
การเลือกและการกำหนดค่ากลไกการอนุมานสำหรับ LLM
เผยแพร่แล้ว: 2024-04-02รู้เบื้องต้นเกี่ยวกับกลไกการอนุมาน
มีเทคนิคการปรับให้เหมาะสมหลายอย่างที่พัฒนาขึ้นเพื่อลดความไร้ประสิทธิภาพที่เกิดขึ้นในขั้นตอนต่างๆ ของกระบวนการอนุมาน เป็นการยากที่จะปรับขนาดการอนุมานตามขนาดด้วยหม้อแปลง/เทคนิควานิลลา กลไกการอนุมานรวมการปรับให้เหมาะสมไว้ในแพ็คเกจเดียวและช่วยให้เราง่ายขึ้นในกระบวนการอนุมาน
สำหรับการทดสอบเฉพาะกิจชุดเล็กๆ หรือการอ้างอิงอย่างรวดเร็ว เราสามารถใช้โค้ด vanilla Transformer เพื่อทำการอนุมานได้
ภาพรวมของกลไกการอนุมานมีการพัฒนาอย่างรวดเร็ว เนื่องจากเรามีทางเลือกหลายทาง การทดสอบและคัดแยกสิ่งที่ดีที่สุดสำหรับกรณีการใช้งานเฉพาะจึงเป็นเรื่องสำคัญ ด้านล่างนี้คือการทดลองกลไกอนุมานบางส่วนที่เราทำ และเหตุผลที่เราพบว่าเหตุใดจึงได้ผลในกรณีของเรา
สำหรับรุ่น Vicuna-7B ที่ได้รับการปรับแต่ง เราได้ลองแล้ว
- ทีจีไอ
- วีแอลแอลเอ็ม
- อะโฟรไดท์
- Optimum-Nvidia
- เพาเวอร์อินเฟอร์
- ลามะซีพีพี
- Ctranslate2
เราได้อ่านหน้า GitHub และคู่มือเริ่มต้นใช้งานอย่างย่อเพื่อตั้งค่าเอนจิ้นเหล่านี้ PowerInfer, LlaamaCPP, Ctranslate2 นั้นไม่ยืดหยุ่นมากนักและไม่รองรับเทคนิคการปรับให้เหมาะสมหลายอย่าง เช่น การแบตช์อย่างต่อเนื่อง ความสนใจแบบเพจ และประสิทธิภาพต่ำกว่ามาตรฐานเมื่อเปรียบเทียบกับเอ็นจิ้นอื่นๆ ที่กล่าวถึง .
เพื่อให้ได้ปริมาณงานที่สูงขึ้น กลไกการอนุมาน/เซิร์ฟเวอร์ควรเพิ่มหน่วยความจำและความสามารถในการคำนวณให้สูงสุด และทั้งไคลเอนต์และเซิร์ฟเวอร์จะต้องทำงานในลักษณะขนาน/อะซิงโครนัสในการให้บริการคำขอ เพื่อให้เซิร์ฟเวอร์ทำงานอยู่เสมอ ตามที่กล่าวไว้ข้างต้น หากไม่ได้รับความช่วยเหลือจากเทคนิคการปรับให้เหมาะสม เช่น PagedAttention, Flash Attention, การแบทช์แบบต่อเนื่อง ก็จะนำไปสู่ประสิทธิภาพการทำงานที่ต่ำกว่าปกติเสมอ
TGI, vLLM และ Aphrodite เป็นตัวเลือกที่เหมาะสมกว่าในเรื่องนี้ และจากการทดลองหลายครั้งตามที่ระบุไว้ด้านล่าง เราพบการกำหนดค่าที่เหมาะสมที่สุดเพื่อบีบประสิทธิภาพสูงสุดออกจากการอนุมาน เทคนิคต่างๆ เช่น การแบทช์ต่อเนื่องและความสนใจแบบเพจจะเปิดใช้งานตามค่าเริ่มต้น การถอดรหัสแบบเก็งกำไรจำเป็นต้องเปิดใช้งานด้วยตนเองในกลไกการอนุมานสำหรับการทดสอบด้านล่าง
การวิเคราะห์เปรียบเทียบกลไกการอนุมาน
ทีจีไอ
หากต้องการใช้ TGI เราสามารถไปที่ส่วน "เริ่มต้น" ของหน้า GitHub ซึ่งนักเทียบท่าคือวิธีที่ง่ายที่สุดในการกำหนดค่าและใช้งานกลไก TGI
