
การวิเคราะห์ปัจจัยเชิงสำรวจใน R
เผยแพร่แล้ว: 2017-02-16การวิเคราะห์ปัจจัยสำรวจใน R คืออะไร?
การวิเคราะห์ปัจจัยเชิงสำรวจ (EFA) หรือที่รู้จักกันในชื่อการวิเคราะห์ปัจจัยใน R เป็นเทคนิคทางสถิติที่ใช้ในการระบุโครงสร้างเชิงสัมพันธ์ที่แฝงอยู่ในชุดของตัวแปรและจำกัดให้เหลือตัวแปรจำนวนน้อย โดยพื้นฐานแล้วหมายความว่าความแปรปรวนของตัวแปรจำนวนมากสามารถอธิบายได้ด้วยตัวแปรสรุปสองสามตัว กล่าวคือ ปัจจัย นี่คือภาพรวมของการวิเคราะห์ปัจจัยเชิงสำรวจใน R
ตามชื่อที่แนะนำ EFA เป็นแบบสำรวจโดยธรรมชาติ เราไม่รู้ตัวแปรแฝงจริงๆ และจะมีขั้นตอนซ้ำๆ จนกว่าเราจะไปถึงปัจจัยจำนวนน้อยลง ในบทช่วยสอนนี้ เราจะดู EFA โดยใช้ R ตอนนี้ มาทำความเข้าใจแนวคิดพื้นฐานของชุดข้อมูลกันก่อน
1. ข้อมูล
ชุดข้อมูลนี้มีคำตอบ 90 แบบสำหรับตัวแปร 14 แบบที่ลูกค้าพิจารณาขณะซื้อรถยนต์ คำถามแบบสำรวจกำหนดกรอบโดยใช้มาตราส่วน Likert 5 จุด โดย 1 ต่ำมาก และ 5 สูงมาก ตัวแปรมีดังต่อไปนี้:
- ราคา
- ความปลอดภัย
- รูปลักษณ์ภายนอก
- พื้นที่และความสะดวกสบาย
- เทคโนโลยี
- บริการหลังการขาย
- มูลค่าการขายต่อ
- ประเภทเชื้อเพลิง
- ประสิทธิภาพการใช้เชื้อเพลิง
- สี
- การซ่อมบำรุง
- ทดลองขับ
- รีวิวสินค้า
- ข้อความรับรอง
คลิกที่นี่เพื่อดาวน์โหลดชุดข้อมูลที่เข้ารหัส
2. การนำเข้าข้อมูลเว็บ
ตอนนี้เราจะอ่านชุดข้อมูลที่อยู่ในรูปแบบ CSV ลงใน R และเก็บเป็นตัวแปร
[รหัสภาษา=”r”] data <- read.csv(file.choose( ),header=TRUE) [/code]
จะเปิดหน้าต่างให้เลือกไฟล์ CSV และตัวเลือก "ส่วนหัว" จะทำให้แน่ใจว่าแถวแรกของไฟล์ถือเป็นส่วนหัว ป้อนข้อมูลต่อไปนี้เพื่อดูหลายแถวแรกของ data frame และยืนยันว่าข้อมูลถูกจัดเก็บอย่างถูกต้อง
[รหัสภาษา =”r”] หัว (ข้อมูล) [/รหัส]
3. การติดตั้งแพ็คเกจ
ตอนนี้เราจะติดตั้งแพ็คเกจที่จำเป็นเพื่อทำการวิเคราะห์เพิ่มเติม แพ็คเกจเหล่านี้คือ 'psych' และ 'GPArotation' ในโค้ดด้านล่าง เรากำลังเรียก `install.packages()` สำหรับการติดตั้ง
[รหัสภาษา=”r”] install.packages('psych') install.packages('GPArotation') [/code]
4. จำนวนปัจจัย
ต่อไป เราจะหาจำนวนปัจจัยที่เราจะเลือกสำหรับการวิเคราะห์ปัจจัย สิ่งนี้ได้รับการประเมินผ่านวิธีการต่างๆ เช่น "การวิเคราะห์คู่ขนาน" และ "ค่าลักษณะเฉพาะ" เป็นต้น
การวิเคราะห์แบบคู่ขนาน
