
การดึงข้อมูลจากเว็บไซต์ไดนามิก: ความท้าทายและแนวทางแก้ไข
เผยแพร่แล้ว: 2023-11-23อินเทอร์เน็ตเป็นแหล่งเก็บข้อมูลที่กว้างขวางและขยายตัวอยู่เสมอ ซึ่งมอบมูลค่ามหาศาลให้กับธุรกิจ นักวิจัย และบุคคลที่แสวงหาข้อมูลเชิงลึก การตัดสินใจด้วยข้อมูลประกอบ หรือโซลูชันที่เป็นนวัตกรรม อย่างไรก็ตาม ข้อมูลอันล้ำค่าส่วนใหญ่อยู่ภายในเว็บไซต์แบบไดนามิก
เว็บไซต์ไดนามิกต่างจากเว็บไซต์คงที่ทั่วไปซึ่งสร้างเนื้อหาแบบไดนามิกเพื่อตอบสนองต่อปฏิสัมพันธ์ของผู้ใช้หรือเหตุการณ์ภายนอก ไซต์เหล่านี้ใช้ประโยชน์จากเทคโนโลยี เช่น JavaScript เพื่อจัดการเนื้อหาของหน้าเว็บ ทำให้เกิดความท้าทายที่น่ากลัวสำหรับเทคนิคการขูดเว็บแบบดั้งเดิมเพื่อดึงข้อมูลอย่างมีประสิทธิภาพ
ในบทความนี้ เราจะเจาะลึกเกี่ยวกับขอบเขตของการขูดหน้าเว็บแบบไดนามิก เราจะตรวจสอบความท้าทายทั่วไปที่เชื่อมโยงกับกระบวนการนี้ และนำเสนอกลยุทธ์ที่มีประสิทธิภาพและแนวทางปฏิบัติที่ดีที่สุดในการเอาชนะอุปสรรคเหล่านี้
ทำความเข้าใจเว็บไซต์ไดนามิก
ก่อนที่จะเจาะลึกความซับซ้อนของการขูดหน้าเว็บแบบไดนามิก จำเป็นอย่างยิ่งที่จะต้องสร้างความเข้าใจที่ชัดเจนเกี่ยวกับลักษณะของเว็บไซต์แบบไดนามิก ตรงกันข้ามกับเว็บไซต์คงที่ที่ให้เนื้อหาที่เหมือนกันในระดับสากล เว็บไซต์ไดนามิกจะสร้างเนื้อหาแบบไดนามิกตามพารามิเตอร์ต่างๆ เช่น การตั้งค่าของผู้ใช้ คำค้นหา หรือข้อมูลแบบเรียลไทม์
เว็บไซต์แบบไดนามิกมักจะใช้ประโยชน์จากเฟรมเวิร์ก JavaScript ที่ซับซ้อนเพื่อแก้ไขและอัปเดตเนื้อหาของหน้าเว็บในฝั่งไคลเอ็นต์แบบไดนามิก แม้ว่าแนวทางนี้จะช่วยเพิ่มการโต้ตอบของผู้ใช้ได้อย่างมาก แต่ก็ทำให้เกิดความท้าทายเมื่อพยายามดึงข้อมูลโดยทางโปรแกรม
