
การเรียนรู้เครื่องขูดหน้าเว็บ: คู่มือสำหรับผู้เริ่มต้นในการดึงข้อมูลออนไลน์
เผยแพร่แล้ว: 2024-04-09Web Page Scrapers คืออะไร?
เครื่องมือขูดหน้าเว็บเป็นเครื่องมือที่ออกแบบมาเพื่อดึงข้อมูลจากเว็บไซต์ มันจำลองการนำทางของมนุษย์เพื่อรวบรวมเนื้อหาเฉพาะ ผู้เริ่มต้นมักจะใช้ประโยชน์จากเครื่องขูดเหล่านี้สำหรับงานที่หลากหลาย รวมถึงการวิจัยตลาด การตรวจสอบราคา และการรวบรวมข้อมูลสำหรับโปรเจ็กต์แมชชีนเลิร์นนิง
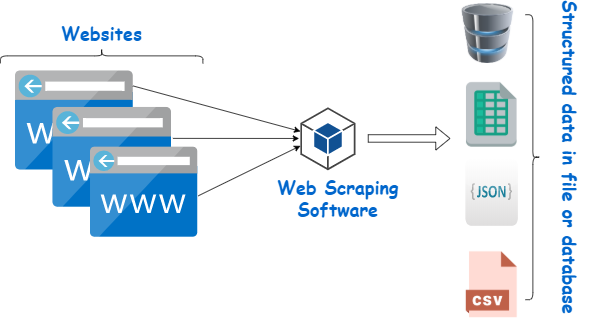
ที่มาของภาพ: https://www.webharvy.com/articles/what-is-web-scraping.html
- ใช้งานง่าย: เป็นมิตรกับผู้ใช้ ช่วยให้บุคคลที่มีทักษะด้านเทคนิคขั้นต่ำสามารถรวบรวมข้อมูลเว็บได้อย่างมีประสิทธิภาพ
- ประสิทธิภาพ: เครื่องขูดสามารถรวบรวมข้อมูลจำนวนมากได้อย่างรวดเร็ว ซึ่งเหนือกว่าความพยายามในการรวบรวมข้อมูลด้วยตนเองมาก
- ความแม่นยำ: การขูดอัตโนมัติช่วยลดความเสี่ยงของข้อผิดพลาดของมนุษย์ เพิ่มความแม่นยำของข้อมูล
- คุ้มทุน: ขจัดความจำเป็นในการป้อนข้อมูลด้วยตนเอง ประหยัดค่าแรงและเวลา
การทำความเข้าใจฟังก์ชันการทำงานของโปรแกรมขูดหน้าเว็บถือเป็นสิ่งสำคัญสำหรับทุกคนที่ต้องการควบคุมพลังของข้อมูลเว็บ
การสร้าง Web Page Scraper อย่างง่ายด้วย Python
ในการเริ่มสร้างตัวขูดหน้าเว็บใน Python จำเป็นต้องติดตั้งไลบรารีบางตัว เช่น คำขอให้ส่งคำขอ HTTP ไปยังหน้าเว็บ และ BeautifulSoup จาก bs4 เพื่อแยกวิเคราะห์เอกสาร HTML และ XML
- เครื่องมือรวบรวม:
- ไลบรารี: ใช้คำขอเพื่อดึงข้อมูลหน้าเว็บและ BeautifulSoup เพื่อแยกวิเคราะห์เนื้อหา HTML ที่ดาวน์โหลด
- การกำหนดเป้าหมายหน้าเว็บ:
- กำหนด URL ของหน้าเว็บที่มีข้อมูลที่เราต้องการคัดลอก
