
Что такое извлечение данных: руководство для начинающих
Опубликовано: 2023-11-07В эпоху, когда данные так же ценны, как и валюта, способность эффективно извлекать эти данные может выделить ваш бизнес среди конкурентов. Извлечение данных — это не просто технический процесс; это стратегический подход, который, если все сделано правильно, может раскрыть информацию, ведущую к более разумным бизнес-решениям и устойчивому росту. В этом сообщении блога рассказывается о том, что, почему и как происходит извлечение данных, и дает вам знания, позволяющие использовать весь его потенциал.
Что такое извлечение данных
Извлечение данных — это процесс извлечения структурированных или неструктурированных данных из различных источников, таких как базы данных, веб-сайты, документы, изображения и т. д. Эти данные затем преобразуются в более управляемый и удобный формат, такой как электронная таблица или база данных. Цель состоит в том, чтобы собрать эту информацию таким образом, чтобы сохранить ее значение и сделать ее доступной для анализа и бизнес-аналитики.
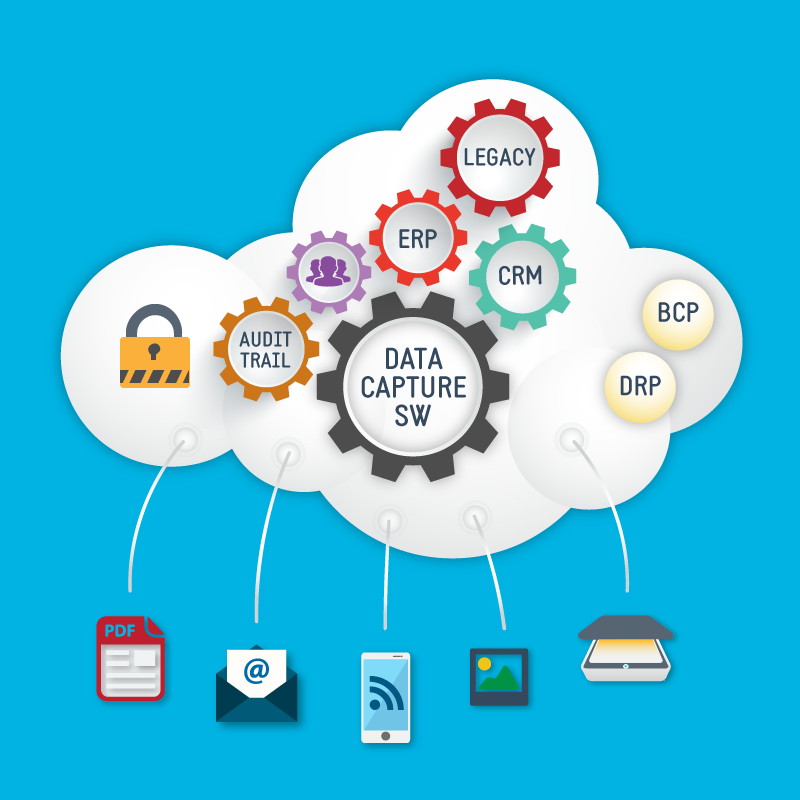
Источник: https://papersoft-dms.com/
Почему извлечение данных имеет решающее значение
- Принятие обоснованных решений. Извлеченные данные обеспечивают основу для аналитики, которая может выявлять тенденции, прогнозировать результаты и направлять стратегические решения.
- Эффективность: автоматизация процессов извлечения данных экономит время и ресурсы, устраняя ручные ошибки и избыточность.
- Интеграция: позволяет объединять данные из разрозненных источников, обеспечивая целостное представление операций.
- Конкурентное преимущество. Быстрый доступ к нужным данным может стать преимуществом, необходимым бизнесу для того, чтобы опередить конкурентов.
Типы извлечения данных
В насыщенном информацией мире, в котором мы живем, способность эффективно извлекать данные из различных источников неоценима. Процессы извлечения данных различаются не только по методологии, но и по применению. Понимание типов извлечения данных поможет вам выбрать метод, соответствующий вашим потребностям в данных.