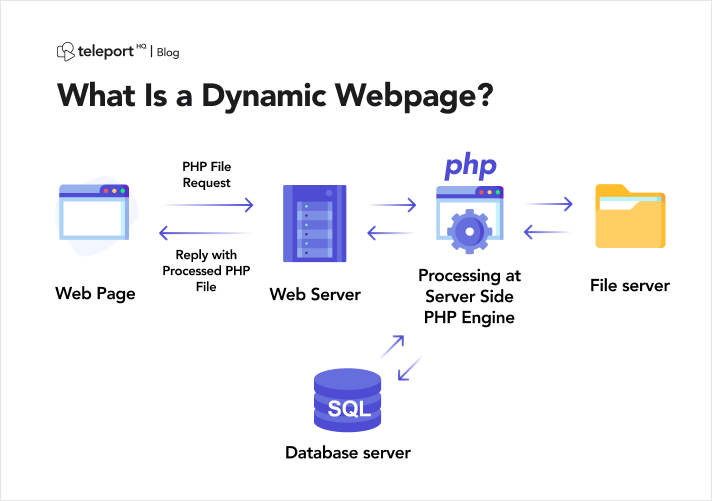
ที่มาของภาพ: https://teleporthq.io/
ความท้าทายทั่วไปในการขูดหน้าเว็บแบบไดนามิก
การขูดหน้าเว็บแบบไดนามิกทำให้เกิดความท้าทายหลายประการเนื่องจากธรรมชาติของเนื้อหาแบบไดนามิก ความท้าทายที่พบบ่อยที่สุดได้แก่:
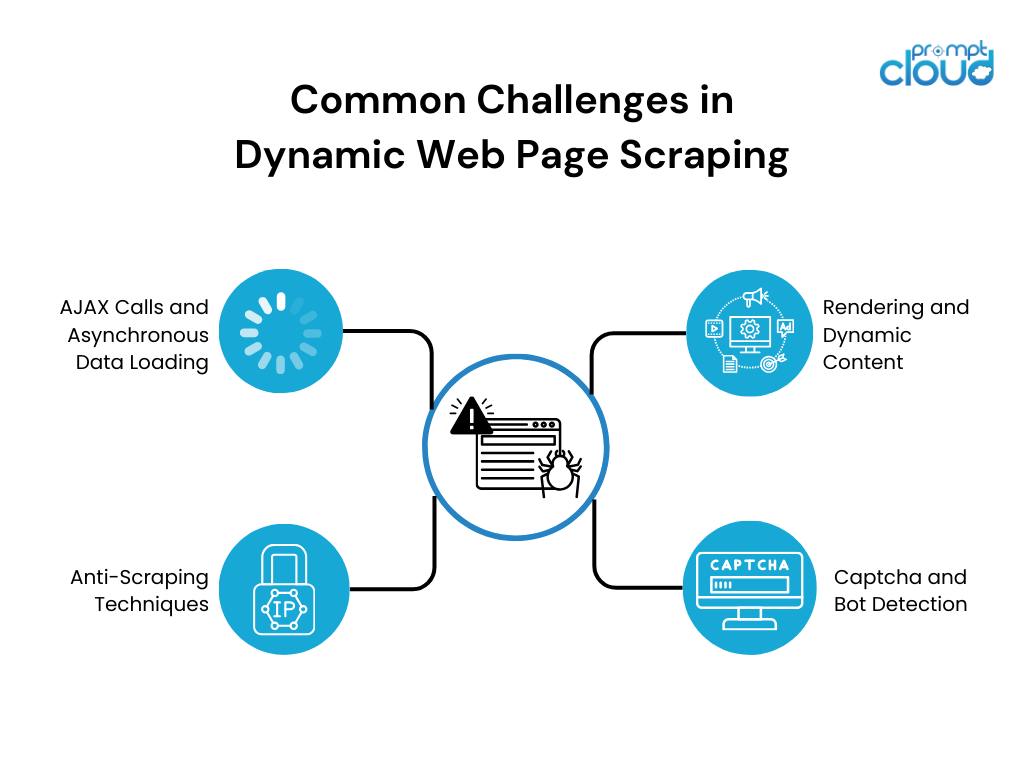
- การเรนเดอร์และเนื้อหาไดนามิก: เว็บไซต์ไดนามิกอาศัย JavaScript อย่างมากในเรนเดอร์เนื้อหาแบบไดนามิก เครื่องมือขูดเว็บแบบดั้งเดิมมีปัญหาในการโต้ตอบกับเนื้อหาที่ขับเคลื่อนด้วย JavaScript ส่งผลให้การแยกข้อมูลไม่สมบูรณ์หรือไม่ถูกต้อง
- การโทร AJAX และการโหลดข้อมูลแบบอะซิงโครนัส: เว็บไซต์ไดนามิกหลายแห่งใช้การเรียก JavaScript แบบอะซิงโครนัสและการเรียก XML (AJAX) เพื่อดึงข้อมูลจากเว็บเซิร์ฟเวอร์โดยไม่ต้องโหลดทั้งหน้าซ้ำ การโหลดข้อมูลแบบอะซิงโครนัสอาจทำให้ยากต่อการคัดลอกชุดข้อมูลทั้งหมด เนื่องจากอาจมีการโหลดอย่างต่อเนื่องหรือถูกกระตุ้นโดยการโต้ตอบของผู้ใช้
- การตรวจจับแคปต์ชาและบอท: เพื่อป้องกันการคัดลอกและปกป้องข้อมูล เว็บไซต์ใช้มาตรการตอบโต้ที่หลากหลาย เช่น กลไกการตรวจจับแคปต์ชาและบอท มาตรการรักษาความปลอดภัยเหล่านี้เป็นอุปสรรคต่อความพยายามในการขูดรีดและจำเป็นต้องมีกลยุทธ์เพิ่มเติมเพื่อเอาชนะ
- เทคนิคการป้องกันการขูด: เว็บไซต์ใช้เทคนิคการป้องกันการขูดหลายอย่าง เช่น การบล็อก IP การจำกัดอัตรา หรือโครงสร้าง HTML ที่สร้างความสับสนเพื่อยับยั้งการขูด เทคนิคเหล่านี้ต้องใช้กลยุทธ์การขูดแบบปรับเปลี่ยนได้เพื่อหลีกเลี่ยงการตรวจจับและขูดข้อมูลที่ต้องการได้สำเร็จ
