
เสียงของบาซาร์
เผยแพร่แล้ว: 2024-04-24บทความเกี่ยวกับการปรับปรุงระบบเดิมให้ทันสมัยนี้เป็นส่วนหนึ่งของการเสวนาที่ฉันนำเสนอเมื่อเร็ว ๆ นี้ที่ AWS Data Summit สำหรับบริษัทซอฟต์แวร์เกี่ยวกับการสร้างมูลค่าจากข้อมูลโดยใช้ประโยชน์จากแนวทางปฏิบัติที่ดีที่สุดของเราเพื่อรับประกันความสำเร็จในโครงการ Machine Learning คุณสามารถกระโดดลงไปด้านล่างเพื่อดูได้หากต้องการ
ยอมรับเถอะว่าซอฟต์แวร์เขียนได้ง่ายกว่าการบำรุงรักษา นี่คือเหตุผลว่าทำไมเราในฐานะวิศวกรซอฟต์แวร์ถึงชอบที่จะ "ฉีกมันออกแล้วเริ่มต้นใหม่" แทนที่จะพยายามทำความเข้าใจว่านักพัฒนาคนอื่น (หรือตัวเราในอดีต) กำลังคิดอะไรอยู่ ดูเหมือนว่าเราจะลืมไปแล้วว่า “ต้องเขียนโปรแกรมเพื่อให้คนอ่าน และบังเอิญเท่านั้นที่เครื่องจะทำงาน”
คุณรู้ว่ามันเป็นความจริง เราทุกคนต่างต้องพยายามติดตามหม้อปรุงอาหารที่มีรหัสสปาเก็ตตี้และภาพนามธรรมสไตล์โลกเก่าบางๆ ที่ขุดหาเนื้อของโปรแกรมเพียงเพื่อจะไม่พบอะไรเลยนอกจากความยุ่งเหยิงที่ด้านล่างของจานของเรา
มันง่ายที่จะตะโกนว่า “WTF” และตำหนิผู้พัฒนาคนก่อนๆ แต่ความจริงมักจะซับซ้อนกว่า เราไม่สามารถมองเห็นอนาคตได้ ดังนั้นจึงเป็นไปไม่ได้ที่จะเข้าใจว่าความต้องการ เทคโนโลยี หรือเป้าหมายทางธุรกิจจะเติบโตอย่างไรเมื่อเราออกแบบระบบใหม่ เป็นผลให้ระบบไม่สามารถอ่านได้เนื่องจากขอบเขตเพิ่มขึ้นพร้อมกับการพึ่งพาของธุรกิจ นี่เป็นความขัดแย้งเล็กน้อย: ระบบที่เก่ากว่าและบำรุงรักษายากมักจะให้คุณค่าสูงสุด พวกเขาทำงานหนักเพราะพวกเขาเติบโตไปพร้อมกับบริษัท และน่ากลัวที่จะทำงานต่อไปเพราะการทำลายมันอาจเป็นหายนะ
ฉันจะโทรหาคุณที่นี่: หากคุณชอบปัญหาที่ยากและคุ้มค่า… ลองดูสิ ใช้ระบบที่เก่าแก่ที่สุดที่คุณมีและทำให้สามารถบำรุงรักษาได้ คุณรู้จักคนที่ฉันกำลังพูดถึง — คนที่ไม่มีใคร "เป็นเจ้าของ" ได้ สิ่งหนึ่งที่แผนกอื่นๆ พึ่งพาแต่วิศวกรเกลียด อันที่คุณต้องแก้ไข Log4Shell ก่อน ทำมัน. ฉันท้าคุณ.
