
การแยกข้อมูลอัตโนมัติ: เครื่องมือ กลยุทธ์ และความท้าทาย
เผยแพร่แล้ว: 2024-03-21ข้อมูลเบื้องต้นเกี่ยวกับระบบอัตโนมัติในการแยกข้อมูล
ในขอบเขตแบบไดนามิกของธุรกิจร่วมสมัยที่ขับเคลื่อนด้วยข้อมูล กระบวนการดึงข้อมูลมีความสำคัญสูงสุด โดยเกี่ยวข้องกับการดึงข้อมูลเชิงลึกที่เกี่ยวข้องจากแหล่งข้อมูลที่ไม่มีโครงสร้างหรือกึ่งโครงสร้างที่หลากหลาย การทำงานอัตโนมัตินี้สามารถเพิ่มประสิทธิภาพ ลดข้อผิดพลาด และประหยัดเวลาได้อย่างมาก ขับเคลื่อนโดยเครื่องมือซอฟต์แวร์ ระบบอัตโนมัติในการดึงข้อมูลทำงานโดยอัตโนมัติ ระบุและเปรียบเทียบข้อมูลได้อย่างเชี่ยวชาญ ปราศจากการแทรกแซงของมนุษย์ การใช้งานจะปฏิวัติขั้นตอนการทำงานในภาคส่วนต่างๆ ที่หลากหลาย เช่น การธนาคาร การดูแลสุขภาพ และอีคอมเมิร์ซ ซึ่งอำนวยความสะดวกในการตัดสินใจโดยใช้ข้อมูลรอบด้านและการมองการณ์ไกลเชิงกลยุทธ์
วิวัฒนาการของเทคโนโลยีการแยกข้อมูล
วิวัฒนาการของเทคโนโลยีการแยกข้อมูลมีความโดดเด่น โดยตอบสนองความต้องการระบบอัตโนมัติในอุตสาหกรรมต่างๆ ที่เพิ่มขึ้น เริ่มแรกอาศัยกระบวนการแบบแมนนวล เช่น การป้อนข้อมูลทางกายภาพ การประมวลผลได้นำการรู้จำอักขระด้วยแสง (OCR) มาใช้ ซึ่งทำให้สามารถแปลงข้อความเป็นรูปแบบที่เข้ารหัสด้วยเครื่องได้ ความก้าวหน้าเพิ่มเติม เช่น การรู้จำอักขระอัจฉริยะ (ICR) และการรู้จำเอกสารอัจฉริยะ (IDR) ปรับปรุงความแม่นยำโดยการเรียนรู้จากการแก้ไข
ความก้าวหน้าอย่างต่อเนื่องซึ่งแสดงให้เห็นผ่านการรู้จำอักขระอัจฉริยะ (ICR) และการรู้จำเอกสารอัจฉริยะ (IDR) ได้เพิ่มความแม่นยำให้มากขึ้นโดยการบูรณาการข้อเสนอแนะเชิงแก้ไข การเพิ่มขึ้นของปัญญาประดิษฐ์ (AI) และการเรียนรู้ของเครื่อง (ML) ถือเป็นการประกาศยุคที่ก้าวล้ำ โดยเตรียมเทคโนโลยีเหล่านี้เพื่อวิเคราะห์รูปแบบข้อมูลที่ซับซ้อน รับข้อมูลเชิงลึกอันมีค่าจากแหล่งข้อมูลที่ไม่มีโครงสร้าง และเข้าใจภาษาธรรมชาติ เครื่องมืออัตโนมัติสมัยใหม่สามารถจัดการประเภทเอกสารและโครงสร้างข้อมูลที่หลากหลายได้อย่างเชี่ยวชาญ จึงช่วยเพิ่มประสิทธิภาพและความแม่นยำ
การประมวลผลแบบคลาวด์ยังมีบทบาทสำคัญในการเปิดใช้โซลูชันที่ปรับขนาดได้ซึ่งจัดการข้อมูลจำนวนมหาศาลและส่งเสริมการทำงานร่วมกันระดับโลก การพัฒนาอย่างต่อเนื่องเน้นที่การประมวลผลแบบเรียลไทม์และการวิเคราะห์เชิงคาดการณ์ ซึ่งกำหนดอนาคตของการดึงข้อมูล