1. Ручное извлечение данных
Ручное извлечение данных является наиболее простой формой, предполагающей участие человека для сбора данных из физических или цифровых источников. Этот метод часто медленный и подвержен ошибкам, но может быть полезен при работе со сложной информацией, требующей человеческого суждения.
2. Автоматизированное извлечение данных
Этот тип использует программное обеспечение и инструменты для автоматического сбора и обработки данных, что значительно ускоряет процесс и снижает вероятность ошибок.
3. Извлечение веб-данных (парсинг веб-страниц)
Веб-скрапинг — это метод, используемый для извлечения данных с веб-сайтов. Это делается с помощью программного обеспечения, которое имитирует работу человека в Интернете для сбора конкретной информации из онлайн-источников.
4. Извлечение структурированных данных
Этот тип относится к поиску данных, организованных в структурированном формате, например в базах данных или электронных таблицах, где данные согласованы и следуют определенной схеме.
5. Извлечение неструктурированных данных
Неструктурированное извлечение данных касается данных, которые не соответствуют определенному формату или структуре, например электронные письма, PDF-файлы или мультимедиа.
6. Извлечение полуструктурированных данных
Полуструктурированное извлечение данных предназначено для данных, которые не находятся в реляционной базе данных, но имеют некоторые организационные свойства, что упрощает анализ, чем неструктурированные данные.
7. Извлечение данных на основе запросов
Этот метод предполагает использование запросов для получения данных из баз данных. Это высокоэффективная форма извлечения структурированных данных, которая может обеспечить извлечение информации в реальном времени или по расписанию.
Методы извлечения данных
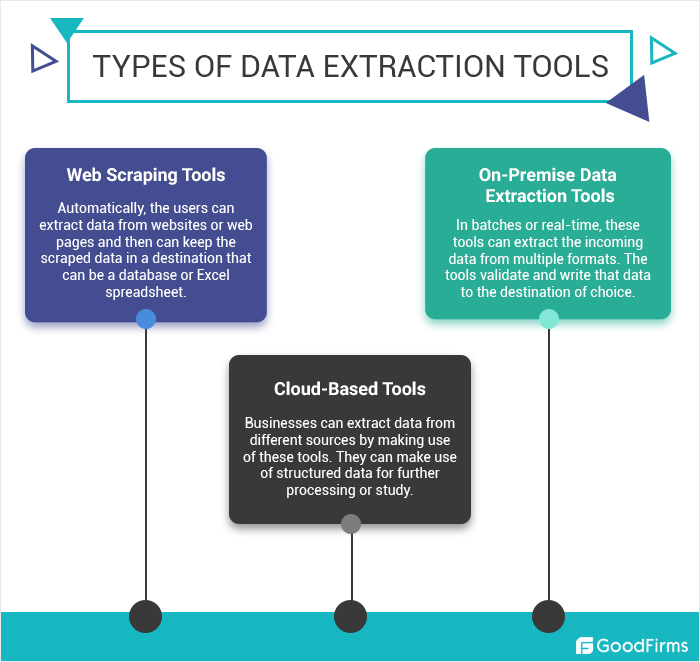
- Автоматический сбор данных: инструменты, которые автоматически обнаруживают и извлекают соответствующую информацию из документов или веб-страниц.
- Веб-скрапинг: использование программного обеспечения для имитации исследования Интернета человеком для сбора конкретных данных.
- Текстовая аналитика: использование обработки естественного языка для извлечения информации из неструктурированного текста.
- Процессы ETL: расшифровываются как «Извлечение, Преобразование, Загрузка». Это интегрированные системы, которые извлекают данные из различных источников, преобразуют их в полезный формат и сохраняют в хранилище данных.
Лучшие практики эффективного извлечения данных
- Определите четкие цели: знайте, что вам нужно от усилий по извлечению данных, чтобы выбрать правильные инструменты и методы.