อาร์กิวเมนต์การสร้างข้อความ -> รายการการตั้งค่าต่าง ๆ ที่เราสามารถใช้ได้บนฝั่งเซิร์ฟเวอร์ ที่สำคัญไม่กี่อย่าง
- –max-input-length : กำหนดความยาวสูงสุดของอินพุตให้กับโมเดล ซึ่งจำเป็นต้องเปลี่ยนแปลงในกรณีส่วนใหญ่ เนื่องจากค่าเริ่มต้นคือ 1024
- –โทเค็นรวมสูงสุด: สูงสุด โทเค็นทั้งหมด เช่น ความยาวโทเค็นอินพุต + เอาต์พุต
- –speculate, –quantiz, –max-concurrent-requests -> default คือ 128 เท่านั้น ซึ่งน้อยกว่าอย่างเห็นได้ชัด
ในการเริ่มต้นโมเดลที่ได้รับการปรับแต่งในท้องถิ่น
นักเทียบท่ารัน –อุปกรณ์ gpus=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –ความยาวอินพุตสูงสุด 3600 –tokens รวมสูงสุด 4000 –คาดเดา 2
ในการเริ่มต้นโมเดลจากฮับ
รุ่น =”lmsys/vicuna-7b-v1.5″; ปริมาณ=$PWD/ข้อมูล; โทเค็น =”<hf_token>”; นักเทียบท่าวิ่ง –gpus ทั้งหมด –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –ความยาวอินพุตสูงสุด 3600 –tokens รวมสูงสุด 4000 –คาดเดา 2
คุณสามารถขอให้ chatGPT อธิบายคำสั่งข้างต้นเพื่อความเข้าใจที่ละเอียดยิ่งขึ้น ที่นี่เรากำลังเริ่มต้นเซิร์ฟเวอร์อนุมานที่พอร์ต 9091 และเราสามารถใช้ไคลเอนต์ภาษาใดก็ได้เพื่อโพสต์คำขอไปยังเซิร์ฟเวอร์ API การอนุมานการสร้างข้อความ -> กล่าวถึงจุดสิ้นสุดและพารามิเตอร์เพย์โหลดทั้งหมดสำหรับการร้องขอ
เช่น
payload=”<พร้อมท์ที่นี่>”
curl -XPOST “0.0.0.0:9091/สร้าง” -H “ประเภทเนื้อหา: แอปพลิเคชัน/json” -d “{“อินพุต”: $payload, “พารามิเตอร์”: {“max_new_tokens”: 400,”do_sample”:false ”best_of”: null”repetition_penalty”: 1”return_full_text”: false”seed”: null”stop_sequences”: null”อุณหภูมิ”: 0.1”top_k”: 100”top_p”: 0.3” ตัด”: null”typical_p”: null”ลายน้ำ”: false”decoder_input_details”: false}}”
ข้อสังเกตบางประการ
- เวลาแฝงจะเพิ่มขึ้นด้วยโทเค็นสูงสุด ซึ่งเห็นได้ชัดว่าหากเราประมวลผลข้อความยาว เวลาโดยรวมก็จะเพิ่มขึ้น
- การเก็งกำไรช่วยได้ แต่ขึ้นอยู่กับกรณีการใช้งานและการกระจายอินพุต-เอาท์พุต
- การหาปริมาณ Eetq ช่วยเพิ่มปริมาณงานได้มากที่สุด
- หากคุณมี GPU หลายตัว การเรียกใช้ 1 API บน GPU แต่ละตัวและการมี GPU API หลายตัวเหล่านี้อยู่เบื้องหลังโหลดบาลานเซอร์ส่งผลให้มีทรูพุตที่สูงกว่าการแบ่งส่วนโดย TGI เอง
วีแอลแอลเอ็ม
