
โปรแกรมรวบรวมข้อมูลเว็บ Python – การสอนแบบทีละขั้นตอน
เผยแพร่แล้ว: 2023-12-07โปรแกรมรวบรวมข้อมูลเว็บเป็นเครื่องมือที่น่าสนใจในโลกของการรวบรวมข้อมูลและการขูดเว็บ พวกเขาทำให้กระบวนการสำรวจเว็บเป็นไปโดยอัตโนมัติเพื่อรวบรวมข้อมูล ซึ่งสามารถนำไปใช้เพื่อวัตถุประสงค์ต่างๆ เช่น การทำดัชนีเครื่องมือค้นหา การทำเหมืองข้อมูล หรือการวิเคราะห์การแข่งขัน ในบทช่วยสอนนี้ เราจะเริ่มต้นการเดินทางที่ให้ข้อมูลเพื่อสร้างโปรแกรมรวบรวมข้อมูลเว็บพื้นฐานโดยใช้ Python ซึ่งเป็นภาษาที่ขึ้นชื่อเรื่องความเรียบง่ายและความสามารถอันทรงพลังในการจัดการข้อมูลเว็บ
Python ซึ่งมีระบบนิเวศของไลบรารีที่หลากหลาย มอบแพลตฟอร์มที่ยอดเยี่ยมสำหรับการพัฒนาโปรแกรมรวบรวมข้อมูลเว็บ ไม่ว่าคุณจะเป็นนักพัฒนาหน้าใหม่ ผู้สนใจข้อมูล หรือเพียงแค่อยากรู้ว่าโปรแกรมรวบรวมข้อมูลเว็บทำงานอย่างไร คำแนะนำทีละขั้นตอนนี้ออกแบบมาเพื่อแนะนำให้คุณรู้จักกับพื้นฐานของการรวบรวมข้อมูลเว็บ และเสริมทักษะในการสร้างโปรแกรมรวบรวมข้อมูลของคุณเอง .
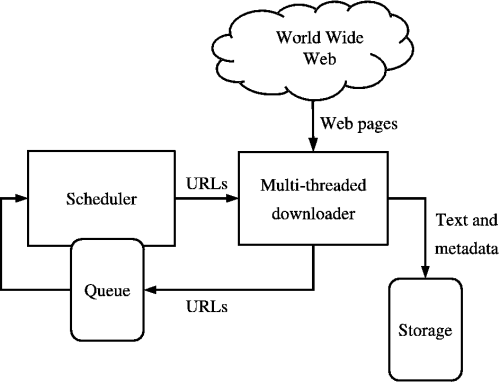
ที่มา: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler – วิธีสร้าง Web Crawler
ขั้นตอนที่ 1: ทำความเข้าใจพื้นฐาน
โปรแกรมรวบรวมข้อมูลเว็บหรือที่เรียกว่าสไปเดอร์เป็นโปรแกรมที่เรียกดูเวิลด์ไวด์เว็บในลักษณะที่เป็นระบบและเป็นอัตโนมัติ สำหรับโปรแกรมรวบรวมข้อมูลของเรา เราจะใช้ Python เนื่องจากความเรียบง่ายและไลบรารีที่มีประสิทธิภาพ
ขั้นตอนที่ 2: ตั้งค่าสภาพแวดล้อมของคุณ
ติดตั้ง Python : ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Python แล้ว คุณสามารถดาวน์โหลดได้จาก python.org
ติดตั้งไลบรารี : คุณจะต้องร้องขอสำหรับการร้องขอ HTTP และ BeautifulSoup จาก bs4 เพื่อแยกวิเคราะห์ HTML ติดตั้งโดยใช้ pip:
คำขอติดตั้ง pip pip ติดตั้ง beautifulsoup4
ขั้นตอนที่ 3: เขียนโปรแกรมรวบรวมข้อมูลพื้นฐาน
นำเข้าไลบรารี :
คำขอนำเข้าจาก bs4 นำเข้า BeautifulSoup
ดึงข้อมูลหน้าเว็บ :
ที่นี่เราจะดึงเนื้อหาของหน้าเว็บ แทนที่ 'URL' ด้วยหน้าเว็บที่คุณต้องการรวบรวมข้อมูล
