
Что такое Robots.txt в SEO: как его создать и оптимизировать
Опубликовано: 2022-04-22Сегодняшняя тема не имеет прямого отношения к монетизации трафика. Но robots.txt может повлиять на SEO вашего сайта и, в конечном итоге, на объем получаемого трафика. Многие веб-администраторы испортили рейтинг своих веб-сайтов из-за неудачных записей в файле robots.txt. Это руководство поможет вам избежать всех этих ловушек. Обязательно дочитайте до конца!
- Что такое файл robots.txt?
- Как выглядит файл robots.txt?
- Как найти файл robots.txt
- Как работает файл Robots.txt?
- Синтаксис robots.txt
- Поддерживаемые директивы
- Пользовательский агент*
- Разрешать
- Запретить
- Карта сайта
- Неподдерживаемые директивы
- Задержка сканирования
- без индекса
- Не следует
- Вам нужен файл robots.txt?
- Создание файла robots.txt
- Файл robots.txt: лучшие практики SEO
- Используйте новую строку для каждой директивы
- Используйте подстановочные знаки для упрощения инструкций
- Используйте знак доллара «$», чтобы указать конец URL-адреса.
- Используйте каждый пользовательский агент только один раз
- Используйте конкретные инструкции, чтобы избежать непреднамеренных ошибок
- Введите комментарии в файле robots.txt с хешем
- Используйте разные файлы robots.txt для каждого поддомена.
- Не блокируйте хороший контент
- Не злоупотребляйте задержкой сканирования
- Обратите внимание на чувствительность к регистру
- Другие лучшие практики:
- Использование robots.txt для предотвращения индексации контента
- Использование robots.txt для защиты частного контента
- Использование robots.txt для сокрытия вредоносного дублированного контента
- Полный доступ для всех ботов
- Нет доступа для всех ботов
- Заблокировать один подкаталог для всех ботов
- Заблокировать один подкаталог для всех ботов (с одним разрешенным файлом)
- Заблокировать один файл для всех ботов
- Заблокировать один тип файла (PDF) для всех ботов
- Блокировать все параметризованные URL-адреса только для робота Googlebot
- Как проверить файл robots.txt на наличие ошибок
- Отправленный URL заблокирован файлом robots.txt
- Заблокировано файлом robots.txt
- Проиндексировано, но заблокировано robots.txt
- Robots.txt против мета-роботов против x-роботов
- дальнейшее чтение
- Подведение итогов
Что такое файл robots.txt?
robots.txt, или протокол исключения роботов, представляет собой набор веб-стандартов, которые контролируют, как роботы поисковых систем сканируют каждую веб-страницу, вплоть до разметки схемы на этой странице. Это стандартный текстовый файл, который может даже помешать поисковым роботам получить доступ ко всему вашему веб-сайту или его частям.
Настраивая SEO и решая технические вопросы, вы можете начать получать пассивный доход от рекламы. Одна строка кода на вашем сайте возвращает регулярные выплаты!
К содержанию ↑Как выглядит файл robots.txt?
Синтаксис прост: вы даете ботам правила, указывая их пользовательский агент и директивы. Файл имеет следующий базовый формат:
Карта сайта: [URL-адрес карты сайта]
Агент пользователя: [идентификатор бота]
[директива 1]
[директива 2]
[директива …]
User-agent: [идентификатор другого бота]
[директива 1]
[директива 2]
[директива …]
Как найти файл robots.txt
Если на вашем веб-сайте уже есть файл robot.txt, вы можете найти его, перейдя по этому URL-адресу: https://yourdomainname.com/robots.txt в браузере. Например, вот наш файл
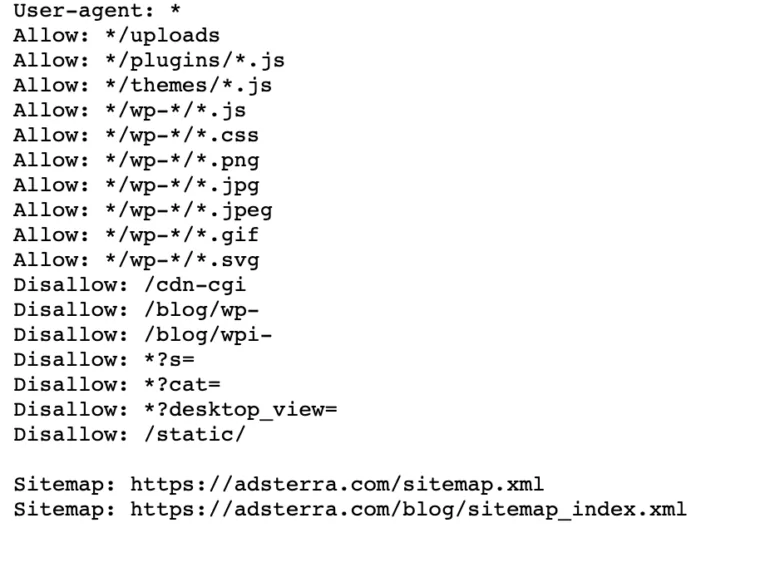
Как работает файл Robots.txt?