ในการเริ่มต้นเซิร์ฟเวอร์ vLLM เราสามารถใช้เซิร์ฟเวอร์/นักเทียบท่า REST API ที่เข้ากันได้กับ OpenAI มันง่ายมากในการเริ่มต้น ทำตาม Deploying with Docker — vLLM หากคุณกำลังจะใช้โมเดลในเครื่อง ให้แนบวอลุ่มและใช้พาธเป็นชื่อโมเดล
นักเทียบท่าทำงาน –รันไทม์ nvidia –อุปกรณ์ gpus=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – รุ่น/รุ่น
ข้างต้นจะเริ่มต้นเซิร์ฟเวอร์ vLLM บนพอร์ต 8000 ที่กล่าวถึง เช่นเดียวกับที่คุณสามารถเล่นกับอาร์กิวเมนต์ได้
ส่งคำขอโพสต์ด้วย
“`เปลือก
payload=”<พร้อมท์ที่นี่>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “ประเภทเนื้อหา: application/json” -d “{“prompt”: $payload”model”:”/model” ”max_tokens ”: 400”top_p”: 0.3, “top_k”: 100, “อุณหภูมิ”: 0.1}”
-
อะโฟรไดท์
“`เปลือก
pip ติดตั้ง aphrodite-engine
หลาม -m aphrodite.endpoints.openai.api_server – รุ่น PygmalionAI/pygmalion-2-7b

-
หรือ
-
นักเทียบท่าวิ่ง -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc โฮสต์ alpindale/aphrodite-engine
-
Aphrodite มีทั้งการติดตั้ง pip และ docker ตามที่กล่าวไว้ในส่วนการเริ่มต้นใช้งาน โดยทั่วไปนักเทียบท่าจะหมุนและทดสอบได้ง่ายกว่า ตัวเลือกการใช้งาน ตัวเลือกเซิร์ฟเวอร์ช่วยเราในการส่งคำขอ
- Aphrodite และ vLLM ใช้เพย์โหลดบนเซิร์ฟเวอร์ openAI ดังนั้นคุณจึงตรวจสอบเอกสารประกอบได้
- เราลองใช้ deepspeed-mii เนื่องจากมันอยู่ในสถานะเปลี่ยนผ่าน (เมื่อเราลอง) จากแบบเดิมไปจนถึงโค้ดเบสใหม่ จึงดูไม่น่าเชื่อถือและใช้งานง่าย
- Optimum-NVIDIA ไม่สนับสนุนการเพิ่มประสิทธิภาพอื่นๆ ที่สำคัญและผลลัพธ์ในประสิทธิภาพที่ต่ำกว่ามาตรฐาน ลิงก์อ้างอิง
- เพิ่มส่วนสำคัญ ซึ่งเป็นโค้ดที่เราใช้ในการทำคำขอแบบขนานเฉพาะกิจ
ตัวชี้วัดและการวัด
เราต้องการลองและค้นหา:
- หมายเลขที่เหมาะสมที่สุด ของเธรดสำหรับไคลเอ็นต์/เซิร์ฟเวอร์กลไกการอนุมาน
- ปริมาณงานเพิ่มขึ้นอย่างไรในหน่วยความจำเพิ่มขึ้น
- ปริมาณงานเพิ่มขึ้นอย่างไรกับเทนเซอร์คอร์
- ผลกระทบของเธรดกับการร้องขอแบบขนานโดยไคลเอ็นต์
วิธีพื้นฐานในการสังเกตการใช้งานคือการดูผ่าน linux utils nvidia-smi, nvtop ซึ่งจะบอกเราเกี่ยวกับหน่วยความจำที่ใช้งาน การใช้งานการประมวลผล อัตราการถ่ายโอนข้อมูล ฯลฯ
อีกวิธีหนึ่งคือการจัดทำโปรไฟล์กระบวนการโดยใช้ GPU กับ nsys
| ส.โน | จีพียู | หน่วยความจำวีแรม | เครื่องมืออนุมาน | กระทู้ | เวลา | เก็งกำไร |