เราจะใช้ฟังก์ชัน 'fa.parallel' ของแพ็คเกจ 'Psych' เพื่อดำเนินการวิเคราะห์แบบขนาน ที่นี่เราระบุ data frame และ factor method (`minres` ในกรณีของเรา) เรียกใช้สิ่งต่อไปนี้เพื่อค้นหาปัจจัยจำนวนที่ยอมรับได้และสร้าง `scree plot`:
[รหัสภาษา=”r”] Parallel <- fa.parallel(data, fm = 'minres', fa = 'fa') [/code]
คอนโซลจะแสดงจำนวนปัจจัยสูงสุดที่เราสามารถพิจารณาได้ นี่คือลักษณะที่ปรากฏ
“การวิเคราะห์แบบคู่ขนานแสดงให้เห็นว่าจำนวนปัจจัย = 5 และจำนวนองค์ประกอบ = NA”
รับด้านล่างใน `scree plot' ที่สร้างจากโค้ดด้านบน:
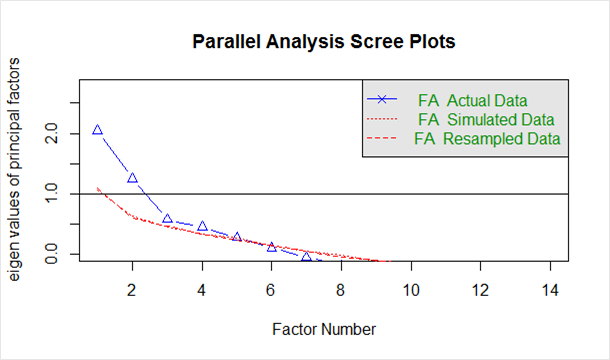
เส้นสีน้ำเงินแสดงค่าลักษณะเฉพาะของข้อมูลจริง และเส้นสีแดงสองเส้น (วางทับกัน) แสดงข้อมูลที่จำลองและสุ่มตัวอย่าง ในที่นี้เราจะดูการลดลงจำนวนมากในข้อมูลจริงและระบุจุดที่ข้อมูลนั้นเลื่อนระดับไปทางขวา นอกจากนี้เรายังระบุตำแหน่งจุดเปลี่ยน – จุดที่ช่องว่างระหว่างข้อมูลจำลองและข้อมูลจริงมีแนวโน้มน้อยที่สุด

เมื่อพิจารณาจากพล็อตนี้และการวิเคราะห์แบบคู่ขนาน ที่ใดก็ได้ระหว่าง 2 ถึง 5 ปัจจัยจะเป็นตัวเลือกที่ดี
การวิเคราะห์ปัจจัย
ตอนนี้เรามาถึงตัวประกอบที่น่าจะเป็นไปได้แล้ว เรามาเริ่มด้วย 3 เป็นจำนวนตัวประกอบกัน เพื่อทำการวิเคราะห์ปัจจัย เราจะใช้ฟังก์ชัน `psych` packages`fa() รับด้านล่างเป็นอาร์กิวเมนต์ที่เราจะจัดหา:
- r – ข้อมูลดิบหรือความสัมพันธ์หรือเมทริกซ์ความแปรปรวนร่วม
- nfactors – จำนวนของปัจจัยที่จะแยก
- หมุน – แม้ว่าจะมีการหมุนหลายประเภท แต่ 'Varimax' และ 'Oblimin' เป็นที่นิยมมากที่สุด
- fm – หนึ่งในเทคนิคการสกัดปัจจัย เช่น `Minimum Residual (OLS)`, `Maximum Liklihood`, `Principal Axis` เป็นต้น
ในกรณีนี้ เราจะเลือกการหมุนเฉียง (rotate = “oblimin”) เนื่องจากเราเชื่อว่าปัจจัยมีความสัมพันธ์กัน โปรดทราบว่าการหมุน Varimax ถูกใช้ภายใต้สมมติฐานที่ว่าปัจจัยต่างๆ ไม่มีความสัมพันธ์กันโดยสมบูรณ์ เราจะใช้แฟคตอริ่ง `Ordinary Least Squared/Minres` (fm = "minres") เนื่องจากเป็นที่ทราบกันดีอยู่แล้วว่าให้ผลลัพธ์ที่คล้ายกับ "ความเป็นไปได้สูงสุด" โดยไม่ต้องสันนิษฐานว่ามีการแจกแจงแบบปกติหลายตัวแปรและได้คำตอบมาจากการสลายตัวของลักษณะเฉพาะแบบวนซ้ำ เช่น แกนหลัก
เรียกใช้สิ่งต่อไปนี้เพื่อเริ่มการวิเคราะห์