เครื่องมือสำคัญสำหรับการดึงข้อมูลอัตโนมัติ
เพื่อให้การแยกข้อมูลเป็นอัตโนมัติอย่างมีประสิทธิภาพ มีการใช้เครื่องมือต่างๆ:
- เครื่องมือขูดเว็บ: ซอฟต์แวร์เช่น Octoparse หรือ Import.io อนุญาตให้รวบรวมข้อมูลจากหน้าเว็บโดยอัตโนมัติ
- ซอฟต์แวร์ ETL (แยก แปลง โหลด): เครื่องมือ เช่น Talend หรือ Informatica อำนวยความสะดวกในการดึงข้อมูลจากหลายแหล่ง การแปลงข้อมูล และการโหลดลงในฐานข้อมูล
- Optical Character Recognition (OCR): เครื่องมือ เช่น ABBYY FlexiCapture หรือ Tesseract ช่วยในการแปลงเอกสารประเภทต่างๆ เช่น กระดาษที่สแกน ให้เป็นข้อมูลที่แก้ไขและค้นหาได้
- APIs (Application Programming Interfaces): ช่วยให้สามารถดึงข้อมูลอัตโนมัติจากบริการเว็บหรือแอปพลิเคชันได้
- Robotic Process Automation (RPA): เครื่องมือ RPA เช่น UiPath หรือ Blue Prism ช่วยให้สามารถสร้างบอทที่เลียนแบบการโต้ตอบของมนุษย์เพื่อดึงข้อมูลจากแหล่งต่างๆ
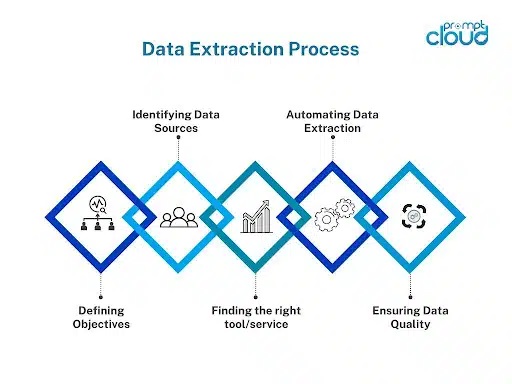
กลยุทธ์เพื่อการเก็บเกี่ยวข้อมูลอย่างมีประสิทธิภาพ
- ระบุวัตถุประสงค์ที่ชัดเจน: การทำความเข้าใจเป้าหมายสุดท้ายจะช่วยปรับแต่งการเก็บเกี่ยวข้อมูลได้อย่างเหมาะสม ทำให้มั่นใจได้ถึงความเกี่ยวข้องและประสิทธิภาพ
- เลือกเครื่องมือที่เหมาะสม: เลือกซอฟต์แวร์ที่ให้ความสมดุลระหว่างการปรับแต่งและความเป็นมิตรต่อผู้ใช้
- มั่นใจในคุณภาพของข้อมูล: ใช้กฎการตรวจสอบเพื่อรักษาความถูกต้องและความสม่ำเสมอในข้อมูลที่รวบรวม
- เคารพกฎหมายความเป็นส่วนตัว: ปฏิบัติตามแนวทางทางกฎหมายอย่างเคร่งครัดเพื่อหลีกเลี่ยงผลกระทบทางจริยธรรมและกฎหมาย
- ทำให้เป็นอัตโนมัติเมื่อเป็นไปได้: ใช้ประโยชน์จากระบบอัตโนมัติเพื่อปรับปรุงกระบวนการต่างๆ แต่ยังคงควบคุมดูแลเพื่อแก้ไขความผิดปกติที่อาจเกิดขึ้น
- อัปเดตโปรโตคอลเป็นประจำ: แหล่งข้อมูลและรูปแบบเปลี่ยนแปลง กิจวัตรต้องพัฒนาเพื่อให้ก้าวทัน
- รวมโซลูชันที่ปรับขนาดได้: เมื่อความต้องการข้อมูลเพิ่มขึ้น ระบบควรจะสามารถรองรับปริมาณที่เพิ่มขึ้นได้โดยไม่สูญเสียประสิทธิภาพ
