
เทคนิคขั้นสูงสำหรับการเพิ่มปริมาณงาน LLM
เผยแพร่แล้ว: 2024-04-02ในโลกของเทคโนโลยีที่เปลี่ยนแปลงไปอย่างรวดเร็ว Large Language Model (LLM) ได้กลายเป็นผู้เล่นหลักในการโต้ตอบกับข้อมูลดิจิทัล เครื่องมืออันทรงพลังเหล่านี้สามารถเขียนบทความ ตอบคำถาม และแม้แต่สนทนาได้ แต่ก็ใช่ว่าจะปราศจากความท้าทาย เนื่องจากเราต้องการโมเดลเหล่านี้มากขึ้น เราก็ประสบปัญหา โดยเฉพาะอย่างยิ่งเมื่อต้องทำให้โมเดลเหล่านี้ทำงานเร็วขึ้นและมีประสิทธิภาพมากขึ้น บล็อกนี้เป็นเรื่องเกี่ยวกับการจัดการกับอุปสรรคเหล่านั้นโดยตรง
เรากำลังเจาะลึกถึงกลยุทธ์อันชาญฉลาดที่ออกแบบมาเพื่อเพิ่มความเร็วในการทำงานของโมเดลเหล่านี้ โดยไม่สูญเสียคุณภาพของเอาต์พุต ลองนึกภาพการพยายามปรับปรุงความเร็วของรถแข่งในขณะเดียวกันก็ให้แน่ใจว่ามันยังสามารถนำทางในโค้งแคบ ๆ ได้อย่างไร้ที่ติ—นั่นคือสิ่งที่เราตั้งเป้าไว้ด้วยโมเดลภาษาขนาดใหญ่ เราจะพิจารณาวิธีการต่างๆ เช่น การรวมชุดอย่างต่อเนื่อง ซึ่งช่วยให้ประมวลผลข้อมูลได้ราบรื่นยิ่งขึ้น และวิธีการที่เป็นนวัตกรรมใหม่ เช่น Paged และ Flash Attention ซึ่งทำให้ LLM มีความเอาใจใส่และรวดเร็วยิ่งขึ้นในการให้เหตุผลทางดิจิทัล
ดังนั้น หากคุณอยากรู้เกี่ยวกับการก้าวข้ามขีดจำกัดของสิ่งที่ AI ยักษ์ใหญ่เหล่านี้สามารถทำได้ แสดงว่าคุณมาถูกที่แล้ว เรามาสำรวจด้วยกันว่าเทคนิคขั้นสูงเหล่านี้กำลังกำหนดอนาคตของ LLM อย่างไร ทำให้พวกเขาเร็วขึ้นและดีกว่าที่เคยเป็นมา
ความท้าทายในการบรรลุปริมาณงานที่สูงขึ้นสำหรับ LLM
การบรรลุปริมาณงานที่สูงขึ้นในโมเดลภาษาขนาดใหญ่ (LLM) ต้องเผชิญกับความท้าทายที่สำคัญหลายประการ ซึ่งแต่ละอย่างทำหน้าที่เป็นอุปสรรคต่อความเร็วและประสิทธิภาพที่โมเดลเหล่านี้สามารถทำงานได้ อุปสรรคหลักประการหนึ่งคือความต้องการหน่วยความจำที่แท้จริงซึ่งจำเป็นในการประมวลผลและจัดเก็บข้อมูลจำนวนมหาศาลที่โมเดลเหล่านี้ใช้งานได้ เนื่องจาก LLM เติบโตขึ้นทั้งในด้านความซับซ้อนและขนาด ความต้องการทรัพยากรการคำนวณก็ทวีความรุนแรงขึ้น ทำให้การรักษาความเร็วในการประมวลผลเป็นเรื่องที่ท้าทาย ไม่ต้องพูดถึงการเพิ่มความเร็วในการประมวลผลเลย
