
Jarvis Rising – วิธีที่ Google สร้างโมเดลแมชชีนเลิร์นนิงแบบ “ทันทีทันใด” เพื่อคาดคะเนคำตอบเมื่อ Search ไม่สามารถทำได้ และวิธีที่ Google สามารถสร้างดัชนีโมเดลเหล่านั้นเพื่อคาดคะเนคำตอบสำหรับคำถามในอนาคต [สิทธิบัตร]
เผยแพร่แล้ว: 2023-07-13
หลังจากวิเคราะห์สิทธิบัตรของ Google ที่เกี่ยวข้องกับ PAA และ PASF แล้ว ฉันก็เริ่มตรวจสอบสิทธิบัตรอื่นๆ ที่เพิ่งได้รับ และไม่นานก่อนที่ฉันจะได้พบอีกอันที่น่าสนใจมากเกี่ยวกับการใช้โมเดลแมชชีนเลิร์นนิง สิทธิบัตรที่ฉันเพิ่งวิเคราะห์มุ่งเน้นไปที่การใช้และ/หรือการสร้างโมเดลแมชชีนเลิร์นนิงเพื่อตอบสนองต่อข้อความค้นหา (เมื่อ Google จำเป็นต้องคาดคะเนคำตอบเนื่องจากผลการค้นหามาตรฐานไม่สามารถให้คำตอบที่เพียงพอได้) หลังจากอ่านสิทธิบัตรหลายครั้ง เอกสารดังกล่าวเน้นย้ำว่าระบบของ Google มีความซับซ้อนเพียงใดเมื่อจำเป็นต้องให้คำตอบที่มีคุณภาพ (หรือการคาดคะเน) สำหรับผู้ใช้
เช่นเดียวกับสิทธิบัตรใดๆ เราไม่สามารถทราบได้ว่า Google นำสิ่งที่สิทธิบัตรครอบคลุมไปใช้จริงหรือไม่ แต่ก็เป็นไปได้เสมอ และหากมีการนำไปใช้ Google ไม่เพียงแต่สามารถใช้โมเดลแมชชีนเลิร์นนิงที่ผ่านการฝึกอบรมแล้วเพื่อช่วย ทำนาย คำตอบสำหรับคำถามเท่านั้น แต่ยังสามารถ จัดทำดัชนี โมเดลแมชชีนเลิร์นนิงเหล่านั้น เชื่อมโยงกับเอนทิตี หน้าเว็บ ฯลฯ ต่างๆ จากนั้นจึงดึงข้อมูลและ ใช้โมเดลเหล่านั้นสำหรับการค้นหาที่เกี่ยวข้องในภายหลัง ลองคิดดูว่า Google จะมีประสิทธิภาพและปรับขนาดได้เพียงใด