Файл robots.txt — это обычный текстовый файл, не содержащий кода HTML-разметки (отсюда и расширение .txt). Этот файл, как и все остальные файлы на веб-сайте, хранится на веб-сервере. Пользователи вряд ли посетят эту страницу, потому что она не связана ни с одной из ваших страниц, но большинство роботов поисковых роботов ищут ее, прежде чем сканировать весь веб-сайт.
Файл robots.txt может давать инструкции ботам, но не может выполнять эти инструкции. Хороший бот, такой как поисковый робот или бот новостной ленты, проверит файл и будет следовать инструкциям перед посещением любой страницы домена. Но вредоносные боты будут либо игнорировать, либо обрабатывать файл для поиска запрещенных веб-страниц.
В ситуации, когда файл robots.txt содержит конфликтующие команды, бот будет использовать наиболее конкретный набор инструкций.
К содержанию ↑Синтаксис robots.txt
Файл robots.txt состоит из нескольких разделов «директив», каждая из которых начинается с пользовательского агента. Пользовательский агент указывает робота сканирования, с которым взаимодействует код. Вы можете обращаться ко всем поисковым системам одновременно или управлять отдельными поисковыми системами.
Всякий раз, когда бот сканирует веб-сайт, он воздействует на те части сайта, которые его вызывают.
Пользовательский агент: *
Запретить: /
Агент пользователя: Googlebot
Запретить:
Агент пользователя: Bingbot
Запретить: /not-for-bing/
Поддерживаемые директивы
Директивы — это рекомендации, которым вы хотите, чтобы пользовательские агенты, которых вы объявляете, следовали. В настоящее время Google поддерживает следующие директивы.
Пользовательский агент*
Когда программа подключается к веб-серверу (робот или обычный веб-браузер), она отправляет HTTP-заголовок, называемый «агент пользователя», содержащий основную информацию о своей личности. У каждой поисковой системы есть пользовательский агент. Роботы Google известны как Googlebot, Yahoo — как Slurp, а Bing — как BingBot. Пользовательский агент инициирует последовательность директив, которые могут применяться к определенным пользовательским агентам или ко всем пользовательским агентам.
Разрешать
Директива allow указывает поисковым системам сканировать страницу или подкаталог, даже каталог с ограниченным доступом. Например, если вы хотите, чтобы поисковые системы не могли получить доступ ко всем сообщениям в вашем блоге, кроме одного, ваш файл robots.txt может выглядеть следующим образом:
Пользовательский агент: *
Запретить: /блог
Разрешить: /blog/allowed-post
Однако поисковые системы могут получить доступ к /blog/allowed-post, но не могут получить доступ к:
/блог/другой пост
/блог/еще-еще-пост
/блог/download-me.pd
Запретить
Директива disallow (которая добавляется в файл robots.txt веб-сайта) указывает поисковым системам не сканировать определенную страницу. В большинстве случаев это также предотвратит появление страницы в результатах поиска.
Вы можете использовать эту директиву, чтобы запретить поисковым системам сканировать файлы и страницы в определенной папке, которую вы скрываете от широкой публики. Например, контент, над которым вы все еще работаете, но по ошибке опубликовали. Ваш файл robots.txt может выглядеть так, если вы хотите запретить всем поисковым системам доступ к вашему блогу:
Пользовательский агент: *
Запретить: /блог
Это означает, что все подкаталоги каталога /blog также не будут сканироваться. Это также заблокирует доступ Google к URL-адресам, содержащим /blog.