กลยุทธ์สำหรับการขูดหน้าเว็บแบบไดนามิกที่ประสบความสำเร็จ
แม้จะมีความท้าทาย แต่ก็มีกลยุทธ์และเทคนิคหลายอย่างที่สามารถนำมาใช้เพื่อเอาชนะอุปสรรคที่ต้องเผชิญในขณะที่คัดลอกหน้าเว็บแบบไดนามิก กลยุทธ์เหล่านี้ประกอบด้วย:

- การใช้เบราว์เซอร์แบบไม่มีส่วนหัว: เบราว์เซอร์แบบไม่มีส่วนหัว เช่น Puppeteer หรือ Selenium ช่วยให้สามารถเรียกใช้ JavaScript และเรนเดอร์เนื้อหาไดนามิก ทำให้สามารถดึงข้อมูลจากเว็บไซต์ไดนามิกได้อย่างแม่นยำ
- การตรวจสอบการรับส่งข้อมูลเครือข่าย: การวิเคราะห์การรับส่งข้อมูลเครือข่ายสามารถให้ข้อมูลเชิงลึกเกี่ยวกับกระแสข้อมูลภายในเว็บไซต์แบบไดนามิก ความรู้นี้สามารถใช้เพื่อระบุการโทร AJAX สกัดกั้นการตอบสนอง และดึงข้อมูลที่จำเป็น
- การแยกวิเคราะห์เนื้อหาแบบไดนามิก: การแยกวิเคราะห์ DOM HTML หลังจากที่เนื้อหาแบบไดนามิกถูกแสดงผลโดย JavaScript สามารถช่วยในการแยกข้อมูลที่ต้องการได้ เครื่องมือต่างๆ เช่น Beautiful Soup หรือ Cheerio สามารถใช้ในการแยกวิเคราะห์และดึงข้อมูลจาก DOM ที่อัปเดตแล้ว
- การหมุนเวียน IP และพร็อกซี: การหมุนเวียนที่อยู่ IP และการใช้พรอกซีสามารถช่วยเอาชนะความท้าทายในการบล็อก IP และการจำกัดอัตรา ช่วยให้สามารถกระจายการคัดลอกและป้องกันไม่ให้เว็บไซต์ระบุเครื่องขูดเป็นแหล่งเดียว
- การจัดการกับ Captchas และเทคนิค Anti-Scraping: เมื่อต้องเผชิญกับ Captchas การใช้บริการแก้ไข Captcha หรือการนำการจำลองโดยมนุษย์สามารถช่วยหลีกเลี่ยงมาตรการเหล่านี้ได้ นอกจากนี้ โครงสร้าง HTML ที่สร้างความสับสนสามารถวิศวกรรมย้อนกลับได้โดยใช้เทคนิค เช่น การข้ามผ่าน DOM หรือการจดจำรูปแบบ
