
แนวปฏิบัติที่ดีที่สุดและกรณีการใช้งานสำหรับการดึงข้อมูลจากเว็บไซต์
เผยแพร่แล้ว: 2023-12-28เมื่อดึงข้อมูลจากเว็บไซต์ จำเป็นต้องปฏิบัติตามกฎระเบียบและกรอบการทำงานของไซต์เป้าหมาย การปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดไม่เพียงแต่เป็นเรื่องของจริยธรรมเท่านั้น แต่ยังช่วยหลีกเลี่ยงปัญหาทางกฎหมายและรับประกันความน่าเชื่อถือของการดึงข้อมูล ข้อควรพิจารณาที่สำคัญมีดังนี้:
- ปฏิบัติตาม robots.txt : ตรวจสอบไฟล์นี้ก่อนทุกครั้งเพื่อทำความเข้าใจว่าเจ้าของไซต์ได้กำหนดขีดจำกัดในการคัดลอกไว้อย่างไร
- ใช้ API : หากมี ให้ใช้ API อย่างเป็นทางการของเว็บไซต์ ซึ่งเป็นวิธีการเข้าถึงข้อมูลที่มีความเสถียรและได้รับการอนุมัติมากกว่า
- คำนึงถึงอัตราการร้องขอ : การคัดลอกข้อมูลที่มากเกินไปสามารถสร้างภาระให้กับเซิร์ฟเวอร์เว็บไซต์ได้ ดังนั้นให้ดำเนินการตามคำขอของคุณอย่างรอบคอบ
- ระบุตัวตน : โปรดโปร่งใสเกี่ยวกับตัวตนและวัตถุประสงค์ของคุณเมื่อทำการคัดลอกผ่านสตริงตัวแทนผู้ใช้ของคุณ
- จัดการข้อมูลอย่างมีความรับผิดชอบ : จัดเก็บและใช้ข้อมูลที่คัดลอกมาตามกฎหมายความเป็นส่วนตัวและข้อบังคับการปกป้องข้อมูล
การปฏิบัติตามแนวทางปฏิบัติเหล่านี้ช่วยให้มั่นใจได้ถึงการคัดลอกอย่างมีจริยธรรม รักษาความสมบูรณ์และความพร้อมใช้งานของเนื้อหาออนไลน์
การทำความเข้าใจกรอบกฎหมาย
เมื่อดึงข้อมูลจากเว็บไซต์ จำเป็นอย่างยิ่งที่จะต้องปฏิบัติตามข้อจำกัดทางกฎหมายที่เกี่ยวพันกัน เนื้อหาทางกฎหมายที่สำคัญได้แก่:
