
ทำความเข้าใจสถาปัตยกรรม GPU สำหรับการเพิ่มประสิทธิภาพการอนุมาน LLM
เผยแพร่แล้ว: 2024-04-02ข้อมูลเบื้องต้นเกี่ยวกับ LLM และความสำคัญของการเพิ่มประสิทธิภาพ GPU
ในยุคปัจจุบันของความก้าวหน้าในการประมวลผลภาษาธรรมชาติ (NLP) โมเดลภาษาขนาดใหญ่ (LLM) ได้กลายเป็นเครื่องมืออันทรงพลังสำหรับงานมากมาย ตั้งแต่การสร้างข้อความไปจนถึงการตอบคำถามและการสรุป สิ่งเหล่านี้เป็นมากกว่าตัวสร้างโทเค็นที่เป็นไปได้ตัวถัดไป อย่างไรก็ตาม ความซับซ้อนและขนาดที่เพิ่มขึ้นของแบบจำลองเหล่านี้ก่อให้เกิดความท้าทายที่สำคัญในแง่ของประสิทธิภาพและประสิทธิภาพของการคำนวณ
ในบล็อกนี้ เราจะเจาะลึกความซับซ้อนของสถาปัตยกรรม GPU โดยสำรวจว่าส่วนประกอบต่างๆ มีส่วนช่วยในการอนุมาน LLM อย่างไร เราจะหารือเกี่ยวกับตัวชี้วัดประสิทธิภาพที่สำคัญ เช่น แบนด์วิดท์หน่วยความจำและการใช้งานเทนเซอร์คอร์ และอธิบายความแตกต่างระหว่างการ์ด GPU ต่างๆ เพื่อให้คุณตัดสินใจได้อย่างชาญฉลาดเมื่อเลือกฮาร์ดแวร์สำหรับงานโมเดลภาษาขนาดใหญ่ของคุณ
ในสภาพแวดล้อมที่มีการพัฒนาอย่างรวดเร็วซึ่งงาน NLP ต้องการทรัพยากรการคำนวณที่เพิ่มมากขึ้น การเพิ่มประสิทธิภาพปริมาณงานการอนุมาน LLM เป็นสิ่งสำคัญยิ่ง เข้าร่วมกับเราในขณะที่เราเริ่มต้นการเดินทางครั้งนี้เพื่อปลดล็อกศักยภาพสูงสุดของ LLM ผ่านเทคนิคการเพิ่มประสิทธิภาพ GPU และเจาะลึกเครื่องมือต่างๆ ที่ช่วยให้เราสามารถปรับปรุงประสิทธิภาพได้อย่างมีประสิทธิภาพ
สิ่งจำเป็นสำหรับสถาปัตยกรรม GPU สำหรับ LLM – รู้จัก GPU ภายในของคุณ
ด้วยธรรมชาติของการประมวลผลแบบขนานที่มีประสิทธิภาพสูง GPU กลายเป็นอุปกรณ์ที่เลือกใช้ในการทำงานการเรียนรู้เชิงลึกทั้งหมด ดังนั้นจึงเป็นสิ่งสำคัญที่จะต้องเข้าใจภาพรวมระดับสูงของสถาปัตยกรรม GPU เพื่อทำความเข้าใจปัญหาคอขวดที่เกิดขึ้นระหว่างขั้นตอนการอนุมาน แนะนำให้ใช้การ์ด Nvidia เนื่องจาก CUDA (Compute Unified Device Architecture) ซึ่งเป็นแพลตฟอร์มการประมวลผลแบบขนานที่เป็นกรรมสิทธิ์และ API ที่พัฒนาโดย NVIDIA ซึ่งช่วยให้นักพัฒนาสามารถระบุความขนานระดับเธรดในภาษาการเขียนโปรแกรม C ทำให้สามารถเข้าถึงชุดคำสั่งเสมือนของ GPU และแบบขนานได้โดยตรง องค์ประกอบการคำนวณ
