
การโหลดเก็งกำไรมีอยู่ใน WordPress
เผยแพร่แล้ว: 2024-04-18ในระหว่างการสัมมนาผ่านเว็บเรื่อง "การโหลดหน้าเว็บทันที" เมื่อต้นปี 2024 Adam Silverstein จาก Google กล่าวว่าทีมงาน WordPress Performance กำลังทำงานเกี่ยวกับปลั๊กอินที่จะเปิดใช้งาน Speculation Rules API:
ก้าวไปข้างหน้าอย่างรวดเร็วจนถึงเดือนเมษายน 2024 เมื่อ WordPress เปิดตัว Speculative Loading อย่างเป็นทางการ ซึ่งเป็นปลั๊กอินประสิทธิภาพที่รองรับ Speculation Rules API

แต่ก่อนที่เราจะพูดถึง ต่อไปนี้เป็นภาพรวมโดยย่อของ Speculation Rules API
อธิบาย API กฎการเก็งกำไรแล้ว
ย่อหน้าต่อไปนี้เป็นคำอธิบายโดยย่อของ Speculation Rules API ของ Google หากคุณต้องการเจาะลึกยิ่งขึ้น โปรดอ่านบทความเฉพาะของเรา
API กฎเก็งกำไรเป็นเทคโนโลยีทดลองที่พัฒนาโดย Google เพื่อปรับปรุงประสิทธิภาพการนำทางหน้าในอนาคต API ที่กำหนดโดย JSON นี้สร้างขึ้นจากคำแนะนำทรัพยากรที่มีอยู่อย่างกว้างขวาง link rel=prefetchและl ink rel=prerenderช่วยให้นักพัฒนาและเจ้าของไซต์มีวิธีที่ยืดหยุ่นและแสดงออกมากขึ้นในการระบุว่าเอกสารใดควรดึงข้อมูลล่วงหน้าหรือแสดงผลล่วงหน้า
คุณสามารถตั้งค่าประเภทการโหลดแบบเก็งกำไร (ดึงข้อมูลล่วงหน้าหรือแสดงผลล่วงหน้า) ภายในอินไลน์ได้อย่างง่ายดาย องค์ประกอบและไฟล์ข้อความภายนอกที่อ้างอิงโดยส่วนหัวการตอบสนองเก็งกำไรกฎ
คุณมีสองตัวเลือกในการเปิดใช้งาน Speculation Rules API:
- ใช้รูปแบบ URL: กำหนดว่า URL ใดมีสิทธิ์สำหรับการดึงข้อมูลล่วงหน้าหรือการแสดงผลล่วงหน้า
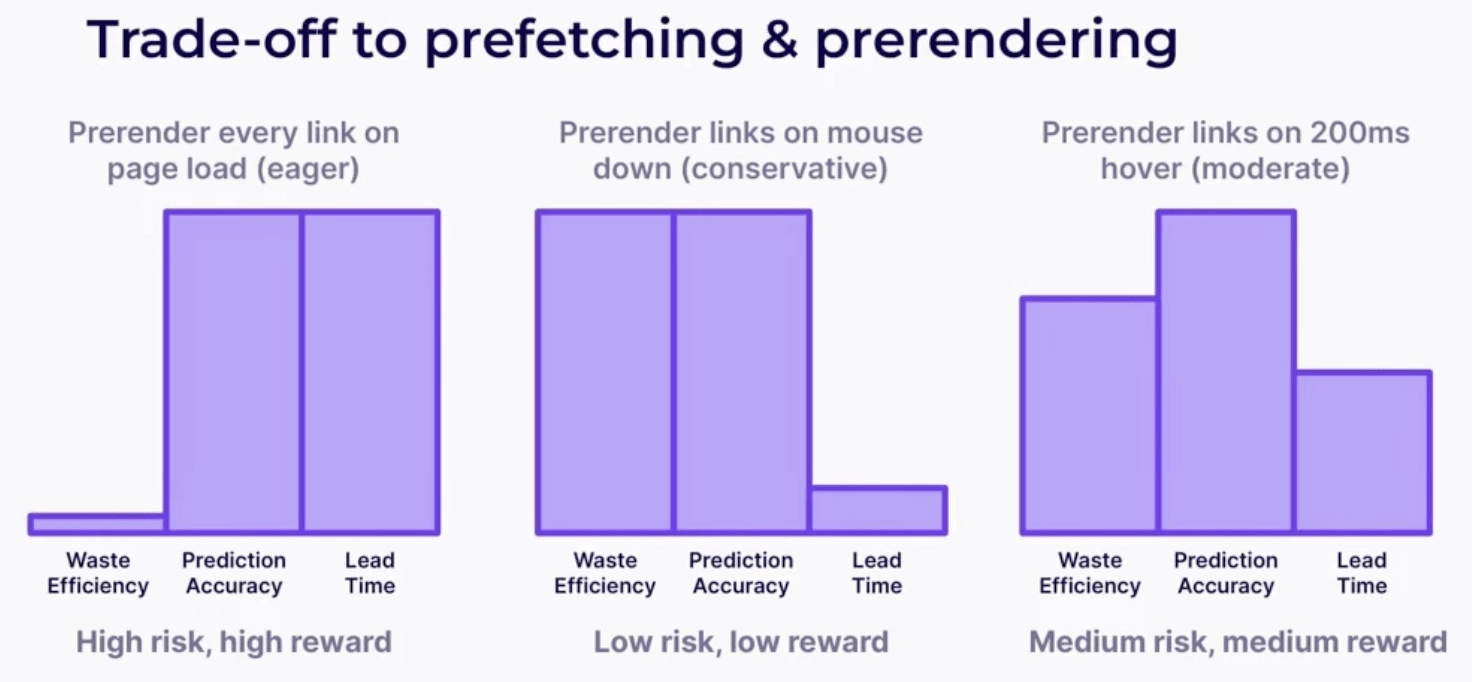
- ระบุระดับของ "ความกระตือรือร้น": ใช้การตั้งค่าความกระตือรือร้นเพื่อระบุว่าเมื่อใดที่การคาดเดาควรเริ่มทำงาน - "กระตือรือร้น" จะเริ่มกฎการเก็งกำไรทันทีที่สังเกตเห็น “ปานกลาง” ทำการคาดเดาหากคุณวางเมาส์เหนือลิงก์เป็นเวลา 200 มิลลิวินาที “อนุรักษ์นิยม” เก็งกำไรบนตัวชี้หรือทัชดาวน์

