
คำแนะนำทีละขั้นตอนในการสร้างโปรแกรมรวบรวมข้อมูลเว็บ
เผยแพร่แล้ว: 2023-12-05ในโลกอินเทอร์เน็ตที่สลับซับซ้อน ซึ่งข้อมูลกระจัดกระจายไปตามเว็บไซต์นับไม่ถ้วน โปรแกรมรวบรวมข้อมูลเว็บกลายเป็นวีรบุรุษที่ไม่มีใครรู้จัก ทำงานอย่างขยันขันแข็งเพื่อจัดระเบียบ จัดทำดัชนี และทำให้สามารถเข้าถึงข้อมูลอันมากมายมหาศาลนี้ได้ บทความนี้เริ่มต้นการสำรวจโปรแกรมรวบรวมข้อมูลเว็บ ให้ความกระจ่างเกี่ยวกับการทำงานพื้นฐาน แยกความแตกต่างระหว่างการรวบรวมข้อมูลเว็บและการขูดเว็บ และให้ข้อมูลเชิงลึกที่เป็นประโยชน์ เช่น คำแนะนำทีละขั้นตอนในการสร้างโปรแกรมรวบรวมข้อมูลเว็บที่ใช้ Python อย่างง่าย เมื่อเราเจาะลึกมากขึ้น เราจะเปิดเผยความสามารถของเครื่องมือขั้นสูง เช่น Scrapy และค้นพบว่า PromptCloud ยกระดับการรวบรวมข้อมูลเว็บไปสู่ระดับอุตสาหกรรมได้อย่างไร
โปรแกรมรวบรวมข้อมูลเว็บคืออะไร
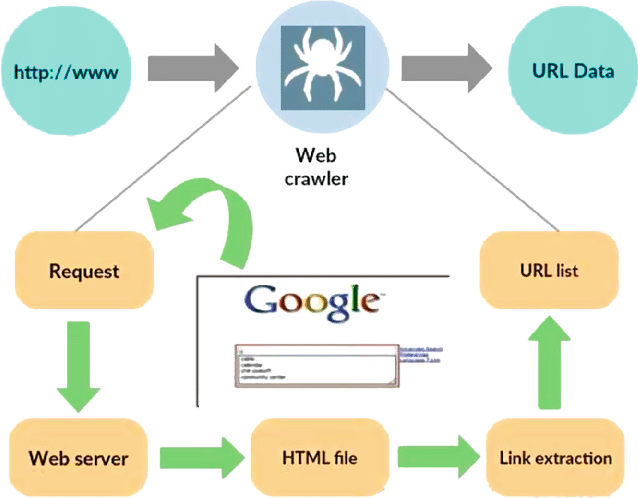
ที่มา: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
โปรแกรมรวบรวมข้อมูลเว็บหรือที่รู้จักกันในชื่อสไปเดอร์หรือบอทเป็นโปรแกรมพิเศษที่ออกแบบมาเพื่อนำทางอย่างเป็นระบบและอัตโนมัติในเวิลด์ไวด์เว็บอันกว้างใหญ่ หน้าที่หลักคือสำรวจเว็บไซต์ รวบรวมข้อมูล และจัดทำดัชนีข้อมูลเพื่อวัตถุประสงค์ต่างๆ เช่น การเพิ่มประสิทธิภาพเครื่องมือค้นหา การทำดัชนีเนื้อหา หรือการดึงข้อมูล
โดยพื้นฐานแล้ว โปรแกรมรวบรวมข้อมูลเว็บจะเลียนแบบการกระทำของผู้ใช้ที่เป็นมนุษย์ แต่ทำได้เร็วกว่าและมีประสิทธิภาพมากกว่ามาก โดยเริ่มต้นการเดินทางจากจุดเริ่มต้นที่กำหนด ซึ่งมักเรียกว่า URL เริ่มต้น จากนั้นติดตามไฮเปอร์ลิงก์จากหน้าเว็บหนึ่งไปยังอีกหน้าเว็บหนึ่ง กระบวนการต่อไปนี้ของลิงก์เป็นแบบเรียกซ้ำ ทำให้โปรแกรมรวบรวมข้อมูลสามารถสำรวจส่วนสำคัญของอินเทอร์เน็ตได้
เมื่อโปรแกรมรวบรวมข้อมูลเข้าชมหน้าเว็บ โปรแกรมจะแยกและจัดเก็บข้อมูลที่เกี่ยวข้องอย่างเป็นระบบ ซึ่งอาจรวมถึงข้อความ รูปภาพ ข้อมูลเมตา และอื่นๆ จากนั้นข้อมูลที่แยกออกมาจะถูกจัดระเบียบและจัดทำดัชนี ทำให้เครื่องมือค้นหาดึงและนำเสนอข้อมูลที่เกี่ยวข้องแก่ผู้ใช้ได้ง่ายขึ้นเมื่อมีการสอบถาม