| 1 | A6000 | 48/48GB | ทีจีไอ | 24 | 664 | - |
| 2 | A6000 | 48/48GB | ทีจีไอ | 64 | 561 | - |
| 3 | A6000 | 48/48GB | ทีจีไอ | 128 | 554 | - |
| 4 | A6000 | 48/48GB | ทีจีไอ | 256 | 568 | - |
จากการทดลองข้างต้น พบว่า 128/ 256 เธรดดีกว่าจำนวนเธรดที่ต่ำกว่า และโอเวอร์เฮดที่เกิน 256 เริ่มมีส่วนทำให้ปริมาณงานลดลง พบว่าขึ้นอยู่กับ CPU และ GPU และต้องมีการทดลองด้วยตนเอง | ||||||
| 5 | A6000 | 48/48GB | ทีจีไอ | 128 | 596 | 2 |
| 6 | A6000 | 48/48GB | ทีจีไอ | 128 | 945 | 8 |
ค่าเก็งกำไรที่สูงขึ้นทำให้เกิดการปฏิเสธมากขึ้นสำหรับโมเดลที่ได้รับการปรับแต่งของเรา และทำให้ปริมาณงานลดลง 1/2 เนื่องจากค่าเก็งกำไรเป็นเรื่องปกติ ซึ่งขึ้นอยู่กับรุ่นและไม่รับประกันว่าจะใช้งานได้เหมือนกันในทุกกรณีการใช้งาน แต่ข้อสรุปคือการถอดรหัสแบบเก็งกำไรช่วยเพิ่มปริมาณงาน | ||||||
| 7 | 3090 | 24/24GB | ทีจีไอ | 128 | 741 | 2 |
| 7 | 4090 | 24/24GB | ทีจีไอ | 128 | 481 | 2 |
4090 มี vRAM น้อยกว่าเมื่อเทียบกับ A6000 แต่ก็มีประสิทธิภาพเหนือกว่าเนื่องจากจำนวนเทนเซอร์คอร์ที่สูงกว่าและความเร็วแบนด์วิธหน่วยความจำ | ||||||
| 8 | A6000 | 24/48GB | ทีจีไอ | 128 | 707 | 2 |
| 9 | A6000 | 2x24/48GB | ทีจีไอ | 128 | 1205 | 2 |
การตั้งค่าและกำหนดค่า TGI สำหรับปริมาณงานสูง
ตั้งค่าการร้องขอแบบอะซิงโครนัสในภาษาสคริปต์ที่คุณเลือก เช่น python/ ruby และเราพบว่าเมื่อใช้ไฟล์เดียวกันในการกำหนดค่า:
- เวลาที่ใช้จะเพิ่มความยาวเอาต์พุตสูงสุดของการสร้างลำดับ
- 128/ 256 เธรดบนไคลเอนต์และเซิร์ฟเวอร์ดีกว่า 24, 64, 512 เมื่อใช้เธรดที่ต่ำกว่า การประมวลผลจะถูกใช้งานน้อยเกินไป และเกินเกณฑ์เช่น 128 โอเวอร์เฮดจะสูงขึ้น และทำให้ปริมาณงานลดลง
- มีการปรับปรุง 6% เมื่อกระโดดจากคำขอแบบอะซิงโครนัสไปเป็นคำขอแบบขนานโดยใช้ 'GNU แบบขนาน' แทนการใช้เธรดในภาษาเช่น Go, Python/ Ruby
- 4090 มีปริมาณงานสูงกว่า A6000 ถึง 12% 4090 มี vRAM น้อยกว่าเมื่อเทียบกับ A6000 แต่ก็มีประสิทธิภาพเหนือกว่าเนื่องจากจำนวนเทนเซอร์คอร์ที่สูงกว่าและความเร็วแบนด์วิธหน่วยความจำ
- เนื่องจาก A6000 มี vRAM ขนาด 48GB เพื่อสรุปว่า RAM พิเศษช่วยปรับปรุงปริมาณงานหรือไม่ เราจึงลองใช้หน่วยความจำ GPU เศษส่วนในการทดลองที่ 8 ของตาราง เราเห็นว่า RAM พิเศษช่วยในการปรับปรุงแต่ไม่ใช่เชิงเส้นตรง นอกจากนี้ เมื่อลองแยกเช่น โฮสต์ 2 API บน GPU เดียวกันโดยใช้หน่วยความจำครึ่งหนึ่งสำหรับแต่ละ API มันจะทำงานเหมือนกับ API ลำดับที่ 2 ที่ทำงานอยู่ แทนที่จะยอมรับคำขอแบบขนาน