เมื่อเร็วๆ นี้ ฉันมีโอกาสอัปเดตระบบการเรียนรู้ของเครื่องที่มีอายุร่วมทศวรรษที่ Bazaarvoice ดูเผินๆ ฟังดูไม่ น่าตื่นเต้นเลย เพราะสิ่งนี้ไม่มีโครงข่ายประสาทด้วยซ้ำ! ใครสน! ก็…มันสำคัญ ระบบนี้ประมวลผลเกือบทุกรีวิวผลิตภัณฑ์ที่ผู้ใช้สร้างขึ้นซึ่ง Bazaarvoice ได้รับ — เกือบ 9 ล้านรายการต่อเดือน — และดำเนินการดังกล่าวด้วยการเรียกโมเดลการเรียนรู้ของเครื่องจักรถึง 90 ล้านครั้ง ใช่แล้ว — 90 ล้านการอนุมาน! มันมีขนาดใหญ่มาก และฉันแทบรอไม่ไหวที่จะเข้าไปดำดิ่งลงไป
ในโพสต์นี้ ผมจะแชร์ว่าการปรับปรุงระบบเดิมให้ทันสมัยด้วยสถาปัตยกรรมใหม่ แทนที่จะเขียนใหม่ ช่วยให้เราสามารถปรับขนาดได้และคุ้มต้นทุนโดยไม่ต้องฉีกโค้ดทั้งหมดแล้วเริ่มต้นใหม่ ผลลัพธ์ที่ได้คือระบบไร้เซิร์ฟเวอร์ มีคอนเทนเนอร์ และสามารถบำรุงรักษาได้ พร้อมทั้งลดต้นทุนการโฮสต์ของเราลงเกือบ 80%
ระบบเดิมคืออะไร?
ระบบเดิมหมายถึงซอฟต์แวร์คอมพิวเตอร์และ/หรือฮาร์ดแวร์ที่ล้าสมัยซึ่งยังคงใช้งานอยู่ แม้ว่าจะยังคงบรรลุวัตถุประสงค์เดิม แต่ก็ยังขาดความสามารถในการขยายขนาดสำหรับการเติบโตในอนาคต
ระบบมรดกเก่า
ก่อนอื่น เรามาดูกันว่าเรากำลังเผชิญกับอะไรที่นี่ ระบบเดิมที่ทีมของฉันกำลังอัปเดตจะกลั่นกรองเนื้อหาที่ผู้ใช้สร้างขึ้นสำหรับ Bazaarvoice ทั้งหมด โดยเฉพาะอย่างยิ่งจะกำหนดว่าเนื้อหาแต่ละชิ้นเหมาะสมกับเว็บไซต์ของลูกค้าของเราหรือไม่

ฟังดูตรงไปตรงมา — กำจัดการละเมิดที่ชัดเจน เช่น คำพูดแสดงความเกลียดชัง ภาษาหยาบคาย หรือการชักชวน — แต่ในทางปฏิบัติ มีความเหมาะสมยิ่งขึ้นมาก ลูกค้าแต่ละรายมีข้อกำหนดเฉพาะสำหรับสิ่งที่พวกเขาเห็นว่าเหมาะสม ตัวอย่างเช่น แบรนด์เบียร์คาดว่าจะมีการพูดคุยเรื่องเครื่องดื่มแอลกอฮอล์ แต่แบรนด์สำหรับเด็กอาจไม่คาดหวัง เรารวบรวมตัวเลือกเฉพาะไคลเอนต์เหล่านี้เมื่อเราเริ่มต้นใช้งานลูกค้าใหม่ และทีมบริการลูกค้าของเราจะเข้ารหัสตัวเลือกเหล่านั้นลงในฐานข้อมูลการจัดการ
เพื่อความซับซ้อนที่เพิ่มเข้ามา เรายังสุ่มตัวอย่างเนื้อหาบางส่วนของเราเพื่อให้ผู้ดูแลที่เป็นมนุษย์เป็นผู้ตรวจสอบ สิ่งนี้ช่วยให้เราสามารถวัดประสิทธิภาพของโมเดลของเราได้อย่างต่อเนื่องและค้นพบโอกาสในการสร้างโมเดลเพิ่มเติม
สถาปัตยกรรมทั้งหมดของระบบเดิมของเราแสดงไว้ด้านล่าง:
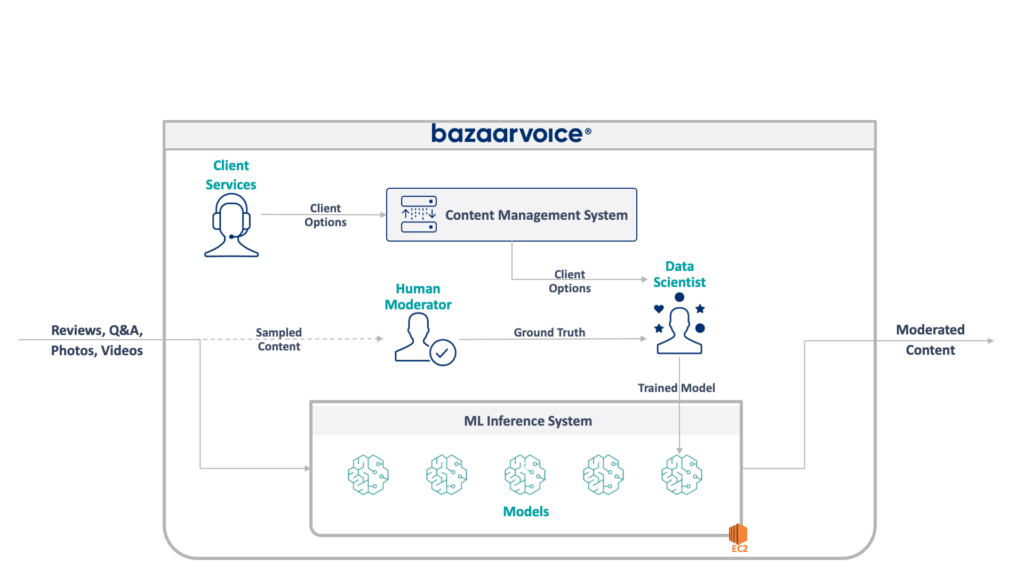