К содержанию ↑Карта сайта
Файлы Sitemap — это список страниц, которые поисковые системы должны сканировать и индексировать. Если вы используете директиву sitemap, поисковые системы будут знать местоположение вашей XML-карты сайта. Лучший вариант — отправить их в инструменты веб-мастера поисковых систем, потому что каждый из них может предоставить посетителям ценную информацию о вашем веб-сайте.
Важно отметить, что повторять директиву карты сайта для каждого агента пользователя не нужно, и она не применяется к одному поисковому агенту. Добавьте директивы карты сайта в начало или конец файла robots.txt.
Пример директивы карты сайта в файле:
Карта сайта: https://www.domain.com/sitemap.xml
Агент пользователя: Googlebot
Запретить: /блог/
Разрешить: /blog/post-title/
Агент пользователя: Bingbot
Запретить: /услуги/
К содержанию ↑Неподдерживаемые директивы
Ниже перечислены директивы, которые Google больше не поддерживает — некоторые из них технически никогда не одобрялись.
Задержка сканирования
Yahoo, Bing и Яндекс быстро реагируют на индексацию веб-сайтов и реагируют на директиву о задержке сканирования, которая некоторое время держит их под контролем.
Примените эту строку к своему блоку:
Агент пользователя: Bingbot
Задержка сканирования: 10
Это означает, что поисковые системы могут ждать десять секунд перед сканированием веб-сайта или десять секунд перед повторным доступом к веб-сайту после сканирования, что является одним и тем же, но немного отличается в зависимости от используемого пользовательского агента.
без индекса
Метатег noindex — отличный способ запретить поисковым системам индексировать одну из ваших страниц. Тег позволяет ботам получать доступ к веб-страницам, но также информирует роботов не индексировать их.
- Заголовок ответа HTTP с тегом noindex. Вы можете реализовать этот тег двумя способами: заголовок ответа HTTP с тегом X-Robots-Tag или тег <meta>, помещенный в раздел <head>. Вот как должен выглядеть ваш тег <meta>:
<meta name="robots" content="noindex">
- Код состояния HTTP 404 и 410. Коды состояния 404 и 410 указывают на то, что страница больше недоступна. После сканирования и обработки страниц 404/410 они автоматически удаляют их из индекса Google. Чтобы снизить риск страниц с ошибками 404 и 410, регулярно сканируйте свой веб-сайт и используйте переадресацию 301 для перенаправления трафика на существующую страницу, где это необходимо.
Не следует
Nofollow предписывает поисковым системам не переходить по ссылкам на страницы и файлы по определенному пути. С 1 марта 2020 года Google больше не считает атрибуты nofollow директивами. Вместо этого они будут подсказками, очень похожими на канонические теги. Если вам нужен атрибут «nofollow» для всех ссылок на странице, используйте метатег робота, заголовок x-robots или атрибут ссылки rel= «nofollow» .
Ранее вы могли использовать следующую директиву, чтобы запретить Google переходить по всем ссылкам в вашем блоге:
Агент пользователя: Googlebot
Nofollow: /блог/
Вам нужен файл robots.txt?
Многим менее сложным веб-сайтам он не нужен. Хотя Google обычно не индексирует веб-страницы, заблокированные файлом robots.txt, невозможно гарантировать, что эти страницы не появятся в результатах поиска. Наличие этого файла дает вам больший контроль и безопасность контента на вашем веб-сайте по сравнению с поисковыми системами.
Файлы robots также помогают выполнять следующие действия:
- Предотвратите сканирование дублированного контента.
- Сохраняйте конфиденциальность для разных разделов сайта.
- Ограничить сканирование результатов внутреннего поиска.
- Предотвратить перегрузку сервера.
- Предотвратите растрату «краулингового бюджета».
- Держите изображения, видео и файлы ресурсов вне результатов поиска Google.
Эти меры в конечном итоге влияют на вашу тактику SEO. Например, дублированный контент сбивает с толку поисковые системы и заставляет их выбирать, какая из двух страниц ранжируется первой. Независимо от того, кто создал контент, Google может не выбрать исходную страницу для первых результатов поиска.

В тех случаях, когда Google обнаруживает дублированный контент, предназначенный для обмана пользователей или манипулирования рейтингом, он корректирует индексацию и рейтинг вашего веб-сайта. В результате рейтинг вашего сайта может пострадать или быть полностью удаленным из индекса Google, что приведет к исчезновению из результатов поиска.