- Обеспечьте качество данных: проверяйте и очищайте ваши данные в рамках процесса извлечения для обеспечения целостности.
- Соблюдайте требования: ознакомьтесь с законами и положениями о конфиденциальности данных, чтобы гарантировать, что ваши методы извлечения данных являются законными.
- Масштабируемость. Выбирайте решения, которые могут расти вместе с вашими потребностями в данных, чтобы избежать будущих изменений.
Проблемы извлечения данных
Извлечение данных, хотя и бесценно, представляет собой множество проблем, которые могут усложнить процесс как для бизнеса, так и для частных лиц. Эти проблемы могут повлиять на качество, скорость и эффективность инициатив, основанных на данных. Ниже мы углубимся в некоторые распространенные препятствия, возникающие в процессе извлечения данных.

- Проблемы качества данных:
- Несогласованные данные. Извлечение данных из различных источников часто означает наличие несоответствий в формате, структуре и качестве, что может привести к получению неточных наборов данных.
- Неполные данные. Отсутствие значений или неполные записи во время извлечения могут исказить результаты аналитики.
- Дубликаты. Во время извлечения могут возникнуть избыточные данные, что приведет к неэффективности и искажению результатов анализа.
- Проблемы масштабируемости:
- Объем. По мере роста объемов данных становится все сложнее извлекать информацию своевременно и эффективно без ущерба для производительности системы.
- Развитие данных. Непрерывное развитие данных требует масштабируемого процесса извлечения, который может адаптироваться к изменениям без необходимости обширной реконфигурации.
- Сложные и разнообразные источники данных:
- Разнообразие. Для извлечения данных из широкого спектра источников в разных форматах (PDF-файлы, веб-страницы, базы данных и т. д.) требуются универсальные и сложные инструменты извлечения.
- Доступность. Доступ к данным, заблокированным в устаревших системах или в проприетарных форматах, может быть особенно сложным для доступа и извлечения.
- Технические ограничения:
- Трудности интеграции. Интеграция извлеченных данных в существующие системы может создать технические проблемы, особенно при работе с различными технологиями или устаревшей инфраструктурой.
- Недостаток опыта: часто приходится долго учиться инструментам и методам, необходимым для эффективного извлечения данных, требуя специальных знаний.
- Юридические вопросы и вопросы соответствия:
- Правила конфиденциальности. Соблюдение строгих законов о конфиденциальности данных, таких как GDPR или HIPAA, может усложнить процесс извлечения, поскольку для некоторых данных могут потребоваться дополнительные протоколы обработки.
- Интеллектуальная собственность. При извлечении данных из внешних источников существует риск нарушения прав интеллектуальной собственности, что может привести к юридическим осложнениям.
- Извлечение данных в реальном времени:
- Задержка. Растет потребность в извлечении данных в реальном времени в определенных секторах, таких как финансы или безопасность, где задержка может существенно повлиять на принятие решений.
- Инфраструктура. Извлечение данных в режиме реального времени требует надежной инфраструктуры, способной обрабатывать непрерывные потоки данных без узких мест.
- Преобразование данных:
- Преобразование формата: Извлеченные данные часто необходимо преобразовать в другой формат для анализа, что может быть сложным и подверженным ошибкам процессом.
- Сохранение контекста. Обеспечение того, чтобы данные сохраняли свое значение после извлечения и преобразования, имеет решающее, но сложное значение, особенно при работе с неструктурированными данными.
- Проблемы безопасности:
- Утечки данных: всегда существует риск утечки данных при извлечении чувствительной или конфиденциальной информации, что требует строгих мер безопасности.
- Повреждение данных. Данные могут быть повреждены во время извлечения из-за ошибок программного обеспечения, проблем совместимости или сбоев оборудования.
Заключение
Извлечение данных, являющееся основой процесса анализа данных, может показаться сложной задачей, но при правильном подходе оно становится катализатором понимания и возможностей. Понимая его принципы и используя современные технологии, любая организация может раскрыть весь потенциал своих данных.