- การดาวน์โหลดเนื้อหา:
- ใช้คำขอดาวน์โหลดโค้ด HTML ของหน้าเว็บ
- แยกวิเคราะห์ HTML:
- BeautifulSoup จะเปลี่ยน HTML ที่ดาวน์โหลดมาเป็นรูปแบบที่มีโครงสร้างเพื่อให้ง่ายต่อการนำทาง
- การดึงข้อมูล:
- ระบุแท็ก HTML เฉพาะที่มีข้อมูลที่เราต้องการ (เช่น ชื่อผลิตภัณฑ์ภายในแท็ก <div>)
- ใช้วิธีการของ BeautifulSoup เพื่อแยกและประมวลผลข้อมูลที่คุณต้องการ
อย่าลืมกำหนดเป้าหมายองค์ประกอบ HTML เฉพาะที่เกี่ยวข้องกับข้อมูลที่คุณต้องการคัดลอก
กระบวนการทีละขั้นตอนสำหรับการขูดเว็บเพจ
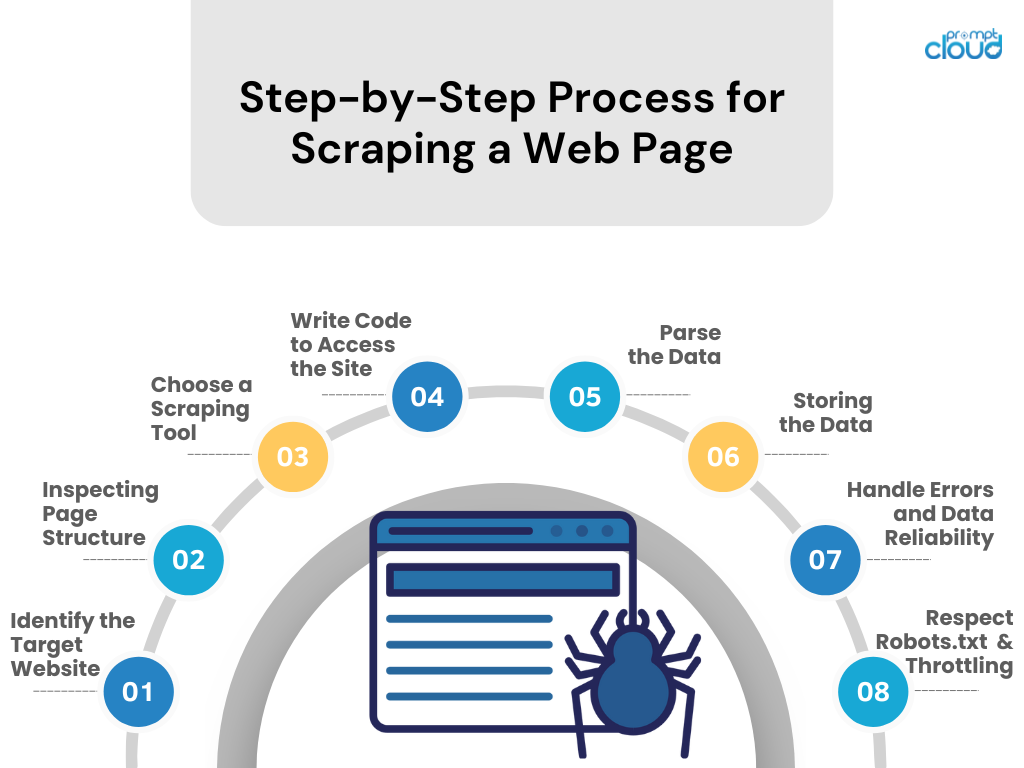
- ระบุเว็บไซต์เป้าหมาย
ศึกษาเว็บไซต์ที่คุณต้องการขูด ตรวจสอบให้แน่ใจว่าการทำเช่นนั้นถูกกฎหมายและมีจริยธรรม - การตรวจสอบโครงสร้างหน้า
ใช้เครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ของเบราว์เซอร์เพื่อตรวจสอบโครงสร้าง HTML ตัวเลือก CSS และเนื้อหาที่ขับเคลื่อนด้วย JavaScript - เลือกเครื่องมือขูด
เลือกเครื่องมือหรือไลบรารีในภาษาการเขียนโปรแกรมที่คุณคุ้นเคย (เช่น BeautifulSoup หรือ Scrapy ของ Python) - เขียนโค้ดเพื่อเข้าถึงไซต์
สร้างสคริปต์ที่ขอข้อมูลจากเว็บไซต์โดยใช้การเรียก API หากมีหรือคำขอ HTTP - แยกวิเคราะห์ข้อมูล
แยกข้อมูลที่เกี่ยวข้องออกจากหน้าเว็บโดยแยกวิเคราะห์ HTML/CSS/JavaScript - การจัดเก็บข้อมูล
บันทึกข้อมูลที่คัดลอกมาในรูปแบบที่มีโครงสร้าง เช่น CSV, JSON หรือลงในฐานข้อมูลโดยตรง - จัดการกับข้อผิดพลาดและความน่าเชื่อถือของข้อมูล
ใช้การจัดการข้อผิดพลาดเพื่อจัดการความล้มเหลวของคำขอและรักษาความสมบูรณ์ของข้อมูล - เคารพ Robots.txt และการควบคุมปริมาณ