วิธีระบุระดับ “ความกระตือรือร้น”
การไม่ว่าคุณจะดึงข้อมูลล่วงหน้าหรือแสดงผลหน้าล่วงหน้านั้นขึ้นอยู่กับการปรับปรุงประสิทธิภาพที่คุณต้องการทำให้สำเร็จ:
การดึงข้อมูลล่วงหน้า จะสั่งให้เบราว์เซอร์ดาวน์โหลดเนื้อหาการตอบกลับของหน้าที่อ้างอิง แต่ไม่ใช่ทรัพยากรย่อยที่อ้างอิงโดยหน้านั้น เมื่อผู้ใช้ไปที่หน้าที่ดึงข้อมูลล่วงหน้า หน้านั้นจะโหลดเร็วกว่าปกติ
ในทางกลับกันการเรนเดอร์ล่วงหน้า จะสั่งให้เบราว์เซอร์ดึงข้อมูล แสดงผล และโหลดเนื้อหาทั้งหมด รวมถึงทรัพยากรย่อยและ JavaScript ลงในแท็บที่มองไม่เห็นการโหลดทรัพยากรล่วงหน้านี้ทำให้เกิดประสบการณ์แทบจะทันทีเมื่อผู้ใช้ไปที่เพจ
แม้ว่าประโยชน์ด้านประสิทธิภาพของการแสดงผลล่วงหน้าจะมีความสำคัญมากกว่า แต่คุณควรใช้เทคโนโลยีการโหลดนี้เท่าที่จำเป็น การแสดงผลล่วงหน้าใช้หน่วยความจำและแบนด์วิดท์เครือข่ายจำนวนมาก ซึ่งอาจทำให้สิ้นเปลืองทรัพยากรหากผู้ใช้ไม่ได้ไปที่หน้านั้น
ในทางกลับกัน ค่าใช้จ่ายล่วงหน้าของการดึงข้อมูลล่วงหน้าจะน้อยกว่าค่าใช้จ่ายของการดึงข้อมูลล่วงหน้ามาก คุณจึงนำการดึงข้อมูลล่วงหน้ามาใช้ในวงกว้างมากขึ้นได้
การเรนเดอร์และการดึงข้อมูลล่วงหน้าใน WordPress
ผู้ใช้ WordPress สามารถแทรกแท็ก ลิงก์ สำหรับการดึงข้อมูลล่วงหน้าหรือการแสดงผลทรัพยากรล่วงหน้าในเอกสาร HTML มาหลายปีแล้ว ต้องขอบคุณ Resource Hints API
อย่างไรก็ตาม การใช้แท็กไม่มีความยืดหยุ่นเนื่องจากต้องระบุ URL ล่วงหน้า ซึ่งอาจนำไปสู่การสิ้นเปลืองทรัพยากรหรือประสิทธิภาพการทำงานที่พลาดไป นอกจากนี้ โซลูชันแบบไดนามิกที่แทรกแท็ก ลิงก์ ตามการมองเห็นวิวพอร์ตยังให้ความยืดหยุ่นมากกว่า แต่ยังคงทำให้เกิดการดึงข้อมูลล่วงหน้ามากเกินไปได้
เมื่อพิจารณาถึงข้อจำกัดเหล่านี้แล้ว ทีมงานด้านประสิทธิภาพก็มีแรงจูงใจอย่างมากในการหาวิธีแก้ปัญหาที่ดีกว่า...