นอกจากนี้ สิทธิบัตรยังอธิบายว่า Google สามารถส่งคืน อินเทอร์เฟ ซแบบอินเทอร์แอกทีฟให้กับโมเดลแมชชีนเลิร์นนิงในผลการค้นหา ซึ่งช่วยให้ผู้ใช้สามารถเพิ่มพารามิเตอร์ซึ่งสามารถใช้เพื่อสร้างการคาดคะเนสำหรับข้อความค้นหาเมื่อผลการค้นหาไม่เพียงพอ ส่วนหนึ่งของสิทธิบัตรนั้นทำให้ฉันคิดถึงข้อความที่ Google เปิดตัวใน SERPs ในเดือนเมษายน 2020 เมื่อมีการส่งคืนผลการค้นหาที่ไม่ได้คุณภาพสำหรับข้อความค้นหา การใช้งานปัจจุบันไม่มีรูปแบบสำหรับผู้ใช้ในการโต้ตอบ แต่แน่นอนว่าอาจทำได้ในบางจุด และบางทีอินเทอร์เฟซนั้นอาจใช้สำหรับการสืบค้นเพิ่มเติมในอนาคต แทนที่จะใช้เพียงสิ่งที่คลุมเครือมากขึ้นในตอนนี้ ฉันจะอธิบายเพิ่มเติมเกี่ยวกับเรื่องนี้ในหัวข้อย่อยด้านล่าง
ประเด็นสำคัญจากสิทธิบัตร:
คล้ายกับโพสต์ล่าสุดของฉันซึ่งครอบคลุมสิทธิบัตร Google ล่าสุด ฉันคิดว่าวิธีที่ดีที่สุดในการครอบคลุมรายละเอียดคือการให้หัวข้อย่อยของประเด็นสำคัญ
การสร้างและ/หรือการใช้โมเดลแมชชีนเลิร์นนิงเพื่อตอบสนองคำขอค้นหา
สหรัฐ 11645277 B2
วันที่ได้รับ: 9 พฤษภาคม 2023
วันที่ยื่น: 12 ธันวาคม 2017
ชื่อผู้รับมอบสิทธิ์: Google LLC
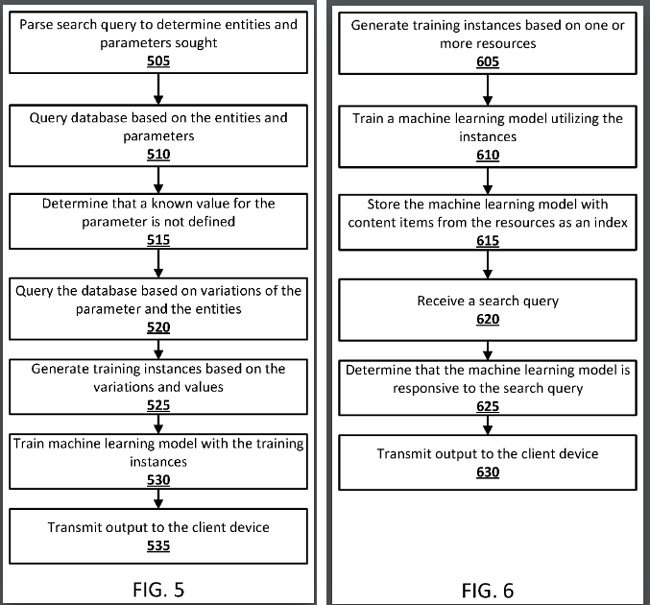
1. สิทธิบัตรของ Google อธิบายว่าหากไม่สามารถระบุคำตอบได้อย่างแน่ชัด และผู้ใช้ส่งคำขอที่มีลักษณะเป็นการคาดการณ์ คุณสามารถใช้โมเดลแมชชีนเลิร์นนิงที่ได้รับการฝึกฝนเพื่อสร้างการคาดคะเนได้
2. ตัวอย่างเช่น ก่อนอื่น Google สามารถสร้างผลการค้นหาตามข้อความค้นหา แต่ถ้าผลลัพธ์มีคุณภาพไม่เพียงพอ ก็สามารถใช้โมเดลแมชชีนเลิร์นนิงเพื่อให้คำตอบที่คาดการณ์ไว้ชัดเจนยิ่งขึ้น ดังนั้น ระบบสามารถให้คำตอบที่คาดคะเนตามโมเดลแมชชีนเลิร์นนิงเมื่อ Google ไม่สามารถตรวจสอบคำตอบได้