ปฏิบัติตามกฎไฟล์ robots.txt ของไซต์ และหลีกเลี่ยงการทำให้เซิร์ฟเวอร์ล้นหลามโดยการควบคุมอัตราการร้องขอ
การเลือกเครื่องมือขูดเว็บที่เหมาะกับความต้องการของคุณ
เมื่อทำการขูดเว็บ การเลือกเครื่องมือที่สอดคล้องกับความสามารถและเป้าหมายของคุณเป็นสิ่งสำคัญ ผู้เริ่มต้นควรพิจารณา:
- ใช้งานง่าย: เลือกใช้เครื่องมือที่ใช้งานง่ายพร้อมความช่วยเหลือด้วยภาพและเอกสารที่ชัดเจน
- ข้อกำหนดข้อมูล: ประเมินโครงสร้างและความซับซ้อนของข้อมูลเป้าหมายเพื่อพิจารณาว่าจำเป็นต้องมีส่วนขยายอย่างง่ายหรือซอฟต์แวร์ที่มีประสิทธิภาพหรือไม่
- งบประมาณ: ชั่งน้ำหนักต้นทุนกับคุณสมบัติต่างๆ เครื่องขูดที่มีประสิทธิภาพหลายเครื่องเสนอระดับฟรี
- การปรับแต่ง: ตรวจสอบให้แน่ใจว่าเครื่องมือสามารถปรับเปลี่ยนได้ตามความต้องการในการขูดเฉพาะ
- การสนับสนุน: การเข้าถึงชุมชนผู้ใช้ที่เป็นประโยชน์ช่วยในการแก้ไขปัญหาและปรับปรุง
เลือกอย่างชาญฉลาดเพื่อการเดินทางที่ราบรื่น
คำแนะนำและเคล็ดลับในการเพิ่มประสิทธิภาพเครื่องขูดหน้าเว็บของคุณ
- ใช้ไลบรารีการแยกวิเคราะห์ที่มีประสิทธิภาพ เช่น BeautifulSoup หรือ Lxml ใน Python เพื่อการประมวลผล HTML ที่เร็วขึ้น
- ใช้แคชเพื่อหลีกเลี่ยงการดาวน์โหลดเพจซ้ำและลดภาระบนเซิร์ฟเวอร์
- เคารพไฟล์ robots.txt และใช้การจำกัดอัตราเพื่อป้องกันการถูกแบนโดยเว็บไซต์เป้าหมาย
- หมุนเวียนตัวแทนผู้ใช้และพร็อกซีเซิร์ฟเวอร์เพื่อเลียนแบบพฤติกรรมของมนุษย์และหลีกเลี่ยงการตรวจจับ
- กำหนดเวลาแครปเปอร์ในช่วงนอกเวลาเร่งด่วนเพื่อลดผลกระทบต่อประสิทธิภาพของเว็บไซต์
- เลือกใช้ตำแหน่งข้อมูล API หากมี เนื่องจากให้ข้อมูลที่มีโครงสร้างและโดยทั่วไปมีประสิทธิภาพมากกว่า