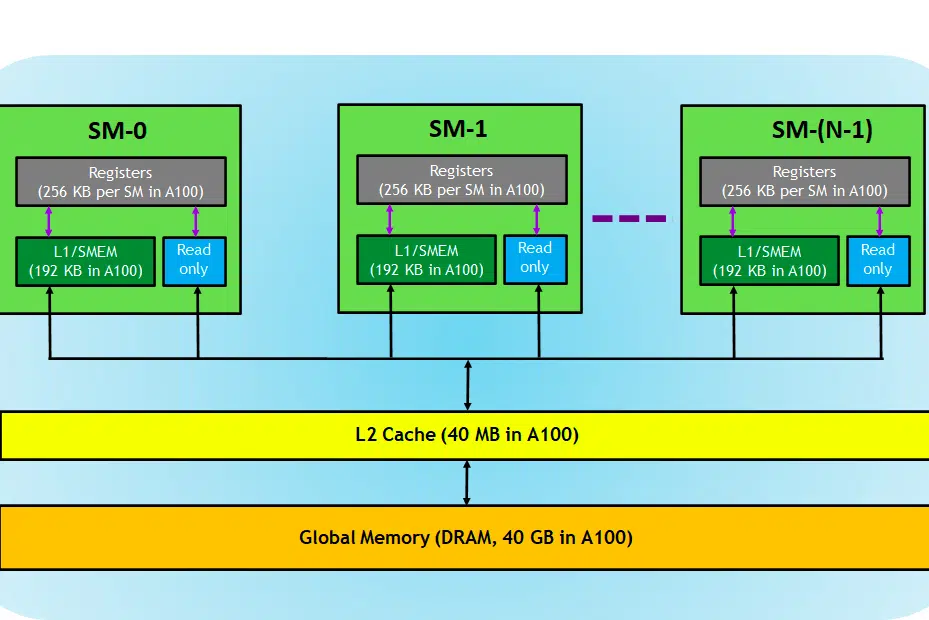
สำหรับบริบท เราใช้การ์ด NVIDIA เพื่ออธิบาย เนื่องจากเป็นที่ต้องการอย่างกว้างขวางสำหรับงาน Deep Learning ตามที่ระบุไว้แล้ว และมีคำศัพท์อื่นๆ อีกสองสามคำ เช่น Tensor Cores ที่สามารถนำมาใช้ได้
มาดูการ์ด GPU กัน ในภาพนี้ เราจะเห็นสามส่วนหลักและ (อีกหนึ่งส่วนหลักที่ซ่อนอยู่) ของอุปกรณ์ GPU
- SM (สตรีมมิ่งมัลติโปรเซสเซอร์)
- แคช L2
- แบนด์วิธหน่วยความจำ
- หน่วยความจำส่วนกลาง (DRAM)
เช่นเดียวกับ CPU-RAM ของคุณที่เล่นร่วมกัน RAM เป็นสถานที่สำหรับเก็บข้อมูล (เช่น หน่วยความจำ) และ CPU สำหรับการประมวลผลงาน (เช่น กระบวนการ) ใน GPU หน่วยความจำทั่วโลกแบนด์วิธสูง (DRAM) จะเก็บน้ำหนักของโมเดล (เช่น LLAMA 7B) ที่โหลดลงในหน่วยความจำ และเมื่อจำเป็น น้ำหนักเหล่านี้จะถูกถ่ายโอนไปยังหน่วยประมวลผล (เช่น โปรเซสเซอร์ SM) เพื่อการคำนวณ
สตรีมมิ่งมัลติโปรเซสเซอร์
มัลติโปรเซสเซอร์สตรีมมิ่งหรือ SM คือชุดของหน่วยประมวลผลขนาดเล็กที่เรียกว่า CUDA cores (แพลตฟอร์มการประมวลผลแบบขนานที่เป็นกรรมสิทธิ์ของ NVIDIA) พร้อมด้วยหน่วยการทำงานเพิ่มเติมที่รับผิดชอบในการดึงคำสั่ง ถอดรหัส กำหนดเวลา และจัดส่ง SM แต่ละตัวทำงานอย่างเป็นอิสระและมีไฟล์รีจิสเตอร์ หน่วยความจำที่ใช้ร่วมกัน แคช L1 และยูนิตพื้นผิวของตัวเอง SM ได้รับการขนานกันอย่างมาก ทำให้สามารถประมวลผลเธรดนับพันพร้อมกันได้ ซึ่งเป็นสิ่งสำคัญสำหรับการบรรลุปริมาณงานสูงในงานประมวลผล GPU โดยทั่วไปประสิทธิภาพของโปรเซสเซอร์จะวัดเป็น FLOPS ซึ่งเป็นหมายเลข ของการดำเนินการแบบลอยตัวก็สามารถทำได้ในแต่ละวินาที
งานการเรียนรู้เชิงลึกส่วนใหญ่ประกอบด้วยการทำงานของเทนเซอร์ เช่น การคูณเมทริกซ์-เมทริกซ์ NVIDIA ได้เปิดตัวเทนเซอร์คอร์ใน GPU รุ่นใหม่ ซึ่งได้รับการออกแบบมาโดยเฉพาะเพื่อดำเนินการเทนเซอร์เหล่านี้ในลักษณะที่มีประสิทธิภาพสูง ดังที่ได้กล่าวไปแล้ว เทนเซอร์คอร์มีประโยชน์เมื่อพูดถึงงานการเรียนรู้เชิงลึก และแทนที่จะเป็นคอร์ CUDA เราต้องตรวจสอบคอร์เทนเซอร์เพื่อพิจารณาว่า GPU สามารถดำเนินการฝึกฝน/อนุมาน LLM ได้อย่างมีประสิทธิภาพเพียงใด