Сохранение конфиденциальности для различных разделов веб-сайта также повышает безопасность вашего веб-сайта и защищает его от хакеров. В конечном итоге эти меры сделают ваш сайт более безопасным, надежным и прибыльным.
Вы владелец веб-сайта и хотите получать прибыль от трафика? С Adsterra вы будете получать пассивный доход с любого сайта!
К содержанию ↑Создание файла robots.txt
Вам понадобится текстовый редактор, например Блокнот.
- Создайте новый лист, сохраните пустую страницу как robots.txt и начните вводить директивы в пустой документ .txt.
- Войдите в свою cPanel, перейдите в корневой каталог сайта, найдите папку public_html .
- Перетащите файл в эту папку, а затем дважды проверьте, правильно ли установлены права доступа к файлу.
Вы можете писать, читать и редактировать файл как владелец, но третьим лицам это запрещено. В файле должен появиться код разрешения «0644» . Если нет, щелкните файл правой кнопкой мыши и выберите «Разрешение на доступ к файлу».
Файл robots.txt: лучшие практики SEO
Используйте новую строку для каждой директивы
Вам нужно объявить каждую директиву на отдельной строке. В противном случае поисковые системы будут запутаны.
Пользовательский агент: *
Запретить: /каталог/
Запретить: /другой-каталог/
Используйте подстановочные знаки для упрощения инструкций
Вы можете использовать подстановочные знаки (*) для всех пользовательских агентов и сопоставлять шаблоны URL при объявлении директив. Подстановочный знак хорошо работает для URL-адресов, имеющих единый шаблон. Например, вы можете запретить сканирование всех страниц фильтров со знаком вопроса (?) в URL-адресах.
Пользовательский агент: *
Запретить: /*?
Используйте знак доллара «$», чтобы указать конец URL-адреса.
Поисковые системы не могут получить доступ к URL-адресам, которые заканчиваются расширениями, такими как .pdf. Это означает, что они не смогут получить доступ к /file.pdf, но смогут получить доступ к /file.pdf?id=68937586, который не заканчивается на «.pdf». Например, если вы хотите запретить поисковым системам доступ ко всем файлам PDF на вашем веб-сайте, ваш файл robots.txt может выглядеть следующим образом:
Пользовательский агент: *
Запретить: /*.pdf$
Используйте каждый пользовательский агент только один раз
В Google не имеет значения, используете ли вы один и тот же пользовательский агент более одного раза. Он просто скомпилирует все правила из различных объявлений в одну директиву и будет ей следовать. Однако объявление каждого пользовательского агента только один раз имеет смысл, потому что это менее запутанно.
Если ваши директивы будут аккуратными и простыми, это снизит риск критических ошибок. Например, если ваш файл robots.txt содержит следующие пользовательские агенты и директивы.
Агент пользователя: Googlebot
Запретить: /а/
Агент пользователя: Googlebot
Запретить: /b/
Используйте конкретные инструкции, чтобы избежать непреднамеренных ошибок
При установке директив отсутствие конкретных инструкций может привести к ошибкам, которые могут повредить вашему SEO. Предположим, у вас есть многоязычный сайт и вы работаете над немецкой версией для подкаталога /de/.
Вы не хотите, чтобы поисковые системы могли получить к нему доступ, потому что он еще не готов. Следующий файл robots.txt не позволит поисковым системам индексировать эту подпапку и ее содержимое:
Пользовательский агент: *
Запретить: / де
Однако поисковые системы не смогут сканировать любые страницы или файлы, начинающиеся с /de. В этом случае добавление завершающей косой черты является простым решением.
Пользовательский агент: *
Запретить: /de/
К содержанию ↑Введите комментарии в файле robots.txt с хешем
Комментарии помогают разработчикам и, возможно, даже вам понять ваш файл robots.txt. Начните строку с решётки (#), чтобы включить комментарий. Сканеры игнорируют строки, начинающиеся с хеша.
# Это указывает боту Bing не сканировать наш сайт.
Агент пользователя: Bingbot
Запретить: /
Используйте разные файлы robots.txt для каждого поддомена.
Robots.txt влияет только на сканирование в своем хост-домене. Вам понадобится еще один файл, чтобы ограничить сканирование на другом субдомене. Например, если вы размещаете свой основной веб-сайт на сайте example.com, а свой блог — на сайте blog.example.com, вам понадобятся два файла robots.txt. Поместите один файл в корневой каталог основного домена, а другой файл должен находиться в корневом каталоге блога.