- หลีกเลี่ยงการขูดข้อมูลที่ไม่จำเป็นโดยการเลือกคำค้นหาของคุณ ซึ่งจะช่วยลดแบนด์วิดท์และพื้นที่เก็บข้อมูลที่จำเป็น
- อัปเดตเครื่องขูดของคุณเป็นประจำเพื่อปรับให้เข้ากับการเปลี่ยนแปลงโครงสร้างเว็บไซต์และรักษาความสมบูรณ์ของข้อมูล
การจัดการปัญหาทั่วไปและการแก้ไขปัญหาในการขูดหน้าเว็บ
เมื่อทำงานกับเครื่องขูดหน้าเว็บ ผู้เริ่มต้นอาจประสบปัญหาทั่วไปหลายประการ:

- ปัญหาเกี่ยวกับตัวเลือก : ตรวจสอบให้แน่ใจว่าตัวเลือกตรงกับโครงสร้างปัจจุบันของหน้าเว็บ เครื่องมือเช่นเครื่องมือสำหรับนักพัฒนาเบราว์เซอร์สามารถช่วยระบุตัวเลือกที่ถูกต้องได้
- เนื้อหาแบบไดนามิก : หน้าเว็บบางหน้าโหลดเนื้อหาแบบไดนามิกด้วย JavaScript ในกรณีเช่นนี้ ให้พิจารณาใช้เบราว์เซอร์แบบไม่มีส่วนหัวหรือเครื่องมือที่แสดงผล JavaScript
- คำขอที่ถูกบล็อก : เว็บไซต์อาจบล็อกเครื่องขูด ใช้กลยุทธ์ต่างๆ เช่น การหมุนเวียนตัวแทนผู้ใช้ การใช้พร็อกซี และการปฏิบัติตาม robots.txt เพื่อลดการบล็อก
- ปัญหารูปแบบข้อมูล : ข้อมูลที่แยกออกมาอาจจำเป็นต้องล้างหรือจัดรูปแบบ ใช้นิพจน์ทั่วไปและการจัดการสตริงเพื่อสร้างมาตรฐานของข้อมูล
อย่าลืมศึกษาเอกสารและฟอรัมชุมชนเพื่อดูคำแนะนำในการแก้ไขปัญหาเฉพาะ
บทสรุป
ขณะนี้ผู้เริ่มต้นสามารถรวบรวมข้อมูลจากเว็บได้อย่างสะดวกผ่านเครื่องมือขูดหน้าเว็บ ทำให้การวิจัยและการวิเคราะห์มีประสิทธิภาพมากขึ้น การทำความเข้าใจวิธีการที่ถูกต้องในขณะที่พิจารณาด้านกฎหมายและจริยธรรมทำให้ผู้ใช้สามารถควบคุมศักยภาพสูงสุดของการขูดเว็บได้ ปฏิบัติตามหลักเกณฑ์เหล่านี้เพื่อการแนะนำการขูดหน้าเว็บที่ราบรื่น ซึ่งเต็มไปด้วยข้อมูลเชิงลึกอันมีค่าและการตัดสินใจอย่างมีข้อมูล
คำถามที่พบบ่อย:
การขูดหน้าคืออะไร?
