
การขูดหน้าเว็บแบบไดนามิกด้วย Python – วิธีการแนะนำ
เผยแพร่แล้ว: 2024-06-08การขูดเว็บแบบไดนามิกเกี่ยวข้องกับการดึงข้อมูลจากเว็บไซต์ที่สร้างเนื้อหาแบบเรียลไทม์ผ่าน JavaScript หรือ Python เนื้อหาแบบไดนามิกโหลดแบบอะซิงโครนัสต่างจากหน้าเว็บแบบคงที่ ทำให้เทคนิคการคัดลอกแบบเดิมไม่มีประสิทธิภาพ
การใช้การขูดเว็บแบบไดนามิก:
- เว็บไซต์ที่ใช้ AJAX
- แอปพลิเคชันหน้าเดียว (SPA)
- ไซต์ที่มีองค์ประกอบการโหลดล่าช้า
เครื่องมือและเทคโนโลยีที่สำคัญ:
- ซีลีเนียม – โต้ตอบเบราว์เซอร์โดยอัตโนมัติ
- BeautifulSoup – แยกวิเคราะห์เนื้อหา HTML
- คำขอ – ดึงเนื้อหาหน้าเว็บ
- lxml – แยกวิเคราะห์ XML และ HTML
Dynamic Web Scraping Python ต้องการความเข้าใจที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับเทคโนโลยีเว็บเพื่อรวบรวมข้อมูลแบบเรียลไทม์อย่างมีประสิทธิภาพ
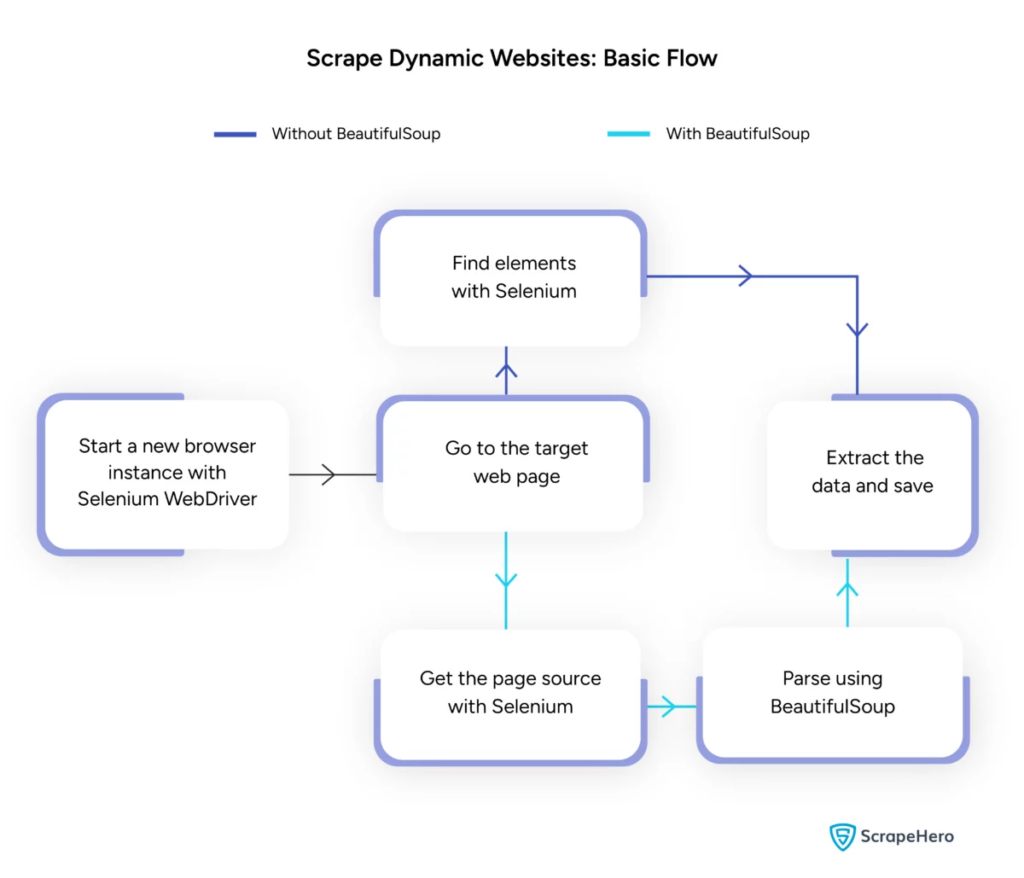
ที่มาของภาพ: https://www.scrapehero.com/scrape-a-dynamic-website/
การตั้งค่าสภาพแวดล้อม Python
ในการเริ่มต้น Python การขูดเว็บแบบไดนามิก จำเป็นต้องตั้งค่าสภาพแวดล้อมอย่างถูกต้อง ทำตามขั้นตอนเหล่านี้:
- ติดตั้ง Python : ตรวจสอบให้แน่ใจว่าติดตั้ง Python บนเครื่องแล้ว สามารถดาวน์โหลดเวอร์ชันล่าสุดได้จากเว็บไซต์ Python อย่างเป็นทางการ
- สร้างสภาพแวดล้อมเสมือนจริง :

