
เริ่มต้นใช้งาน Web Scraping: เครื่องมือและเทคนิค
เผยแพร่แล้ว: 2023-09-13การขูดเว็บเป็นกระบวนการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติ กลายเป็นทักษะที่จำเป็นสำหรับนักวิเคราะห์ข้อมูล นักวิจัย และธุรกิจที่ต้องการรวบรวมข้อมูลเพื่อวัตถุประสงค์ต่างๆ บทความนี้จะให้ภาพรวมของการขูดเว็บ ประโยชน์ที่ได้รับ เครื่องมือต่างๆ ที่มี เทคนิคขั้นพื้นฐานและขั้นสูง ความท้าทายทั่วไป และแนวปฏิบัติที่ดีที่สุดที่ควรปฏิบัติตามเมื่อเริ่มต้นด้วยการขูดเว็บ
ทำความเข้าใจกับการขูดเว็บ
การขูดเว็บเกี่ยวข้องกับการส่งคำขอ HTTP ไปยังเว็บไซต์ การแยกวิเคราะห์เนื้อหา HTML และการแยกข้อมูลที่ต้องการ ช่วยให้คุณสามารถดึงข้อมูล เช่น ข้อความ รูปภาพ ตาราง และลิงก์จากหน้าเว็บได้ การขูดเว็บมักใช้สำหรับการดึงข้อมูล การวิเคราะห์ข้อมูล ข้อมูลทางการแข่งขัน และการตรวจสอบ
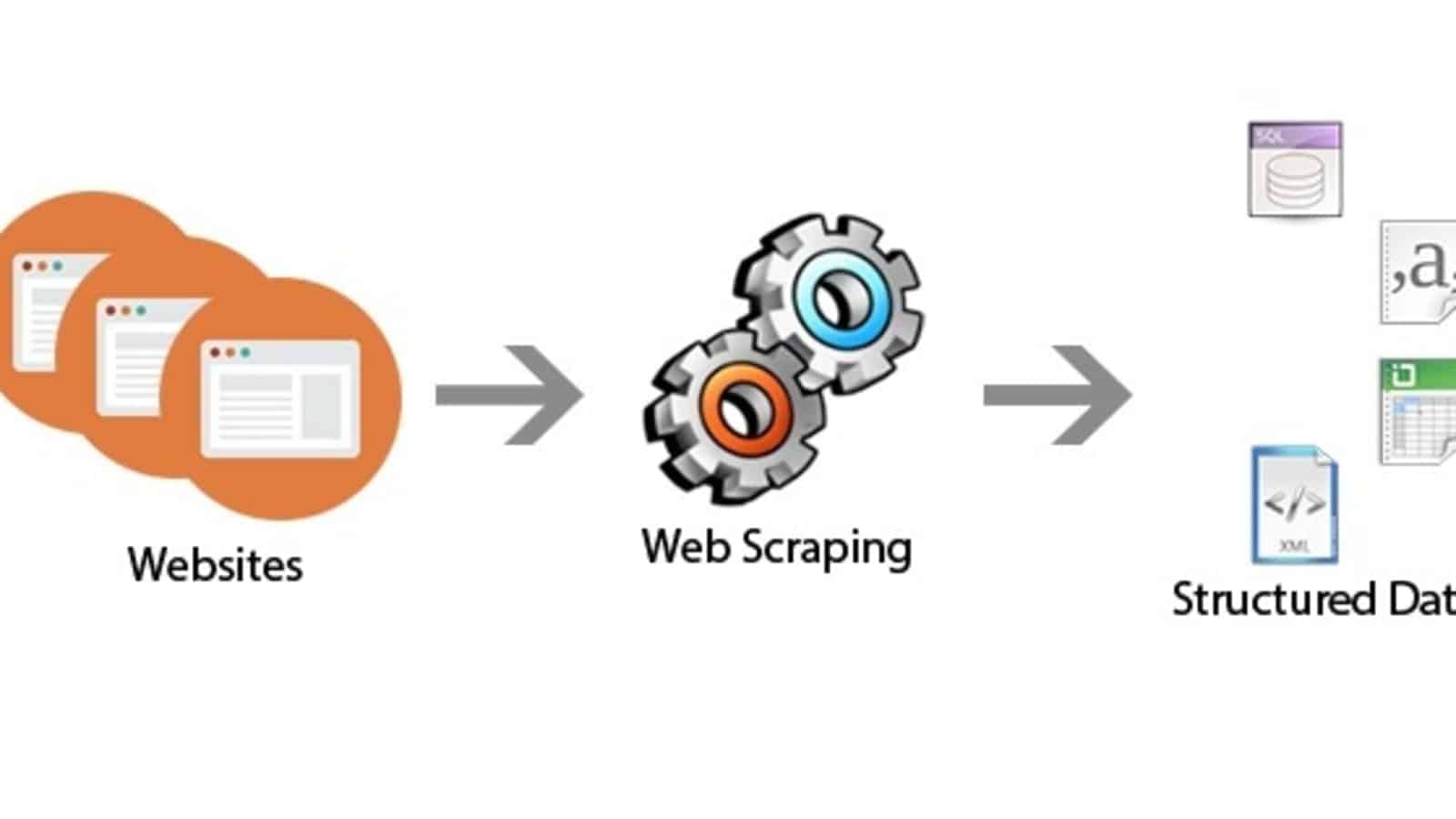
ประโยชน์ของการขูดเว็บ
การขูดเว็บมีประโยชน์มากมาย รวมไปถึง:
- การรวบรวมข้อมูล: การขูดเว็บช่วยให้คุณรวบรวมข้อมูลจำนวนมหาศาลจากหลายแหล่งอย่างรวดเร็วและมีประสิทธิภาพ
- การดึงข้อมูลอัตโนมัติ: แทนที่จะคัดลอกและวางข้อมูลจากเว็บไซต์ด้วยตนเอง การขูดเว็บจะทำให้กระบวนการแยกข้อมูลเป็นไปโดยอัตโนมัติ
- ข้อมูลเรียลไทม์: การขูดเว็บช่วยให้คุณเข้าถึงข้อมูลแบบเรียลไทม์จากเว็บไซต์ ทำให้มั่นใจได้ว่าคุณมีข้อมูลที่ทันสมัยที่สุด
- การวิเคราะห์การแข่งขัน: Web scraping สามารถใช้ในการตรวจสอบเว็บไซต์ของคู่แข่งและดึงข้อมูลอันมีค่าสำหรับการวิเคราะห์ธุรกิจ
- การวิจัยและการวิเคราะห์: การขูดเว็บช่วยให้นักวิจัยมีเครื่องมืออันทรงพลังในการรวบรวมข้อมูลเพื่อการวิเคราะห์และข้อมูลเชิงลึก
การเลือกเครื่องมือขูดเว็บที่เหมาะสม