แนวทางปฏิบัติที่ดีที่สุดสำหรับการขูดเว็บแบบไดนามิก
ในขณะที่ทำการคัดลอกหน้าเว็บแบบไดนามิก สิ่งสำคัญคือต้องปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเพื่อให้แน่ใจว่ากระบวนการคัดลอกจะประสบความสำเร็จและมีจริยธรรม แนวทางปฏิบัติที่ดีที่สุดบางประการ ได้แก่:
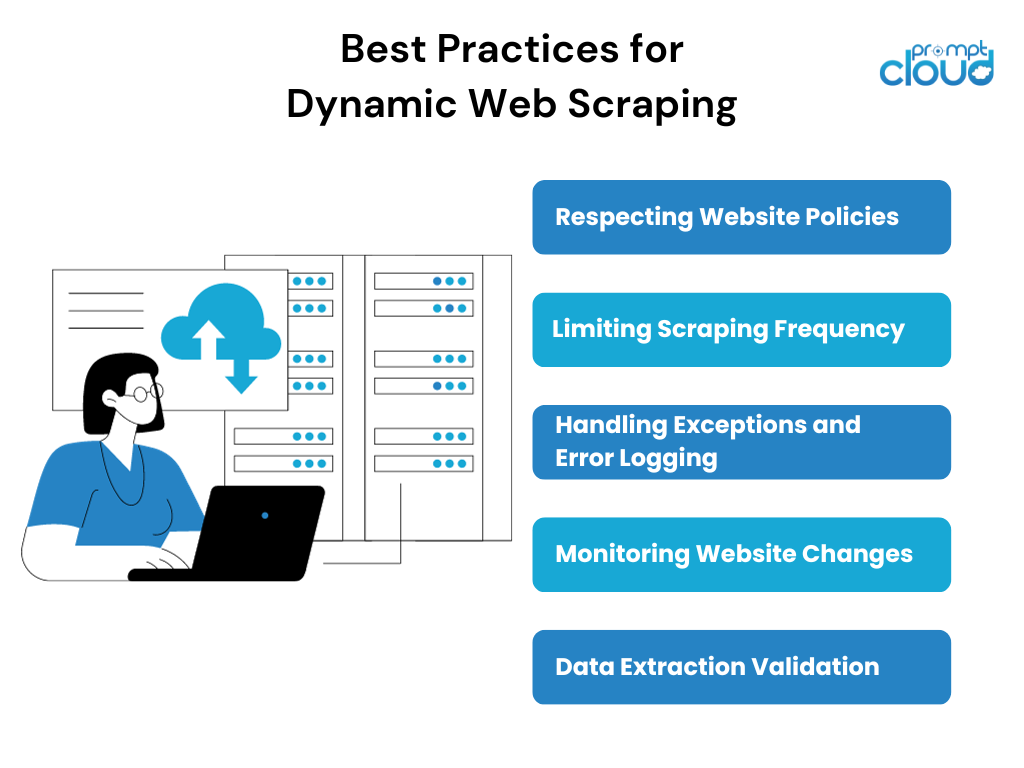
- การเคารพนโยบายเว็บไซต์: ก่อนที่จะทำการคัดลอกเว็บไซต์ใดๆ จำเป็นต้องตรวจสอบและเคารพข้อกำหนดในการให้บริการของเว็บไซต์ ไฟล์ robots.txt และหลักเกณฑ์การคัดลอกเฉพาะใดๆ ที่กล่าวถึง
- การจำกัดความถี่ในการคัดลอก: การคัดลอกมากเกินไปสามารถสร้างความตึงเครียดให้กับทั้งทรัพยากรของเครื่องขูดและเว็บไซต์ที่ถูกคัดลอก การใช้ขีดจำกัดความถี่ในการขูดที่สมเหตุสมผลและอัตราการเคารพขีดจำกัดที่กำหนดโดยเว็บไซต์สามารถช่วยรักษากระบวนการขูดที่กลมกลืนกัน
- การจัดการข้อยกเว้นและการบันทึกข้อผิดพลาด: การขูดเว็บแบบไดนามิกเกี่ยวข้องกับการจัดการกับสถานการณ์ที่คาดเดาไม่ได้ เช่น ข้อผิดพลาดของเครือข่าย คำขอ captcha หรือการเปลี่ยนแปลงโครงสร้างของเว็บไซต์ การใช้กลไกการจัดการข้อยกเว้นและการบันทึกข้อผิดพลาดที่เหมาะสมจะช่วยระบุและแก้ไขปัญหาเหล่านี้
- การตรวจสอบการเปลี่ยนแปลงเว็บไซต์: เว็บไซต์ไดนามิกมักได้รับการอัปเดตหรือการออกแบบใหม่ ซึ่งสามารถทำลายสคริปต์การคัดลอกที่มีอยู่ได้ การตรวจสอบเว็บไซต์เป้าหมายอย่างสม่ำเสมอสำหรับการเปลี่ยนแปลงใด ๆ และการปรับกลยุทธ์การขูดทันทีสามารถรับประกันการดึงข้อมูลได้อย่างต่อเนื่อง