เปิดใช้งานสภาพแวดล้อมเสมือน:

- ติดตั้งไลบรารีที่จำเป็น :

- ตั้งค่าตัวแก้ไขโค้ด : ใช้ IDE เช่น PyCharm, VSCode หรือ Jupyter Notebook สำหรับการเขียนและเรียกใช้สคริปต์
- ทำความคุ้นเคยกับ HTML/CSS : การทำความเข้าใจโครงสร้างหน้าเว็บช่วยในการนำทางและแยกข้อมูลได้อย่างมีประสิทธิภาพ
ขั้นตอนเหล่านี้สร้างรากฐานที่มั่นคงสำหรับโครงการหลามการขูดเว็บแบบไดนามิก
ทำความเข้าใจพื้นฐานของคำขอ HTTP
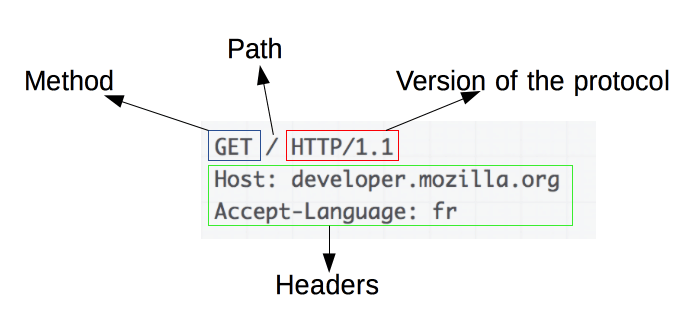
ที่มาของภาพ: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
คำขอ HTTP เป็นรากฐานของการขูดเว็บ เมื่อไคลเอนต์ เช่น เว็บเบราว์เซอร์หรือเครื่องขูดเว็บ ต้องการดึงข้อมูลจากเซิร์ฟเวอร์ ไคลเอนต์จะส่งคำขอ HTTP คำขอเหล่านี้เป็นไปตามโครงสร้างเฉพาะ:
- Method : การดำเนินการที่จะดำเนินการ เช่น GET หรือ POST
- URL : ที่อยู่ของทรัพยากรบนเซิร์ฟเวอร์
- ส่วนหัว : ข้อมูลเมตาเกี่ยวกับคำขอ เช่น ประเภทเนื้อหาและ user-agent
- เนื้อหา : ข้อมูลเสริมที่ส่งไปพร้อมกับคำขอ โดยทั่วไปจะใช้กับ POST
การทำความเข้าใจวิธีตีความและสร้างส่วนประกอบเหล่านี้ถือเป็นสิ่งสำคัญสำหรับการขูดเว็บอย่างมีประสิทธิภาพ ไลบรารี Python เช่น คำขอทำให้กระบวนการนี้ง่ายขึ้น ช่วยให้สามารถควบคุมคำขอได้อย่างแม่นยำ
การติดตั้งไลบรารี Python
ที่มาของภาพ: https://ajaytech.co/what-are-python-libraries/
สำหรับการขูดเว็บแบบไดนามิกด้วย Python ตรวจสอบให้แน่ใจว่าได้ติดตั้ง Python แล้ว เปิดเทอร์มินัลหรือพรอมต์คำสั่ง และติดตั้งไลบรารีที่จำเป็นโดยใช้ pip:
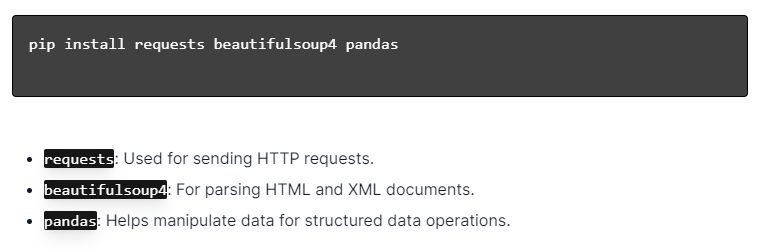
จากนั้น นำเข้าไลบรารีเหล่านี้ลงในสคริปต์ของคุณ:

การทำเช่นนี้ แต่ละไลบรารีจะพร้อมสำหรับงานขูดเว็บ เช่น การส่งคำขอ การแยกวิเคราะห์ HTML และการจัดการข้อมูลอย่างมีประสิทธิภาพ
การสร้างสคริปต์ขูดเว็บอย่างง่าย
หากต้องการสร้างสคริปต์การขูดเว็บแบบไดนามิกขั้นพื้นฐานใน Python จะต้องติดตั้งไลบรารีที่จำเป็นก่อน ไลบรารี “คำขอ” จัดการคำขอ HTTP ในขณะที่ “BeautifulSoup” แยกวิเคราะห์เนื้อหา HTML
ขั้นตอนในการติดตาม:
- ติดตั้งการพึ่งพา:

- นำเข้าไลบรารี:

- รับเนื้อหา HTML:
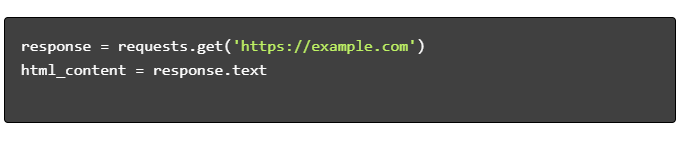
- แยก HTML:

- ดึงข้อมูล:

การจัดการการขูดเว็บแบบไดนามิกด้วย Python
เว็บไซต์ไดนามิกสร้างเนื้อหาได้ทันที ซึ่งมักต้องใช้เทคนิคที่ซับซ้อนมากขึ้น

พิจารณาขั้นตอนต่อไปนี้:
- ระบุองค์ประกอบเป้าหมาย : ตรวจสอบหน้าเว็บเพื่อค้นหาเนื้อหาแบบไดนามิก
- เลือก Python Framework : ใช้ไลบรารีเช่น Selenium หรือ Playwright
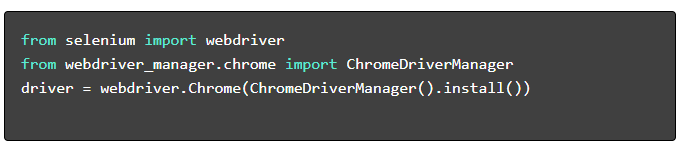
- ติดตั้งแพ็คเกจที่จำเป็น :
- ตั้งค่าเว็บไดร์เวอร์ :