[รหัสภาษา=”r”] threefactor <- fa(data,nfactors = 3, หมุน = “oblimin”,fm=”minres”) พิมพ์ (สามปัจจัย) [/ รหัส]
นี่คือผลลัพธ์ที่แสดงปัจจัยและการโหลด:
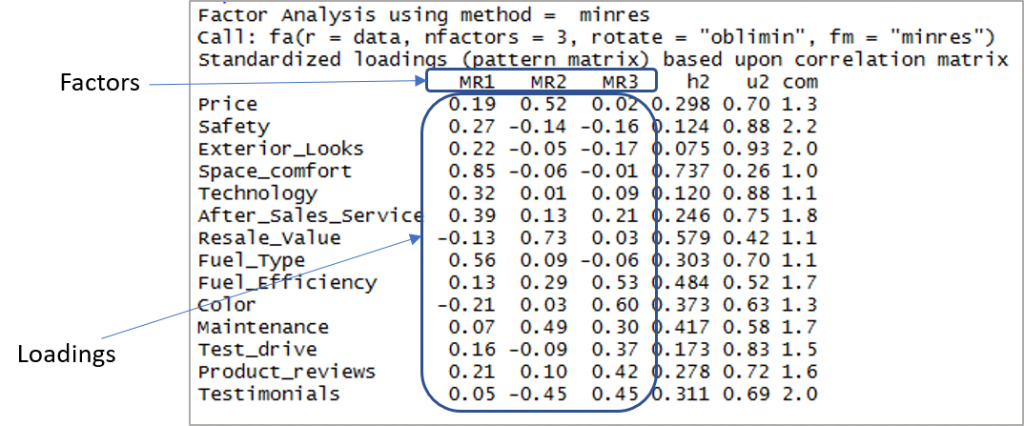
ตอนนี้เราต้องพิจารณาการโหลดที่มากกว่า 0.3 และไม่โหลดมากกว่าหนึ่งปัจจัย โปรดทราบว่าค่าลบเป็นที่ยอมรับได้ที่นี่ ขั้นแรก เรามาสร้างจุดตัดเพื่อปรับปรุงการมองเห็นกันก่อน
[รหัสภาษา =”r”] พิมพ์ (threefactor$loadings,cutoff = 0.3) [/code]
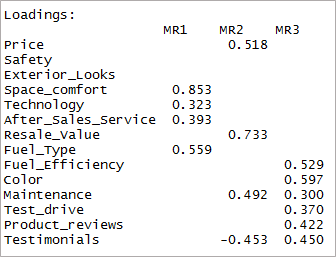
อย่างที่คุณเห็นตัวแปรสองตัวนั้นไม่มีนัยสำคัญและอีกสองตัวมีการโหลดซ้ำ ต่อไป เราจะพิจารณาปัจจัย '4'
[รหัสภาษา=”r”] fourfactor <- fa(data,nfactors = 4, หมุน = “oblimin”,fm=”minres”) พิมพ์ (fourfactor$loadings,cutoff = 0.3) [/code]
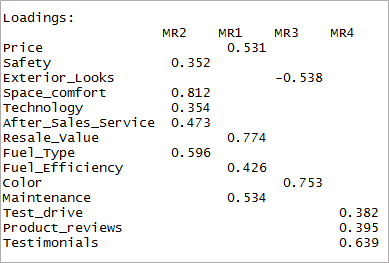
เราจะเห็นว่ามันส่งผลให้โหลดเพียงครั้งเดียว นี้เรียกว่าโครงสร้างที่เรียบง่าย
กดปุ่มต่อไปนี้เพื่อดูการแมปแฟคเตอร์
[code language=”r”] fa.diagram(fourfactor) [/code]
การทดสอบความเพียงพอ
เมื่อเราได้โครงสร้างที่เรียบง่ายแล้ว ก็ถึงเวลาตรวจสอบแบบจำลองของเรา ลองดูผลลัพธ์การวิเคราะห์ปัจจัยเพื่อดำเนินการต่อ

รากหมายถึงกำลังสองของเศษเหลือ (RMSR) คือ 0.05 ซึ่งเป็นที่ยอมรับได้เนื่องจากค่านี้ควรใกล้กับ 0 มากขึ้น ต่อไป เราควรตรวจสอบดัชนี RMSEA (ค่าคลาดเคลื่อนกำลังสองเฉลี่ยของการประมาณค่าราก) ค่าของมัน 0.001 แสดงให้เห็นถึงรูปแบบที่ดีที่มันอยู่ต่ำกว่า 0.05 สุดท้าย ดัชนีทักเกอร์-ลูอิส (TLI) คือ 0.93 ซึ่งเป็นค่าที่ยอมรับได้เมื่อพิจารณาว่ามากกว่า 0.9
การตั้งชื่อปัจจัย

หลังจากกำหนดความเพียงพอของปัจจัยแล้ว ก็ถึงเวลาที่เราจะตั้งชื่อปัจจัย นี่คือด้านทฤษฎีของการวิเคราะห์ที่เราสร้างปัจจัยขึ้นอยู่กับการโหลดตัวแปร ในกรณีนี้ นี่คือวิธีการสร้างปัจจัยต่างๆ
บทสรุป
ในบทช่วยสอนสำหรับการวิเคราะห์ใน r นี้ เราได้พูดถึงแนวคิดพื้นฐานของ EFA (การวิเคราะห์ปัจจัยเชิงสำรวจใน R) ครอบคลุมการวิเคราะห์แบบคู่ขนาน และการตีความพล็อตหินกรวด จากนั้นเราย้ายไปที่การวิเคราะห์ปัจจัยใน R เพื่อให้ได้โครงสร้างที่เรียบง่ายและตรวจสอบความถูกต้องเพื่อให้แน่ใจว่าแบบจำลองมีความเพียงพอ ในที่สุดก็มาถึงชื่อของปัจจัยจากตัวแปร ไปข้างหน้า ลองใช้ และโพสต์สิ่งที่คุณค้นพบในส่วนความคิดเห็น