ความท้าทายที่สำคัญอีกประการหนึ่งคือลักษณะการถดถอยอัตโนมัติของ LLM โดยเฉพาะอย่างยิ่งในแบบจำลองที่ใช้สำหรับการสร้างข้อความ ซึ่งหมายความว่าเอาต์พุตในแต่ละขั้นตอนจะขึ้นอยู่กับขั้นตอนก่อนหน้า สร้างข้อกำหนดการประมวลผลตามลำดับที่จำกัดความเร็วในการดำเนินงานโดยธรรมชาติ การพึ่งพาตามลำดับนี้มักส่งผลให้เกิดปัญหาคอขวด เนื่องจากแต่ละขั้นตอนต้องรอให้ขั้นตอนก่อนหน้าเสร็จสิ้นก่อนจึงจะสามารถดำเนินการต่อได้ ซึ่งขัดขวางความพยายามในการบรรลุปริมาณงานที่สูงขึ้น
นอกจากนี้ ความสมดุลระหว่างความแม่นยำและความเร็วยังเป็นเรื่องที่ละเอียดอ่อนอีกด้วย การเพิ่มปริมาณงานโดยไม่กระทบต่อคุณภาพของเอาต์พุตนั้นต้องใช้ความพยายามอย่างมาก โดยต้องใช้โซลูชันที่เป็นนวัตกรรมที่สามารถนำทางภูมิทัศน์ที่ซับซ้อนของประสิทธิภาพการคำนวณและประสิทธิผลของแบบจำลอง
ความท้าทายเหล่านี้ก่อให้เกิดความก้าวหน้าในการเพิ่มประสิทธิภาพ LLM ซึ่งผลักดันขอบเขตของสิ่งที่เป็นไปได้ในขอบเขตของการประมวลผลภาษาธรรมชาติและอื่น ๆ
ความต้องการหน่วยความจำ
ขั้นตอนการถอดรหัสจะสร้างโทเค็นเดียวในแต่ละขั้นตอนเวลา แต่แต่ละโทเค็นจะขึ้นอยู่กับคีย์และเทนเซอร์ค่าของโทเค็นก่อนหน้าทั้งหมด (รวมถึงเทนเซอร์ KV ของโทเค็นอินพุตที่คำนวณในการเติมล่วงหน้า และเทนเซอร์ KV ใหม่ใดๆ ที่คำนวณจนถึงขั้นตอนเวลาปัจจุบัน) .
ดังนั้น เพื่อลดการคำนวณที่ซ้ำซ้อนทุกครั้ง และเพื่อหลีกเลี่ยงการคำนวณเทนเซอร์เหล่านี้ทั้งหมดใหม่สำหรับโทเค็นทั้งหมดในแต่ละขั้นตอน จึงเป็นไปได้ที่จะแคชโทเค็นเหล่านั้นไว้ในหน่วยความจำ GPU การวนซ้ำทุกครั้งเมื่อมีการคำนวณองค์ประกอบใหม่ องค์ประกอบเหล่านั้นจะถูกเพิ่มลงในแคชที่กำลังทำงานอยู่เพื่อใช้ในการวนซ้ำครั้งถัดไป โดยพื้นฐานแล้วเรียกว่าแคช KV
สิ่งนี้ช่วยลดความจำเป็นในการคำนวณได้อย่างมาก แต่ยังทำให้เกิดความต้องการหน่วยความจำควบคู่กับความต้องการหน่วยความจำที่สูงขึ้นสำหรับโมเดลภาษาขนาดใหญ่ ซึ่งทำให้ยากต่อการรันบน GPU สินค้าโภคภัณฑ์ ด้วยขนาดพารามิเตอร์โมเดลที่เพิ่มขึ้น (7B ถึง 33B) และความแม่นยำที่สูงขึ้น (fp16 ถึง fp32) ความต้องการหน่วยความจำก็เพิ่มขึ้นเช่นกัน มาดูตัวอย่างความจุหน่วยความจำที่ต้องการ
ดังที่เราทราบแล้วว่าผู้ครอบครองหน่วยความจำหลักสองคนคือ
- ตุ้มน้ำหนักของโมเดลเองในความทรงจำนี้มาพร้อมกับหมายเลข ของพารามิเตอร์เช่น 7B และประเภทข้อมูลของแต่ละพารามิเตอร์ เช่น 7B ใน fp16(2 ไบต์) ~= 14GB ในหน่วยความจำ
- แคช KV: แคชที่ใช้สำหรับค่าคีย์ของระยะการดูแลตนเองเพื่อหลีกเลี่ยงการคำนวณซ้ำซ้อน