url = 'URL' การตอบสนอง = request.get (url) content = response.content
แยกวิเคราะห์เนื้อหา HTML :
ซุป = BeautifulSoup (เนื้อหา 'html.parser')
ดึงข้อมูล :
ตัวอย่างเช่น หากต้องการแยกไฮเปอร์ลิงก์ทั้งหมด คุณสามารถทำได้:
สำหรับลิงก์ในซุป.find_all('a'): print(link.get('href'))
ขั้นตอนที่ 4: ขยายโปรแกรมรวบรวมข้อมูลของคุณ
การจัดการ URL ที่เกี่ยวข้อง :
ใช้ urljoin เพื่อจัดการ URL ที่เกี่ยวข้อง
จาก urllib.parse นำเข้า urljoin
หลีกเลี่ยงการรวบรวมข้อมูลหน้าเดียวกันสองครั้ง :
รักษาชุด URL ที่เยี่ยมชมเพื่อหลีกเลี่ยงความซ้ำซ้อน
เพิ่มความล่าช้า :
การรวบรวมข้อมูลด้วยความเคารพรวมถึงความล่าช้าระหว่างคำขอต่างๆ ใช้ time.sleep()
ขั้นตอนที่ 5: เคารพ Robots.txt
ตรวจสอบให้แน่ใจว่าโปรแกรมรวบรวมข้อมูลของคุณเคารพไฟล์ robots.txt ของเว็บไซต์ ซึ่งระบุว่าส่วนใดของเว็บไซต์ที่ไม่ควรถูกรวบรวมข้อมูล
ขั้นตอนที่ 6: การจัดการข้อผิดพลาด
ใช้บล็อกลองยกเว้นเพื่อจัดการกับข้อผิดพลาดที่อาจเกิดขึ้น เช่น การหมดเวลาการเชื่อมต่อหรือการเข้าถึงที่ถูกปฏิเสธ
ขั้นตอนที่ 7: เจาะลึกยิ่งขึ้น
คุณสามารถเพิ่มประสิทธิภาพให้โปรแกรมรวบรวมข้อมูลของคุณจัดการงานที่ซับซ้อนมากขึ้นได้ เช่น การส่งแบบฟอร์มหรือการแสดงผล JavaScript สำหรับเว็บไซต์ที่มี JavaScript หนาแน่น ให้พิจารณาใช้ Selenium
ขั้นตอนที่ 8: จัดเก็บข้อมูล
ตัดสินใจว่าจะจัดเก็บข้อมูลที่คุณรวบรวมข้อมูลอย่างไร ตัวเลือกต่างๆ ได้แก่ ไฟล์ธรรมดา ฐานข้อมูล หรือแม้แต่การส่งข้อมูลไปยังเซิร์ฟเวอร์โดยตรง
ขั้นตอนที่ 9: มีจริยธรรม
- อย่าโอเวอร์โหลดเซิร์ฟเวอร์ เพิ่มความล่าช้าในคำขอของคุณ
- ปฏิบัติตามข้อกำหนดในการให้บริการของเว็บไซต์
- ห้ามขูดหรือจัดเก็บข้อมูลส่วนบุคคลโดยไม่ได้รับอนุญาต
การถูกบล็อกถือเป็นความท้าทายที่พบบ่อยเมื่อรวบรวมข้อมูลเว็บ โดยเฉพาะอย่างยิ่งเมื่อต้องรับมือกับเว็บไซต์ที่มีมาตรการตรวจจับและบล็อกการเข้าถึงอัตโนมัติ ต่อไปนี้เป็นกลยุทธ์และข้อควรพิจารณาบางส่วนเพื่อช่วยคุณแก้ไขปัญหานี้ใน Python:
ทำความเข้าใจว่าทำไมคุณถึงถูกบล็อก
คำขอที่พบบ่อย: คำขอที่รวดเร็วและซ้ำกันจาก IP เดียวกันสามารถทำให้เกิดการบล็อกได้
