содержит собственный файл регистров, общую память, кэш L1 и текстурный блок. SM имеют высокую степень распараллеливания, что позволяет им одновременно обрабатывать тысячи потоков, что важно для достижения высокой пропускной способности при выполнении вычислительных задач на графическом процессоре. Производительность процессора обычно измеряется во FLOPS, нет. плавающих операций, которые он может выполнять каждую секунду.
Задачи глубокого обучения в основном состоят из тензорных операций, то есть умножения матриц на матрицы. NVIDIA представила тензорные ядра в графических процессорах нового поколения, которые разработаны специально для высокоэффективного выполнения этих тензорных операций. Как уже упоминалось, тензорные ядра полезны, когда речь идет о задачах глубокого обучения, и вместо ядер CUDA мы должны проверить тензорные ядра, чтобы определить, насколько эффективно графический процессор может выполнять обучение/вывод LLM.
Кэш L2
Кэш L2 — это память с высокой пропускной способностью, которая используется совместно SM и предназначена для оптимизации доступа к памяти и эффективности передачи данных внутри системы. Это меньший по размеру и более быстрый тип памяти, который расположен ближе к процессорам (например, потоковым мультипроцессорам) по сравнению с DRAM. Это помогает повысить общую эффективность доступа к памяти за счет уменьшения необходимости доступа к более медленной DRAM для каждого запроса к памяти.
Пропускная способность памяти
Итак, производительность зависит от того, насколько быстро мы сможем перенести веса из памяти в процессор и насколько эффективно и быстро процессор сможет обработать данные вычисления.
Когда вычислительная мощность выше/быстрее, чем скорость передачи данных между памятью и SM, SM будет нехватать данных для обработки и, таким образом, вычислительные ресурсы используются недостаточно. Эта ситуация, когда пропускная способность памяти ниже скорости потребления, известна как фаза привязки к памяти. . Это очень важно отметить, поскольку это преобладающее узкое место в процессе вывода.
Напротив, если обработка вычислений занимает больше времени и если в очередь для вычислений поставлено больше данных, это состояние является фазой , связанной с вычислениями .
Чтобы в полной мере воспользоваться преимуществами графического процессора, мы должны находиться в состоянии, ограниченном вычислениями, при этом делая происходящие вычисления максимально эффективными.
Память DRAM
DRAM служит основной памятью в графическом процессоре, предоставляя большой пул памяти для хранения данных и инструкций, необходимых для вычислений. Обычно он организован в иерархию с несколькими банками памяти и каналами для обеспечения высокоскоростного доступа.

Для задачи вывода DRAM графического процессора определяет, насколько большую модель мы можем загрузить, а вычислительные FLOPS и пропускная способность определяют пропускную способность, которую мы можем получить.
Сравнение видеокарт для задач LLM
Чтобы получить информацию о количестве тензорных ядер и скорости полосы пропускания, можно просмотреть технический документ, выпущенный производителем графического процессора. Вот пример,
| РТХ А6000 | РТХ 4090 | РТХ 3090 | |
| Объем памяти | 48 ГБ | 24 ГБ | 24 ГБ |
| Тип памяти | ГДДР6 | GDDR6X | |
| Пропускная способность | 768,0 ГБ/с | 1008 ГБ/сек. | 936,2 ГБ/с |
| Ядра CUDA/графический процессор | 10752 | 16384 | 10496 |
| Тензорные ядра | 336 | 512 | 328 |
| Кэш L1 | 128 КБ (на SM) | 128 КБ (на SM) | 128 КБ (на SM) |
| FP16 Нетензорный | 38,71 Тфлопс (1:1) | 82,6 | 35,58 Тфлопс (1:1) |
| FP32 Нетензорный | 38,71 Тфлопс | 82,6 | 35,58 Тфлопс |
| FP64 Нетензорный | 1210 ГФЛОПС (1:32) | 556,0 ГФЛОПС (1:64) | |
| Пиковое значение тензорных терафлопс FP16 с накоплением FP16 | 154,8/309,6 | 330,3/660,6 | 142/284 |
| Пиковое значение тензорных терафлопс FP16 с накоплением FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Пиковое значение тензорных терафлопс BF16 с FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Пиковый тензорный TF32 TFLOPS | 77,4/154,8 | 82,6/165,2 | 35,6/71 |
| Пиковые INT8 Тензорные вершины | 309,7/619,4 | 660,6/1321,2 | 284/568 |
| Пиковые тензорные вершины INT4 | 619,3/1238,6 | 1321,2/2642,4 | 568/1136 |
| Кэш L2 | 6 МБ | 72 МБ | 6 МБ |
| Шина памяти | 384 бит | 384 бит | 384 бит |
| ТМУ | 336 | 512 | 328 |
| РОП | 112 | 176 | 112 |
| Количество SM | 84 | 128 | 82 |
| RT-ядра | 84 | 128 | 82 |
Здесь мы видим, что FLOPS специально упоминается для тензорных операций. Эти данные помогут нам сравнить различные карты графического процессора и составить список подходящих для нашего варианта использования. Судя по таблице, хотя A6000 имеет в два раза больше памяти, чем 4090, тензорные флопсы и пропускная способность памяти 4090 лучше в цифрах и, следовательно, более эффективны для вывода больших языковых моделей.