แคช L2
แคช L2 เป็นหน่วยความจำแบนด์วิธสูงที่ใช้ร่วมกันระหว่าง SM โดยมีจุดประสงค์เพื่อเพิ่มประสิทธิภาพการเข้าถึงหน่วยความจำและประสิทธิภาพการถ่ายโอนข้อมูลภายในระบบ เป็นหน่วยความจำประเภทที่เล็กกว่าและเร็วกว่าซึ่งอยู่ใกล้กับหน่วยประมวลผลมากกว่า (เช่น มัลติโปรเซสเซอร์แบบสตรีมมิ่ง) เมื่อเทียบกับ DRAM ช่วยปรับปรุงประสิทธิภาพการเข้าถึงหน่วยความจำโดยรวมโดยลดความจำเป็นในการเข้าถึง DRAM ที่ช้ากว่าสำหรับทุกคำขอหน่วยความจำ
แบนด์วิธหน่วยความจำ
ดังนั้น ประสิทธิภาพจึงขึ้นอยู่กับความเร็วที่เราสามารถถ่ายโอนน้ำหนักจากหน่วยความจำไปยังโปรเซสเซอร์ และความรวดเร็วที่โปรเซสเซอร์สามารถประมวลผลการคำนวณที่กำหนดได้
เมื่อความสามารถในการคำนวณสูง/เร็วกว่าอัตราการถ่ายโอนข้อมูลระหว่างหน่วยความจำไปยัง SM SM จะอดอาหารสำหรับข้อมูลที่จะประมวลผลและทำให้การประมวลผลมีการใช้งานน้อยเกินไป สถานการณ์ที่แบนด์วิดท์หน่วยความจำต่ำกว่าอัตราการใช้นี้เรียกว่าเฟส ที่ผูกกับหน่วยความจำ . นี่เป็นสิ่งสำคัญมากที่ควรทราบเนื่องจากนี่คือปัญหาคอขวดที่เกิดขึ้นในกระบวนการอนุมาน
ในทางตรงกันข้าม หากการประมวลผลใช้เวลาในการประมวลผลมากขึ้น และหากมีข้อมูลเข้าคิวสำหรับการคำนวณมากขึ้น สถานะนี้จะเข้าสู่ขั้นตอน ที่เกี่ยวข้องกับการประมวลผล
เพื่อใช้ประโยชน์จาก GPU ได้อย่างเต็มที่ เราต้องอยู่ในสถานะที่ถูกผูกไว้กับการประมวลผล ขณะเดียวกันก็ทำให้การคำนวณที่เกิดขึ้นมีประสิทธิภาพมากที่สุดเท่าที่จะเป็นไปได้
หน่วยความจำ DRAM
DRAM ทำหน้าที่เป็นหน่วยความจำหลักใน GPU ซึ่งเป็นแหล่งหน่วยความจำขนาดใหญ่สำหรับการจัดเก็บข้อมูลและคำแนะนำที่จำเป็นสำหรับการคำนวณ โดยทั่วไปจะจัดอยู่ในลำดับชั้น โดยมีธนาคารหน่วยความจำหลายช่องและช่องสัญญาณเพื่อให้สามารถเข้าถึงความเร็วสูงได้

สำหรับงานอนุมาน DRAM ของ GPU จะกำหนดขนาดของโมเดลที่เราสามารถโหลดได้ และ FLOPS การประมวลผลและแบนด์วิดท์จะกำหนดปริมาณงานที่เราสามารถรับได้