ขนาดของแคช KV ต่อโทเค็นในหน่วยไบต์ = 2 * (num_layers) * (hidden_size) * precision_in_bytes
ตัวประกอบแรก 2 คำนึงถึงเมทริกซ์ K และ V สามารถรับ Hidden_size และ dim_head เหล่านี้ได้จากการ์ดของโมเดลหรือไฟล์กำหนดค่า
สูตรข้างต้นเป็นสูตรต่อโทเค็น ดังนั้นสำหรับลำดับอินพุต มันจะเป็น seq_len * size_of_kv_per_token ดังนั้นสูตรข้างต้นจะเปลี่ยนเป็น
ขนาดรวมของแคช KV เป็นไบต์ = (sequence_length) * 2 * (num_layers) * (hidden_size) * precision_in_bytes
เช่น ด้วย LLAMA 2 ใน fp16 ขนาดจะเป็น (4096) * 2 * (32) * (4096) * 2 ซึ่งเท่ากับ ~2GB
ข้อมูลข้างต้นนี้ใช้สำหรับอินพุตเดียว โดยมีหลายอินพุต ซึ่งจะเติบโตอย่างรวดเร็ว การจัดสรรและการจัดการหน่วยความจำบนเครื่องบินนี้จึงกลายเป็นขั้นตอนสำคัญในการบรรลุประสิทธิภาพสูงสุด หากไม่ส่งผลให้เกิดปัญหาหน่วยความจำไม่เพียงพอและการกระจายตัว
บางครั้ง ความต้องการหน่วยความจำนั้นมากกว่าความจุของ GPU ของเรา ในกรณีเหล่านั้น เราต้องพิจารณาโมเดลความขนาน ความเท่าเทียมของเทนเซอร์ ซึ่งไม่ได้กล่าวถึงในที่นี้ แต่คุณสามารถสำรวจไปในทิศทางนั้นได้
การถดถอยอัตโนมัติและการดำเนินการที่ถูกผูกไว้กับหน่วยความจำ
ดังที่เราเห็น ส่วนการสร้างเอาต์พุตของโมเดลภาษาขนาดใหญ่มีลักษณะการถดถอยอัตโนมัติ ตัวบ่งชี้สำหรับโทเค็นใหม่ที่จะถูกสร้างขึ้น ขึ้นอยู่กับโทเค็นก่อนหน้าทั้งหมดและสถานะระดับกลาง เนื่องจากในระยะเอาท์พุต โทเค็นบางอันไม่พร้อมสำหรับการคำนวณเพิ่มเติม และมีเพียงเวกเตอร์เดียว (สำหรับโทเค็นถัดไป) และบล็อกของสเตจก่อนหน้า สิ่งนี้จึงกลายเป็นเหมือนการดำเนินการเมทริกซ์-เวกเตอร์ซึ่งใช้ความสามารถในการคำนวณ GPU ต่ำกว่าเมื่อ เมื่อเทียบกับขั้นตอนการเติมล่วงหน้า ความเร็วที่ข้อมูล (น้ำหนัก คีย์ ค่า การเปิดใช้งาน) ถ่ายโอนไปยัง GPU จากหน่วยความจำจะควบคุมเวลาแฝง ไม่ใช่ความเร็วของการคำนวณที่เกิดขึ้นจริง กล่าวอีกนัยหนึ่ง นี่คือการดำเนินการ ที่ผูกกับหน่วยความจำ
โซลูชั่นที่เป็นนวัตกรรมเพื่อเอาชนะความท้าทายด้านปริมาณงาน
การแบทช์อย่างต่อเนื่อง