Читать далее: Nvidia CUDA за 100 секунд
Заключение
В быстро развивающейся области НЛП оптимизация моделей большого языка (LLM) для задач вывода стала критически важной областью внимания. Как мы выяснили, архитектура графических процессоров играет ключевую роль в достижении высокой производительности и эффективности при выполнении этих задач. Понимание внутренних компонентов графических процессоров, таких как потоковые мультипроцессоры (SM), кэш L2, пропускная способность памяти и DRAM, необходимо для выявления потенциальных узких мест в процессах вывода LLM.
Сравнение различных графических карт NVIDIA — RTX A6000, RTX 4090 и RTX 3090 — выявляет существенные различия с точки зрения размера памяти, пропускной способности, количества CUDA и тензорных ядер, а также других факторов. Эти различия имеют решающее значение для принятия обоснованных решений о том, какой графический процессор лучше всего подходит для конкретных задач LLM. Например, в то время как RTX A6000 предлагает больший объем памяти, RTX 4090 выделяется с точки зрения тензорных FLOPS и пропускной способности памяти, что делает ее более эффективным выбором для сложных задач вывода LLM.
Оптимизация вывода LLM требует сбалансированного подхода, учитывающего как вычислительную мощность графического процессора, так и конкретные требования текущей задачи LLM. Выбор подходящего графического процессора предполагает понимание компромисса между объемом памяти, вычислительной мощностью и пропускной способностью, чтобы гарантировать, что графический процессор сможет эффективно обрабатывать веса модели и выполнять вычисления, не становясь узким местом. Поскольку область НЛП продолжает развиваться, получение информации о новейших технологиях графических процессоров и их возможностях будет иметь первостепенное значение для тех, кто хочет расширить границы возможного с помощью моделей большого языка.
Используемая терминология
- Пропускная способность:
В случае умозаключения пропускная способность — это мера того, сколько запросов/подсказок обрабатывается за определенный период времени. Пропускная способность обычно измеряется двумя способами:
- Запросов в секунду (RPS) :
- RPS измеряет количество запросов на вывод, которые модель может обработать в течение секунды. Запрос на вывод обычно включает в себя генерацию ответа или прогноза на основе входных данных.
- Для генерации LLM RPS указывает, насколько быстро модель может реагировать на входящие запросы или подсказки. Более высокие значения RPS предполагают лучшую скорость реагирования и масштабируемость для приложений, работающих в режиме реального времени или почти в реальном времени.
- Достижение высоких значений числа запросов в секунду часто требует эффективных стратегий развертывания, таких как группирование нескольких запросов вместе, чтобы амортизировать накладные расходы и максимально эффективно использовать вычислительные ресурсы.
- Токенов в секунду (TPS) :
- TPS измеряет скорость, с которой модель может обрабатывать и генерировать токены (слова или подслова) во время генерации текста.
- В контексте генерации LLM TPS отражает пропускную способность модели с точки зрения генерации текста. Это показывает, насколько быстро модель может давать последовательные и значимые ответы.
- Более высокие значения TPS подразумевают более быстрое создание текста, позволяя модели обрабатывать больше входных данных и генерировать более длинные ответы за заданный промежуток времени.
- Достижение высоких значений TPS часто предполагает оптимизацию архитектуры модели, распараллеливание вычислений и использование аппаратных ускорителей, таких как графические процессоры, для ускорения генерации токенов.
- Задержка:
Задержка в LLM относится к временной задержке между вводом и выводом во время вывода. Минимизация задержки необходима для улучшения пользовательского опыта и обеспечения взаимодействия в реальном времени в приложениях, использующих LLM. Очень важно найти баланс между пропускной способностью и задержкой в зависимости от услуги, которую нам необходимо предоставить. Низкая задержка желательна для таких случаев, как взаимодействие чат-ботов/второго пилота в реальном времени, но не обязательна для случаев массовой обработки данных, таких как повторная обработка внутренних данных.
Подробнее о передовых методах повышения производительности LLM можно прочитать здесь.