การเลือกเครื่องมือขูดเว็บที่เหมาะสมเป็นสิ่งสำคัญสำหรับโครงการขูดเว็บที่ประสบความสำเร็จ ต่อไปนี้เป็นเครื่องมือยอดนิยมที่ควรพิจารณา:
- Beautiful Soup: ไลบรารี Python สำหรับแยกวิเคราะห์ไฟล์ HTML และ XML โดยให้วิธีการที่ง่ายและยืดหยุ่นในการนำทาง ค้นหา และดึงข้อมูลจากหน้าเว็บ
- ซีลีเนียม: เครื่องมือทดสอบเว็บที่สามารถใช้ในการขูดเว็บได้ ช่วยให้สามารถโต้ตอบกับเว็บไซต์ที่ต้องอาศัย JavaScript อย่างมากในการแสดงผลเนื้อหา
พิจารณาปัจจัยต่างๆ เช่น ความคุ้นเคยกับภาษาการเขียนโปรแกรม ความซับซ้อนของโครงการ และข้อกำหนดเฉพาะเมื่อเลือกเครื่องมือขูดเว็บที่เหมาะสม
เทคนิคการขูดเว็บขั้นพื้นฐาน
เมื่อเริ่มต้นด้วยการขูดเว็บ คุณสามารถเริ่มต้นด้วยเทคนิคพื้นฐานในการดึงข้อมูลจากหน้าเว็บ ต่อไปนี้เป็นเทคนิคที่ใช้กันทั่วไปบางส่วน:
- การแยกวิเคราะห์ HTML: ใช้ไลบรารีการแยกวิเคราะห์ HTML เช่น Beautiful Soup หรือ lxml เพื่อนำทางผ่านโครงสร้าง HTML ของหน้าเว็บและแยกข้อมูลที่เกี่ยวข้อง
- ตัวเลือก XPath และ CSS: ใช้ตัวเลือก XPath หรือ CSS เพื่อระบุองค์ประกอบเฉพาะบนหน้าเว็บและดึงเนื้อหาของพวกเขา
- การรวม API: บางเว็บไซต์มี API (Application Programming Interfaces) ที่ให้คุณเข้าถึงและดึงข้อมูลในรูปแบบที่มีโครงสร้าง ซึ่งช่วยลดความจำเป็นในการคัดลอก HTML
สิ่งสำคัญที่ควรทราบคือก่อนที่จะทำการคัดลอกเว็บไซต์ คุณควรตรวจสอบข้อกำหนดในการให้บริการของเว็บไซต์ และตรวจสอบให้แน่ใจว่ากิจกรรมการคัดลอกของคุณนั้นถูกกฎหมายและมีจริยธรรม

เทคนิคการขูดเว็บขั้นสูง
เมื่อคุณมีความเชี่ยวชาญในการขูดเว็บ คุณสามารถสำรวจเทคนิคขั้นสูงเพื่อจัดการกับสถานการณ์การขูดที่ซับซ้อนมากขึ้น เทคนิคขั้นสูงบางประการ ได้แก่ :
- การจัดการ JavaScript: เว็บไซต์ที่ใช้ JavaScript เพื่อโหลดเนื้อหาแบบไดนามิกจำเป็นต้องมีเครื่องมือเช่น Selenium เพื่อขูดข้อมูลอย่างมีประสิทธิภาพ
