
Проблемы и решения парсинга веб-страниц: преодоление сложностей
Опубликовано: 2023-09-13Веб-скрапинг стал бесценным методом извлечения данных с веб-сайтов. Если вам нужно собрать информацию для исследовательских целей, отслеживать цены или тенденции или автоматизировать определенные онлайн-задачи, парсинг веб-страниц может сэкономить вам время и усилия. Навигация по тонкостям веб-сайтов и решение различных проблем, связанных с парсингом веб-страниц, может оказаться непростой задачей. В этой статье мы углубимся в упрощение процесса парсинга веб-страниц, получив полное представление о нем. Мы рассмотрим необходимые шаги: выбор подходящих инструментов, определение целевых данных, навигацию по структурам веб-сайта, обработку аутентификации и проверки подлинности, а также обработку динамического контента.
Понимание веб-скрапинга
Веб-скрапинг — это процедура извлечения данных с веб-сайтов посредством анализа и анализа кода HTML и CSS. Он включает в себя отправку HTTP-запросов на веб-страницы, получение содержимого HTML и последующее извлечение соответствующей информации. Хотя ручное парсинг веб-страниц путем проверки исходного кода и копирования данных является возможным вариантом, он часто неэффективен и отнимает много времени, особенно при сборе обширных данных.
Для автоматизации процесса парсинга веб-страниц можно использовать языки программирования, такие как Python, и библиотеки, такие как Beautiful Soup или Selenium, а также специальные инструменты парсинга веб-страниц, такие как Scrapy или Beautiful Soup. Эти инструменты предлагают функциональные возможности для взаимодействия с веб-сайтами, анализа HTML и эффективного извлечения данных.
Проблемы со парсингом веб-страниц
Выбор подходящих инструментов
Выбор правильных инструментов имеет решающее значение для успеха вашего проекта по парсингу веб-страниц. Вот некоторые соображения при выборе инструментов для вашего проекта парсинга веб-страниц:
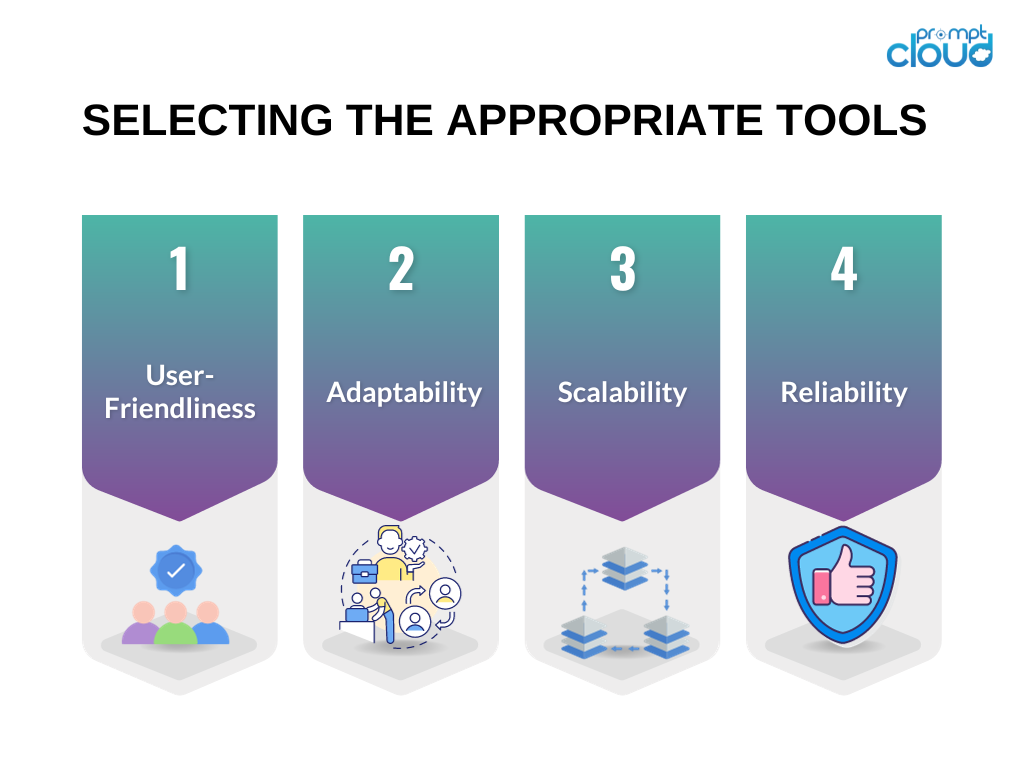
Удобство для пользователя . Отдавайте предпочтение инструментам с удобным интерфейсом или тем, которые предоставляют четкую документацию и практические примеры.
Адаптивность : выбирайте инструменты, способные обрабатывать различные типы веб-сайтов и адаптироваться к изменениям в их структурах.
Масштабируемость . Если ваша задача по сбору данных включает в себя значительный объем данных или требует расширенных возможностей веб-скрапинга, рассмотрите инструменты, которые могут обрабатывать большие объемы и предлагают функции параллельной обработки.