- พระราชบัญญัติการฉ้อโกงและการใช้คอมพิวเตอร์ในทางที่ผิด (CFAA): กฎหมายในสหรัฐอเมริกา ทำให้การเข้าถึงคอมพิวเตอร์โดยไม่ได้รับอนุญาตอย่างเหมาะสมถือเป็นเรื่องผิดกฎหมาย
- กฎระเบียบคุ้มครองข้อมูลทั่วไป (GDPR) ของสหภาพยุโรป : มอบอำนาจให้ยินยอมในการใช้ข้อมูลส่วนบุคคลและให้สิทธิ์บุคคลในการควบคุมข้อมูลของตน
- พระราชบัญญัติลิขสิทธิ์แห่งสหัสวรรษดิจิทัล (DMCA) : ป้องกันการเผยแพร่เนื้อหาที่มีลิขสิทธิ์โดยไม่ได้รับอนุญาต
เครื่องขูดต้องเคารพข้อตกลง 'ข้อกำหนดการใช้งาน' ของเว็บไซต์ ซึ่งมักจะจำกัดการดึงข้อมูล การปฏิบัติตามกฎหมายและนโยบายเหล่านี้ถือเป็นสิ่งสำคัญในการทำลายข้อมูลเว็บไซต์อย่างมีจริยธรรมและถูกกฎหมาย
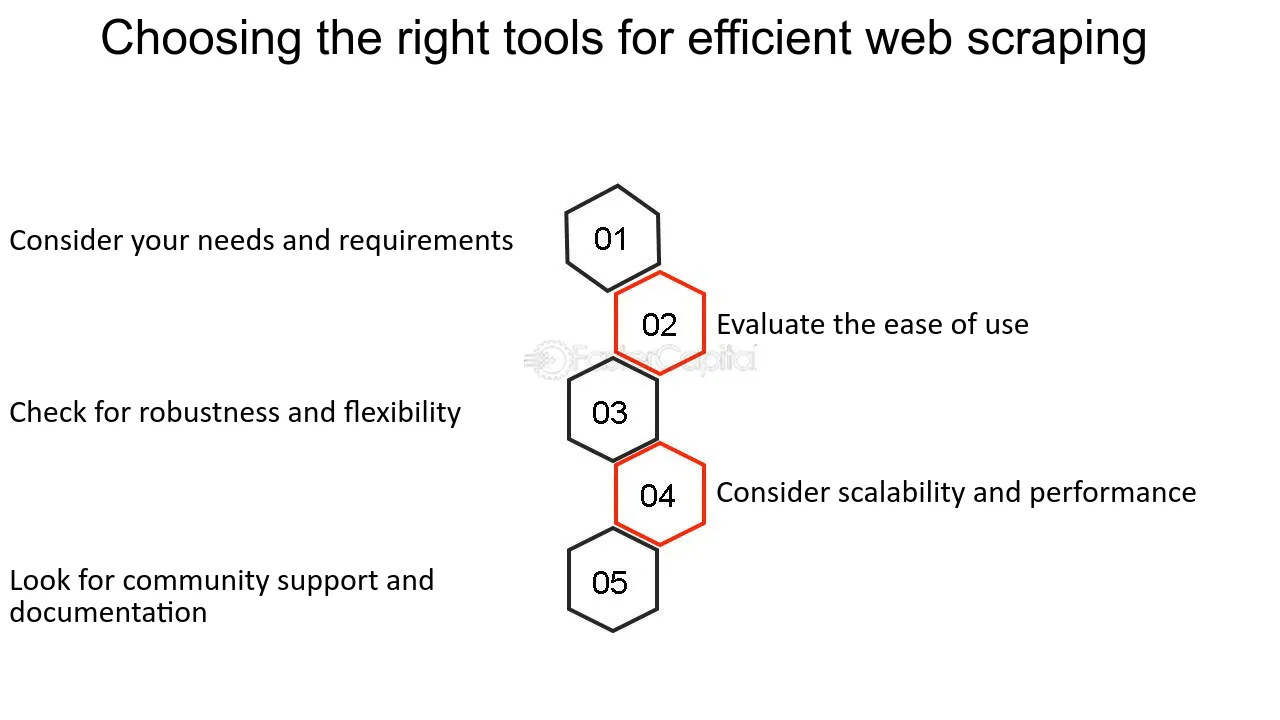
การเลือกเครื่องมือที่เหมาะสมสำหรับการขูด
การเลือกเครื่องมือที่ถูกต้องเป็นสิ่งสำคัญเมื่อเริ่มต้นโครงการขูดเว็บ ปัจจัยที่ต้องพิจารณา ได้แก่ :
- ความซับซ้อนของเว็บไซต์ : ไซต์ไดนามิกอาจต้องใช้เครื่องมือเช่น Selenium ที่สามารถโต้ตอบกับ JavaScript ได้
- ปริมาณข้อมูล : สำหรับการขูดขนาดใหญ่ แนะนำให้ใช้เครื่องมือที่มีความสามารถในการขูดแบบกระจาย เช่น Scrapy
- ความถูกต้องตามกฎหมายและจริยธรรม : เลือกเครื่องมือที่มีคุณสมบัติตาม robots.txt และตั้งค่าสตริงตัวแทนผู้ใช้
- ใช้งานง่าย : มือใหม่อาจชอบอินเทอร์เฟซที่ใช้งานง่ายที่พบในซอฟต์แวร์เช่น Octoparse
- ความรู้ด้านการเขียนโปรแกรม : ผู้ที่ไม่ใช่ผู้เขียนโค้ดอาจหันไปใช้ซอฟต์แวร์ที่มี GUI ในขณะที่โปรแกรมเมอร์สามารถเลือกใช้ไลบรารีเช่น BeautifulSoup