ขั้นตอนง่ายๆ ในการลดลักษณะที่ผูกกับหน่วยความจำของขั้นตอนการถอดรหัสคือการแบทช์อินพุตและทำการคำนวณสำหรับอินพุตหลายรายการพร้อมกัน แต่การแบทช์คงที่อย่างง่ายส่งผลให้ประสิทธิภาพไม่ดีเนื่องจากลักษณะของความยาวลำดับที่แตกต่างกันที่ถูกสร้างขึ้น และเวลาแฝงของแบทช์ขึ้นอยู่กับลำดับที่ยาวที่สุดที่สร้างขึ้นในแบทช์และยังมีความต้องการหน่วยความจำที่เพิ่มขึ้นเนื่องจากมีอินพุตหลายตัว ตอนนี้ประมวลผลทันที
ดังนั้นการแบตช์แบบคงที่อย่างง่ายจึงไม่ได้ผล และเกิดการแบทช์ต่อเนื่อง สาระสำคัญอยู่ที่การรวบรวมชุดคำขอที่เข้ามาแบบไดนามิก การปรับให้เข้ากับอัตราการมาถึงที่ผันผวน และใช้ประโยชน์จากโอกาสในการประมวลผลแบบขนานทุกครั้งที่เป็นไปได้ นอกจากนี้ยังปรับการใช้งานหน่วยความจำให้เหมาะสมด้วยการจัดกลุ่มลำดับที่มีความยาวใกล้เคียงกันไว้ด้วยกันในแต่ละชุด ซึ่งจะช่วยลดจำนวนช่องว่างภายในที่จำเป็นสำหรับลำดับที่สั้นลง และหลีกเลี่ยงการสิ้นเปลืองทรัพยากรการคำนวณในการเติมช่องว่างที่มากเกินไป

โดยจะปรับขนาดแบตช์ตามปัจจัยต่างๆ เช่น ความจุหน่วยความจำปัจจุบัน ทรัพยากรการคำนวณ และความยาวของลำดับอินพุต เพื่อให้แน่ใจว่าโมเดลจะทำงานได้อย่างเหมาะสมที่สุดภายใต้สภาวะที่แตกต่างกันโดยไม่เกินข้อจำกัดของหน่วยความจำ ซึ่งช่วยในเรื่องเพจความสนใจ (อธิบายไว้ด้านล่าง) ช่วยลดเวลาแฝงและเพิ่มปริมาณงาน
อ่านเพิ่มเติม: วิธีที่การแบทช์อย่างต่อเนื่องทำให้เกิดปริมาณงาน 23x ในการอนุมาน LLM ในขณะที่ลดเวลาแฝง p50
เพจความสนใจ
ขณะที่เราจัดชุดเพื่อปรับปรุงปริมาณงาน ความต้องการหน่วยความจำแคช KV ที่เพิ่มขึ้นก็ต้องแลกมาด้วย เนื่องจากขณะนี้เรากำลังประมวลผลอินพุตหลายรายการพร้อมกัน ลำดับเหล่านี้อาจเกินความจุหน่วยความจำของทรัพยากรการคำนวณที่มีอยู่ ทำให้เป็นไปไม่ได้ที่จะประมวลผลทั้งหมดทั้งหมด
นอกจากนี้ยังพบว่าการจัดสรรหน่วยความจำแบบไร้เดียงสาของแคช KV ส่งผลให้เกิดการกระจายตัวของหน่วยความจำจำนวนมาก เช่นเดียวกับที่เราสังเกตในระบบคอมพิวเตอร์เนื่องจากการจัดสรรหน่วยความจำที่ไม่สม่ำเสมอ vLLM เปิดตัว Paged Attention ซึ่งเป็นเทคนิคการจัดการหน่วยความจำที่ได้รับแรงบันดาลใจจากแนวคิดของระบบปฏิบัติการเกี่ยวกับการเพจและหน่วยความจำเสมือน เพื่อรองรับความต้องการที่เพิ่มขึ้นของแคช KV ได้อย่างมีประสิทธิภาพ
Paged Attention จัดการกับข้อจำกัดของหน่วยความจำโดยการแบ่งกลไกความสนใจออกเป็นเพจหรือเซ็กเมนต์เล็กๆ ซึ่งแต่ละส่วนจะครอบคลุมชุดย่อยของลำดับอินพุต แทนที่จะคำนวณคะแนนความสนใจสำหรับลำดับอินพุตทั้งหมดพร้อมกัน โมเดลจะเน้นที่ทีละหน้า และประมวลผลตามลำดับ