การเปรียบเทียบการ์ด GPU สำหรับงาน LLM
หากต้องการรับข้อมูลเกี่ยวกับจำนวนเทนเซอร์คอร์ ความเร็วแบนด์วิดท์ คุณสามารถดูเอกสารไวท์เปเปอร์ที่ออกโดยผู้ผลิต GPU ได้ นี่คือตัวอย่าง
| RTX A6000 | RTX4090 | RTX3090 | |
| ขนาดหน่วยความจำ | 48 กิกะไบต์ | 24GB | 24GB |
| ประเภทหน่วยความจำ | GDDR6 | GDDR6X | |
| แบนด์วิธ | 768.0 กิกะไบต์/วินาที | 1,008GB/วินาที | 936.2 กิกะไบต์/วินาที |
| CUDA แกน / GPU | 10752 | 16384 | 10496 |
| แกนเทนเซอร์ | 336 | 512 | 328 |
| แคช L1 | 128 KB (ต่อ SM) | 128 KB (ต่อ SM) | 128 KB (ต่อ SM) |
| FP16 ไม่ใช่เทนเซอร์ | 38.71 ทีฟล็อปส์ (1:1) | 82.6 | 35.58 ทีฟล็อปส์ (1:1) |
| FP32 ไม่ใช่เทนเซอร์ | 38.71 ทีฟล็อปส์ | 82.6 | 35.58 ทีฟล็อปส์ |
| FP64 ไม่ใช่เทนเซอร์ | 1,210 GFLOPS (1:32) | 556.0 GFLOPS (1:64) | |
| จุดสูงสุดของ FP16 Tensor TFLOPS พร้อม FP16 สะสม | 154.8/309.6 | 330.3/660.6 | 142/284 |
| จุดสูงสุดของ FP16 Tensor TFLOPS พร้อม FP32 สะสม | 154.8/309.6 | 165.2/330.4 | 71/142 |
| พีค BF16 เทนเซอร์ TFLOPS พร้อม FP32 | 154.8/309.6 | 165.2/330.4 | 71/142 |
| พีค TF32 เทนเซอร์ TFLOPS | 77.4/154.8 | 82.6/165.2 | 35.6/71 |
| พีค INT8 Tensor TOPS | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| พีค INT4 Tensor TOPS | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| แคช L2 | 6 เมกะไบต์ | 72 เมกะไบต์ | 6 เมกะไบต์ |
| เมมโมรี่บัส | 384 บิต | 384 บิต | 384 บิต |
| TMU | 336 | 512 | 328 |
| รปส | 112 | 176 | 112 |
| เคานต์เอสเอ็ม | 84 | 128 | 82 |
| RT แกน | 84 | 128 | 82 |
ที่นี่เราจะเห็นว่า FLOPS ได้รับการกล่าวถึงเป็นพิเศษสำหรับการทำงานของ Tensor ข้อมูลนี้จะช่วยให้เราเปรียบเทียบการ์ด GPU ต่างๆ และคัดเลือกการ์ดที่เหมาะสมสำหรับกรณีการใช้งานของเรา จากตาราง แม้ว่า A6000 จะมีหน่วยความจำเป็นสองเท่าของ 4090 แต่เทนเซอร์ฟล็อปและแบนด์วิธหน่วยความจำ 4090 ก็มีตัวเลขที่ดีกว่า และมีประสิทธิภาพมากกว่าสำหรับการอนุมานโมเดลภาษาขนาดใหญ่
