
Что такое маркировка данных в машинном обучении и как она работает?
Опубликовано: 2022-04-29Данные — это новое богатство для современного бизнеса. Благодаря тому, что такие технологии, как искусственный интеллект, постепенно берут на себя большую часть нашей повседневной деятельности, правильное использование любых данных оказывает положительное влияние на общество. Эффективно разделяя и маркируя данные, алгоритмы машинного обучения могут обнаруживать проблемы и предлагать практические и актуальные решения.
С помощью маркировки данных мы обучаем машину различным приемам и вводим информацию в различных форматах, чтобы она вел себя «умно». Наука, стоящая за маркировкой данных, включает в себя множество домашних заданий в виде аннотирования или маркировки наборов данных несколькими вариантами одной и той же информации. Хотя окончательный результат удивляет и облегчает нашу повседневную жизнь, труд, стоящий за ним, огромен, а самоотверженность достойна похвалы.
Что такое маркировка данных?
В машинном обучении качество и тип входных данных определяют качество и тип вывода. Качество данных, используемых для обучения машины, повышает точность вашей модели ИИ.
Другими словами, маркировка данных — это процесс обучения машины находить различия и сходства между неструктурированными или структурированными наборами данных путем их маркировки или аннотирования.
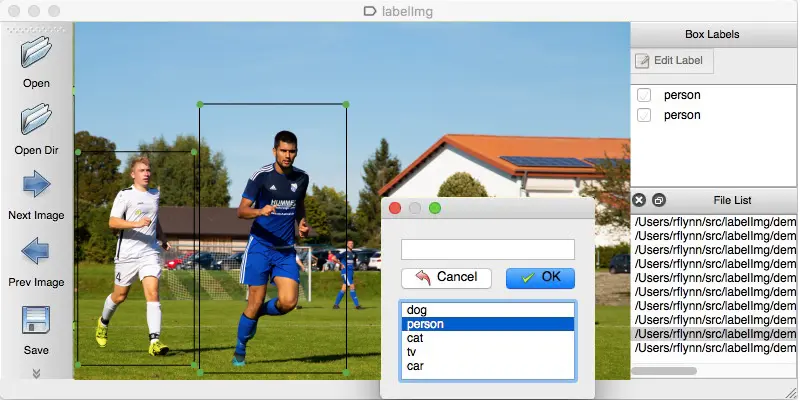
Давайте разберемся в этом на примере. Чтобы обучить машину тому, что красный свет является знаком остановки, вам необходимо пометить все красные огни на различных картинках, чтобы машина могла понять сигнал. На основе этого ИИ создает алгоритм, который будет считывать красный свет как стоп-сигнал в каждом заданном сценарии. Другой пример: музыкальные жанры можно разделить с помощью нескольких наборов данных под ярлыками джаз, поп, рок, классика и т. д.
Проблемы с маркировкой данных
Любые новые изменения/улучшения в технологии или структуре приносят свои преимущества и проблемы. То же самое и с маркировкой данных. Хотя маркировка данных может значительно сократить время на масштабирование бизнеса , она сопряжена с затратами. Остановимся на некоторых проблемах, связанных с маркировкой данных.
Стоимость с точки зрения времени и усилий
Само по себе получение данных по конкретным нишам в огромных количествах является сложной задачей. Добавление тегов вручную для каждого элемента только увеличивает и без того трудоемкую задачу. Если проект выполняется собственными силами, большая часть проектного времени тратится на задачи, связанные с данными, такие как сбор, подготовка и маркировка данных.
Чтобы эффективно справляться с этими задачами и выполнять работу с первого раза, вам потребуются опытные этикетировщики с этим конкретным опытом. Это также дорогостоящее мероприятие, что делает его затратным не только с точки зрения времени, но и денег.
непоследовательность
Аннотаторы с разным опытом могут иметь разные критерии маркировки. Следовательно, существует высокая вероятность несовместимости тегов. При этом, когда несколько человек маркируют один и тот же набор данных, показатели точности данных будут намного выше.
Экспертиза домена
Для конкретных отраслей вы почувствуете необходимость найма этикетировщиков с опытом работы в конкретной области. Например, при создании приложения машинного обучения для сферы здравоохранения аннотаторам, не имеющим соответствующего опыта в предметной области, будет очень сложно правильно пометить элементы.
Несовершенства
Любая повторяющаяся работа, выполняемая людьми, подвержена ошибкам. Каким бы уровнем знаний ни обладал человек, наносящий ярлыки, ручная маркировка всегда будет несовершенна. Обеспечить отсутствие ошибок практически невозможно, поскольку аннотаторам приходится иметь дело с большими наборами необработанных данных для маркировки.