Не блокируйте хороший контент
Не используйте файл robots.txt или тег noindex для блокировки любого качественного контента, который вы хотите сделать общедоступным, чтобы избежать негативного влияния на результаты SEO. Тщательно проверьте теги noindex и запрещающие правила на своих страницах.
Не злоупотребляйте задержкой сканирования
Мы объяснили задержку сканирования, но вам не следует использовать ее часто, потому что она ограничивает сканирование всех страниц ботами. Это может работать для некоторых веб-сайтов, но вы можете повредить своему рейтингу и трафику, если у вас большой веб-сайт.
Обратите внимание на чувствительность к регистру
Файл robots.txt чувствителен к регистру, поэтому необходимо убедиться, что вы создаете файл robots в правильном формате. Файл robots должен называться robots.txt со всеми строчными буквами. Иначе это не сработает.
Другие лучшие практики:
- Убедитесь, что вы не блокируете контент или разделы вашего веб-сайта от сканирования.
- Не используйте robots.txt, чтобы убрать конфиденциальные данные (частную информацию пользователя) из результатов поисковой выдачи. Используйте другой метод, например шифрование данных или мета-директиву noindex , чтобы ограничить доступ, если другие страницы ссылаются непосредственно на приватную страницу.
- Некоторые поисковые системы имеют более одного пользовательского агента. Google, например, использует Googlebot для обычного поиска и Googlebot-Image для изображений. Нет необходимости задавать директивы для нескольких сканеров каждой поисковой системы, поскольку большинство пользовательских агентов одной и той же поисковой системы следуют одним и тем же правилам.
- Поисковая система кэширует содержимое robots.txt, но ежедневно обновляет его. Если вы изменили файл и хотите обновить его быстрее, вы можете отправить URL-адрес файла в Google.
Использование robots.txt для предотвращения индексации контента
Отключение страницы — самый эффективный способ предотвратить ее прямое сканирование ботами. Однако это не сработает в следующих случаях:
- Если на страницу есть ссылки из другого источника, боты все равно ее просканируют и проиндексируют.
- Незаконные боты будут продолжать сканировать и индексировать контент.
Использование robots.txt для защиты частного контента
Некоторый личный контент, например PDF-файлы или страницы с благодарностью, можно индексировать, даже если вы заблокируете ботов. Размещение всех ваших эксклюзивных страниц за логином — один из лучших способов усилить директиву запрета. Ваш контент останется доступным, но ваши посетители сделают дополнительный шаг для доступа к нему.
Использование robots.txt для сокрытия вредоносного дублированного контента
Дублированный контент либо идентичен, либо очень похож на другой контент на том же языке. Google пытается индексировать и показывать страницы с уникальным содержанием. Например, если на вашем сайте есть «обычная» и «печатная» версии каждой статьи, а тег noindex не блокирует ни одну из них, будет указана одна из них.
Примеры файлов robots.txt
Ниже приведены несколько примеров файлов robots.txt. В первую очередь они предназначены для идей, но если один из них соответствует вашим потребностям, скопируйте и вставьте его в текстовый документ, сохраните его как «robots.txt» и загрузите в соответствующий каталог.
Полный доступ для всех ботов
Есть несколько способов сообщить поисковым системам о доступе ко всем файлам, включая наличие пустого файла robots.txt или его отсутствия.
Пользовательский агент: *
Запретить:
Нет доступа для всех ботов
Следующий файл robots.txt предписывает всем поисковым системам избегать доступа ко всему сайту:
Пользовательский агент: *
Запретить: /
Заблокировать один подкаталог для всех ботов
Пользовательский агент: *
Запретить: /папка/
Заблокировать один подкаталог для всех ботов (с одним разрешенным файлом)
Пользовательский агент: *
Запретить: /папка/
Разрешить: /folder/page.html
Заблокировать один файл для всех ботов
Пользовательский агент: *
Запретить: /this-is-a-file.pdf
Заблокировать один тип файла (PDF) для всех ботов
Пользовательский агент: *
Запретить: /*.pdf$
Блокировать все параметризованные URL-адреса только для робота Googlebot
Агент пользователя: Googlebot
Запретить: /*?
Как проверить файл robots.txt на наличие ошибок
Ошибки в файле robots.txt могут быть серьезными, поэтому важно следить за ними. Регулярно проверяйте отчет «Покрытие» в Search Console на наличие проблем, связанных с файлом robot.txt. Ниже перечислены некоторые из ошибок, с которыми вы можете столкнуться, что они означают и как их исправить.