อ่านเพิ่มเติม: Nvidia CUDA ใน 100 วินาที
บทสรุป
ในสาขาที่ก้าวหน้าอย่างรวดเร็วของ NLP การเพิ่มประสิทธิภาพของ Large Language Models (LLM) สำหรับงานอนุมานได้กลายเป็นประเด็นสำคัญที่ต้องมุ่งเน้น ตามที่เราได้สำรวจไปแล้ว สถาปัตยกรรมของ GPU มีบทบาทสำคัญในการบรรลุประสิทธิภาพและประสิทธิผลสูงในงานเหล่านี้ การทำความเข้าใจส่วนประกอบภายในของ GPU เช่น Streaming Multiprocessors (SM), แคช L2, แบนด์วิดท์หน่วยความจำ และ DRAM ถือเป็นสิ่งสำคัญสำหรับการระบุปัญหาคอขวดที่อาจเกิดขึ้นในกระบวนการอนุมาน LLM
การเปรียบเทียบระหว่างการ์ด NVIDIA GPU ต่างๆ ได้แก่ RTX A6000, RTX 4090 และ RTX 3090 เผยให้เห็นความแตกต่างที่สำคัญในแง่ของขนาดหน่วยความจำ แบนด์วิดท์ และจำนวน CUDA และ Tensor Cores ท่ามกลางปัจจัยอื่นๆ ความแตกต่างเหล่านี้มีความสำคัญอย่างยิ่งต่อการตัดสินใจโดยอาศัยข้อมูลว่า GPU ตัวใดเหมาะสมที่สุดสำหรับงาน LLM เฉพาะด้าน ตัวอย่างเช่น แม้ว่า RTX A6000 จะให้ขนาดหน่วยความจำที่ใหญ่กว่า แต่ RTX 4090 ก็เหนือกว่าในแง่ของ Tensor FLOPS และแบนด์วิธหน่วยความจำ ทำให้เป็นตัวเลือกที่มีศักยภาพมากขึ้นสำหรับงานอนุมาน LLM ที่มีความต้องการสูง
การเพิ่มประสิทธิภาพการอนุมาน LLM ต้องใช้แนวทางที่สมดุล โดยพิจารณาทั้งความสามารถในการคำนวณของ GPU และข้อกำหนดเฉพาะของงาน LLM ที่มีอยู่ การเลือก GPU ที่เหมาะสมเกี่ยวข้องกับการทำความเข้าใจการแลกเปลี่ยนระหว่างความจุหน่วยความจำ พลังการประมวลผล และแบนด์วิดท์ เพื่อให้แน่ใจว่า GPU สามารถรองรับน้ำหนักของโมเดลได้อย่างมีประสิทธิภาพ และทำการคำนวณโดยไม่กลายเป็นคอขวด ในขณะที่สาขา NLP มีการพัฒนาอย่างต่อเนื่อง การรับทราบข้อมูลเกี่ยวกับเทคโนโลยี GPU ล่าสุดและความสามารถของพวกเขาจะเป็นสิ่งสำคัญยิ่งสำหรับผู้ที่ต้องการก้าวข้ามขอบเขตของสิ่งที่เป็นไปได้ด้วยโมเดลภาษาขนาดใหญ่
คำศัพท์ที่ใช้
- ปริมาณงาน:
ในกรณีที่เป็นการอนุมาน ปริมาณงานคือการวัดจำนวนคำขอ/พร้อมต์ที่ได้รับการประมวลผลในช่วงเวลาที่กำหนด โดยทั่วไปปริมาณงานจะวัดได้สองวิธี:
- คำขอต่อวินาที (RPS) :
- RPS วัดจำนวนคำขออนุมานที่โมเดลสามารถจัดการได้ภายในไม่กี่วินาที โดยทั่วไปคำขออนุมานจะเกี่ยวข้องกับการสร้างการตอบสนองหรือการคาดคะเนตามข้อมูลอินพุต
- สำหรับการสร้าง LLM นั้น RPS จะระบุว่าโมเดลสามารถตอบสนองข้อความแจ้งหรือคำค้นหาที่เข้ามาได้เร็วเพียงใด ค่า RPS ที่สูงขึ้นบ่งบอกถึงการตอบสนองและความสามารถในการปรับขนาดที่ดีขึ้นสำหรับแอปพลิเคชันแบบเรียลไทม์หรือใกล้เคียงเรียลไทม์
- การบรรลุค่า RPS ที่สูงมักต้องใช้กลยุทธ์การปรับใช้ที่มีประสิทธิภาพ เช่น การรวมคำขอหลายรายการเข้าด้วยกันเพื่อตัดค่าใช้จ่ายและเพิ่มการใช้ทรัพยากรการคำนวณให้เกิดประโยชน์สูงสุด
- โทเค็นต่อวินาที (TPS) :
- TPS วัดความเร็วที่โมเดลสามารถประมวลผลและสร้างโทเค็น (คำหรือคำย่อย) ในระหว่างการสร้างข้อความ
- ในบริบทของการสร้าง LLM นั้น TPS สะท้อนถึงปริมาณงานของโมเดลในแง่ของการสร้างข้อความ โดยจะบ่งชี้ว่าแบบจำลองสามารถสร้างการตอบสนองที่สอดคล้องกันและมีความหมายได้เร็วเพียงใด
- ค่า TPS ที่สูงขึ้นหมายถึงการสร้างข้อความที่เร็วขึ้น ทำให้โมเดลสามารถประมวลผลข้อมูลที่ป้อนเข้าได้มากขึ้น และสร้างการตอบสนองที่นานขึ้นในระยะเวลาที่กำหนด
- การบรรลุค่า TPS ที่สูงมักเกี่ยวข้องกับการปรับสถาปัตยกรรมโมเดลให้เหมาะสม การคำนวณแบบขนาน และการใช้ประโยชน์จากตัวเร่งฮาร์ดแวร์ เช่น GPU เพื่อเร่งการสร้างโทเค็น
- เวลาแฝง:
เวลาแฝงใน LLM หมายถึงการหน่วงเวลาระหว่างอินพุตและเอาต์พุตระหว่างการอนุมาน การลดเวลาแฝงให้เหลือน้อยที่สุดถือเป็นสิ่งสำคัญในการปรับปรุงประสบการณ์ผู้ใช้และเปิดใช้งานการโต้ตอบแบบเรียลไทม์ในแอปพลิเคชันที่ใช้ประโยชน์จาก LLM จำเป็นอย่างยิ่งที่จะต้องรักษาสมดุลระหว่างปริมาณงานและเวลาแฝงโดยพิจารณาจากบริการที่เราต้องการมอบให้ เวลาแฝงต่ำเป็นที่ต้องการสำหรับกรณีเช่นแชทบอท/โคไพล็อตที่มีการโต้ตอบแบบเรียลไทม์ แต่ไม่จำเป็นสำหรับกรณีการประมวลผลข้อมูลจำนวนมาก เช่น การประมวลผลข้อมูลภายในใหม่
อ่านเพิ่มเติมเกี่ยวกับเทคนิคขั้นสูงในการเพิ่มปริมาณงาน LLM ที่นี่