- การแบ่งหน้าและการเลื่อนแบบไม่มีที่สิ้นสุด: เมื่อต้องจัดการกับเนื้อหาที่มีการแบ่งหน้าหรือหน้าที่มีการเลื่อนแบบไม่มีที่สิ้นสุด คุณต้องจำลองการโต้ตอบของผู้ใช้เพื่อดึงข้อมูลจากหลาย ๆ หน้า
- การจัดการเซสชั่น: บางเว็บไซต์จำเป็นต้องมีการจัดการเซสชั่น เช่น การจัดการคุกกี้หรือการรักษาสถานะการเข้าสู่ระบบ เครื่องมืออย่าง Scrapy มีคุณสมบัติในตัวเพื่อจัดการกับสถานการณ์เหล่านี้
ด้วยการเรียนรู้เทคนิคการขูดเว็บขั้นสูง คุณสามารถเอาชนะความท้าทายต่าง ๆ และขูดข้อมูลได้อย่างมีประสิทธิภาพจากเว็บไซต์ที่ซับซ้อนที่สุด
ความท้าทายทั่วไปในการขูดเว็บ

แม้ว่าการขูดเว็บจะมีประโยชน์มากมาย แต่ก็มีความท้าทายบางประการเช่นกัน ความท้าทายทั่วไปบางประการที่ต้องเผชิญในระหว่างการขูดเว็บ ได้แก่ :
- การเปลี่ยนแปลงโครงสร้างเว็บไซต์: เว็บไซต์มักมีการเปลี่ยนแปลงในโครงสร้าง HTML ซึ่งสามารถทำลายสคริปต์การขูดเว็บที่มีอยู่ได้ การบำรุงรักษาและการตรวจสอบสคริปต์การคัดลอกเป็นประจำมีความจำเป็นเพื่อบรรเทาความท้าทายนี้
- การบล็อกแคปต์ชาและ IP: เว็บไซต์อาจใช้แคปต์ชาหรือจำกัดการเข้าถึงตามที่อยู่ IP เพื่อป้องกันการขูดข้อมูล การเอาชนะความท้าทายเหล่านี้อาจต้องใช้พรอกซี การหมุนเวียนที่อยู่ IP หรือใช้เทคนิคการเรียนรู้ของเครื่อง
- ความซับซ้อนในการแยกข้อมูล: บางเว็บไซต์ใช้เทคนิคที่ซับซ้อน เช่น การเรนเดอร์ JavaScript หรือ AJAX เพื่อโหลดข้อมูล ทำให้กระบวนการขูดมีความท้าทายมากขึ้น ใช้เครื่องมือเช่น Selenium หรือใช้ API ทุกครั้งที่เป็นไปได้เพื่อจัดการกับสถานการณ์ดังกล่าว
การตระหนักถึงความท้าทายเหล่านี้และการมีกลยุทธ์ในการจัดการกับสิ่งเหล่านี้จะช่วยในการดำเนินโครงการขูดเว็บที่ประสบความสำเร็จ
แนวทางปฏิบัติที่ดีที่สุดสำหรับการขูดเว็บ