รูปแบบที่ไม่ใช่มนุษย์: บอทมักแสดงพฤติกรรมที่แตกต่างจากรูปแบบการเรียกดูของมนุษย์ เช่น การเข้าถึงหน้าเว็บเร็วเกินไปหรืออยู่ในลำดับที่คาดเดาได้
การจัดการส่วนหัวที่ไม่ถูกต้อง: ส่วนหัว HTTP ที่ขาดหายไปหรือไม่ถูกต้องอาจทำให้คำขอของคุณดูน่าสงสัย
การเพิกเฉยต่อ robots.txt: การไม่ปฏิบัติตามคำสั่งในไฟล์ robots.txt ของไซต์อาจทำให้เกิดการบล็อกได้
กลยุทธ์เพื่อหลีกเลี่ยงการถูกบล็อก
เคารพ robots.txt : ตรวจสอบและปฏิบัติตามไฟล์ robots.txt ของเว็บไซต์เสมอ ถือเป็นหลักปฏิบัติด้านจริยธรรมและสามารถป้องกันการบล็อกโดยไม่จำเป็นได้
ตัวแทนผู้ใช้แบบหมุนเวียน : เว็บไซต์สามารถระบุตัวคุณผ่านตัวแทนผู้ใช้ของคุณ ด้วยการหมุนเวียน คุณจะลดความเสี่ยงที่จะถูกตั้งค่าสถานะเป็นบอท ใช้ไลบรารี fake_useragent เพื่อใช้งานสิ่งนี้

จาก fake_useragent นำเข้า UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}
การเพิ่มความล่าช้า : การใช้ความล่าช้าระหว่างคำขอสามารถเลียนแบบพฤติกรรมของมนุษย์ได้ ใช้ time.sleep() เพื่อเพิ่มความล่าช้าแบบสุ่มหรือคงที่
เวลานำเข้า time.sleep(3) # รอ 3 วินาที
การหมุนเวียน IP : หากเป็นไปได้ ให้ใช้บริการพร็อกซีเพื่อหมุนเวียนที่อยู่ IP ของคุณ มีบริการทั้งแบบฟรีและชำระเงินสำหรับสิ่งนี้
การใช้เซสชัน : ออบเจ็กต์คำขอเซสชันใน Python สามารถช่วยรักษาการเชื่อมต่อที่สอดคล้องกันและแชร์ส่วนหัว คุกกี้ ฯลฯ ข้ามคำขอ ทำให้โปรแกรมรวบรวมข้อมูลของคุณดูเหมือนเซสชันเบราว์เซอร์ทั่วไปมากขึ้น
ด้วยการร้องขอเซสชัน () เป็นเซสชัน: session.headers = {'User-Agent': ua.random} การตอบสนอง = session.get (url)
การจัดการ JavaScript : บางเว็บไซต์ใช้ JavaScript อย่างมากในการโหลดเนื้อหา เครื่องมืออย่าง Selenium หรือ Puppeteer สามารถเลียนแบบเบราว์เซอร์จริงได้ รวมถึงการเรนเดอร์ JavaScript
การจัดการข้อผิดพลาด : ใช้การจัดการข้อผิดพลาดที่มีประสิทธิภาพเพื่อจัดการและตอบสนองต่อการบล็อกหรือปัญหาอื่น ๆ อย่างสวยงาม
ข้อพิจารณาทางจริยธรรม
- เคารพข้อกำหนดในการให้บริการของเว็บไซต์เสมอ หากเว็บไซต์ห้ามการคัดลอกเว็บอย่างชัดเจน วิธีที่ดีที่สุดคือปฏิบัติตาม