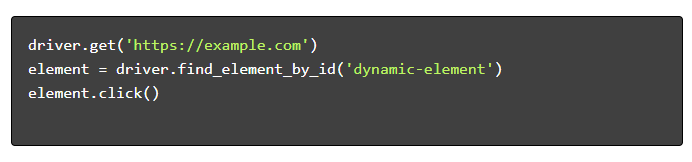
- นำทางและโต้ตอบ :
แนวทางปฏิบัติที่ดีที่สุดในการขูดเว็บ
แนะนำให้ปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดในการขูดเว็บเพื่อให้มั่นใจถึงประสิทธิภาพและความถูกต้องตามกฎหมาย ด้านล่างนี้เป็นแนวทางหลักและกลยุทธ์การจัดการข้อผิดพลาด:
- เคารพ Robots.txt : ตรวจสอบไฟล์ robots.txt ของไซต์เป้าหมายเสมอ
- การควบคุมปริมาณ : ใช้ความล่าช้าเพื่อป้องกันเซิร์ฟเวอร์โอเวอร์โหลด
- User-Agent : ใช้สตริง User-Agent ที่กำหนดเองเพื่อหลีกเลี่ยงการบล็อกที่อาจเกิดขึ้น
- ลองลอจิกใหม่ : ใช้บล็อกลองยกเว้นและตั้งค่าตรรกะลองใหม่เพื่อจัดการการหมดเวลาของเซิร์ฟเวอร์
- การบันทึก : รักษาบันทึกที่ครอบคลุมสำหรับการดีบัก
- การจัดการข้อยกเว้น : จับข้อผิดพลาดของเครือข่าย ข้อผิดพลาด HTTP และข้อผิดพลาดในการแยกวิเคราะห์โดยเฉพาะ
- การตรวจจับแคปต์ชา : รวมกลยุทธ์ในการตรวจจับและแก้ไขหรือเลี่ยงแคปต์ชา
ความท้าทายในการขูดเว็บแบบไดนามิกทั่วไป
แคปช่า
เว็บไซต์หลายแห่งใช้ CAPTCHA เพื่อป้องกันบอทอัตโนมัติ หากต้องการข้ามสิ่งนี้:
- ใช้บริการแก้ปัญหา CAPTCHA เช่น 2Captcha
- ใช้การแทรกแซงของมนุษย์เพื่อแก้ปัญหา CAPTCHA
- ใช้พรอกซีเพื่อจำกัดอัตราการร้องขอ
การบล็อกไอพี
ไซต์อาจบล็อก IP ที่ส่งคำขอมากเกินไป ตอบโต้โดย:
- การใช้พรอกซีแบบหมุน
- การดำเนินการควบคุมปริมาณคำขอ
- การใช้กลยุทธ์การหมุนเวียนตัวแทนผู้ใช้
การแสดงผลจาวาสคริปต์
บางไซต์โหลดเนื้อหาผ่าน JavaScript จัดการกับความท้าทายนี้โดย:
- การใช้ Selenium หรือ Puppeteer สำหรับเบราว์เซอร์อัตโนมัติ
- การใช้ Scrapy-splash เพื่อเรนเดอร์เนื้อหาแบบไดนามิก
- สำรวจเบราว์เซอร์ที่ไม่มีหัวเพื่อโต้ตอบกับ JavaScript
ประเด็นทางกฎหมาย
การขูดเว็บบางครั้งอาจละเมิดข้อกำหนดในการให้บริการ ตรวจสอบการปฏิบัติตามโดย:
- ให้คำปรึกษาแนะนำด้านกฎหมาย
- การขูดข้อมูลที่เข้าถึงได้แบบสาธารณะ
- การปฏิบัติตามคำสั่งของ robots.txt
การแยกวิเคราะห์ข้อมูล
การจัดการโครงสร้างข้อมูลที่ไม่สอดคล้องกันอาจเป็นเรื่องท้าทาย โซลูชั่นประกอบด้วย:
- การใช้ไลบรารีเช่น BeautifulSoup สำหรับการแยกวิเคราะห์ HTML
- การใช้นิพจน์ทั่วไปในการแยกข้อความ