ที่มาของภาพ: https://fastercapital.com/
แนวทางปฏิบัติที่ดีที่สุดในการคัดลอกข้อมูลจากเว็บไซต์อย่างมีประสิทธิภาพ
หากต้องการดึงข้อมูลจากเว็บไซต์อย่างมีประสิทธิภาพและมีความรับผิดชอบ ให้ปฏิบัติตามหลักเกณฑ์เหล่านี้:
- เคารพไฟล์ robots.txt และข้อกำหนดของเว็บไซต์เพื่อหลีกเลี่ยงปัญหาทางกฎหมาย
- ใช้ส่วนหัวและหมุนเวียนตัวแทนผู้ใช้เพื่อเลียนแบบพฤติกรรมของมนุษย์
- ใช้ความล่าช้าระหว่างคำขอเพื่อลดภาระของเซิร์ฟเวอร์
- ใช้พรอกซีเพื่อป้องกันการแบน IP
- ขูดในช่วงเวลานอกเวลาเร่งด่วนเพื่อลดการหยุดชะงักของเว็บไซต์
- จัดเก็บข้อมูลอย่างมีประสิทธิภาพเสมอ หลีกเลี่ยงรายการที่ซ้ำกัน
- ตรวจสอบความถูกต้องของข้อมูลที่คัดลอกมาด้วยการตรวจสอบอย่างสม่ำเสมอ
- โปรดคำนึงถึงกฎหมายความเป็นส่วนตัวของข้อมูลเมื่อจัดเก็บและใช้ข้อมูล
- อัปเดตเครื่องมือขูดของคุณให้ทันสมัยอยู่เสมอเพื่อรับมือกับการเปลี่ยนแปลงเว็บไซต์
- เตรียมพร้อมเสมอที่จะปรับกลยุทธ์การขูดหากเว็บไซต์อัปเดตโครงสร้างของตน
กรณีการใช้งานการขูดข้อมูลในอุตสาหกรรมต่างๆ
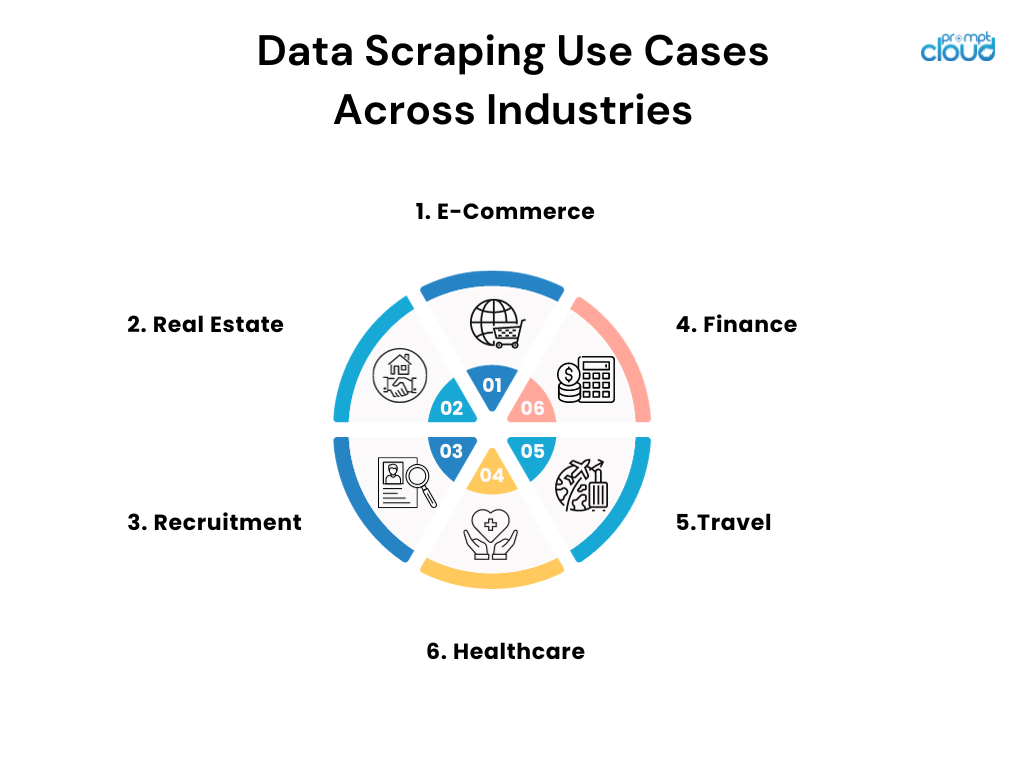
- อีคอมเมิร์ซ: ผู้ค้าปลีกออนไลน์ใช้การขูดเพื่อติดตามราคาของคู่แข่งและปรับกลยุทธ์การกำหนดราคาให้เหมาะสม
- อสังหาริมทรัพย์: ตัวแทนและบริษัทคัดแยกรายการเพื่อรวบรวมข้อมูลอสังหาริมทรัพย์ แนวโน้ม และข้อมูลราคาจากแหล่งต่างๆ
- การสรรหาบุคลากร: บริษัทต่างๆ ขูดกระดานงานและโซเชียลมีเดียเพื่อค้นหาผู้สมัครที่มีศักยภาพและวิเคราะห์แนวโน้มของตลาดงาน
