
คำแนะนำขั้นสูงสุดในการสร้าง Web Scrapers ในราคาที่แข่งขันได้
เผยแพร่แล้ว: 2024-04-05การกำหนดราคาที่แข่งขันได้ แนวทางปฏิบัติในการเลือกจุดราคาเชิงกลยุทธ์เพื่อใช้ประโยชน์จากตลาดของผลิตภัณฑ์หรือบริการให้ดีที่สุดเมื่อเทียบกับคู่แข่ง ได้กลายเป็นเครื่องมือสำคัญสำหรับธุรกิจที่มุ่งหวังที่จะดึงดูดและรักษาลูกค้าไว้ ในยุคดิจิทัลที่การเปรียบเทียบราคาทำได้เพียงคลิกเดียว ความสำคัญของการกำหนดราคาที่แข่งขันได้ได้ถูกขยายออกไป ไม่เพียงแต่มีอิทธิพลต่อการตัดสินใจซื้อของผู้บริโภคเท่านั้น แต่ยังส่งผลกระทบโดยตรงต่อส่วนแบ่งการตลาดและความสามารถในการทำกำไรของธุรกิจอีกด้วย
เข้าสู่ขอบเขตของ web scraper ซึ่งเป็นเครื่องมืออันทรงพลังที่ทำให้กระบวนการดึงข้อมูลจากเว็บไซต์เป็นไปโดยอัตโนมัติ ในบริบทของการกำหนดราคาที่แข่งขันได้ Web Scraping ถูกนำมาใช้เพื่อรวบรวมข้อมูลการกำหนดราคาจากเว็บไซต์ของคู่แข่ง ช่วยให้ธุรกิจต่างๆ สามารถวิเคราะห์ตำแหน่งทางการตลาดของตนและปรับกลยุทธ์การกำหนดราคาให้เหมาะสมได้ เทคนิคนี้นำเสนอมุมมองที่ครอบคลุมแบบเรียลไทม์ของแนวการแข่งขัน ซึ่งมีความสำคัญต่อการตัดสินใจด้านราคาอย่างมีข้อมูล ด้วยการใช้ประโยชน์จาก web scraper บริษัทต่างๆ สามารถมั่นใจได้ว่ากลยุทธ์การกำหนดราคาของตนนั้นขับเคลื่อนด้วยข้อมูล ไดนามิก และสอดคล้องกับแนวโน้มของตลาด
ก่อนที่จะเจาะลึกถึงความซับซ้อนของการสร้าง web scraper สำหรับกลยุทธ์การกำหนดราคาที่แข่งขันได้ จำเป็นอย่างยิ่งที่จะต้องสร้างความเข้าใจอย่างถ่องแท้ว่า web scraping เกี่ยวข้องกับอะไรและหลักการพื้นฐานที่อยู่เบื้องหลัง
Web Scraping คืออะไร?
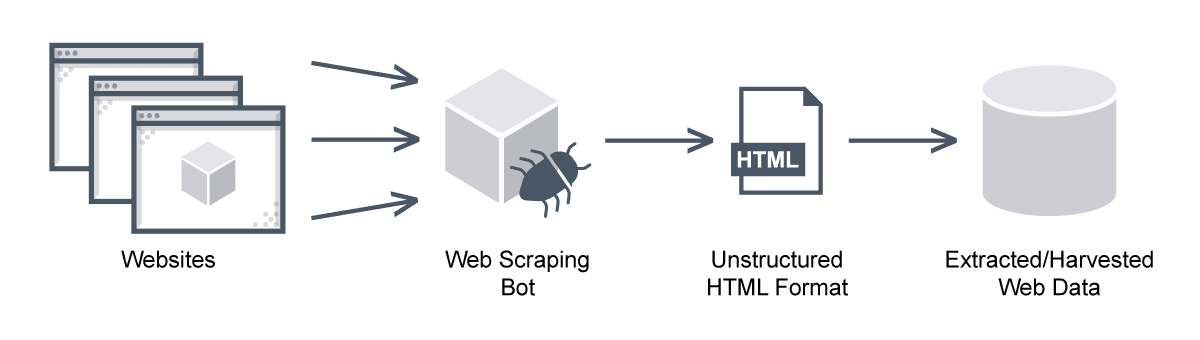
ที่มา: https://avinetworks.com/glossary/web-scraping/
การขูดเว็บเป็นเทคนิคที่ใช้ในการดึงข้อมูลจำนวนมากจากเว็บไซต์โดยอัตโนมัติ กระบวนการนี้เกี่ยวข้องกับการส่งคำขอไปยังหน้าเว็บ ดาวน์โหลดหน้าเว็บ จากนั้นแยกวิเคราะห์โค้ด HTML เพื่อแยกข้อมูลที่คุณต้องการ เทคนิคนี้มีประโยชน์อย่างยิ่งในการรวบรวมข้อมูลจากเว็บไซต์ที่ไม่มี API หรือวิธีอื่นในการเข้าถึงข้อมูลโดยทางโปรแกรม
การตั้งค่าสภาพแวดล้อมการขูดเว็บของคุณ