การสังเกตและการวัด
ด้านล่างนี้เป็นกราฟสำหรับการทดลองบางอย่าง และเวลาที่ใช้ในการดำเนินการชุดอินพุตคงที่ให้เสร็จสิ้น ลดเวลาที่ใช้ลงจะดีกว่า
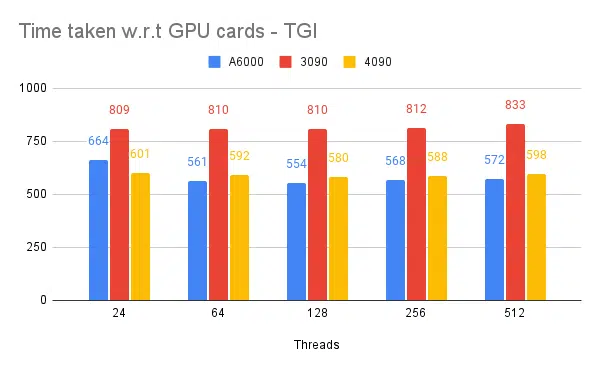
- กล่าวถึงคือเธรดฝั่งไคลเอ็นต์ ฝั่งเซิร์ฟเวอร์เราต้องพูดถึงในขณะที่สตาร์ทเอ็นจิ้นการอนุมาน
เก็งกำไรการทดสอบ:

การทดสอบเอ็นจิ้นการอนุมานหลายตัว:
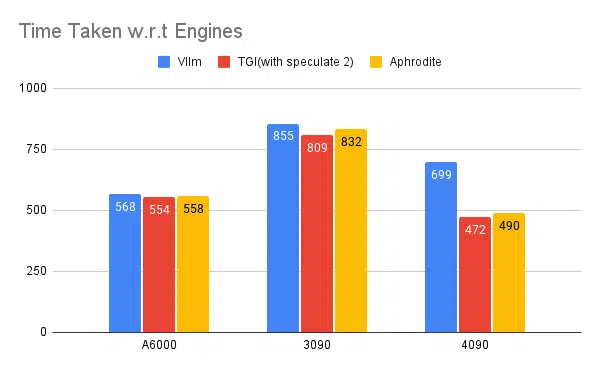
การทดลองประเภทเดียวกันกับที่ทำกับเอ็นจิ้นอื่นๆ เช่น vLLM และ Aphrodite เราสังเกตเห็นผลลัพธ์ที่คล้ายกัน ในขณะที่เขียนบทความนี้ vLLM และ Aphrodite ยังไม่รองรับการถอดรหัสแบบเก็งกำไร ทำให้เราเลือก TGI เนื่องจากให้ปริมาณงานที่สูงกว่าส่วนที่เหลือ เพื่อการถอดรหัสแบบเก็งกำไร
นอกจากนี้ คุณยังสามารถกำหนดค่าโปรไฟล์ GPU เพื่อเพิ่มความสามารถในการสังเกต ช่วยในการระบุพื้นที่ที่มีการใช้ทรัพยากรมากเกินไปและเพิ่มประสิทธิภาพการทำงาน อ่านเพิ่มเติม: เครื่องมือสำหรับนักพัฒนา Nvidia Nsight – Max Katz
บทสรุป
เราเห็นว่าภูมิทัศน์ของการสร้างการอนุมานมีการพัฒนาอย่างต่อเนื่อง และการปรับปรุงปริมาณงานใน LLM จำเป็นต้องมีความเข้าใจที่ดีเกี่ยวกับ GPU ตัวชี้วัดประสิทธิภาพ เทคนิคการปรับให้เหมาะสม และความท้าทายที่เกี่ยวข้องกับงานการสร้างข้อความ ซึ่งจะช่วยในการเลือกเครื่องมือที่เหมาะสมกับงาน ด้วยการทำความเข้าใจ GPU ภายในและวิธีที่พวกมันสอดคล้องกับการอนุมาน LLM เช่น การใช้ประโยชน์จากเทนเซอร์คอร์และการเพิ่มแบนด์วิธหน่วยความจำให้สูงสุด นักพัฒนาสามารถเลือก GPU ที่คุ้มต้นทุนและเพิ่มประสิทธิภาพการทำงานได้อย่างมีประสิทธิภาพ
การ์ด GPU ที่แตกต่างกันมีความสามารถที่แตกต่างกัน และการทำความเข้าใจความแตกต่างเป็นสิ่งสำคัญในการเลือกฮาร์ดแวร์ที่เหมาะสมที่สุดสำหรับงานเฉพาะ เทคนิคต่างๆ เช่น การแบทช์อย่างต่อเนื่อง เพจความสนใจ การรวมเคอร์เนล และความสนใจแบบแฟลช นำเสนอโซลูชันที่น่าหวังในการเอาชนะความท้าทายที่เกิดขึ้นและปรับปรุงประสิทธิภาพ TGI มองหาตัวเลือกที่ดีที่สุดสำหรับกรณีการใช้งานของเรา โดยพิจารณาจากการทดลองและผลลัพธ์ที่เราได้รับ
อ่านบทความอื่นๆ ที่เกี่ยวข้องกับโมเดลภาษาขนาดใหญ่:
ทำความเข้าใจสถาปัตยกรรม GPU สำหรับการเพิ่มประสิทธิภาพการอนุมาน LLM
เทคนิคขั้นสูงสำหรับการเพิ่มปริมาณงาน LLM