การโหลดแบบเก็งกำไร: ปลั๊กอินประสิทธิภาพ WordPress ใหม่
การโหลดแบบเก็งกำไรทำให้สามารถแสดงผลล่วงหน้าหรือดึงข้อมูล URL ส่วนหน้าอื่นๆ ที่เชื่อมโยงอยู่บนหน้าได้
เมื่อเปิดใช้งานแล้ว ปลั๊กอินจะแทรกสคริปต์ JSON โดยอัตโนมัติ และแสดงผล URL ใดๆ บนหน้าล่วงหน้าด้วยความกระตือรือร้น "ปานกลาง"
คุณสามารถเปลี่ยนพฤติกรรมเริ่มต้นนี้ได้อย่างง่ายดายและแก้ไขได้ผ่านทางส่วน "การโหลดแบบเก็งกำไร" ใน การตั้งค่า > หน้าจอการอ่าน :


ที่มา:เวิร์ดเพรส
นอกจากนี้ คุณยังสามารถปรับแต่ง URL ที่จะโหลดล่วงหน้าแบบคาดเดาได้โดยใช้ตัวกรองที่เรียกว่า “plsr_speculation_rules_href_exclude_paths” ตัวอย่างเช่น หน้าที่แก้ไขตามการกระทำของผู้ใช้ (เช่น รถเข็น) สามารถแยกออกจากการแสดงผลล่วงหน้าหรือดึงข้อมูลล่วงหน้าได้
นี่คือตัวอย่างโค้ดของตัวกรอง:

ที่มา:เวิร์ดเพรส
วิธีทดสอบและส่งคำติชม
ทีมงาน WordPress Performance กำลังสนับสนุนให้ผู้คนทดสอบปลั๊กอินใหม่มากขึ้น เนื่องจากพวกเขาพิจารณาที่จะรวมคุณสมบัตินี้ไว้ในแกนหลักของ WordPress ในอนาคต
ต่อไปนี้คือวิธีที่คุณสามารถช่วยพวกเขาได้:
- ติดตั้งและเปิดใช้งาน ปลั๊กอิน Speculative Loading บนไซต์ของคุณผ่าน WP Admin หรือปลั๊กอิน Performance Lab
- ลองกำหนดค่าต่างๆ ผ่านทางส่วน "การโหลดแบบเก็งกำไร" ใต้การตั้งค่า > การอ่าน
- แก้ไขข้อบกพร่องว่ากฎที่เพิ่มโดยปลั๊กอินทริกเกอร์การโหลดแบบเก็งกำไรอย่างไร เพื่อให้เข้าใจคุณลักษณะได้ดีขึ้นและค้นหาจุดบกพร่องที่อาจเกิดขึ้น
- รายงานข้อเสนอแนะหรือข้อบกพร่อง ในพื้นที่เก็บข้อมูล GitHub หรือฟอรัมสนับสนุนของปลั๊กอิน
- ผสานรวม ปลั๊กอินของคุณเข้ากับตัวกรอง “plsr_speculation_rules_href_exclude_paths” เพื่อยกเว้น URL ที่ต้องการจากการดึงข้อมูลล่วงหน้าและ/หรือการแสดงผลล่วงหน้า
AI การนำทางโดย NitroPack: โซลูชันอัตโนมัติสำหรับประสบการณ์เพจทันที
Navigation AI โดย NitroPack คือเครื่องมือเพิ่มประสิทธิภาพเว็บที่ขับเคลื่อนด้วย AI ซึ่งจะคาดการณ์และวิเคราะห์พฤติกรรมของผู้ใช้โดยอัตโนมัติเพื่อแสดงผลทั้งหน้าล่วงหน้าในระหว่างการเดินทางของลูกค้า
โซลูชันแบบไม่ต้องสัมผัสสร้างขึ้นจาก Speculation Rules API ช่วยให้นักพัฒนาและเจ้าของไซต์สามารถมอบประสบการณ์การท่องเว็บได้ทันทีโดย:
- การใช้การคาดการณ์เบื้องต้นที่ปรับปรุงโดย AI ในการโหลดหน้าเว็บโดยอิงตามข้อมูลโดยไม่ส่งต่อไปยัง Speculation Rules API (ยัง)
- วิเคราะห์พฤติกรรมของผู้ใช้ ปรับการคาดการณ์ และสั่งให้ Speculation Rules API แสดงผลล่วงหน้า (หรือดึงข้อมูลล่วงหน้า) หน้าเว็บเมื่อเราแน่ใจว่าการดำเนินการต่อไปนี้จะเป็นอย่างไร

การผสมผสานระหว่างปัญญาประดิษฐ์และ Speculation Rules API ของ Google ย่อมนำไปสู่ผลลัพธ์ประสิทธิภาพที่น่าประทับใจอย่างหลีกเลี่ยงไม่ได้:
- เวลาในการโหลดต่ำกว่า 3 วินาที
- การปรับปรุงครั้งใหญ่ใน LCP (Largest Contentful Paint) และ CLS (Cumulative Layout Shift)
- Core Web Vitals ที่ดีขึ้นสำหรับทั้งเว็บไซต์
ดังนั้น หากคุณต้องการให้ผู้เยี่ยมชมตื่นตะลึงกับความเร็วในการโหลดหน้าเว็บของคุณ...