Подходы к маркировке данных
Как упоминалось выше, маркировка данных — трудоемкая задача, требующая внимания к деталям. В зависимости от постановки задачи, количества данных, которые должны быть помечены, сложности данных и стиля, стратегия, применяемая для аннотирования данных, будет различаться.
Давайте рассмотрим различные подходы, которые ваша компания может выбрать в зависимости от финансовых ресурсов и доступного времени.
Маркировка внутренних данных
В зависимости от типа отрасли, наличия времени для завершения данного проекта ИИ и наличия необходимых ресурсов, организация может выполнять процесс маркировки данных самостоятельно.
Плюсы:
- Высокая точность
- Высокого качества
- Упрощенное отслеживание
Минусы:
- Отнимает много времени/медленно
- Требуют обширных ресурсов
Краудсорсинг
Наборы исходных данных, помеченные фрилансерами, доступны на различных краудсорсинговых платформах. Этот метод можно использовать для аннотирования обобщенных данных, таких как изображения.
Самый известный пример маркировки данных с помощью краудсорсинга — Recaptcha. Пользователя просят определить определенные типы изображений, чтобы доказать, что это люди. Они проверяются на основе данных, предоставленных другими пользователями. Это действует как база данных меток для массива изображений.
Плюсы:
- Быстро и просто
- Экономически эффективным
Минусы:
- Нельзя использовать для данных, требующих экспертных знаний в предметной области.
- Качество не гарантируется
Аутсорсинг
Аутсорсинг может выступать промежуточным звеном между внутренней маркировкой данных и краудсорсингом. Наем сторонних организаций или отдельных лиц, обладающих знаниями в предметной области, может помочь организациям во всех долгосрочных и краткосрочных проектах.
Плюсы:
- Оптимально для временных проектов высокого уровня
- Сторонние аутсорсинговые компании предоставляют проверенный персонал
- Предоставляет как готовые, так и настраиваемые инструменты маркировки данных в соответствии с потребностями вашего бизнеса.
- Можно получить возможность специалистов по маркировке данных в конкретной нише
Минусы:
- Управление третьей стороной может занять много времени
Машинный
Одной из последних форм маркировки и аннотирования данных, которая широко используется и принимается в различных отраслях, является машинное аннотирование. Автоматизация процесса маркировки данных с помощью программного обеспечения для маркировки данных снижает вмешательство человека и увеличивает скорость выполнения маркировки. С помощью метода, называемого активным обучением, данные могут быть помечены, на основе чего теги могут автоматически добавляться в наборы обучающих данных.
Плюсы:
- Более быстрая обработка данных и маркировка
- Предполагает меньшее вмешательство человека
Минусы:
- Хотя качество лучше, но не наравне с человеческими тегами
- В случае ошибок вмешательство человека по-прежнему требуется

Как работает маркировка данных?
Исходя из потребностей вашего бизнеса, вы можете выбрать подход, который лучше всего соответствует вашим требованиям. Однако процесс маркировки данных работает в следующем хронологическом порядке.
Сбор данных
Основой любого проекта машинного обучения являются данные. Сбор необходимого количества необработанных данных в различных форматах представляет собой первый этап маркировки данных. Сбор данных может осуществляться в двух формах: одна собирается внутри компании, а другая собирается из внешних общедоступных источников.
Будучи в необработанном виде, эти данные требуют очистки и обработки перед созданием меток для наборов данных. Затем эти очищенные и предварительно обработанные данные передаются модели для обучения. Чем больше и разнообразнее данные, тем точнее будут результаты.
Аннотация данных
После очистки данных эксперты предметной области просматривают данные и добавляют метки, используя различные подходы к маркировке данных. Осмысленный контекст связан с моделью, которую можно использовать в качестве базовой истины . Это целевые переменные, такие как изображения, которые вы хотите, чтобы модель предсказывала.

Гарантия качества
Успех обучения модели машинного обучения во многом зависит от качества данных, которые должны быть надежными, точными и непротиворечивыми. Чтобы обеспечить эти точные и точные метки данных, должны проводиться регулярные проверки качества. С помощью алгоритмов контроля качества, таких как консенсус и альфа-тест Кронбаха, можно определить точность этих аннотаций. Регулярные проверки качества в значительной степени способствуют точности результатов.
Обучение и тестирование моделей
Выполнение всех вышеперечисленных шагов имеет смысл только в том случае, если данные проверены на точность. Ввод неструктурированного набора данных, чтобы увидеть, дает ли он ожидаемые результаты, проверит процесс.
Отраслевые варианты использования маркировки данных
Теперь, когда мы знакомы с тем, что такое маркировка данных и как она работает, давайте рассмотрим наиболее известные варианты использования.