- โปรดคำนึงถึงผลกระทบที่โปรแกรมรวบรวมข้อมูลของคุณมีต่อทรัพยากรของเว็บไซต์ การโอเวอร์โหลดเซิร์ฟเวอร์อาจทำให้เกิดปัญหากับเจ้าของไซต์ได้
เทคนิคขั้นสูง
- Web Scraping Frameworks : พิจารณาใช้เฟรมเวิร์ก เช่น Scrapy ซึ่งมีคุณสมบัติในตัวเพื่อจัดการกับปัญหาการรวบรวมข้อมูลต่างๆ
- บริการแก้ไข CAPTCHA : สำหรับไซต์ที่มีปัญหาเกี่ยวกับ CAPTCHA มีบริการต่างๆ ที่สามารถแก้ไข CAPTCHA ได้ แม้ว่าการใช้งานจะทำให้เกิดข้อกังวลด้านจริยธรรมก็ตาม
แนวทางปฏิบัติที่ดีที่สุดในการรวบรวมข้อมูลเว็บใน Python
การมีส่วนร่วมในกิจกรรมการรวบรวมข้อมูลเว็บต้องมีความสมดุลระหว่างประสิทธิภาพทางเทคนิคและความรับผิดชอบทางจริยธรรม เมื่อใช้ Python สำหรับการรวบรวมข้อมูลเว็บ สิ่งสำคัญคือต้องปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดโดยคำนึงถึงข้อมูลและเว็บไซต์ที่เป็นแหล่งที่มาของข้อมูล ข้อควรพิจารณาที่สำคัญและแนวปฏิบัติที่ดีที่สุดสำหรับการรวบรวมข้อมูลเว็บใน Python มีดังนี้
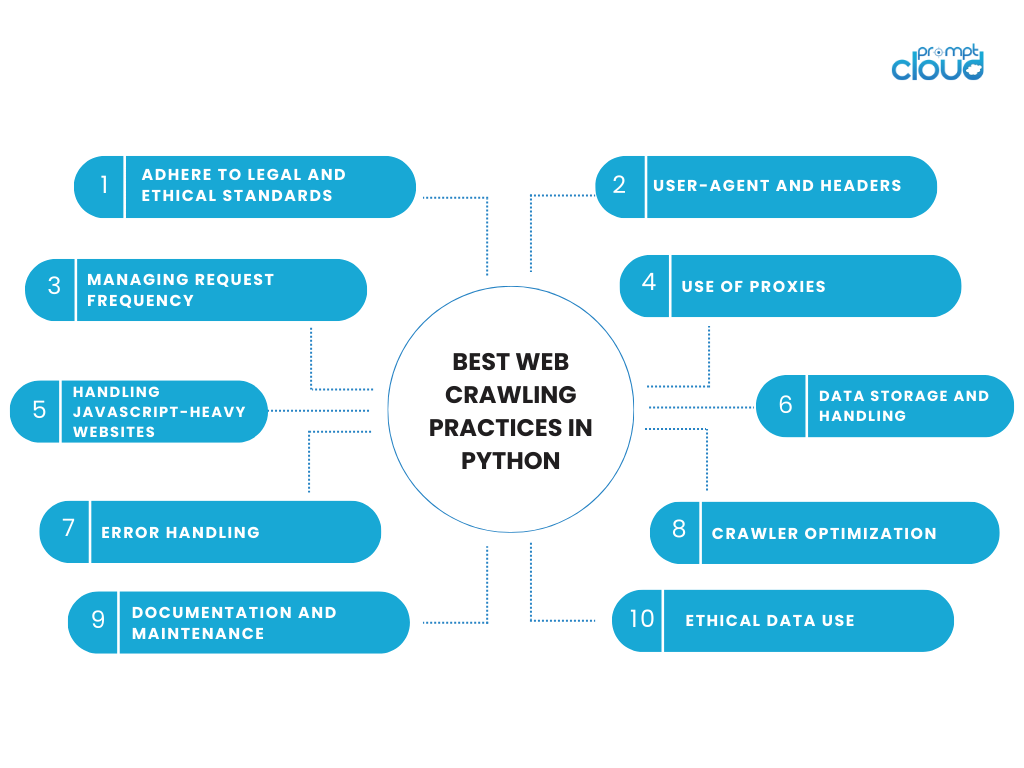
ปฏิบัติตามมาตรฐานทางกฎหมายและจริยธรรม
- เคารพ robots.txt: ตรวจสอบไฟล์ robots.txt ของเว็บไซต์เสมอ ไฟล์นี้สรุปพื้นที่ของไซต์ที่เจ้าของเว็บไซต์ไม่ต้องการให้รวบรวมข้อมูล
- ปฏิบัติตามข้อกำหนดในการให้บริการ: เว็บไซต์หลายแห่งมีข้อกำหนดเกี่ยวกับการขูดเว็บไว้ในข้อกำหนดในการให้บริการ การปฏิบัติตามข้อกำหนดเหล่านี้ถือเป็นการปฏิบัติตามหลักจริยธรรมและรอบคอบตามกฎหมาย
- หลีกเลี่ยงการโอเวอร์โหลดเซิร์ฟเวอร์: ส่งคำขอด้วยความเร็วที่เหมาะสมเพื่อหลีกเลี่ยงการโหลดมากเกินไปบนเซิร์ฟเวอร์ของเว็บไซต์
ตัวแทนผู้ใช้และส่วนหัว
- ระบุตัวตน: ใช้สตริงตัวแทนผู้ใช้ที่มีข้อมูลติดต่อของคุณหรือวัตถุประสงค์ของการรวบรวมข้อมูล ความโปร่งใสนี้สามารถสร้างความไว้วางใจได้
- ใช้ส่วนหัวอย่างเหมาะสม: ส่วนหัว HTTP ที่กำหนดค่าไว้อย่างดีสามารถลดโอกาสที่จะถูกบล็อกได้ พวกเขาสามารถรวมข้อมูลเช่น user-agent, ยอมรับภาษา ฯลฯ
การจัดการความถี่คำขอ
- เพิ่มความล่าช้า: ใช้ความล่าช้าระหว่างคำขอเพื่อเลียนแบบรูปแบบการเรียกดูของมนุษย์ ใช้ฟังก์ชัน time.sleep() ของ Python