Надежность . Убедитесь, что инструменты оснащены средствами управления различными типами ошибок, такими как тайм-ауты соединения или ошибки HTTP, и оснащены встроенными механизмами обработки ошибок.
Основываясь на этих критериях, для проектов парсинга веб-страниц часто рекомендуются широко используемые инструменты, такие как Beautiful Soup и Selenium.
Определение целевых данных
Прежде чем начать проект парсинга веб-страниц, важно определить целевые данные, которые вы хотите извлечь с веб-сайта. Это может быть информация о продукте, новостные статьи, публикации в социальных сетях или любой другой тип контента. Понимание структуры целевого веб-сайта имеет решающее значение для эффективного извлечения нужных данных.
Чтобы идентифицировать целевые данные, вы можете использовать инструменты разработчика браузера, такие как Chrome DevTools или Firefox Developer Tools. Эти инструменты позволяют вам проверять HTML-структуру веб-страницы, идентифицировать конкретные элементы, содержащие нужные вам данные, и понимать селекторы CSS или выражения XPath, необходимые для извлечения этих данных.

Навигация по структурам веб-сайта
Веб-сайты могут иметь сложную структуру с вложенными элементами HTML, динамическим содержимым JavaScript или запросами AJAX. Навигация по этим структурам и извлечение соответствующей информации требует тщательного анализа и стратегий.
Вот несколько методов, которые помогут вам ориентироваться в сложных структурах веб-сайта:
Используйте селекторы CSS или выражения XPath . Понимая структуру HTML-кода, вы можете использовать селекторы CSS или выражения XPath для выбора конкретных элементов и извлечения нужных данных.
Обработка нумерации страниц . Если целевые данные распределены по нескольким страницам, вам необходимо реализовать нумерацию страниц, чтобы очистить всю информацию. Это можно сделать путем автоматизации процесса нажатия кнопок «Далее» или «Загрузить еще» или путем создания URL-адресов с различными параметрами.
Работа с вложенными элементами . Иногда целевые данные вложены в несколько уровней HTML-элементов. В таких случаях вам необходимо пройти через вложенные элементы, используя отношения родитель-потомок или родственные отношения, чтобы извлечь нужную информацию.
Обработка аутентификации и капчи
Некоторые веб-сайты могут требовать аутентификацию или представление капч, чтобы предотвратить автоматическое сканирование. Чтобы преодолеть эти проблемы с парсингом веб-страниц, вы можете использовать следующие стратегии:
Управление сеансом : поддерживайте состояние сеанса с помощью файлов cookie или токенов для выполнения требований аутентификации.
Подмена пользовательского агента : эмулируйте различные пользовательские агенты, чтобы они выглядели как обычные пользователи и избегали обнаружения.
Службы решения капчи . Используйте сторонние службы, которые могут автоматически решать капчи от вашего имени.
Имейте в виду, что хотя аутентификацию и капчи можно обойти, вам следует убедиться, что ваши действия по очистке веб-страниц соответствуют условиям обслуживания веб-сайта и юридическим ограничениям.
Работа с динамическим контентом
Веб-сайты часто используют JavaScript для динамической загрузки контента или получения данных с помощью запросов AJAX. Традиционные методы парсинга веб-страниц могут не фиксировать этот динамический контент. Для обработки динамического контента рассмотрите следующие подходы:
Используйте автономные браузеры . Такие инструменты, как Selenium, позволяют вам программно управлять реальными веб-браузерами и взаимодействовать с динамическим контентом.
Используйте библиотеки веб-скрапинга . Некоторые библиотеки, такие как Puppeteer или Scrapy-Splash, могут обрабатывать рендеринг JavaScript и извлечение динамического контента.
Используя эти методы, вы можете гарантировать, что сможете парсить веб-сайты, которые в значительной степени полагаются на JavaScript для доставки контента.
Реализация обработки ошибок
Парсинг веб-страниц — не всегда гладкий процесс. Веб-сайты могут изменять свою структуру, возвращать ошибки или налагать ограничения на очистку данных. Чтобы снизить риски, связанные с этими проблемами парсинга веб-страниц, важно реализовать механизмы обработки ошибок:
Отслеживайте изменения веб-сайта . Регулярно проверяйте, не изменилась ли структура или макет веб-сайта, и соответствующим образом корректируйте свой парсинг-код.
Механизмы повтора и тайм-аута . Реализуйте механизмы повтора и тайм-аута для корректной обработки периодических ошибок, таких как тайм-ауты соединения или ошибки HTTP.
Регистрируйте и обрабатывайте исключения . Регистрируйте и обрабатывайте различные типы исключений, например ошибки синтаксического анализа или сбои сети, чтобы предотвратить полный сбой процесса очистки.
Внедряя методы обработки ошибок, вы можете обеспечить надежность и надежность вашего кода веб-скрапинга.
Краткое содержание
В заключение, задачи парсинга веб-страниц можно упростить, если понять процесс, выбрать правильные инструменты, определить целевые данные, перемещаться по структурам веб-сайта, обрабатывать аутентификацию и проверку подлинности, работать с динамическим контентом и внедрять методы обработки ошибок. Следуя этим рекомендациям, вы сможете преодолеть сложности парсинга веб-страниц и эффективно собирать необходимые данные.