Компьютерное зрение (резюме)
Это подмножество ИИ, которое позволяет машинам получать осмысленную интерпретацию входных данных, предоставленных в виде визуальных эффектов и видео (неподвижных изображений, извлеченных для маркировки).
Аннотации компьютерного зрения можно использовать в различных отраслях для реализации практических преимуществ ИИ.
- В автомобильной промышленности маркировка изображений и видео для сегментирования дорог, зданий, пешеходов и других объектов поможет автономным транспортным средствам различать эти объекты, чтобы избежать контакта в реальной жизни.
- В сфере здравоохранения симптомы заболевания можно сегментировать на рентгенограммах, МРТ и КТ. С помощью микроскопических изображений можно диагностировать большинство критических заболеваний на ранней стадии.
- QR-коды, штрих-коды этикеток и т. д. могут использоваться в качестве этикеток в транспортной и логистической отрасли для отслеживания товаров.
Обработка естественного языка (NLP)
Это подмножество, которое позволяет машинам ИИ интерпретировать человеческий язык и статистику. Извлекая значение из текста и речи, алгоритм может анализировать различные лингвистические аспекты.
NLP все чаще используется во многих корпоративных решениях .
- Он широко используется во всех отраслях в качестве помощника по электронной почте, функции автозаполнения, проверки орфографии, разделения спама и не спама и многого другого.
- В форме чат- ботов основные запросы клиентов интерпретируются и отвечают на них без вмешательства человека в режиме реального времени. Прогнозируется, что к 2023 году 70% взаимодействий с клиентами будут управляться чат-ботами и мобильными приложениями для обмена сообщениями.
- Понимание отрицательной и положительной полярности текста для улавливания настроений клиентов достигается с помощью маркировки данных в электронной коммерции.
Компания Appinventiv успешно создала приложение для социальных сетей для Vyrb , которое позволяет пользователям отправлять и получать аудиосообщения, оптимизированные для носимых устройств Bluetooth.

Обзор рынка маркировки данных ИИ
Маркировка данных — это процветающая отрасль, основанная на технологии искусственного интеллекта . Поскольку маркировка данных во многом зависит от точности данных, поступающих в машинное обучение, в ближайшие несколько лет она будет расти.
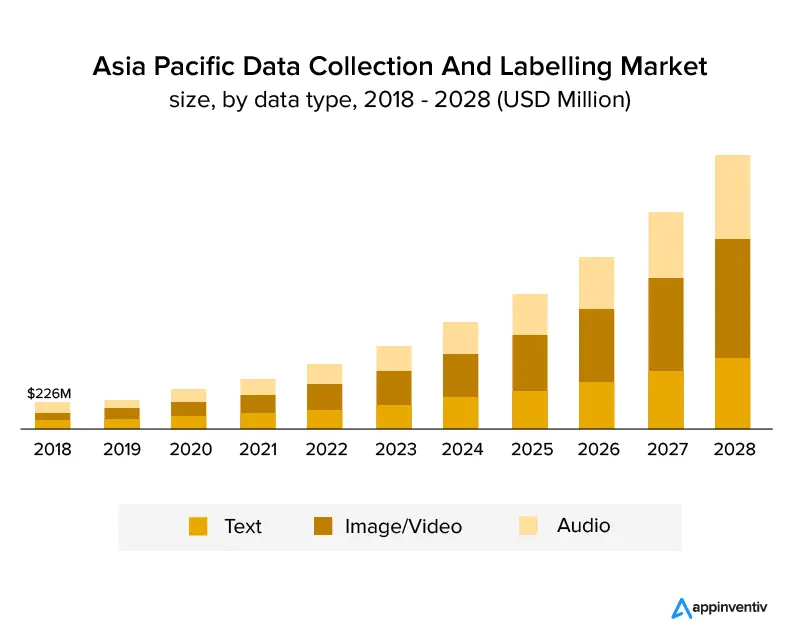
График ниже ясно показывает, что отрасль выросла и продолжит расти в ближайшие годы. Ожидается, что совокупный годовой прирост составит 25,6%, а к 2028 году объем рынка достигнет 8,22 млрд долларов США. На приведенном ниже графике показан рост по типам данных.