- การจำกัดอัตรา: ระวังจำนวนคำขอที่คุณส่งไปยังเว็บไซต์ภายในกรอบเวลาที่กำหนด
การใช้ผู้รับมอบฉันทะ
- การหมุนเวียน IP: การใช้พรอกซีเพื่อหมุนเวียนที่อยู่ IP ของคุณสามารถช่วยหลีกเลี่ยงการบล็อกตาม IP ได้ แต่ควรทำด้วยความรับผิดชอบและมีจริยธรรม
การจัดการเว็บไซต์ที่มี JavaScript จำนวนมาก
- เนื้อหาแบบไดนามิก: สำหรับไซต์ที่โหลดเนื้อหาแบบไดนามิกด้วย JavaScript เครื่องมือเช่น Selenium หรือ Puppeteer (ร่วมกับ Pyppeteer สำหรับ Python) สามารถแสดงผลหน้าเว็บได้เหมือนกับเบราว์เซอร์
การจัดเก็บและการจัดการข้อมูล
- การจัดเก็บข้อมูล: จัดเก็บข้อมูลที่รวบรวมข้อมูลอย่างมีความรับผิดชอบ โดยคำนึงถึงกฎหมายและข้อบังคับด้านความเป็นส่วนตัวของข้อมูล
- ย่อขนาดการดึงข้อมูล: ดึงเฉพาะข้อมูลที่คุณต้องการเท่านั้น หลีกเลี่ยงการเก็บรวบรวมข้อมูลส่วนบุคคลหรือข้อมูลที่ละเอียดอ่อน เว้นแต่จะมีความจำเป็นอย่างยิ่งและถูกกฎหมาย
การจัดการข้อผิดพลาด
- การจัดการข้อผิดพลาดที่มีประสิทธิภาพ: ใช้การจัดการข้อผิดพลาดที่ครอบคลุมเพื่อจัดการปัญหาต่างๆ เช่น การหมดเวลา ข้อผิดพลาดของเซิร์ฟเวอร์ หรือเนื้อหาที่ไม่สามารถโหลดได้
การเพิ่มประสิทธิภาพโปรแกรมรวบรวมข้อมูล
- ความสามารถในการปรับขนาด: ออกแบบโปรแกรมรวบรวมข้อมูลของคุณเพื่อรองรับขนาดที่เพิ่มขึ้น ทั้งในแง่ของจำนวนหน้าที่รวบรวมข้อมูลและจำนวนข้อมูลที่ประมวลผล
- ประสิทธิภาพ: เพิ่มประสิทธิภาพโค้ดของคุณเพื่อประสิทธิภาพ โค้ดที่มีประสิทธิภาพจะช่วยลดภาระทั้งในระบบและเซิร์ฟเวอร์เป้าหมาย
เอกสารและการบำรุงรักษา
- เก็บเอกสารประกอบ: บันทึกรหัสและตรรกะการรวบรวมข้อมูลของคุณเพื่อใช้อ้างอิงและบำรุงรักษาในอนาคต
- การอัปเดตเป็นประจำ: อัปเดตโค้ดการรวบรวมข้อมูลของคุณอยู่เสมอ โดยเฉพาะอย่างยิ่งหากโครงสร้างของเว็บไซต์เป้าหมายเปลี่ยนแปลง
การใช้ข้อมูลอย่างมีจริยธรรม
- การใช้อย่างมีจริยธรรม: ใช้ข้อมูลที่คุณรวบรวมไว้อย่างมีจริยธรรม โดยเคารพความเป็นส่วนตัวของผู้ใช้และบรรทัดฐานการใช้ข้อมูล
สรุปแล้ว