ในระหว่างการอนุมานหรือการฝึกอบรม โมเดลจะวนซ้ำแต่ละหน้าของลำดับอินพุต คำนวณคะแนนความสนใจ และสร้างผลลัพธ์ตามลำดับ เมื่อเพจได้รับการประมวลผล ผลลัพธ์จะถูกจัดเก็บ และโมเดลจะย้ายไปยังหน้าถัดไป
ด้วยการแบ่งกลไกความสนใจออกเป็นเพจ Paged Attention อนุญาตให้โมเดลภาษาขนาดใหญ่จัดการลำดับอินพุตที่มีความยาวตามใจชอบโดยไม่เกินข้อจำกัดของหน่วยความจำ โดยช่วยลดพื้นที่หน่วยความจำที่จำเป็นสำหรับการประมวลผลลำดับที่ยาวได้อย่างมีประสิทธิภาพ ทำให้สามารถทำงานกับเอกสารและแบตช์ขนาดใหญ่ได้
อ่านเพิ่มเติม: การให้บริการ LLM ที่รวดเร็วด้วย vLLM และ PagedAttention
ความสนใจแบบแฟลช
เนื่องจากกลไกความสนใจเป็นสิ่งสำคัญสำหรับโมเดลหม้อแปลงไฟฟ้าที่ใช้โมเดลภาษาขนาดใหญ่ จึงช่วยให้โมเดลมุ่งเน้นไปที่ส่วนที่เกี่ยวข้องของข้อความอินพุตเมื่อทำการคาดการณ์ อย่างไรก็ตาม เนื่องจากโมเดลที่ใช้หม้อแปลงมีขนาดใหญ่ขึ้นและซับซ้อนมากขึ้น กลไกการเอาใจใส่ตนเองจะช้าลงและใช้หน่วยความจำมากขึ้น ซึ่งนำไปสู่ปัญหาคอขวดของหน่วยความจำดังที่ได้กล่าวไว้ข้างต้น Flash Attention เป็นอีกหนึ่งเทคนิคการปรับให้เหมาะสมซึ่งมีจุดมุ่งหมายเพื่อบรรเทาปัญหานี้โดยการปรับการดำเนินการด้านความสนใจให้เหมาะสม เพื่อให้สามารถฝึกอบรมและการอนุมานได้เร็วขึ้น
คุณสมบัติที่สำคัญของ Flash Attention:
เคอร์เนลฟิวชั่น: สิ่งสำคัญคือไม่เพียงแต่เพิ่มการใช้งานการประมวลผล GPU ให้สูงสุด แต่ยังทำให้การทำงานมีประสิทธิภาพเป็นไปได้ด้วย Flash Attention รวมขั้นตอนการคำนวณหลายขั้นตอนไว้ในการดำเนินการเดียว ช่วยลดความจำเป็นในการถ่ายโอนข้อมูลซ้ำๆ แนวทางที่ได้รับการปรับปรุงนี้ทำให้กระบวนการนำไปใช้ง่ายขึ้นและเพิ่มประสิทธิภาพในการคำนวณ
การเรียงต่อกัน: Flash Attention แบ่งข้อมูลที่โหลดออกเป็นบล็อกเล็กๆ ซึ่งช่วยให้ประมวลผลแบบขนานได้ กลยุทธ์นี้ปรับการใช้หน่วยความจำให้เหมาะสม ทำให้เกิดโซลูชันที่ปรับขนาดได้สำหรับโมเดลที่มีขนาดอินพุตที่ใหญ่กว่า
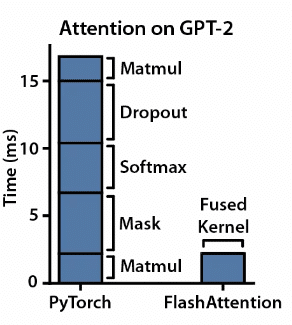
(เคอร์เนล CUDA แบบผสมแสดงให้เห็นว่าการปูกระเบื้องและฟิวชั่นช่วยลดเวลาที่ต้องใช้ในการคำนวณอย่างไร แหล่งที่มาของรูปภาพ: FlashAttention: ความสนใจที่แน่นอนที่รวดเร็วและมีประสิทธิภาพด้วย IO-Awareness)