3. นอกจากนี้ยังสามารถสร้างโมเดลแมชชีนเลิร์นนิงได้ "ทันที" และ Google อาจจัดเก็บโมเดลแมชชีนเลิร์นนิงที่ผ่านการฝึกอบรมไว้ในดัชนีการค้นหา ได้ Google สามารถจัดทำดัชนีโมเดลแมชชีนเลิร์นนิงที่ได้รับการฝึกฝนเพื่อให้คาดการณ์ตามประเภทของข้อความค้นหาที่เฉพาะเจาะจง ฉันจะอธิบายเพิ่มเติมเกี่ยวกับเรื่องนี้ในไม่ช้า

4. สิทธิบัตรดังกล่าวได้ยกตัวอย่างจากคำถามว่า “ในปี 2050 จะมีแพทย์กี่คนในจีน” หากไม่สามารถให้คำตอบที่เชื่อถือได้ผ่านผลการค้นหามาตรฐาน การสืบค้นสามารถส่งผ่านไปยังโมเดลแมชชีนเลิร์นนิงที่ได้รับการฝึกฝนเพื่อสร้างการคาดคะเน

5. สิทธิบัตรอธิบายต่อไปว่าระบบอาจใช้เวลาปีอื่นๆ เช่น 2010, 2015, 2020 เป็นต้น และใช้สิ่งเหล่านั้นเพื่อสร้างการคาดการณ์ (ผ่านโมเดลการเรียนรู้ของเครื่องที่ได้รับการฝึกฝนเกี่ยวกับพารามิเตอร์เหล่านั้น)

6. สิทธิบัตรอธิบายว่าโมเดลแมชชีนเลิร์นนิงที่ผ่านการฝึกอบรมสามารถจัดทำดัชนีโดยรายการเนื้อหาตั้งแต่หนึ่งรายการขึ้นไปจาก “ทรัพยากรที่ใช้ในการฝึกโมเดล” และสำหรับการสืบค้นในอนาคต เมื่อระบบระบุพารามิเตอร์ที่เกี่ยวข้องกับโมเดลแมชชีนเลิร์นนิง (เช่น หากผู้ใช้คนต่อมาถามคำถามที่เกี่ยวข้อง เช่น "มีแพทย์กี่คนในประเทศจีนใน ปี 2040 ") โมเดลแมชชีนเลิร์นนิงอาจ ใช้เพื่อสร้างคำทำนาย

7. สิทธิบัตรอธิบายต่อไปว่าโมเดลแมชชีนเลิร์นนิงสามารถเก็บไว้กับรายการเนื้อหาหนึ่งรายการหรือมากกว่า เช่น เอนทิตีในกราฟความรู้ ชื่อตาราง ชื่อคอลัมน์ ชื่อหน้าเว็บ และอื่นๆ นอกจากนี้ โมเดลแมชชีนเลิร์นนิงยังใช้คำที่เกี่ยวข้องกับข้อความค้นหา เช่น "จีน" และ "แพทย์" เพื่อสร้างการคาดคะเนได้
8. สิทธิบัตรอธิบายต่อไปว่าระบบอาจมีอินเทอร์เฟซแบบโต้ตอบสำหรับผู้ใช้เพื่อเลือกพารามิเตอร์ที่สามารถส่งผ่านไปยังโมเดลการเรียนรู้ของเครื่อง ซึ่งอาจเป็นช่องข้อความ เมนูแบบเลื่อนลง เป็นต้น นอกจากนี้ การตอบสนองอาจรวมถึงข้อความที่แสดงต่อผู้ใช้ว่าการตอบสนองเป็นการคาดคะเนตามโมเดลแมชชีนเลิร์นนิงที่ได้รับการฝึกฝน ดังนั้น Google จึงต้องการให้แน่ใจว่าผู้ใช้เข้าใจว่าเป็นการคาดคะเนตามโมเดลแมชชีนเลิร์นนิงเมื่อเทียบกับคำตอบที่ให้ตามข้อมูลที่จัดทำดัชนีไว้

9. จากนั้นโมเดลที่ผ่านการฝึกอบรมจะสามารถตรวจสอบได้เพื่อให้แน่ใจว่าการคาดการณ์นั้นมี "คุณภาพเกณฑ์" เป็นอย่างน้อย สิ่งใดที่ต่ำกว่าเกณฑ์ที่กำหนดสามารถถูกระงับและไม่ได้มอบให้กับผู้ใช้ ในกรณีนั้น ผลการค้นหามาตรฐานสามารถแสดงแทนได้