โปรแกรมรวบรวมข้อมูลเว็บมีบทบาทสำคัญในการทำงานของเครื่องมือค้นหาเช่น Google, Bing และ Yahoo ด้วยการรวบรวมข้อมูลเว็บอย่างต่อเนื่องและเป็นระบบ ช่วยให้มั่นใจได้ว่าดัชนีเครื่องมือค้นหามีความทันสมัย ทำให้ผู้ใช้ได้รับผลการค้นหาที่แม่นยำและเกี่ยวข้อง นอกจากนี้ โปรแกรมรวบรวมข้อมูลเว็บยังถูกนำมาใช้ในแอปพลิเคชันอื่นๆ มากมาย รวมถึงการรวบรวมเนื้อหา การตรวจสอบเว็บไซต์ และการขุดข้อมูล
ประสิทธิผลของโปรแกรมรวบรวมข้อมูลเว็บขึ้นอยู่กับความสามารถในการสำรวจโครงสร้างเว็บไซต์ที่หลากหลาย จัดการเนื้อหาแบบไดนามิก และเคารพกฎที่กำหนดโดยเว็บไซต์ผ่านไฟล์ robots.txt ซึ่งสรุปว่าส่วนใดของเว็บไซต์ที่สามารถรวบรวมข้อมูลได้ การทำความเข้าใจวิธีการทำงานของโปรแกรมรวบรวมข้อมูลเว็บเป็นพื้นฐานในการตระหนักถึงความสำคัญในการทำให้สามารถเข้าถึงและจัดระเบียบเว็บข้อมูลอันกว้างใหญ่ได้
โปรแกรมรวบรวมข้อมูลเว็บทำงานอย่างไร
โปรแกรมรวบรวมข้อมูลเว็บหรือที่เรียกว่าสไปเดอร์หรือบอททำงานผ่านกระบวนการที่เป็นระบบในการนำทางเวิลด์ไวด์เว็บเพื่อรวบรวมข้อมูลจากเว็บไซต์ ภาพรวมการทำงานของโปรแกรมรวบรวมข้อมูลเว็บมีดังนี้:
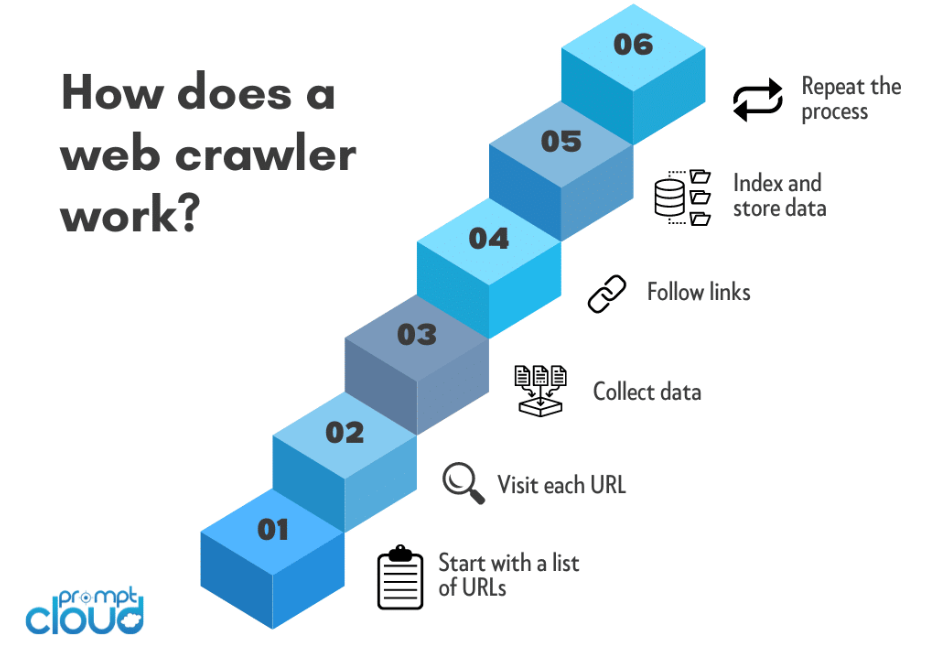
การเลือก URL ของเมล็ดพันธุ์:
โดยทั่วไป กระบวนการรวบรวมข้อมูลเว็บจะเริ่มต้นด้วย URL เริ่มต้น นี่คือหน้าเว็บหรือเว็บไซต์เริ่มต้นที่โปรแกรมรวบรวมข้อมูลเริ่มต้นการเดินทาง
คำขอ HTTP:
โปรแกรมรวบรวมข้อมูลส่งคำขอ HTTP ไปยัง URL เริ่มต้นเพื่อดึงเนื้อหา HTML ของหน้าเว็บ คำขอนี้คล้ายกับคำขอที่ทำโดยเว็บเบราว์เซอร์เมื่อเข้าถึงเว็บไซต์
การแยกวิเคราะห์ HTML:
เมื่อดึงเนื้อหา HTML แล้ว โปรแกรมรวบรวมข้อมูลจะแยกวิเคราะห์เพื่อแยกข้อมูลที่เกี่ยวข้อง ซึ่งเกี่ยวข้องกับการแบ่งโค้ด HTML ให้เป็นรูปแบบที่มีโครงสร้างซึ่งโปรแกรมรวบรวมข้อมูลสามารถนำทางและวิเคราะห์ได้
การแยก URL:
โปรแกรมรวบรวมข้อมูลจะระบุและแยกไฮเปอร์ลิงก์ (URL) ที่มีอยู่ในเนื้อหา HTML URL เหล่านี้แสดงถึงลิงก์ไปยังหน้าอื่นๆ ที่โปรแกรมรวบรวมข้อมูลจะเข้าชมในภายหลัง
คิวและตัวกำหนดเวลา:
URL ที่แยกออกมาจะถูกเพิ่มลงในคิวหรือตัวกำหนดเวลา คิวช่วยให้แน่ใจว่าโปรแกรมรวบรวมข้อมูลเข้าชม URL ในลำดับเฉพาะ โดยมักจะจัดลำดับความสำคัญของ URL ใหม่หรือที่ไม่ได้เข้าชมก่อน
การเรียกซ้ำ:
โปรแกรมรวบรวมข้อมูลติดตามลิงก์ในคิว ทำซ้ำขั้นตอนการส่งคำขอ HTTP แยกวิเคราะห์เนื้อหา HTML และแยก URL ใหม่ กระบวนการแบบเรียกซ้ำนี้ช่วยให้โปรแกรมรวบรวมข้อมูลสามารถนำทางผ่านหน้าเว็บหลายชั้นได้
การสกัดข้อมูล:
ในขณะที่โปรแกรมรวบรวมข้อมูลสำรวจเว็บ มันจะดึงข้อมูลที่เกี่ยวข้องจากหน้าที่เยี่ยมชมแต่ละหน้า ประเภทของข้อมูลที่แยกออกมาจะขึ้นอยู่กับวัตถุประสงค์ของโปรแกรมรวบรวมข้อมูล และอาจรวมถึงข้อความ รูปภาพ ข้อมูลเมตา หรือเนื้อหาเฉพาะอื่นๆ
การจัดทำดัชนีเนื้อหา:
ข้อมูลที่รวบรวมจะถูกจัดระเบียบและจัดทำดัชนี การทำดัชนีเกี่ยวข้องกับการสร้างฐานข้อมูลที่มีโครงสร้างซึ่งทำให้ง่ายต่อการค้นหา ดึงข้อมูล และนำเสนอข้อมูลเมื่อผู้ใช้ส่งแบบสอบถาม
เคารพ Robots.txt:
โดยทั่วไปโปรแกรมรวบรวมข้อมูลเว็บจะปฏิบัติตามกฎที่ระบุในไฟล์ robots.txt ของเว็บไซต์ ไฟล์นี้ให้คำแนะนำว่าพื้นที่ใดของไซต์ที่สามารถรวบรวมข้อมูลได้ และส่วนใดที่ควรยกเว้น
ความล่าช้าในการรวบรวมข้อมูลและความสุภาพ:
เพื่อหลีกเลี่ยงไม่ให้เซิร์ฟเวอร์ทำงานหนักเกินไปและทำให้เกิดการหยุดชะงัก โปรแกรมรวบรวมข้อมูลมักจะรวมกลไกสำหรับความล่าช้าในการรวบรวมข้อมูลและความสุภาพ มาตรการเหล่านี้ช่วยให้แน่ใจว่าโปรแกรมรวบรวมข้อมูลโต้ตอบกับเว็บไซต์ด้วยความเคารพและไม่รบกวน
โปรแกรมรวบรวมข้อมูลเว็บนำทางเว็บอย่างเป็นระบบ ตามลิงก์ แยกข้อมูล และสร้างดัชนีที่จัดระเบียบ กระบวนการนี้ช่วยให้เครื่องมือค้นหาสามารถนำเสนอผลลัพธ์ที่แม่นยำและเกี่ยวข้องแก่ผู้ใช้ตามข้อความค้นหาของพวกเขา ทำให้โปรแกรมรวบรวมข้อมูลเว็บเป็นองค์ประกอบพื้นฐานของระบบนิเวศอินเทอร์เน็ตสมัยใหม่