การเพิ่มประสิทธิภาพหน่วยความจำ: Flash Attention โหลดพารามิเตอร์สำหรับโทเค็นเพียงไม่กี่รายการที่ผ่านมา โดยนำการเปิดใช้งานจากโทเค็นที่คำนวณล่าสุดกลับมาใช้ใหม่ วิธีการหน้าต่างแบบเลื่อนนี้จะช่วยลดจำนวนคำขอ IO เพื่อโหลดน้ำหนักและเพิ่มปริมาณงานหน่วยความจำแฟลชให้สูงสุด
ลดการถ่ายโอนข้อมูล: Flash Attention ช่วยลดการถ่ายโอนข้อมูลกลับไปกลับมาระหว่างประเภทหน่วยความจำ เช่น High Bandwidth Memory (HBM) และ SRAM (Static Random-Access Memory) การโหลดข้อมูลทั้งหมด (คำค้นหา คีย์ และค่า) เพียงครั้งเดียว จะช่วยลดค่าใช้จ่ายในการถ่ายโอนข้อมูลซ้ำๆ
กรณีศึกษา – การเพิ่มประสิทธิภาพการอนุมานด้วยการถอดรหัสเชิงเก็งกำไร
อีกวิธีหนึ่งที่ใช้เพื่อเร่งการสร้างข้อความในแบบจำลองภาษาแบบถดถอยอัตโนมัติคือการถอดรหัสแบบเก็งกำไร วัตถุประสงค์หลักของการถอดรหัสแบบคาดเดาคือเพื่อเร่งการสร้างข้อความในขณะที่รักษาคุณภาพของข้อความที่สร้างขึ้นในระดับที่เทียบเคียงได้กับการกระจายเป้าหมาย
การถอดรหัสแบบเก็งกำไรแนะนำโมเดลขนาดเล็ก/แบบร่างซึ่งคาดการณ์โทเค็นที่ตามมาในลำดับ ซึ่งจากนั้นจะยอมรับ/ปฏิเสธโดยโมเดลหลักตามเกณฑ์ที่กำหนดไว้ล่วงหน้า การรวมโมเดลร่างที่มีขนาดเล็กเข้ากับโมเดลเป้าหมายจะช่วยเพิ่มความเร็วในการสร้างข้อความได้อย่างมาก ทั้งนี้เนื่องมาจากลักษณะของความต้องการหน่วยความจำ เนื่องจากแบบร่างมีขนาดเล็ก จึงต้องใช้จำนวนน้อย ของน้ำหนักเซลล์ประสาทที่จะโหลดและจำนวน ของการคำนวณยังน้อยกว่าเมื่อเทียบกับรุ่นหลัก ซึ่งจะช่วยลดความหน่วงและเพิ่มความเร็วในกระบวนการสร้างเอาต์พุต โมเดลหลักจะประเมินผลลัพธ์ที่สร้างขึ้นและตรวจสอบให้แน่ใจว่าเหมาะสมกับการกระจายเป้าหมายของโทเค็นที่เป็นไปได้ถัดไป
โดยพื้นฐานแล้ว การถอดรหัสแบบเก็งกำไรจะเพิ่มความคล่องตัวให้กับกระบวนการสร้างข้อความโดยใช้ประโยชน์จากแบบจำลองร่างที่เล็กลงและรวดเร็วยิ่งขึ้นเพื่อทำนายโทเค็นที่ตามมา ซึ่งจะช่วยเร่งความเร็วโดยรวมของการสร้างข้อความในขณะที่ยังคงรักษาคุณภาพของเนื้อหาที่สร้างขึ้นใกล้กับการกระจายเป้าหมาย
เป็นสิ่งสำคัญมากที่โทเค็นที่สร้างโดยโมเดลขนาดเล็กจะไม่ถูกปฏิเสธอย่างต่อเนื่อง ในกรณีนี้จะทำให้ประสิทธิภาพลดลงแทนที่จะปรับปรุง จากการทดลองและลักษณะของกรณีการใช้งาน เราสามารถเลือกแบบจำลองที่เล็กลง/แนะนำการถอดรหัสแบบเก็งกำไรในกระบวนการอนุมาน
บทสรุป