- ติดตามและประเมินผล: ประเมินขั้นตอนและผลลัพธ์อย่างต่อเนื่อง ปรับแต่งกลยุทธ์เพื่อการปรับปรุงอย่างต่อเนื่อง
บทบาทของปัญญาประดิษฐ์ในการสกัดข้อมูล
ปัญญาประดิษฐ์ (AI) แปลงโฉมการดึงข้อมูลโดยเปิดใช้งานระบบอัตโนมัติอัจฉริยะ เทคโนโลยี AI เช่น การเรียนรู้ของเครื่องและการประมวลผลภาษาธรรมชาติ (NLP) ช่วยให้ระบบสามารถเรียนรู้จากรูปแบบข้อมูลและปรับปรุงเมื่อเวลาผ่านไป ความสามารถในการเรียนรู้นี้ช่วยเพิ่มความแม่นยำของข้อมูลที่ดึงมา เครื่องมือที่ขับเคลื่อนด้วย AI สามารถ:

ที่มา: pollthepeople.app
- ระบุข้อมูลที่เกี่ยวข้องจากแหล่งที่มาต่างๆ
- ทำความเข้าใจและตีความเอกสารที่ซับซ้อน รวมถึงข้อมูลที่ไม่มีโครงสร้าง
- จำแนกประเภทและจัดทำดัชนีข้อมูลโดยอัตโนมัติ
- ลดข้อผิดพลาดด้วยตนเองโดยการตรวจสอบความถูกต้องของข้อมูลที่แยกออกมากับรูปแบบที่เรียนรู้
- ปรับให้เข้ากับเอกสารประเภทใหม่โดยไม่ต้องเขียนโปรแกรมอย่างชัดเจน
ด้วยการรวม AI เข้าด้วยกัน กระบวนการดึงข้อมูลจะมีประสิทธิภาพ ปรับขนาดได้ และแม่นยำยิ่งขึ้น ซึ่งขับเคลื่อนมูลค่าที่สำคัญให้กับองค์กรทั่วทั้งอุตสาหกรรม
ความท้าทายที่ต้องเผชิญในการดึงข้อมูลอัตโนมัติ
การดึงข้อมูลอัตโนมัติไม่ใช่อุปสรรค มักเกี่ยวข้องกับโครงสร้างข้อมูลที่ซับซ้อนซึ่งไม่ได้มาตรฐาน ทำให้เกิดความท้าทายที่สำคัญ:
- คุณภาพและความสม่ำเสมอของข้อมูล: ระบบอัตโนมัติจะต้องจัดการกับข้อมูลที่มักไม่มีโครงสร้าง ไม่สมบูรณ์ หรือไม่สอดคล้องกัน ซึ่งจำเป็นต้องใช้อัลกอริธึมที่ซับซ้อนเพื่อให้แน่ใจว่ามีการดึงข้อมูลที่แม่นยำ
- การแยกไฟล์ PDF: ข้อมูลภายใน PDF อาจเป็นเรื่องที่ท้าทายอย่างยิ่ง เนื่องจากมีเค้าโครงที่หลากหลายและรูปภาพที่ฝังไว้
- ความแปรปรวนในรูปแบบและแหล่งที่มา: เครื่องมือแยกข้อมูลต้องสามารถปรับให้เข้ากับรูปแบบต่างๆ มากมายและแหล่งข้อมูลที่เปลี่ยนแปลงตลอดเวลา
- การจัดการข้อมูลขนาดใหญ่: การประมวลผลข้อมูลปริมาณมากอย่างรวดเร็วและมีประสิทธิภาพต้องใช้ระบบที่แข็งแกร่งพร้อมพลังการคำนวณที่สำคัญ
- ความสามารถในการปรับขนาดของซอฟต์แวร์: เนื่องจากความต้องการข้อมูลขององค์กรเพิ่มขึ้น ระบบการแยกข้อมูลจึงต้องปรับขนาดตามนั้นโดยไม่ทำให้ประสิทธิภาพลดลง