การรวบรวมข้อมูลเว็บกับการขูดเว็บ

ที่มา: https://research.aimultiple.com/web-crawling-vs-web-scraping/
แม้ว่าการรวบรวมข้อมูลเว็บและการขูดเว็บมักใช้สลับกัน แต่ก็มีจุดประสงค์ที่แตกต่างกันออกไป การรวบรวมข้อมูลเว็บเกี่ยวข้องกับการนำทางเว็บอย่างเป็นระบบเพื่อสร้างดัชนีและรวบรวมข้อมูล ในขณะที่การขูดเว็บมุ่งเน้นไปที่การแยกข้อมูลเฉพาะจากหน้าเว็บ โดยพื้นฐานแล้ว การรวบรวมข้อมูลเว็บเป็นเรื่องเกี่ยวกับการสำรวจและจัดทำแผนที่เว็บ ในขณะที่การคัดลอกเว็บเป็นเรื่องเกี่ยวกับการรวบรวมข้อมูลเป้าหมาย
การสร้างโปรแกรมรวบรวมข้อมูลเว็บ
การสร้างโปรแกรมรวบรวมข้อมูลเว็บอย่างง่ายใน Python เกี่ยวข้องกับหลายขั้นตอน ตั้งแต่การตั้งค่าสภาพแวดล้อมการพัฒนาไปจนถึงการเขียนโค้ดตรรกะของโปรแกรมรวบรวมข้อมูล ด้านล่างนี้เป็นคำแนะนำโดยละเอียดเพื่อช่วยคุณสร้างโปรแกรมรวบรวมข้อมูลเว็บพื้นฐานโดยใช้ Python โดยใช้ไลบรารีคำขอสำหรับสร้างคำขอ HTTP และ BeautifulSoup สำหรับการแยกวิเคราะห์ HTML
ขั้นตอนที่ 1: ตั้งค่าสภาพแวดล้อม
ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Python บนระบบของคุณ คุณสามารถดาวน์โหลดได้จาก python.org นอกจากนี้ คุณจะต้องติดตั้งไลบรารีที่จำเป็น:
pip install requests beautifulsoup4
ขั้นตอนที่ 2: นำเข้าไลบรารี
สร้างไฟล์ Python ใหม่ (เช่น simple_crawler.py) และนำเข้าไลบรารีที่จำเป็น:
import requests from bs4 import BeautifulSoup
ขั้นตอนที่ 3: กำหนดฟังก์ชันรวบรวมข้อมูล
สร้างฟังก์ชันที่ใช้ URL เป็นอินพุต ส่งคำขอ HTTP และดึงข้อมูลที่เกี่ยวข้องจากเนื้อหา HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
ขั้นตอนที่ 4: ทดสอบโปรแกรมรวบรวมข้อมูล
ระบุ URL ตัวอย่างและเรียกใช้ฟังก์ชัน simple_crawler เพื่อทดสอบโปรแกรมรวบรวมข้อมูล:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
ขั้นตอนที่ 5: เรียกใช้โปรแกรมรวบรวมข้อมูล
รันสคริปต์ Python ในเทอร์มินัลหรือพร้อมท์คำสั่งของคุณ:
python simple_crawler.py