การเดินทางผ่านเทคนิคขั้นสูงในการปรับปรุงปริมาณงานของโมเดลภาษาขนาดใหญ่ (LLM) ช่วยให้มองเห็นเส้นทางข้างหน้าในขอบเขตของการประมวลผลภาษาธรรมชาติ ซึ่งไม่เพียงแต่แสดงให้เห็นถึงความท้าทายเท่านั้น แต่ยังรวมถึงโซลูชั่นเชิงนวัตกรรมที่สามารถตอบสนองความท้าทายเหล่านั้นได้โดยตรง เทคนิคเหล่านี้ ตั้งแต่การต่อเนื่องเป็นชุดไปจนถึง Paged และ Flash Attention และวิธีการที่น่าสนใจของการถอดรหัสแบบเก็งกำไร เป็นมากกว่าการปรับปรุงแบบค่อยเป็นค่อยไป สิ่งเหล่านี้แสดงถึงการก้าวกระโดดครั้งสำคัญในความสามารถของเราในการสร้างโมเดลภาษาขนาดใหญ่ได้เร็วขึ้น มีประสิทธิภาพมากขึ้น และเข้าถึงได้มากขึ้นในท้ายที่สุดสำหรับแอปพลิเคชันที่หลากหลาย
ความสำคัญของความก้าวหน้าเหล่านี้ไม่สามารถกล่าวเกินจริงได้ ในการเพิ่มประสิทธิภาพปริมาณงาน LLM และปรับปรุงประสิทธิภาพ เราไม่เพียงแค่ปรับแต่งเครื่องยนต์ของรุ่นที่ทรงพลังเหล่านี้เท่านั้น เรากำลังกำหนดนิยามใหม่ให้กับสิ่งที่เป็นไปได้ในแง่ของความเร็วและประสิทธิภาพในการประมวลผล ในทางกลับกัน นี่จะเป็นการเปิดโลกทัศน์ใหม่สำหรับการประยุกต์ใช้โมเดลภาษาขนาดใหญ่ ตั้งแต่บริการแปลภาษาแบบเรียลไทม์ที่สามารถทำงานด้วยความเร็วของการสนทนา ไปจนถึงเครื่องมือวิเคราะห์ขั้นสูงที่สามารถประมวลผลชุดข้อมูลจำนวนมหาศาลด้วยความเร็วที่ไม่เคยมีมาก่อน
นอกจากนี้ เทคนิคเหล่านี้ยังเน้นย้ำถึงความสำคัญของแนวทางที่สมดุลในการเพิ่มประสิทธิภาพโมเดลภาษาขนาดใหญ่ ซึ่งเป็นแนวทางที่พิจารณาอย่างรอบคอบถึงอิทธิพลซึ่งกันและกันระหว่างความเร็ว ความแม่นยำ และทรัพยากรการคำนวณ ขณะที่เราขยายขอบเขตความสามารถของ LLM การรักษาสมดุลนี้จะเป็นสิ่งสำคัญสำหรับการรับประกันว่าโมเดลเหล่านี้จะยังคงทำหน้าที่เป็นเครื่องมือที่หลากหลายและเชื่อถือได้ในอุตสาหกรรมต่างๆ มากมาย
เทคนิคขั้นสูงในการปรับปรุงปริมาณงานของโมเดลภาษาขนาดใหญ่เป็นมากกว่าความสำเร็จทางเทคนิค สิ่งเหล่านี้ถือเป็นเหตุการณ์สำคัญในการพัฒนาปัญญาประดิษฐ์อย่างต่อเนื่อง พวกเขาสัญญาว่าจะทำให้ LLM ปรับตัวได้มากขึ้น มีประสิทธิภาพมากขึ้น และมีประสิทธิภาพมากขึ้น โดยปูทางไปสู่นวัตกรรมในอนาคตที่จะยังคงเปลี่ยนแปลงภูมิทัศน์ดิจิทัลของเราต่อไป
อ่านเพิ่มเติมเกี่ยวกับสถาปัตยกรรม GPU สำหรับการเพิ่มประสิทธิภาพการอนุมานโมเดลภาษาขนาดใหญ่ในบล็อกโพสต์ล่าสุดของเรา