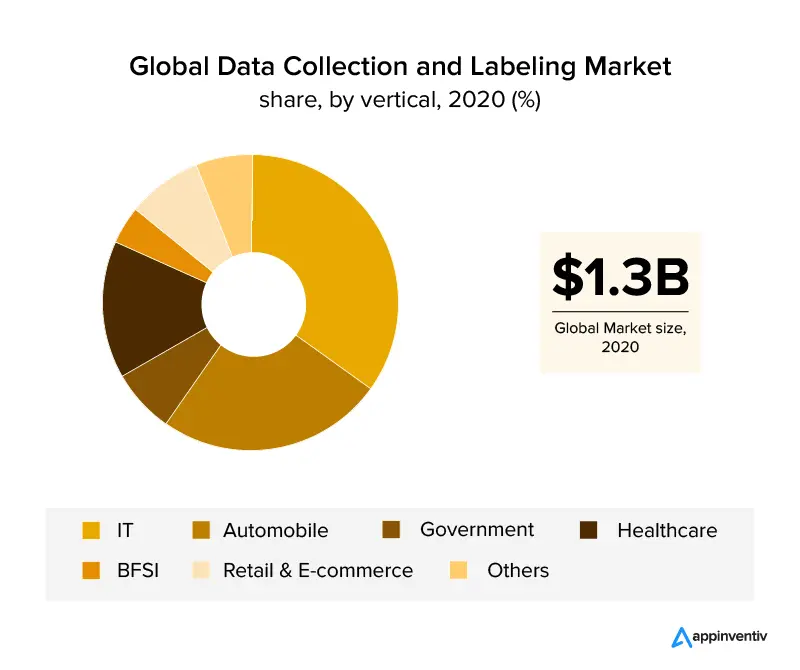
Обзор бизнес-вертикалей, в которых используется маркировка данных, — это ИТ- и автомобильный секторы, на долю которых приходится более 30% мирового дохода. Ожидается, что с ростом отрасли здравоохранения маркировка данных будет стремительно расти из-за требований к точным данным для эффективных приложений на основе ИИ в этом секторе. С помощью маркировки изображений отрасли розничной торговли и электронной коммерции также завоевали значительную долю рынка в индустрии маркировки данных.
Маркировка данных с помощью Appinventiv
Стратегически компании отдают на аутсорсинг услуги по сбору данных и маркировке для создания надежных моделей машинного обучения.
Appinventiv — компания по разработке искусственного интеллекта и машинного обучения , которая уже много лет помогает организациям открывать возможности с помощью решений на основе искусственного интеллекта . Обладая почти десятилетним опытом трансформации бизнеса, мы успешно реализовали множество сложных проектов ИИ для различных отраслей.
Например, Appinventiv успешно автоматизировала банковский процесс для ведущего банка Европы. Процесс автоматизации помог банку повысить точность на 50% и уровень обслуживания банкоматов на 92%.
Еще один пример, когда Appinventiv помогла YouCOMM создать революционное решение для трансформации общения с пациентами в больнице, обеспечив доступ к медицинской помощи в режиме реального времени. Благодаря настраиваемой системе сообщений пациенты могут легко уведомлять персонал о своих потребностях с помощью голосовых команд и жестов головы.
Благодаря нашему опыту и команде, ориентированной на клиента, мы предоставляем услуги по маркировке данных, которые помогут вам преодолеть проблемы, предоставляя вам комплексные услуги по маркировке данных, основанные на ваших конкретных потребностях и требованиях.
Используя широкий набор инструментов, необходимых для маркировки и аннотирования данных, Appinventiv может улучшить ваши процессы обучения данных, чтобы упростить сложные модели. Это позволяет нам превосходить по точности сегментации, классификации и последующей маркировки данных, что будет быстро и просто.
Подведение итогов!
«Сила искусственного интеллекта настолько невероятна, что он очень глубоко изменит общество». - Билл Гейтс
Искусственный интеллект может облегчить человеческую жизнь, тем самым принося пользу обществу. Его способность сортировать огромные объемы данных в осмысленные инструкции с помощью маркировки данных помогла отраслям развиваться и расти стремительными темпами.
Часто задаваемые вопросы
В. Каковы наилучшие методы для улучшения маркировки данных?
О. В зависимости от выбранного вами подхода к маркировке данных есть несколько рекомендаций, которым вы можете следовать:
- Убедитесь, что собранные данные адекватны, правильно очищены и обработаны.
- В зависимости от отрасли назначайте работу только специалистам по маркировке данных в предметной области.
- Убедитесь, что команда придерживается единого подхода, предоставив им критерии методов аннотирования, которым необходимо следовать.
- Следуйте процессу проверки производителя, назначив несколько аннотаторов для перекрестной маркировки.
В. Каковы преимущества маркировки данных?
A. Маркировка данных помогает лучше понять контекст, качество и удобство использования, чтобы сделать точный прогноз данных. Это, в свою очередь, помогает повысить удобство использования переменных в модели.
В. Какие элементы следует учитывать при составлении списка компаний, занимающихся маркировкой данных?
О. Существует пять параметров, которые следует учитывать при выборе служб меток данных для машинного обучения.
- Масштабируемость процесса маркировки данных
- Стоимость услуги маркировки данных
- Безопасность данных
- Платформа маркировки данных