โปรแกรมรวบรวมข้อมูลจะดึงเนื้อหา HTML ของ URL ที่ระบุ แยกวิเคราะห์ และพิมพ์ชื่อ คุณสามารถขยายโปรแกรมรวบรวมข้อมูลได้โดยการเพิ่มฟังก์ชันการทำงานเพิ่มเติมสำหรับการดึงข้อมูลประเภทต่างๆ
การรวบรวมข้อมูลเว็บด้วย Scrapy
การรวบรวมข้อมูลเว็บด้วย Scrapy เปิดประตูสู่เฟรมเวิร์กที่ทรงพลังและยืดหยุ่น ซึ่งออกแบบมาโดยเฉพาะเพื่อการขูดเว็บที่มีประสิทธิภาพและปรับขนาดได้ Scrapy ช่วยลดความซับซ้อนในการสร้างโปรแกรมรวบรวมข้อมูลเว็บ โดยนำเสนอสภาพแวดล้อมที่มีโครงสร้างสำหรับการสร้างสไปเดอร์ที่สามารถนำทางเว็บไซต์ ดึงข้อมูล และจัดเก็บอย่างเป็นระบบ ต่อไปนี้เป็นภาพรวมของการรวบรวมข้อมูลเว็บด้วย Scrapy:
การติดตั้ง:
ก่อนที่คุณจะเริ่ม ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Scrapy แล้ว คุณสามารถติดตั้งได้โดยใช้:
pip install scrapy
การสร้างโครงการ Scrapy:
เริ่มต้นโครงการ Scrapy:
เปิดเทอร์มินัลแล้วไปที่ไดเร็กทอรีที่คุณต้องการสร้างโปรเจ็กต์ Scrapy รันคำสั่งต่อไปนี้:
scrapy startproject your_project_name
สิ่งนี้จะสร้างโครงสร้างพื้นฐานของโปรเจ็กต์พร้อมไฟล์ที่จำเป็น
กำหนดแมงมุม:
ภายในไดเร็กทอรีโปรเจ็กต์ ให้นำทางไปยังโฟลเดอร์สไปเดอร์และสร้างไฟล์ Python สำหรับสไปเดอร์ของคุณ กำหนดคลาสสไปเดอร์โดยคลาสย่อย scrapy.Spider และระบุรายละเอียดที่สำคัญ เช่น ชื่อ โดเมนที่อนุญาต และ URL เริ่มต้น
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
การดึงข้อมูล:
การใช้ตัวเลือก:
Scrapy ใช้ตัวเลือกที่มีประสิทธิภาพในการดึงข้อมูลจาก HTML คุณสามารถกำหนดตัวเลือกในวิธีการแยกวิเคราะห์ของสไปเดอร์เพื่อจับองค์ประกอบเฉพาะ
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
ตัวอย่างนี้แยกเนื้อหาข้อความของแท็ก <title>
ลิงค์ต่อไปนี้:
Scrapy ช่วยให้กระบวนการต่อไปนี้ลิงก์ง่ายขึ้น ใช้วิธีติดตามเพื่อนำทางไปยังหน้าอื่นๆ
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
วิ่งแมงมุม:
ดำเนินการสไปเดอร์ของคุณโดยใช้คำสั่งต่อไปนี้จากไดเรกทอรีโครงการ:
scrapy crawl your_spider
Scrapy จะเริ่มต้นสไปเดอร์ ติดตามลิงก์ และดำเนินการตรรกะการแยกวิเคราะห์ที่กำหนดไว้ในวิธีการแยกวิเคราะห์
การรวบรวมข้อมูลเว็บด้วย Scrapy นำเสนอเฟรมเวิร์กที่แข็งแกร่งและขยายได้สำหรับการจัดการงานการขูดที่ซับซ้อน สถาปัตยกรรมแบบโมดูลาร์และคุณสมบัติในตัวทำให้เป็นตัวเลือกที่ดีสำหรับนักพัฒนาที่มีส่วนร่วมในโครงการแยกข้อมูลเว็บที่ซับซ้อน
การรวบรวมข้อมูลเว็บตามขนาด
การรวบรวมข้อมูลเว็บในวงกว้างทำให้เกิดความท้าทายที่ไม่เหมือนใคร โดยเฉพาะอย่างยิ่งเมื่อต้องรับมือกับข้อมูลจำนวนมหาศาลที่กระจายอยู่ตามเว็บไซต์จำนวนมาก PromptCloud เป็นแพลตฟอร์มพิเศษที่ออกแบบมาเพื่อปรับปรุงประสิทธิภาพและเพิ่มประสิทธิภาพกระบวนการรวบรวมข้อมูลเว็บในวงกว้าง ต่อไปนี้คือวิธีที่ PromptCloud สามารถช่วยในการจัดการโครงการริเริ่มการรวบรวมข้อมูลเว็บขนาดใหญ่:
- ความสามารถในการขยายขนาด
- การดึงข้อมูลและการเพิ่มคุณค่า
- คุณภาพและความถูกต้องของข้อมูล
- การจัดการโครงสร้างพื้นฐาน
- สะดวกในการใช้
- การปฏิบัติตามกฎระเบียบและจริยธรรม
- การตรวจสอบและการรายงานแบบเรียลไทม์
- การสนับสนุนและการบำรุงรักษา
PromptCloud เป็นโซลูชันที่มีประสิทธิภาพสำหรับองค์กรและบุคคลที่ต้องการดำเนินการรวบรวมข้อมูลเว็บในวงกว้าง ด้วยการจัดการกับความท้าทายหลักที่เกี่ยวข้องกับการดึงข้อมูลขนาดใหญ่ แพลตฟอร์มดังกล่าวจึงเพิ่มประสิทธิภาพ ความน่าเชื่อถือ และความสามารถในการจัดการของความคิดริเริ่มในการรวบรวมข้อมูลเว็บ
สรุป
โปรแกรมรวบรวมข้อมูลเว็บยืนหยัดเป็นวีรบุรุษที่ไม่มีใครรู้จักในโลกดิจิทัลอันกว้างใหญ่ โดยสำรวจเว็บอย่างขยันขันแข็งเพื่อจัดทำดัชนี รวบรวม และจัดระเบียบข้อมูล เมื่อขนาดของโปรเจ็กต์การรวบรวมข้อมูลเว็บขยายใหญ่ขึ้น PromptCloud ก็ก้าวเข้ามาเป็นโซลูชัน โดยนำเสนอความสามารถในการปรับขนาด การเพิ่มคุณค่าของข้อมูล และการปฏิบัติตามหลักจริยธรรมเพื่อปรับปรุงความริเริ่มขนาดใหญ่ ติดต่อเราได้ที่ sales@promptcloud.com