ระบบนี้มีข้อบกพร่องร้ายแรงบางประการ โดยเฉพาะอย่างยิ่ง — โมเดลทั้งหมดโฮสต์อยู่บน EC2 instance เดียว นี่ไม่ได้เกิดจากวิศวกรรมที่ไม่ดี — เพียงแต่โปรแกรมเมอร์ดั้งเดิมไม่สามารถคาดการณ์ขนาดที่บริษัทต้องการได้ ไม่มีใครคิดว่ามันจะเติบโตได้มากเท่านี้
นอกจากนี้ ระบบยังได้รับผลกระทบจากการปฏิเสธของนักพัฒนา: มันถูกเขียนด้วย Scala ซึ่งมีวิศวกรเพียงไม่กี่คนที่เข้าใจ ดังนั้นจึงมักถูกมองข้ามการปรับปรุงเนื่องจากไม่มีใครอยากแตะต้องมัน
เป็นผลให้ระบบยังคงเติบโตอย่างต่อเนื่องในลักษณะเปิดไฟ เมื่อเราปรับสถาปัตยกรรมมันใหม่แล้ว มันก็ทำงานบนอินสแตนซ์ x1e.8xlarge เดียว สิ่งนี้มี RAM เกือบเทราไบต์และมีค่าใช้จ่ายประมาณ 5,000 เหรียญสหรัฐต่อเดือน (ไม่สงวนไว้) ในการดำเนินการ ไม่ต้องกังวล เราเพิ่งเปิดตัวส่วนที่สองสำหรับการสำรองและส่วนที่สามสำหรับ QA
ระบบนี้มีค่าใช้จ่ายสูงในการทำงานและมีความเสี่ยงสูงที่จะเกิดความล้มเหลว (โมเดลที่ไม่ดีเพียงตัวเดียวอาจทำให้บริการทั้งหมดล่มได้) นอกจากนี้ ฐานโค้ดยังไม่ได้รับการพัฒนาอย่างจริงจัง และล้าสมัยอย่างมากด้วยแพ็คเกจวิทยาศาสตร์ข้อมูลสมัยใหม่ และไม่ปฏิบัติตามหลักปฏิบัติมาตรฐานของเราสำหรับบริการที่เขียนด้วย Scala
ระบบใหม่
เมื่อออกแบบระบบนี้ใหม่ เรามีเป้าหมายที่ชัดเจน: ทำให้สามารถปรับขนาดได้ การลดต้นทุนการดำเนินงานเป็นเป้าหมายรอง เช่นเดียวกับการปรับโมเดลและการจัดการโค้ดให้ง่ายขึ้น
การออกแบบใหม่ที่เราสร้างขึ้นมีดังต่อไปนี้:

แนวทางของเราในการแก้ปัญหาทั้งหมดนี้คือการวางโมเดล Machine Learning แต่ละโมเดลไว้บนจุดสิ้นสุด SageMaker Serverless ที่แยกออกมา เช่นเดียวกับฟังก์ชัน AWS Lambda ตำแหน่งข้อมูลแบบไร้เซิร์ฟเวอร์จะปิดเมื่อไม่ได้ใช้งาน ซึ่งช่วยเราประหยัดค่าใช้จ่ายรันไทม์สำหรับรุ่นที่ไม่ค่อยได้ใช้ นอกจากนี้ยังสามารถขยายขนาดได้อย่างรวดเร็วเพื่อตอบสนองต่อปริมาณการเข้าชมที่เพิ่มขึ้น

นอกจากนี้ เรายังเปิดเผยตัวเลือกไคลเอ็นต์กับไมโครเซอร์วิสเดียวที่กำหนดเส้นทางเนื้อหาไปยังโมเดลที่เหมาะสม นี่เป็นโค้ดใหม่ส่วนใหญ่ที่เราต้องเขียน: API ขนาดเล็กที่ง่ายต่อการบำรุงรักษาและให้นักวิทยาศาสตร์ข้อมูลของเราอัปเดตและปรับใช้โมเดลใหม่ได้ง่ายขึ้น
วิธีนี้มีประโยชน์ดังต่อไปนี้:
- ลดเวลาในการสร้างมูลค่าลงมากกว่า 6 เท่า โดยเฉพาะอย่างยิ่ง การกำหนดเส้นทางการรับส่งข้อมูลไปยังโมเดลที่มีอยู่นั้นสามารถทำได้ทันที และการปรับใช้โมเดลใหม่สามารถทำได้ภายในเวลาไม่ถึง 5 นาที แทนที่จะเป็น 30 นาที
- ปรับขนาดได้ไม่จำกัด – ขณะนี้เรามีโมเดล 400 โมเดล แต่วางแผนที่จะขยายเป็นหลายพันโมเดลเพื่อเพิ่มปริมาณเนื้อหาที่เรากลั่นกรองได้โดยอัตโนมัติ
- เห็นการลดต้นทุนถึง 82% โดยย้ายออกจาก EC2 เนื่องจากฟังก์ชันปิดเมื่อไม่ได้ใช้งาน และเราไม่ได้จ่ายเงินสำหรับเครื่องจักรระดับสูงที่มีการใช้งานน้อยเกินไป
อย่างไรก็ตาม การออกแบบสถาปัตยกรรมในอุดมคติเพียงอย่างเดียวไม่ใช่ส่วนที่ยาก ที่น่าสนใจ จริงๆ ในการสร้างระบบเดิมขึ้นมาใหม่ — คุณต้อง ย้าย ไปยังระบบนั้น
ความท้าทายแรกของเราในการย้ายข้อมูลคือการหาวิธีย้ายโมเดล Java WEKA เพื่อทำงานบน SageMaker ไม่ต้องพูดถึง SageMaker Serverless
โชคดีที่ SageMaker ปรับใช้โมเดลในคอนเทนเนอร์ Docker ดังนั้นอย่างน้อยเราก็สามารถหยุดเวอร์ชัน Java และการอ้างอิงเพื่อให้ตรงกับโค้ดเก่าของเราได้ สิ่งนี้จะช่วยให้แน่ใจว่าโมเดลที่โฮสต์อยู่ในระบบใหม่จะให้ผลลัพธ์เหมือนกับโมเดลเดิม

หากต้องการทำให้คอนเทนเนอร์เข้ากันได้กับ SageMaker สิ่งที่คุณต้องทำคือติดตั้งตำแหน่งข้อมูล HTTP เฉพาะบางอย่าง:
-
POST /invocation— ยอมรับอินพุต อนุมาน และส่งคืนผลลัพธ์ -
GET /ping— คืนค่า 200 หากเซิร์ฟเวอร์ JVM มีประสิทธิภาพดี
(เราเลือกที่จะเพิกเฉยต่อข้อขัดแย้งทั้งหมดเกี่ยวกับคอนเทนเนอร์หลายแบบจำลอง BYO และชุดเครื่องมืออนุมานของ SageMaker)
สรุปสั้นๆ สั้นๆ เกี่ยวกับ com.sun.net.httpserver.HttpServer และเราพร้อมแล้ว
และคุณรู้อะไรไหม? นี่มันสนุกจริงๆ การใช้คอนเทนเนอร์ Docker และบังคับให้บางสิ่งบางอย่างอายุ 10 ปีเข้าสู่ SageMaker Serverless ให้ความรู้สึกที่ยุ่งยากเล็กน้อย มันค่อนข้างน่าตื่นเต้นเมื่อเราทำให้มันใช้งานได้ โดยเฉพาะอย่างยิ่งเมื่อเราได้รับโค้ดระบบเดิมเพื่อสร้างมันใน sbt stack ใหม่ของเราแทนที่จะเป็น maven
สแต็ก sbt ใหม่ทำให้ทำงานได้ง่าย และการวางคอนเทนเนอร์ทำให้เรามั่นใจได้ว่าเราจะมีพฤติกรรมที่เหมาะสมขณะทำงานในสภาพแวดล้อม SageMaker
การย้ายไปยังระบบใหม่
เรามีโมเดลในคอนเทนเนอร์และสามารถปรับใช้กับ SageMaker ได้ — เกือบจะเสร็จแล้วใช่ไหม ไม่มาก.