เพื่อควบคุมศักยภาพของ web scraper อย่างเต็มที่เพื่อราคาที่แข่งขันได้ สิ่งสำคัญคือต้องสร้างสภาพแวดล้อมการพัฒนาที่แข็งแกร่งและยืดหยุ่น สิ่งนี้เกี่ยวข้องกับการเลือกเครื่องมือและภาษาการเขียนโปรแกรมที่เหมาะสม
การเลือกเครื่องมือและภาษาการเขียนโปรแกรมที่เหมาะสม

ที่มา: https://fastercapital.com/startup-topic/web-scraping.html
- Python : มีชื่อเสียงในด้านความเรียบง่ายและอ่านง่าย Python จึงเป็นที่ชื่นชอบในหมู่ web scraper เนื่องจากมีระบบนิเวศน์ของไลบรารีที่หลากหลาย ซึ่งออกแบบมาเพื่อการแยกและจัดการข้อมูล ความคล่องตัวและความสะดวกในการใช้งานทำให้เหมาะสำหรับผู้เริ่มต้นและผู้เชี่ยวชาญ
- JavaScript : สำหรับเว็บไซต์ที่ต้องอาศัย JavaScript อย่างมากในการโหลดเนื้อหาแบบไดนามิก การใช้ JavaScript (โดยเฉพาะ Node.js) สำหรับการคัดลอกจะเป็นประโยชน์ ไลบรารีเช่น Puppeteer หรือ Cheerio เป็นตัวเลือกยอดนิยมในการคัดลอกเนื้อหาแบบไดนามิกดังกล่าว
- เครื่องมืออื่นๆ : แม้ว่า Python และ JavaScript จะเป็นภาษาที่ใช้บ่อยที่สุดสำหรับการขูดเว็บ แต่เครื่องมืออย่าง R (สำหรับการวิเคราะห์ทางสถิติ) และซอฟต์แวร์อย่าง Octoparse (เครื่องมือขูดเว็บแบบไม่มีโค้ด) ก็สามารถมีคุณค่าได้เช่นกัน ขึ้นอยู่กับความต้องการเฉพาะของคุณ
การขูดเว็บสำหรับข้อมูลราคา
เครื่องมือขูดเว็บสำหรับข้อมูลราคาเป็นงานสำคัญสำหรับธุรกิจที่มุ่งหวังที่จะรักษาความสามารถในการแข่งขันในตลาดของตน ซึ่งเกี่ยวข้องกับการระบุและดึงข้อมูลการกำหนดราคาที่เกี่ยวข้องจากเว็บไซต์ของคู่แข่ง ซึ่งสามารถนำไปใช้ในการวิเคราะห์การแข่งขัน กลยุทธ์การกำหนดราคา และการวิจัยตลาด เมื่อพิจารณาถึงเทคโนโลยีเว็บที่หลากหลายที่ใช้อยู่ในปัจจุบัน การดึงข้อมูลนี้อย่างมีประสิทธิภาพ โดยเฉพาะอย่างยิ่งจากเว็บไซต์ไดนามิกที่โหลดเนื้อหาผ่าน JavaScript ถือเป็นความท้าทายที่ไม่เหมือนใคร ด้านล่างนี้คือเทคนิคและกลยุทธ์ในการดึงข้อมูลการกำหนดราคาอย่างมีประสิทธิภาพ

เทคนิคการระบุและดึงข้อมูลราคาจากหน้าเว็บ
การตรวจสอบโครงสร้างหน้าเว็บ
- ใช้เครื่องมือสำหรับนักพัฒนาเบราว์เซอร์ (ตรวจสอบองค์ประกอบใน Chrome หรือ Firefox) เพื่อตรวจสอบว่าข้อมูลราคามีโครงสร้างและบรรจุอยู่ภายใน HTML ของหน้าอย่างไร