- การตรวจสอบการแยกข้อมูล: การตรวจสอบและการอ้างอิงโยงข้อมูลที่แยกออกมาด้วยอินเทอร์เฟซผู้ใช้ของเว็บไซต์สามารถช่วยรับประกันความถูกต้องและครบถ้วนของข้อมูลที่คัดลอกมา ขั้นตอนการตรวจสอบนี้มีความสำคัญอย่างยิ่งเมื่อคัดลอกหน้าเว็บไดนามิกที่มีเนื้อหาที่กำลังพัฒนา
บทสรุป
พลังของการขูดหน้าเว็บแบบไดนามิกเปิดโลกแห่งโอกาสในการเข้าถึงข้อมูลอันมีค่าที่ซ่อนอยู่ภายในเว็บไซต์แบบไดนามิก การเอาชนะความท้าทายที่เกี่ยวข้องกับการคัดลอกเว็บไซต์แบบไดนามิกนั้นต้องอาศัยการผสมผสานระหว่างความเชี่ยวชาญด้านเทคนิคและการยึดมั่นในแนวทางปฏิบัติที่มีจริยธรรม
ด้วยการทำความเข้าใจความซับซ้อนของการคัดลอกหน้าเว็บแบบไดนามิกและการนำกลยุทธ์และแนวทางปฏิบัติที่ดีที่สุดที่ระบุไว้ในบทความนี้ไปใช้ ธุรกิจและบุคคลทั่วไปสามารถปลดล็อกศักยภาพของข้อมูลเว็บได้อย่างเต็มที่ และเพิ่มข้อได้เปรียบทางการแข่งขันในโดเมนต่างๆ
ความท้าทายอีกประการหนึ่งที่พบในการขูดหน้าเว็บแบบไดนามิกคือปริมาณข้อมูลที่ต้องแยกออกมา หน้าเว็บแบบไดนามิกมักจะมีข้อมูลจำนวนมาก ทำให้ยากต่อการดึงและแยกข้อมูลที่เกี่ยวข้องอย่างมีประสิทธิภาพ
เพื่อเอาชนะอุปสรรคนี้ ธุรกิจสามารถใช้ประโยชน์จากความเชี่ยวชาญของผู้ให้บริการขูดเว็บได้ โครงสร้างพื้นฐานการคัดลอกอันทรงพลังของ PromptCloud และเทคนิคการแยกข้อมูลขั้นสูงช่วยให้ธุรกิจสามารถจัดการโปรเจ็กต์การคัดลอกขนาดใหญ่ได้อย่างง่ายดาย
ด้วยความช่วยเหลือจาก PromptCloud องค์กรต่างๆ สามารถดึงข้อมูลเชิงลึกอันมีค่าจากหน้าเว็บไดนามิกและแปลงให้เป็นข้อมูลอัจฉริยะที่นำไปปฏิบัติได้ สัมผัสประสบการณ์พลังของการขูดหน้าเว็บแบบไดนามิกโดยร่วมมือกับ PromptCloud วันนี้ ติดต่อเราได้ที่ [email protected]