การขูดเว็บหรือที่เรียกว่า Data Scraping หรือการเก็บเกี่ยวเว็บ ประกอบด้วยการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติโดยใช้โปรแกรมคอมพิวเตอร์ที่เลียนแบบพฤติกรรมการนำทางของมนุษย์ ด้วยเครื่องมือขูดหน้าเว็บ ทำให้สามารถจัดเรียงข้อมูลจำนวนมหาศาลได้อย่างรวดเร็ว โดยเน้นไปที่ส่วนสำคัญเพียงอย่างเดียว แทนที่จะรวบรวมด้วยตนเอง
ธุรกิจต่างๆ ใช้ Web Scraping สำหรับฟังก์ชันต่างๆ เช่น ตรวจสอบต้นทุน การจัดการชื่อเสียง วิเคราะห์แนวโน้ม และดำเนินการวิเคราะห์การแข่งขัน การใช้โครงการขูดเว็บรับประกันว่าเว็บไซต์ที่เยี่ยมชมอนุมัติการดำเนินการและการปฏิบัติตาม robots.txt และโปรโตคอลที่ไม่ปฏิบัติตามที่เกี่ยวข้องทั้งหมด
ฉันจะขูดทั้งหน้าได้อย่างไร
หากต้องการคัดลอกหน้าเว็บทั้งหมด โดยทั่วไปคุณจะต้องมีองค์ประกอบ 2 ส่วน ได้แก่ วิธีค้นหาข้อมูลที่ต้องการภายในหน้าเว็บ และกลไกในการบันทึกข้อมูลนั้นไว้ที่อื่น ภาษาการเขียนโปรแกรมหลายภาษารองรับการขูดเว็บ โดยเฉพาะ Python และ JavaScript
มีไลบรารีโอเพ่นซอร์สหลายแห่งสำหรับทั้งสอง ซึ่งช่วยให้กระบวนการง่ายยิ่งขึ้นไปอีก ตัวเลือกยอดนิยมในหมู่นักพัฒนา Python ได้แก่ BeautifulSoup, Requests, LXML และ Scrapy อีกทางหนึ่ง แพลตฟอร์มเชิงพาณิชย์ เช่น ParseHub และ Octoparse ช่วยให้บุคคลที่มีเทคนิคน้อยสามารถสร้างเวิร์กโฟลว์การขูดเว็บที่ซับซ้อนได้ด้วยการมองเห็น หลังจากติดตั้งไลบรารีที่จำเป็นและทำความเข้าใจแนวคิดพื้นฐานเบื้องหลังการเลือกองค์ประกอบ DOM แล้ว ให้เริ่มต้นด้วยการระบุจุดข้อมูลที่น่าสนใจภายในหน้าเว็บเป้าหมาย
ใช้เครื่องมือสำหรับนักพัฒนาเบราว์เซอร์เพื่อตรวจสอบแท็ก HTML และแอตทริบิวต์ จากนั้นแปลผลการค้นพบเหล่านี้เป็นไวยากรณ์ที่เกี่ยวข้องซึ่งสนับสนุนโดยไลบรารีหรือแพลตฟอร์มที่เลือก สุดท้าย ระบุการตั้งค่ารูปแบบเอาต์พุต ไม่ว่าจะเป็น CSV, Excel, JSON, SQL หรือตัวเลือกอื่น พร้อมทั้งปลายทางที่มีข้อมูลที่บันทึกไว้
ฉันจะใช้มีดโกนของ Google ได้อย่างไร