10. นอกเหนือจากผลการค้นหาสาธารณะ สิทธิบัตรอธิบายว่าระบบสามารถใช้กับฐานข้อมูลส่วนตัวเพื่อช่วยให้บริษัทคาดการณ์ผลลัพธ์บางอย่างได้ สิทธิบัตรอธิบายว่า “เป็นส่วนตัวสำหรับกลุ่มผู้ใช้ บริษัท และ/หรือชุดจำกัดอื่นๆ” ตัวอย่างเช่น พนักงานของสวนสนุกอาจถามว่า “พรุ่งนี้เราจะขายกรวยหิมะได้กี่ลูก” จากนั้นระบบสามารถค้นหาฐานข้อมูลส่วนตัวเพื่อทำความเข้าใจยอดขายของวันก่อนหน้า ข้อมูลสภาพอากาศ ข้อมูลการเข้างาน ฯลฯ เพื่อคาดคะเนคำตอบสำหรับพนักงาน
11. สิทธิบัตรอธิบายว่าระบบสามารถให้ การแจ้งเตือนแบบพุช จาก "ผู้ช่วยอัตโนมัติ" ได้ในบางจุด และเพียงแค่คิดออกมาดัง ๆ ฉันก็สงสัยว่านั่นอาจมาจากผู้ช่วยที่เหมือนจาร์วิสอย่างที่ฉันอธิบายในโพสต์ของฉันเกี่ยวกับ Code Red ของ Google ที่เรียกใช้ Code Reds นับพันที่ผู้เผยแพร่

12. จากมุมมองด้านเวลาแฝง สิทธิบัตรอธิบายว่าอาจมีความล่าช้าหลังจากที่ผู้ใช้ส่งคำถาม เมื่อเป็นเช่นนั้น ผลการค้นหามาตรฐานอาจแสดงขึ้นในขั้นต้นพร้อมกับข้อความว่าไม่มีผลการค้นหา "ดี" สำหรับข้อความค้นหา และมีการใช้โมเดลการเรียนรู้ของเครื่องเพื่อสร้างการคาดคะเน ในสถานการณ์เหล่านั้น ระบบสามารถส่งการคาดคะเนนั้นไปยังผู้ใช้ในภายหลัง หรือจัดเตรียมไฮเปอร์ลิงก์ให้ผู้ใช้คลิกเพื่อดูผลลัพธ์ของแมชชีนเลิร์นนิง
13. นอกจากนี้ สิทธิบัตรระบุในบางสถานการณ์ว่าผู้ใช้จะต้องยืนยันข้อความแจ้งเพื่อให้กระบวนการดำเนินการต่อไป ตัวอย่างเช่น ระบบอาจแสดงข้อความว่า “ไม่มีคำตอบที่ดี คุณต้องการให้ฉันทำนายคำตอบให้คุณหรือไม่” จากนั้นโมเดลแมชชีนเลิร์นนิงจะได้รับการฝึกอบรมเฉพาะเมื่อได้รับการตอบรับจากผู้ใช้เพื่อตอบสนองต่อข้อความแจ้ง อย่างที่ฉันอธิบายไปก่อนหน้านี้ ฉันเห็นความเชื่อมโยงกับข้อความ “ไม่มีรายการที่ตรงกับการค้นหาของคุณมากนัก” ที่เปิดตัวในเดือนเมษายน 2020 ฉันสงสัยว่าจะขยายไปสู่การใช้โมเดลนี้ในอนาคตหรือไม่…

สรุป: Google สามารถคาดคะเนคำตอบที่มีคุณภาพด้วยวิธีที่ทรงพลังและมีประสิทธิภาพสูงผ่านโมเดลการเรียนรู้ของเครื่อง (จัดทำดัชนี)
แม้ว่าเราจะไม่ทราบว่ามีการใช้สิทธิบัตรใดเป็นพิเศษหรือไม่ แต่พลังและประสิทธิภาพของกระบวนการนี้เหมาะสมอย่างยิ่งสำหรับ Google จากการสร้างโมเดลแมชชีนเลิร์นนิงแบบ "ทันที" ไปจนถึงการจัดทำดัชนีโมเดลเหล่านั้นสำหรับการใช้งานในอนาคต ไปจนถึงการใช้อินเทอร์เฟซแบบอินเทอร์แอกทีฟพร้อมการแจ้งเตือนแบบพุช ดูเหมือนว่า Google กำลังเตรียมขั้นตอนสำหรับผู้ช่วยอย่างจาร์วิส ดังนั้น ครั้งต่อไปที่คุณขอให้ Google คาดเดาคำตอบ ให้นึกถึงสิทธิบัตรนี้ และคุณอาจได้รับแจ้งให้ขอข้อมูลเพิ่มเติมในบางจุด (จนกว่า Jarvis จะทำทั้งหมดนี้ได้ในเสี้ยววินาที) :)
จีจี