- การเงิน: นักวิเคราะห์จะคัดลอกบันทึกสาธารณะและเอกสารทางการเงินเพื่อแจ้งกลยุทธ์การลงทุนและติดตามความเชื่อมั่นของตลาด
- การเดินทาง: เอเจนซี่ขูดราคาสายการบินและโรงแรมเพื่อมอบข้อเสนอและแพ็คเกจที่ดีที่สุดแก่ลูกค้า
- การดูแลสุขภาพ: นักวิจัยดึงฐานข้อมูลและวารสารทางการแพทย์เพื่อรับทราบข้อมูลล่าสุดเกี่ยวกับการค้นพบล่าสุดและการทดลองทางคลินิก
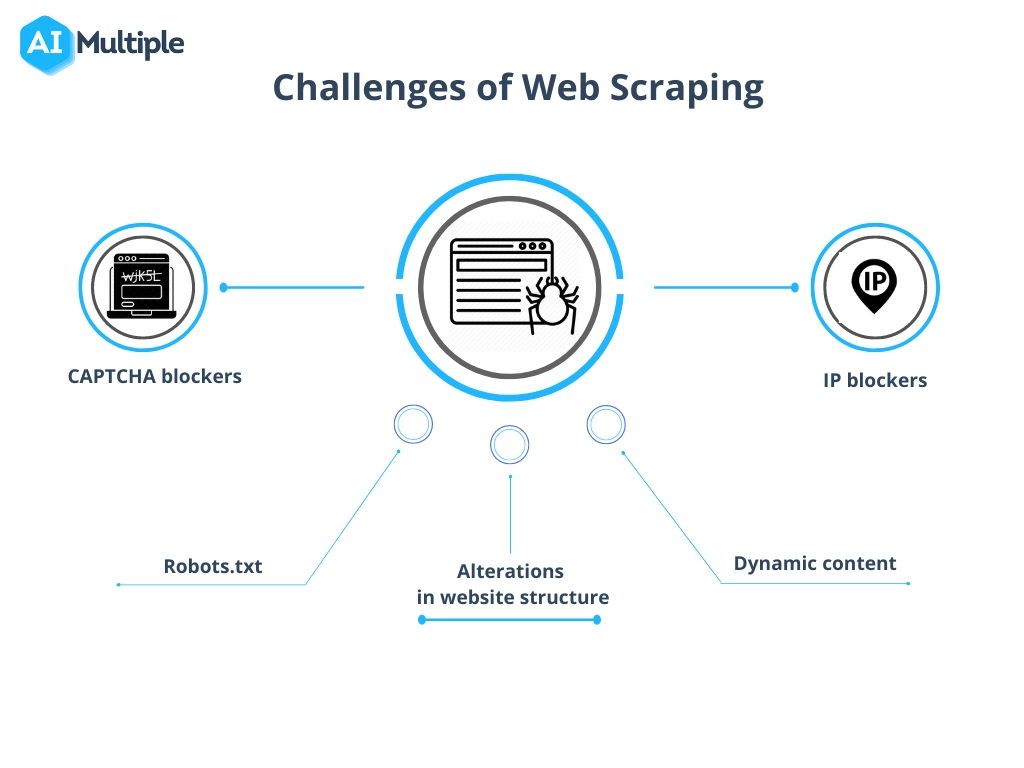
จัดการกับความท้าทายทั่วไปในการขูดข้อมูล
กระบวนการดึงข้อมูลจากเว็บไซต์ แม้จะมีคุณค่ามหาศาล แต่บ่อยครั้งเกี่ยวข้องกับการเอาชนะอุปสรรคต่างๆ เช่น การเปลี่ยนแปลงโครงสร้างเว็บไซต์ มาตรการป้องกันการคัดลอก และความกังวลเกี่ยวกับคุณภาพของข้อมูล

ที่มาของภาพ: https://research.aimultiple.com/
เพื่อนำทางสิ่งเหล่านี้อย่างมีประสิทธิภาพ:
- ปรับตัวอยู่เสมอ : อัปเดตสคริปต์ขูดเป็นประจำเพื่อให้ตรงกับการอัปเดตเว็บไซต์ การใช้การเรียนรู้ของเครื่องสามารถช่วยปรับให้เข้ากับการเปลี่ยนแปลงโครงสร้างแบบไดนามิกได้
- เคารพขอบเขตทางกฎหมาย : ทำความเข้าใจและปฏิบัติตามกฎหมายของการขูดเพื่อหลีกเลี่ยงการดำเนินคดี อย่าลืมตรวจสอบไฟล์ robots.txt และข้อกำหนดในการให้บริการบนเว็บไซต์
- ท็อปฟอร์ม
- เลียนแบบปฏิสัมพันธ์ของมนุษย์ : เว็บไซต์อาจบล็อกสแครปเปอร์ที่ส่งคำขอเร็วเกินไป ใช้ความล่าช้าและช่วงเวลาสุ่มระหว่างคำขอเพื่อให้ดูเหมือนหุ่นยนต์น้อยลง
- จัดการ CAPTCHA : มีเครื่องมือและบริการที่สามารถแก้ไขหรือเลี่ยง CAPTCHA ได้ แม้ว่าการใช้งานจะต้องคำนึงถึงผลกระทบทางจริยธรรมและกฎหมายก็ตาม