ในการสรุปการสำรวจการสร้างโปรแกรมรวบรวมข้อมูลเว็บใน Python เราได้เดินทางผ่านความซับซ้อนของการรวบรวมข้อมูลอัตโนมัติและข้อพิจารณาด้านจริยธรรมที่มาพร้อมกับข้อมูลดังกล่าว ความพยายามนี้ไม่เพียงแต่ช่วยเพิ่มทักษะทางเทคนิคของเราเท่านั้น แต่ยังทำให้เรามีความเข้าใจลึกซึ้งยิ่งขึ้นเกี่ยวกับการจัดการข้อมูลที่มีความรับผิดชอบในภูมิทัศน์ดิจิทัลอันกว้างใหญ่อีกด้วย
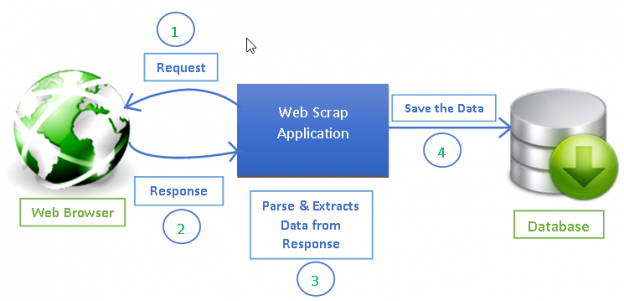
ที่มา: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
อย่างไรก็ตาม การสร้างและดูแลรักษาโปรแกรมรวบรวมข้อมูลเว็บอาจเป็นงานที่ซับซ้อนและใช้เวลานาน โดยเฉพาะอย่างยิ่งสำหรับธุรกิจที่มีความต้องการข้อมูลขนาดใหญ่โดยเฉพาะ นี่คือจุดที่บริการขูดเว็บแบบกำหนดเองของ PromptCloud เข้ามามีบทบาท หากคุณกำลังมองหาโซลูชันที่ปรับแต่ง มีประสิทธิภาพ และมีจริยธรรมสำหรับความต้องการข้อมูลเว็บของคุณ PromptCloud เสนอบริการที่หลากหลายเพื่อให้เหมาะกับความต้องการเฉพาะของคุณ ตั้งแต่การจัดการเว็บไซต์ที่ซับซ้อนไปจนถึงการจัดหาข้อมูลที่สะอาดและมีโครงสร้าง พวกเขารับประกันว่าโครงการขูดเว็บของคุณจะไม่ยุ่งยากและสอดคล้องกับวัตถุประสงค์ทางธุรกิจของคุณ
สำหรับธุรกิจและบุคคลที่อาจไม่มีเวลาหรือความเชี่ยวชาญทางเทคนิคในการพัฒนาและจัดการโปรแกรมรวบรวมข้อมูลเว็บของตนเอง การจ้างผู้เชี่ยวชาญอย่าง PromptCloud งานนี้อาจเป็นตัวเปลี่ยนเกมได้ บริการของพวกเขาไม่เพียงแต่ประหยัดเวลาและทรัพยากรเท่านั้น แต่ยังรับประกันว่าคุณจะได้รับข้อมูลที่แม่นยำและเกี่ยวข้องที่สุด ทั้งหมดนี้ในขณะเดียวกันก็ปฏิบัติตามมาตรฐานทางกฎหมายและจริยธรรม
สนใจที่จะเรียนรู้เพิ่มเติมว่า PromptCloud สามารถตอบสนองความต้องการข้อมูลเฉพาะของคุณได้อย่างไร ติดต่อพวกเขาที่ sales@promptcloud.com เพื่อขอข้อมูลเพิ่มเติมและหารือว่าโซลูชันการขูดเว็บแบบกำหนดเองสามารถช่วยขับเคลื่อนธุรกิจของคุณไปข้างหน้าได้อย่างไร
ในโลกของข้อมูลเว็บที่มีการเปลี่ยนแปลงตลอดเวลา การมีพันธมิตรที่เชื่อถือได้เช่น PromptCloud สามารถเสริมศักยภาพธุรกิจของคุณได้ ทำให้คุณมีความได้เปรียบในการตัดสินใจโดยอาศัยข้อมูล โปรดจำไว้ว่าในขอบเขตของการรวบรวมและการวิเคราะห์ข้อมูล พันธมิตรที่เหมาะสมจะสร้างความแตกต่างทั้งหมด
มีความสุขในการตามล่าข้อมูล!