บทเรียนที่ยากเกี่ยวกับการโยกย้ายไปยังสถาปัตยกรรมใหม่คือคุณต้องสร้างระบบจริงของคุณสามครั้งเพื่อรองรับการย้าย นอกจากระบบใหม่แล้ว เรายังต้องสร้าง:
- ไปป์ไลน์การจับข้อมูลในระบบเก่าเพื่อบันทึกอินพุตและเอาต์พุตจากโมเดล เราใช้สิ่งเหล่านี้เพื่อยืนยันว่าระบบใหม่จะให้ผลลัพธ์เหมือนเดิม
- ไปป์ไลน์การประมวลผลข้อมูลในระบบใหม่เพื่อคำนวณผลลัพธ์และเปรียบเทียบกับข้อมูลจากระบบเก่า สิ่งนี้เกี่ยวข้องกับการวัดจำนวนมากด้วย Datadog และจำเป็นต้องเสนอความสามารถในการเล่นข้อมูลซ้ำเมื่อเราพบความคลาดเคลื่อน
- ระบบการปรับใช้โมเดลเต็มรูปแบบเพื่อหลีกเลี่ยงผลกระทบต่อผู้ใช้ระบบเก่า (ซึ่งจะอัปโหลดโมเดลไปยัง S3) เรารู้ว่าในที่สุดเราต้องการย้ายพวกมันไปยัง API แต่สำหรับการเปิดตัวครั้งแรก เราจำเป็นต้องดำเนินการอย่างราบรื่น
ทั้งหมดนี้เป็นโค้ดแบบใช้แล้วทิ้งที่เรารู้ว่าสามารถโยนทิ้งได้เมื่อเราย้ายผู้ใช้ทั้งหมดเสร็จแล้ว แต่เรายังคงต้องสร้างมันขึ้นมาและตรวจสอบให้แน่ใจว่าผลลัพธ์ของระบบใหม่ตรงกับระบบเก่า
คาดหวังสิ่งนี้ล่วงหน้า
แม้ว่าการสร้างเครื่องมือและระบบการย้ายข้อมูลจะใช้เวลามากกว่า 60% ของเวลาด้านวิศวกรรมของเราในโครงการนี้ แต่ก็เป็นประสบการณ์ที่สนุกสนานเช่นกัน การทดสอบหน่วยกลายเป็นเหมือนการทดลองวิทยาศาสตร์ข้อมูลมากขึ้น: เราเขียนทั้งชุดเพื่อให้แน่ใจว่าผลลัพธ์ของเราตรงกัน ทุกประการ มันเป็นวิธีคิดที่แตกต่างออกไปที่ทำให้งานสนุกยิ่งขึ้น ก้าวออกจากกรอบปกติของเราถ้าคุณต้องการ
การปรับปรุงระบบเดิมให้ทันสมัยด้วยสถาปัตยกรรมใหม่
ครั้งต่อไปที่คุณถูกล่อลวงให้สร้างระบบใหม่ตั้งแต่เริ่มต้นโค้ด ฉันขอแนะนำให้คุณลองย้ายสถาปัตยกรรมแทนโค้ด คุณจะพบกับความท้าทายด้านเทคนิคที่น่าสนใจและคุ้มค่า และจะสนุกไปกับมันมากกว่าการดีบักกรณี Edge ที่ไม่คาดคิดของโค้ดใหม่ของคุณ
ต้องการเรียนรู้เพิ่มเติมหรือไม่? ดูการบรรยายที่ฉันบรรยายที่ AWS Data Summit ด้านล่าง ซึ่งจะเจาะลึกเกี่ยวกับ MLOps