เพื่อให้มั่นใจว่าการขูดเว็บเป็นไปอย่างราบรื่นและมีจริยธรรม จำเป็นอย่างยิ่งที่จะต้องปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุด ต่อไปนี้เป็นหลักเกณฑ์บางประการ:
- เคารพนโยบายเว็บไซต์: ตรวจสอบข้อกำหนดในการให้บริการของเว็บไซต์เสมอ และปฏิบัติตามหลักเกณฑ์หรือข้อจำกัดในการคัดลอกข้อมูล
- หลีกเลี่ยงการโอเวอร์โหลดเซิร์ฟเวอร์: ใช้ความล่าช้าในการขูดคำขอเพื่อหลีกเลี่ยงเซิร์ฟเวอร์ที่ล้นหลามและเพื่อให้ความเคารพต่อแบนด์วิดท์ของเว็บไซต์
- ติดตามการเปลี่ยนแปลง: ตรวจสอบเว็บไซต์ที่คัดลอกมาเป็นประจำเพื่อดูการเปลี่ยนแปลงโครงสร้างหรือข้อมูลที่อาจต้องมีการแก้ไขในสคริปต์การคัดลอกของคุณ
- จัดการข้อผิดพลาดอย่างสง่างาม: ใช้กลไกการจัดการข้อผิดพลาดเพื่อจัดการกับข้อผิดพลาดและข้อยกเว้นที่อาจเกิดขึ้นระหว่างการขูดเว็บ
- อัปเดตอยู่เสมอ: ติดตามเทคนิคการขูดเว็บ แนวปฏิบัติ และข้อพิจารณาทางกฎหมายล่าสุดเพื่อให้แน่ใจว่าการขูดเว็บมีประสิทธิภาพและเป็นไปตามข้อกำหนด
การปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเหล่านี้ไม่เพียงช่วยให้คุณขูดเว็บไซต์ได้อย่างมีประสิทธิภาพ แต่ยังรักษาความสัมพันธ์ที่ดีกับเว็บไซต์ที่คุณดึงข้อมูลมาด้วย
บทสรุป
การขูดเว็บอาจเป็นเครื่องมือที่มีประสิทธิภาพในการรวบรวมข้อมูลและรับข้อมูลเชิงลึกจากเว็บไซต์ ด้วยการเลือกเครื่องมือที่เหมาะสม ทำความเข้าใจเทคนิคพื้นฐานและขั้นสูง การจัดการกับความท้าทายทั่วไป และการปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุด คุณสามารถใช้ประโยชน์จากการขูดเว็บได้อย่างมีประสิทธิภาพ อย่าลืมเคารพนโยบายเว็บไซต์ อัปเดตเทคนิคล่าสุดอยู่เสมอ และจัดการการแยกข้อมูลอย่างมีความรับผิดชอบ ด้วยแนวทางที่ถูกต้อง การขูดเว็บสามารถเป็นทรัพยากรที่มีคุณค่าสำหรับการใช้งานและอุตสาหกรรมต่างๆ