- การใช้ตัวแยกวิเคราะห์ JSON และ XML สำหรับข้อมูลที่มีโครงสร้าง
การจัดเก็บและวิเคราะห์ข้อมูลที่คัดลอกมา
การจัดเก็บและวิเคราะห์ข้อมูลที่คัดลอกมาเป็นขั้นตอนสำคัญในการคัดลอกเว็บ การตัดสินใจว่าจะจัดเก็บข้อมูลไว้ที่ใดขึ้นอยู่กับปริมาณและรูปแบบ ตัวเลือกการจัดเก็บข้อมูลทั่วไป ได้แก่:
- ไฟล์ CSV : ง่ายสำหรับชุดข้อมูลขนาดเล็กและการวิเคราะห์ง่ายๆ
- ฐานข้อมูล : ฐานข้อมูล SQL สำหรับข้อมูลที่มีโครงสร้าง NoSQL สำหรับไม่มีโครงสร้าง
เมื่อจัดเก็บแล้ว การวิเคราะห์ข้อมูลสามารถทำได้โดยใช้ไลบรารี Python:
- Pandas : เหมาะสำหรับการจัดการและทำความสะอาดข้อมูล
- NumPy : มีประสิทธิภาพสำหรับการดำเนินการเชิงตัวเลข
- Matplotlib และ Seaborn : เหมาะสำหรับการแสดงข้อมูลเป็นภาพ
- Scikit-learn : จัดเตรียมเครื่องมือสำหรับการเรียนรู้ของเครื่อง
การจัดเก็บและการวิเคราะห์ข้อมูลที่เหมาะสมช่วยปรับปรุงการเข้าถึงข้อมูลและข้อมูลเชิงลึก
บทสรุปและขั้นตอนต่อไป
เมื่อเดินผ่าน Python ที่ขูดเว็บแบบไดนามิกแล้ว จำเป็นต้องปรับแต่งความเข้าใจเกี่ยวกับเครื่องมือและไลบรารีที่ไฮไลต์อย่างละเอียด
- ทบทวนโค้ด : ศึกษาสคริปต์ขั้นสุดท้ายและปรับให้เป็นโมดูลเมื่อเป็นไปได้เพื่อปรับปรุงการนำกลับมาใช้ใหม่ได้
- ไลบรารีเพิ่มเติม : สำรวจไลบรารีขั้นสูง เช่น Scrapy หรือ Splash สำหรับความต้องการที่ซับซ้อนยิ่งขึ้น
- การจัดเก็บข้อมูล : พิจารณาตัวเลือกการจัดเก็บข้อมูลที่มีประสิทธิภาพ—ฐานข้อมูล SQL หรือที่เก็บข้อมูลบนคลาวด์สำหรับการจัดการชุดข้อมูลขนาดใหญ่
- ข้อพิจารณาทางกฎหมายและจริยธรรม : ติดตามแนวทางทางกฎหมายเกี่ยวกับการขูดเว็บเพื่อหลีกเลี่ยงการละเมิดที่อาจเกิดขึ้น
- โปรเจ็กต์ถัดไป : การแก้ปัญหาโปรเจ็กต์การขูดเว็บใหม่ที่มีความซับซ้อนต่างกันจะช่วยเสริมทักษะเหล่านี้ให้แข็งแกร่งยิ่งขึ้น
กำลังมองหาวิธีรวมการขูดเว็บแบบไดนามิกระดับมืออาชีพเข้ากับ Python เข้ากับโปรเจ็กต์ของคุณหรือไม่? สำหรับทีมที่ต้องการการแยกข้อมูลในระดับสูงโดยไม่มีความซับซ้อนในการจัดการภายใน PromptCloud นำเสนอโซลูชันที่ปรับให้เหมาะสม สำรวจบริการของ PromptCloud เพื่อหาโซลูชันที่แข็งแกร่งและเชื่อถือได้ ติดต่อเราวันนี้!