ตรงกันข้ามกับความเชื่อที่นิยม Google ไม่ได้เสนอเครื่องมือขูดเว็บสาธารณะโดยตรง แม้ว่าจะมี API และ SDK เพื่ออำนวยความสะดวกในการผสานรวมกับผลิตภัณฑ์หลายรายการอย่างราบรื่นก็ตาม อย่างไรก็ตาม นักพัฒนาที่มีทักษะได้สร้างโซลูชันของบุคคลที่สามซึ่งสร้างขึ้นจากเทคโนโลยีหลักของ Google ซึ่งขยายความสามารถอย่างมีประสิทธิผลนอกเหนือจากฟังก์ชันการทำงานแบบเนทีฟ ตัวอย่าง ได้แก่ SerpApi ซึ่งสรุปแง่มุมที่ซับซ้อนของ Google Search Console และนำเสนออินเทอร์เฟซที่ใช้งานง่ายสำหรับการติดตามการจัดอันดับคำหลัก การประมาณค่าการเข้าชมทั่วไป และการสำรวจลิงก์ย้อนกลับ
แม้ว่าทางเทคนิคจะแตกต่างจากการขูดเว็บแบบเดิมๆ แต่โมเดลไฮบริดเหล่านี้ก็พร่าเลือนเส้นแบ่งระหว่างคำจำกัดความทั่วไป ตัวอย่างอื่นๆ แสดงให้เห็นความพยายามทางวิศวกรรมย้อนกลับที่นำไปใช้กับการสร้างตรรกะภายในขึ้นมาใหม่ซึ่งขับเคลื่อนแพลตฟอร์ม Google Maps, YouTube Data API v3 หรือ Google Shopping Services ทำให้มีฟังก์ชันการทำงานที่ใกล้เคียงกับเวอร์ชันดั้งเดิมอย่างน่าทึ่ง แม้ว่าจะขึ้นอยู่กับระดับความถูกต้องตามกฎหมายและความเสี่ยงด้านความยั่งยืนที่แตกต่างกันไป ท้ายที่สุดแล้ว ผู้ขูดหน้าเว็บที่ต้องการควรสำรวจตัวเลือกที่หลากหลายและประเมินข้อดีที่เกี่ยวข้องกับข้อกำหนดเฉพาะก่อนที่จะตัดสินใจเลือกเส้นทางที่กำหนด
มีดโกน Facebook ถูกกฎหมายหรือไม่?
ตามที่ระบุไว้ในนโยบายนักพัฒนาของ Facebook การขูดเว็บโดยไม่ได้รับอนุญาตถือเป็นการละเมิดมาตรฐานชุมชนอย่างชัดเจน ผู้ใช้ตกลงที่จะไม่พัฒนาหรือใช้งานแอปพลิเคชัน สคริปต์ หรือกลไกอื่น ๆ ที่ออกแบบมาเพื่อหลีกเลี่ยงหรือเกินขีดจำกัดอัตรา API ที่กำหนด และจะไม่พยายามถอดรหัส แยกส่วน หรือวิศวกรรมย้อนกลับด้านใด ๆ ของไซต์หรือบริการ นอกจากนี้ยังเน้นย้ำถึงความคาดหวังเกี่ยวกับการปกป้องข้อมูลและความเป็นส่วนตัว โดยต้องได้รับความยินยอมจากผู้ใช้อย่างชัดเจนก่อนที่จะแบ่งปันข้อมูลที่สามารถระบุตัวบุคคลได้นอกบริบทที่ได้รับอนุญาต
การไม่ปฏิบัติตามหลักการที่ระบุไว้จะกระตุ้นให้เกิดมาตรการทางวินัยที่เพิ่มมากขึ้น โดยเริ่มด้วยการตักเตือน และค่อยๆ ก้าวไปสู่การจำกัดการเข้าถึงหรือการเพิกถอนสิทธิพิเศษโดยสมบูรณ์ ขึ้นอยู่กับระดับความรุนแรง แม้ว่าจะมีข้อยกเว้นสำหรับนักวิจัยด้านความปลอดภัยที่ดำเนินงานภายใต้โปรแกรม Bug Bounty ที่ได้รับอนุมัติ ผู้สนับสนุนที่เป็นเอกฉันท์ทั่วไปก็หลีกเลี่ยงโครงการริเริ่ม Facebook ที่ไม่ได้รับอนุญาตเพื่อเลี่ยงภาวะแทรกซ้อนที่ไม่จำเป็น ให้พิจารณาดำเนินการทางเลือกอื่นที่เข้ากันได้กับบรรทัดฐานและแบบแผนทั่วไปที่ได้รับการรับรองโดยแพลตฟอร์ม