เข้าร่วมรายชื่อรอสำหรับ Navigation AI และเตรียมไซต์ของคุณให้พร้อมสำหรับประสบการณ์ผู้ใช้ทันที →
คำถามที่พบบ่อย
ปลั๊กอินการโหลดเก็งกำไรใน WordPress ใช้ AI หรือไม่
ไม่ ปลั๊กอินการโหลดแบบเก็งกำไรไม่ได้ขับเคลื่อนโดยปัญญาประดิษฐ์ (AI) มันใช้ประโยชน์จาก Speculation Rules API ของ Google โดยแทรกสคริปต์ JSON ลงใน URL ใดๆ ที่เชื่อมโยงบนเพจ และแสดงผลล่วงหน้าด้วยการกำหนดค่าความกระตือรือร้นเป็น "ปานกลาง"
หน้าใดที่มีสิทธิ์สำหรับการโหลดแบบเก็งกำไร
คุณสามารถใช้กลยุทธ์การโหลดแบบเก็งกำไรกับทุกหน้าที่ไม่ได้ถูกแก้ไขโดยการกระทำของผู้ใช้ หลักการทั่วไปที่ดีคือหลีกเลี่ยงการแสดงผลล่วงหน้าหรือดึงข้อมูลหน้าชำระเงินและรถเข็นล่วงหน้า เนื่องจากอาจทำให้ผู้ใช้ได้รับประสบการณ์ที่ไม่ดี นอกจากนี้ Google แนะนำเฉพาะหน้าเว็บที่แอบอ้างเมื่อมีความเป็นไปได้สูง (มากกว่า 80% ของเวลา) ที่ผู้ใช้จะโหลดหน้าเว็บเหล่านั้น
เบราว์เซอร์ใดบ้างที่รองรับ Speculation Rules API
แม้ว่า Speculation Rules API จะพร้อมใช้งานใน Chrome และ Edge ตั้งแต่เวอร์ชัน 109 แต่ฟีเจอร์ย่อย “กฎเอกสาร” ที่ช่วยให้เบราว์เซอร์รับรายการ URL สำหรับการโหลดแบบคาดเดาจากองค์ประกอบในหน้าเว็บนั้นพร้อมใช้งานจาก Chrome 121 กล่าวอีกนัยหนึ่ง ผู้ใช้จะต้องใช้ Chrome 121+ หรือ Edge 121+ เพื่อรับประโยชน์เต็มที่จาก Speculation Rules API
Google Analytics จัดการกับการโหลดล่วงหน้าแบบเก็งกำไรอย่างไร
หากคุณใช้ Google Analytics คุณไม่จำเป็นต้องดำเนินการใดๆ เนื่องจาก GA จะจัดการการเรนเดอร์ล่วงหน้าโดยเลื่อนออกไปจนกว่าจะเปิดใช้งานตามค่าเริ่มต้น อย่างไรก็ตาม สำหรับเครื่องมืออื่นๆ หน้าที่แสดงผลล่วงหน้าอาจส่งผลกระทบต่อการวิเคราะห์ และเจ้าของไซต์อาจต้องเพิ่มโค้ดพิเศษเพื่อเปิดใช้งานเฉพาะการวิเคราะห์สำหรับหน้าที่แสดงผลล่วงหน้าเมื่อเปิดใช้งาน ซึ่งสามารถทำได้โดยใช้ Promise ซึ่งจะรอเหตุการณ์ การเปลี่ยนแปลงการเรนเดอร์ล่วงหน้า หากเอกสารกำลังเรนเดอร์ล่วงหน้า