- รักษาความสมบูรณ์ของข้อมูล : ตรวจสอบความถูกต้องของข้อมูลที่แยกออกมา ตรวจสอบข้อมูลอย่างสม่ำเสมอและทำความสะอาดเพื่อรักษาคุณภาพและประโยชน์
กลยุทธ์เหล่านี้ช่วยในการเอาชนะอุปสรรคในการคัดลอกข้อมูลทั่วไป และอำนวยความสะดวกในการดึงข้อมูลอันมีค่า
บทสรุป
การดึงข้อมูลจากเว็บไซต์อย่างมีประสิทธิภาพเป็นวิธีการที่มีคุณค่าพร้อมการใช้งานที่หลากหลาย ตั้งแต่การวิจัยตลาดไปจนถึงการวิเคราะห์การแข่งขัน สิ่งสำคัญคือต้องปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุด รับรองความถูกต้องตามกฎหมาย เคารพหลักเกณฑ์ของ robots.txt และควบคุมความถี่ในการคัดลอกอย่างระมัดระวังเพื่อป้องกันการโอเวอร์โหลดของเซิร์ฟเวอร์
การใช้วิธีการเหล่านี้อย่างมีความรับผิดชอบจะเปิดประตูสู่แหล่งข้อมูลที่หลากหลายซึ่งสามารถให้ข้อมูลเชิงลึกที่นำไปใช้ได้จริง และขับเคลื่อนการตัดสินใจที่มีข้อมูลครบถ้วนสำหรับธุรกิจและบุคคลทั่วไป การใช้งานที่เหมาะสมควบคู่ไปกับการพิจารณาด้านจริยธรรม ช่วยให้มั่นใจได้ว่าการคัดลอกข้อมูลยังคงเป็นเครื่องมือที่ทรงพลังในภูมิทัศน์ดิจิทัล
พร้อมที่จะเพิ่มพูนข้อมูลเชิงลึกของคุณด้วยการดึงข้อมูลจากเว็บไซต์แล้วหรือยัง? ไม่ต้องมองอีกต่อไป! PromptCloud เสนอบริการขูดเว็บที่มีจริยธรรมและเชื่อถือได้ซึ่งปรับให้เหมาะกับความต้องการของคุณ เชื่อมต่อกับเราที่ sales@promptcloud.com เพื่อแปลงข้อมูลดิบให้เป็นข้อมูลอัจฉริยะที่นำไปปฏิบัติได้ มายกระดับการตัดสินใจของคุณไปด้วยกัน!