- การบูรณาการกับระบบที่มีอยู่: การตรวจสอบให้แน่ใจว่ากระบวนการแยกข้อมูลสามารถรวมเข้ากับฐานข้อมูลและเวิร์กโฟลว์ปัจจุบันได้อย่างราบรื่นถือเป็นสิ่งสำคัญแต่มักจะซับซ้อน
- การปฏิบัติตามกฎระเบียบ: การปฏิบัติตามกฎหมายความเป็นส่วนตัวและข้อบังคับอุตสาหกรรม เช่น GDPR หรือ HIPAA เมื่อแยกและประมวลผลข้อมูลจะเพิ่มความซับซ้อนอีกชั้น
แนวทางปฏิบัติที่ดีที่สุดสำหรับการนำโซลูชันข้อมูลไปใช้
- เริ่มต้นด้วยวัตถุประสงค์ที่ชัดเจน: กำหนดเป้าหมายและวัตถุประสงค์ที่ชัดเจนสำหรับสิ่งที่การแยกข้อมูลควรบรรลุ
- เลือกเครื่องมือที่เหมาะสม: ประเมินและเลือกเครื่องมือที่สอดคล้องกับประเภทข้อมูล ปริมาณ และความซับซ้อนของงาน
- มุ่งเน้นไปที่คุณภาพข้อมูล: ใช้กฎการตรวจสอบเพื่อรับรองความถูกต้องและความสมบูรณ์ของข้อมูลที่แยกออกมา
- ตรวจสอบการปฏิบัติตามข้อกำหนด: พิจารณาข้อกำหนดด้านกฎระเบียบทั้งหมดที่เกี่ยวข้องกับความเป็นส่วนตัวและการปกป้องข้อมูลในระหว่างกระบวนการแยกข้อมูล
- แผนสำหรับความสามารถในการขยายขนาด: คาดการณ์ความต้องการข้อมูลในอนาคตและเลือกโซลูชันที่สามารถปรับขนาดตามธุรกิจของคุณได้
- การทดสอบซ้ำ: ดำเนินการทดสอบอย่างละเอียดเป็นระยะเพื่อตรวจจับข้อผิดพลาดตั้งแต่เนิ่นๆ และปรับปรุงกระบวนการ
- ฝึกอบรมพนักงานอย่างเพียงพอ: ให้การฝึกอบรมและทรัพยากรที่ครอบคลุมสำหรับพนักงานที่เกี่ยวข้องกับการดึงข้อมูล
- การตรวจสอบและปรับปรุงอย่างต่อเนื่อง: ตรวจสอบระบบอย่างสม่ำเสมอเพื่อประสิทธิภาพและทำการปรับปรุงที่จำเป็น
บทสรุป
ข้อมูลอัตโนมัติเป็นตัวอย่างที่ชัดเจนของโดเมนไดนามิก โดยที่เครื่องมือและกลยุทธ์ระดับแนวหน้าจะต้องสอดคล้องกับความท้าทายเชิงปฏิบัติที่มีพื้นฐาน ในการสำรวจภูมิทัศน์ที่มีหลายแง่มุมนี้ องค์กรต่างๆ จะได้รับมอบหมายให้บูรณาการเทคโนโลยีล้ำสมัยได้อย่างราบรื่น ขณะเดียวกันก็เผชิญกับปัญหาด้านความถูกต้อง ความสามารถในการขยายขนาด และประสิทธิภาพด้านต้นทุน วัตถุประสงค์โดยรวมยังคงเป็นการสังเคราะห์ศักยภาพของระบบอัตโนมัติด้วยลัทธิปฏิบัตินิยมที่จำเป็นสำหรับการดำเนินการอย่างมีชัย เพื่อให้มั่นใจว่าการแสวงหานวัตกรรมยังคงพึ่งพาอาศัยกัน โดยมีความเสถียรในการดำเนินงานและความน่าเชื่อถือที่ไม่เปลี่ยนแปลง
สำหรับโซลูชันการแยกข้อมูลแบบกำหนดเอง โปรดติดต่อที่ [email protected]