- มองหารูปแบบในโครงสร้าง HTML หรือ URL ที่สามารถช่วยนำทางผ่านรายการผลิตภัณฑ์หรือหมวดหมู่โดยทางโปรแกรม
ตัวเลือก XPath และ CSS
- ใช้ตัวเลือก XPath หรือ CSS เพื่อกำหนดเป้าหมายองค์ประกอบเฉพาะที่มีข้อมูลราคา ตัวเลือกเหล่านี้ช่วยในการระบุตำแหน่งที่แน่นอนของข้อมูลราคาภายในโครงสร้าง DOM ของหน้าเว็บ
- เครื่องมือเช่น XPath Helper (Chrome) หรือ Try XPath (Firefox) สามารถช่วยในการสร้างและทดสอบนิพจน์เหล่านี้ได้
นิพจน์ทั่วไป
- ในบางกรณี โดยเฉพาะอย่างยิ่งเมื่อต้องรับมือกับ HTML ที่มีโครงสร้างไม่ดี นิพจน์ทั่วไป (regex) สามารถใช้เพื่อดึงข้อมูลการกำหนดราคาจากเนื้อหาข้อความของหน้าเว็บได้
- โปรดใช้ความระมัดระวังกับ regex เนื่องจากรูปแบบที่ซับซ้อนมากเกินไปอาจรักษาได้ยาก และอาจนำไปสู่การคัดลอกที่ไม่ถูกต้องหากโครงสร้างของหน้าเว็บเปลี่ยนแปลง
การจัดการเว็บไซต์แบบไดนามิกและข้อมูลที่โหลดผ่าน JavaScript
เว็บไซต์ไดนามิกที่โหลดเนื้อหา รวมถึงข้อมูลราคา ผ่าน JavaScript ก่อให้เกิดความท้าทายที่สำคัญสำหรับเทคนิคการขูดเว็บแบบดั้งเดิมที่จะแยกวิเคราะห์เนื้อหา HTML แบบคงที่เท่านั้น
เบราว์เซอร์หัวขาด
- เครื่องมืออย่าง Puppeteer (สำหรับ Node.js) และ Selenium (สำหรับภาษาการเขียนโปรแกรมหลายภาษา รวมถึง Python) สามารถทำให้เบราว์เซอร์โต้ตอบกับหน้าเว็บได้โดยอัตโนมัติเหมือนกับที่ผู้ใช้ทำ ซึ่งรวมถึงการรอให้ JavaScript โหลดข้อมูลราคาแบบไดนามิก
- เบราว์เซอร์ที่ไม่มีส่วนหัวสามารถนำทาง เลื่อน และแม้แต่โต้ตอบกับองค์ประกอบเว็บเพื่อให้แน่ใจว่าข้อมูลที่เกี่ยวข้องทั้งหมด รวมถึงเนื้อหาที่โหลดแบบไดนามิก จะถูกแสดงผลก่อนที่จะคัดลอก
การเรียก API
- เว็บไซต์ไดนามิกหลายแห่งทำการเรียก API แยกกันเพื่อดึงข้อมูลราคาและข้อมูลอื่นๆ ตรวจสอบการรับส่งข้อมูลเครือข่ายโดยใช้เครื่องมือสำหรับนักพัฒนาเบราว์เซอร์เพื่อระบุการเรียก API เหล่านี้
- การดึงข้อมูลโดยตรงจากตำแหน่งข้อมูล API เหล่านี้มีประสิทธิภาพและเชื่อถือได้มากกว่าการแยกวิเคราะห์เนื้อหา HTML เนื่องจาก API มักจะส่งคืนข้อมูลในรูปแบบที่มีโครงสร้าง เช่น JSON
การจัดการคำขอ AJAX
- สำหรับเนื้อหาที่โหลดผ่าน AJAX จำเป็นต้องมีเครื่องมือที่รองรับการรอให้องค์ประกอบปรากฏหรือตรวจสอบการเปลี่ยนแปลงในโครงสร้างของหน้าเว็บเป็นสิ่งที่จำเป็น ตัวอย่างเช่น ซีลีเนียมเสนอการรอที่ชัดเจนและโดยปริยายเพื่อจัดการ AJAX