คำถามที่พบบ่อย
การขูดข้อมูลจากเว็บไซต์ยอมรับได้หรือไม่?
แน่นอนว่าการขูดข้อมูลเป็นเรื่องปกติ แต่คุณต้องเล่นตามกฎ ก่อนที่จะดำดิ่งสู่การผจญภัยแบบเจาะลึกใดๆ โปรดพิจารณาข้อกำหนดในการให้บริการและไฟล์ robots.txt ของเว็บไซต์ที่เป็นปัญหาให้ถี่ถ้วน การแสดงความเคารพต่อรูปแบบของเว็บไซต์ การยึดมั่นในขีดจำกัดความถี่ และการรักษาสิ่งที่ถูกต้องตามหลักจริยธรรม ล้วนเป็นกุญแจสำคัญในแนวทางปฏิบัติในการขูดข้อมูลอย่างมีความรับผิดชอบ
ฉันจะดึงข้อมูลผู้ใช้จากเว็บไซต์ผ่านการขูดได้อย่างไร
การดึงข้อมูลผู้ใช้ผ่านการขูดต้องใช้วิธีการที่พิถีพิถันเพื่อให้สอดคล้องกับบรรทัดฐานทางกฎหมายและจริยธรรม เมื่อใดก็ตามที่เป็นไปได้ ขอแนะนำให้ใช้ประโยชน์จาก API ที่เปิดเผยต่อสาธารณะซึ่งจัดทำโดยเว็บไซต์สำหรับการดึงข้อมูล ในกรณีที่ไม่มี API จำเป็นต้องตรวจสอบให้แน่ใจว่าวิธีการคัดลอกที่ใช้นั้นเป็นไปตามกฎหมายความเป็นส่วนตัว เงื่อนไขการใช้งาน และนโยบายที่กำหนดโดยเว็บไซต์ เพื่อลดผลกระทบทางกฎหมายที่อาจเกิดขึ้น
การขูดข้อมูลเว็บไซต์ถือว่าผิดกฎหมายหรือไม่?
ความถูกต้องตามกฎหมายของการขูดเว็บขึ้นอยู่กับปัจจัยหลายประการ รวมถึงวัตถุประสงค์ วิธีการ และการปฏิบัติตามกฎหมายที่เกี่ยวข้อง แม้ว่าการขูดเว็บนั้นไม่ได้ผิดกฎหมายโดยเนื้อแท้ การเข้าถึงโดยไม่ได้รับอนุญาต การละเมิดข้อกำหนดในการให้บริการของเว็บไซต์ หรือการเพิกเฉยต่อกฎหมายความเป็นส่วนตัวอาจนำไปสู่ผลทางกฎหมาย การดำเนินการที่มีความรับผิดชอบและมีจริยธรรมในกิจกรรมการขูดเว็บเป็นสิ่งสำคัญยิ่ง ซึ่งเกี่ยวข้องกับการตระหนักถึงขอบเขตทางกฎหมายและการพิจารณาด้านจริยธรรม
เว็บไซต์สามารถตรวจพบกรณีของการขูดเว็บได้หรือไม่
เว็บไซต์ได้ใช้กลไกในการตรวจจับและป้องกันกิจกรรมการขูดเว็บ องค์ประกอบการตรวจสอบ เช่น สตริงตัวแทนผู้ใช้ ที่อยู่ IP และรูปแบบคำขอ เพื่อบรรเทาการตรวจจับ แนวทางปฏิบัติที่ดีที่สุด ได้แก่ การใช้เทคนิคต่างๆ เช่น การหมุนเวียนตัวแทนผู้ใช้ การใช้พร็อกซี และการใช้ความล่าช้าแบบสุ่มระหว่างคำขอ อย่างไรก็ตาม สิ่งสำคัญคือต้องทราบว่าความพยายามที่จะหลีกเลี่ยงมาตรการตรวจจับอาจละเมิดข้อกำหนดในการให้บริการของเว็บไซต์ และอาจส่งผลให้เกิดผลทางกฎหมาย แนวทางปฏิบัติในการขูดเว็บอย่างมีความรับผิดชอบและมีจริยธรรม ให้ความสำคัญกับความโปร่งใสและการปฏิบัติตามมาตรฐานทางกฎหมายและจริยธรรม