Отправленный URL заблокирован файлом robots.txt
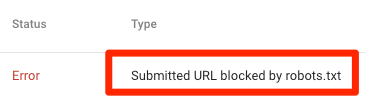
Это указывает на то, что robots.txt заблокировал как минимум один из URL-адресов в ваших картах сайта. Если ваша карта сайта верна и не включает канонизированные, неиндексированные или перенаправленные страницы, файл robots.txt не должен блокировать отправляемые вами страницы. Если это так, определите затронутые страницы и снимите блокировку с файла robots.txt.
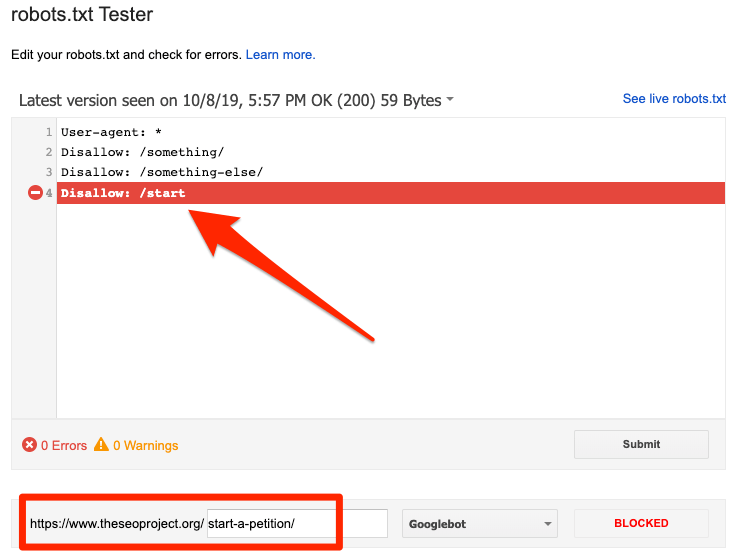
Вы можете использовать тестер Google robots.txt для определения директивы блокировки. Будьте осторожны при редактировании файла robots.txt, поскольку ошибка может повлиять на другие страницы или файлы.
Заблокировано файлом robots.txt
Эта ошибка указывает на то, что robots.txt заблокировал контент, который Google не может проиндексировать. Удалите блокировку сканирования в robots.txt, если этот контент имеет решающее значение и должен быть проиндексирован. (Кроме того, убедитесь, что содержимое не проиндексировано.)
Если вы хотите исключить контент из индекса Google, используйте метатег робота или x-robots-header и удалите блокировку сканирования. Это единственный способ не допустить попадания контента в индекс Google.
Проиндексировано, но заблокировано robots.txt
Это означает, что Google по-прежнему индексирует часть контента, заблокированного файлом robots.txt. Robots.txt не является решением для предотвращения отображения вашего контента в результатах поиска Google.
Чтобы предотвратить индексирование, удалите блокировку сканирования и замените его метатегом robots или HTTP-заголовком x-robots-tag. Если вы случайно заблокировали этот контент и хотите, чтобы Google проиндексировал его, снимите блокировку сканирования в файле robots.txt. Это может помочь улучшить видимость контента в поиске Google.
Robots.txt против мета-роботов против x-роботов
Что отличает эти три команды робота? Robots.txt — это простой текстовый файл, а meta и x-robots — это метадирективы. Помимо своих основных ролей, все три имеют различные функции. Robots.txt определяет поведение сканирования для всего веб-сайта или каталога, тогда как meta и x-robots определяют поведение индексации для отдельных страниц (или элементов страницы).
дальнейшее чтение
Полезные ресурсы
- Википедия: Протокол исключения роботов
- Документация Google по Robots.txt
- Документация Bing (и Yahoo) по Robots.txt
- Директивы объяснил
- Документация Яндекса по Robots.txt
Подведение итогов
Мы надеемся, что вы полностью осознали важность файла robot.txt и его вклад в вашу общую практику SEO и прибыльность веб-сайта. Если вы все еще боретесь с получением дохода от своего веб-сайта, вам не понадобится кодирование, чтобы начать зарабатывать на рекламе Adsterra. Разместите рекламный код на своем веб-сайте HTML, WordPress или Blogger и начните получать прибыль уже сегодня!