
Раскрытие потенциала ИИ при парсинге веб-сайтов: обзор
Опубликовано: 2024-02-02Сегодня парсинг веб-страниц превратился из нишевого программирования в важный бизнес-инструмент. Первоначально парсинг представлял собой ручной процесс, когда люди копировали данные с веб-страниц. Эволюция технологий привела к появлению автоматизированных сценариев, которые могли извлекать данные более эффективно, хотя и грубо.
По мере того, как веб-сайты становились более продвинутыми, методы парсинга также развивались, адаптируясь к сложным структурам и сопротивляясь мерам по борьбе с парсингом. Прогресс в области искусственного интеллекта и машинного обучения вывел парсинг веб-страниц на неизведанные территории, обеспечивая контекстуальное понимание и адаптируемые подходы, имитирующие поведение человека в Интернете. Этот непрерывный прогресс определяет, как организации используют веб-данные в масштабе и с беспрецедентной сложностью.
Появление ИИ в парсинге веб-страниц

Источник изображения: https://www.scrapehero.com/
Влияние искусственного интеллекта (ИИ) на парсинг веб-страниц невозможно переоценить; это абсолютно изменило ситуацию, сделав процесс более эффективным. Прошли времена кропотливой ручной настройки и постоянной бдительности, чтобы адаптироваться к меняющейся структуре веб-сайта.
Теперь, благодаря искусственному интеллекту, веб-скраперы превратились в интуитивно понятные инструменты, способные учиться на шаблонах и автономно приспосабливаться к структурным изменениям без постоянного контроля со стороны человека. Это означает, что они могут понимать контекст данных, с поразительной точностью определяя, что важно, и оставляя позади все постороннее.
Этот более интеллектуальный и гибкий метод изменил процесс извлечения данных, предоставив отраслям инструменты для принятия более обоснованных решений, основанных на первоклассном качестве данных. По мере развития технологии искусственного интеллекта ее включение в инструменты парсинга веб-страниц может установить новые стандарты, фундаментально изменяющие суть того, как мы собираем информацию из Интернета.
Этические и юридические аспекты современного парсинга веб-страниц
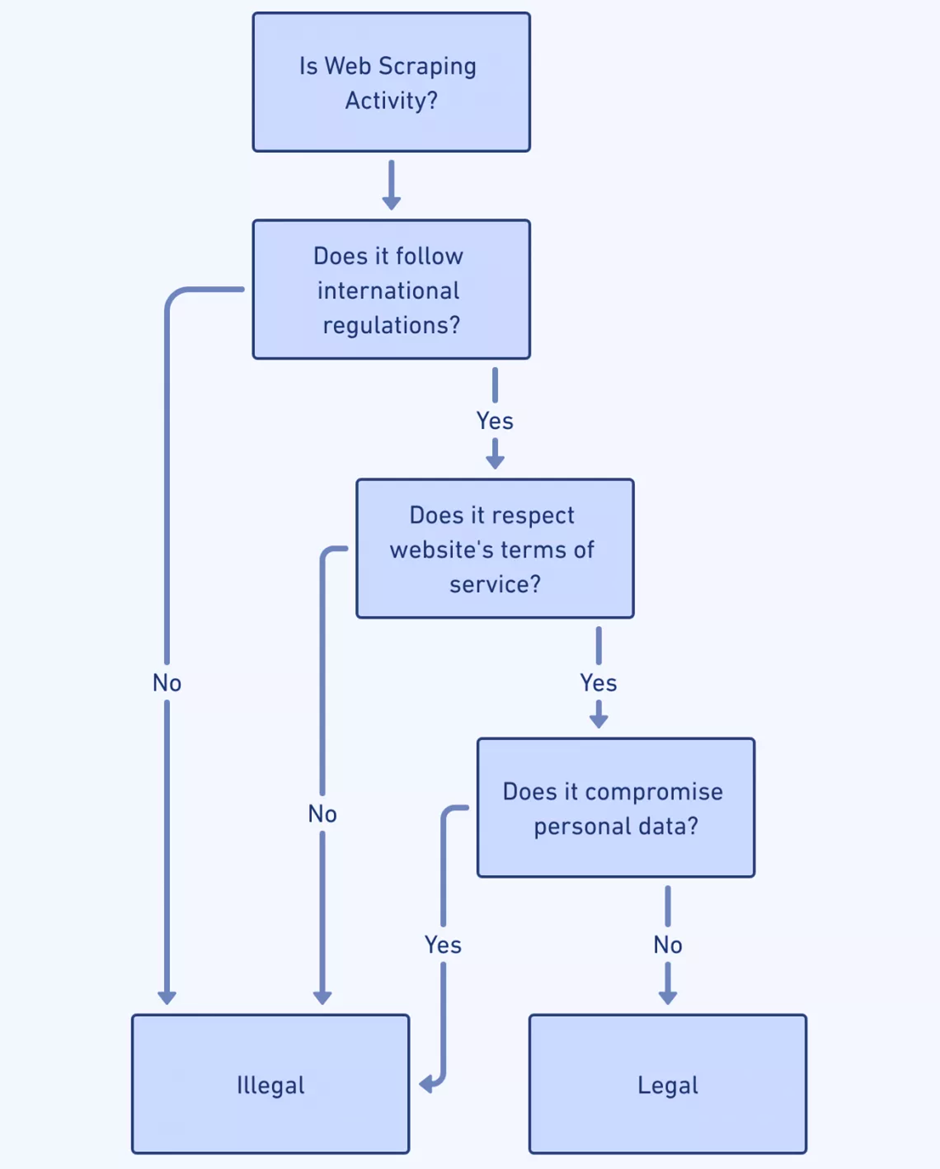
По мере того, как парсинг веб-страниц развивается вместе с развитием искусственного интеллекта, этические и юридические последствия становятся более сложными. Веб-скраперы должны ориентироваться:
- Законы о конфиденциальности данных . Разработчики парсеров должны понимать такие законы, как GDPR и CCPA, чтобы избежать юридических нарушений, связанных с личными данными.
- Соблюдение условий обслуживания . Соблюдение условий обслуживания веб-сайта имеет решающее значение; парсинг, противоречащий этим правилам, может привести к судебному разбирательству или отказу в доступе.
- Материал, защищенный авторским правом : полученный контент не должен нарушать авторские права, что вызывает опасения по поводу распространения и использования собранных данных.
- Стандарт исключения роботов . Соблюдение файла robots.txt веб-сайтов свидетельствует об этическом поведении, поскольку мы уважаем предпочтения владельца сайта в отношении парсинга.
- Согласие пользователя : когда речь идет о личных данных, обеспечение получения согласия пользователя сохраняет этическую целостность.
- Прозрачность : четкое информирование о целях и объеме операций по сбору информации способствует созданию атмосферы доверия и подотчетности.
Источник изображения: https://scrape-it.cloud/
Учет этих соображений требует бдительности и приверженности этическим нормам.
Достижения в алгоритмах искусственного интеллекта для расширенного извлечения данных
В последнее время мы наблюдаем заметную эволюцию алгоритмов ИИ, значительно меняющую ландшафт возможностей извлечения данных. Усовершенствованные модели машинного обучения, демонстрирующие улучшенную способность расшифровывать сложные закономерности, подняли точность извлечения данных до беспрецедентного уровня.