- การตรวจสอบคำขอ AJAX ยังสามารถเปิดเผยจุดสิ้นสุด API หรือ URL โดยตรงไปยังข้อมูลราคา โดยไม่ต้องแยกวิเคราะห์ HTML
ตัวอย่างที่แท้จริงของการขูดเว็บที่ประสบความสำเร็จสำหรับข้อมูลราคา
อีคอมเมิร์ซยักษ์ใหญ่ของ Amazon:
- กลยุทธ์ : Amazon ใช้ Web Scraping เพื่อติดตามราคาของคู่แข่งแบบเรียลไทม์ ทำให้พวกเขาสามารถปรับราคาเพื่อให้สามารถแข่งขันได้
- ผลลัพธ์ : กลยุทธ์การกำหนดราคาแบบไดนามิกนี้มีส่วนอย่างมากต่อตำแหน่งของ Amazon ในฐานะผู้นำตลาด ทำให้มั่นใจในความภักดีของลูกค้าผ่านการกำหนดราคาที่แข่งขันได้
- บทเรียน : ความสำคัญของข้อมูลแบบเรียลไทม์ในการใช้กลยุทธ์การกำหนดราคาแบบไดนามิก
แพลตฟอร์มการเดินทาง Booking.com :
- กลยุทธ์ : Booking.com ดึงข้อมูลราคาจากเว็บไซต์โรงแรมและสายการบินทั่วโลกเพื่อเสนอข้อเสนอที่ดีที่สุดแก่ผู้ใช้
- ผลลัพธ์ : เพิ่มความพึงพอใจของผู้ใช้และเพิ่มการจองด้วยราคาที่แข่งขันได้
- บทเรียน : การใช้ประโยชน์จากข้อมูลที่คัดลอกมาเพื่อเพิ่มมูลค่าของผู้ใช้สามารถนำไปสู่ส่วนแบ่งการตลาดที่เพิ่มขึ้นและความภักดีของลูกค้า
เครือข่ายค้าปลีก Walmart :
- กลยุทธ์ : Walmart ใช้ Web Scraping เพื่อตรวจสอบไม่เพียงแต่ราคาเท่านั้น แต่ยังรวมถึงความพร้อมในสต็อกของผลิตภัณฑ์บนเว็บไซต์ของคู่แข่งด้วย
- ผลลัพธ์ : ปรับปรุงการจัดการสินค้าคงคลังและกลยุทธ์การกำหนดราคาที่สอดคล้องกับความคาดหวังของลูกค้า
- บทเรียน : การบูรณาการข้อมูลสินค้าคงคลังเข้ากับกลยุทธ์การกำหนดราคาเพื่อความสามารถในการแข่งขันในตลาดที่ครอบคลุม
สำหรับผู้ที่ต้องการเจาะลึกลงไปในการขูดเว็บและการวิเคราะห์ข้อมูล PromptCloud นำเสนอโซลูชั่นที่หลากหลายที่เหมาะกับความต้องการทางธุรกิจของคุณ ความเชี่ยวชาญและเครื่องมือของเราสามารถช่วยคุณจัดการกับความซับซ้อนของการขูดเว็บ เพื่อให้มั่นใจว่าคุณจะได้รับประโยชน์สูงสุดจากความพยายามของคุณ
สำรวจโซลูชันของ PromptCloud สำหรับการขูดเว็บและการวิเคราะห์ข้อมูลเพื่อเปลี่ยนแปลงกลยุทธ์การกำหนดราคาที่แข่งขันได้และขับเคลื่อนธุรกิจของคุณไปข้างหน้า มาควบคุมพลังของข้อมูลด้วยกัน