Достижения в области обработки естественного языка (НЛП) углубили контекстуальное понимание, не только облегчив извлечение соответствующей информации, но и позволив интерпретировать тонкие семантические нюансы и чувства.
Появление нейронных сетей, в частности сверточных нейронных сетей (CNN), вызвало революцию в извлечении данных изображений. Этот прорыв позволяет искусственному интеллекту не только распознавать, но и классифицировать визуальный контент, полученный из огромных просторов Интернета.
Более того, обучение с подкреплением (RL) представило новую парадигму, в которой инструменты ИИ со временем совершенствуют оптимальные стратегии очистки, тем самым повышая их операционную эффективность. Интеграция этих алгоритмов в инструменты парсинга веб-страниц привела к:
- Сложная интерпретация и анализ данных
- Улучшенная адаптируемость к разнообразным веб-структурам.
- Снижение необходимости вмешательства человека для выполнения сложных задач.
- Повышенная эффективность при обработке крупномасштабного извлечения данных.
Преодоление препятствий: CAPTCHA, динамический контент и качество данных
Технология парсинга веб-страниц должна преодолеть несколько препятствий:
- CAPTCHA : Парсеры веб-сайтов с использованием искусственного интеллекта теперь используют передовые алгоритмы распознавания изображений и машинного обучения для решения CAPTCHA с более высокой точностью, обеспечивая доступ без вмешательства человека.
- Динамический контент : парсеры веб-сайтов с искусственным интеллектом предназначены для интерпретации JavaScript и AJAX, которые генерируют динамический контент, гарантируя, что данные из веб-приложений будут собираться так же эффективно, как и со статических страниц.

Источник изображения: PromptCloud
- Качество данных . Внедрение ИИ привело к улучшению идентификации и классификации данных. Это необходимо для того, чтобы собранная информация была актуальной и высокого качества, что снижает необходимость ручной очистки и проверки. Парсеры веб-сайтов с использованием искусственного интеллекта постоянно учатся различать шум и ценные данные, совершенствуя процесс извлечения данных.
Объединение искусственного интеллекта с аналитикой больших данных в веб-скрапинге
Интеграция искусственного интеллекта (ИИ) с аналитикой больших данных представляет собой революционный шаг вперед в парсинге веб-страниц. В этой интеграции:
- Алгоритмы искусственного интеллекта используются для интерпретации и анализа огромных наборов данных, собранных с помощью парсинга, что позволяет получать ценную информацию с беспрецедентной скоростью.
- Элементы машинного обучения в рамках ИИ могут еще больше улучшить извлечение данных, научившись эффективно выявлять и экстраполировать закономерности и информацию.
- Аналитика больших данных может затем обрабатывать эту информацию, предоставляя предприятиям полезную информацию.
- Кроме того, ИИ помогает в очистке и структурировании данных, что является важным шагом для эффективного использования анализа больших данных.
- Эта синергия между искусственным интеллектом и аналитикой больших данных при парсинге веб-страниц имеет решающее значение для оперативного принятия решений и поддержания конкурентных преимуществ.
Будущее: прогнозы и потенциал для парсеров веб-сайтов с использованием искусственного интеллекта
Сфера парсинга веб-сайтов с помощью ИИ находится на значительном пороге трансформации. Прогнозы указывают на:
- Расширенные когнитивные возможности, позволяющие парсерам интерпретировать сложные данные с человеческим пониманием.
- Интеграция с другими технологиями искусственного интеллекта, такими как обработка естественного языка, для более детального извлечения данных.
- Самообучающиеся парсеры, которые совершенствуют свои методы на основе показателей успеха, создавая более эффективные протоколы сбора данных.
- Более строгое соблюдение этических и правовых стандартов благодаря передовым алгоритмам соответствия.
- Сотрудничество парсеров искусственного интеллекта и технологий блокчейна для безопасных и прозрачных транзакций данных.
Свяжитесь с нами сегодня по адресу sales@promptcloud.com, чтобы узнать, как наша передовая технология очистки веб-сайтов с использованием искусственного интеллекта может революционизировать ваши процессы извлечения данных и поднять вашу организацию на новые высоты!