
ปลดล็อกศักยภาพของ AI ในการขูดเว็บไซต์: ภาพรวม
เผยแพร่แล้ว: 2024-02-02การขูดเว็บในปัจจุบันได้เปลี่ยนจากกิจกรรมการเขียนโปรแกรมเฉพาะไปสู่เครื่องมือทางธุรกิจที่จำเป็น ในตอนแรก การขูดเป็นกระบวนการที่ดำเนินการด้วยตนเอง โดยแต่ละบุคคลจะคัดลอกข้อมูลจากหน้าเว็บ วิวัฒนาการของเทคโนโลยีทำให้เกิดสคริปต์อัตโนมัติที่สามารถดึงข้อมูลได้อย่างมีประสิทธิภาพมากขึ้นแม้ว่าจะหยาบก็ตาม
เมื่อเว็บไซต์ก้าวหน้ามากขึ้น เทคนิคการขูดก็ก้าวหน้าเช่นกัน โดยปรับให้เข้ากับโครงสร้างที่ซับซ้อนและต่อต้านมาตรการป้องกันการขูด ความก้าวหน้าใน AI และการเรียนรู้ของเครื่องได้ขับเคลื่อนการขูดเว็บไปสู่ดินแดนที่ไม่คุ้นเคย ทำให้สามารถเข้าใจบริบทและแนวทางที่ปรับเปลี่ยนได้ซึ่งเลียนแบบพฤติกรรมการท่องเว็บของมนุษย์ ความก้าวหน้าอย่างต่อเนื่องนี้กำหนดวิธีที่องค์กรต่างๆ ควบคุมข้อมูลเว็บในวงกว้างและมีความซับซ้อนอย่างที่ไม่เคยมีมาก่อน
การเกิดขึ้นของ AI ใน Web Scraping

ที่มาของภาพ: https://www.scrapehero.com/
ผลกระทบของปัญญาประดิษฐ์ (AI) ต่อการขูดเว็บไม่สามารถกล่าวเกินจริงได้ มันได้เปลี่ยนภูมิทัศน์ไปอย่างสิ้นเชิง ทำให้กระบวนการมีประสิทธิภาพมากขึ้น หมดยุคของการกำหนดค่าด้วยตนเองที่ต้องใช้ความพยายามและความระมัดระวังอย่างต่อเนื่องเพื่อปรับให้เข้ากับโครงสร้างเว็บไซต์ที่เปลี่ยนแปลงไป
ต้องขอบคุณ AI ที่ทำให้เว็บสแครปเปอร์ได้พัฒนาเป็นเครื่องมือที่ใช้งานง่ายซึ่งสามารถเรียนรู้จากรูปแบบและปรับตามการเปลี่ยนแปลงโครงสร้างโดยอัตโนมัติโดยไม่ต้องมีการควบคุมดูแลจากมนุษย์ตลอดเวลา ซึ่งหมายความว่าพวกเขาสามารถเข้าใจบริบทของข้อมูล แยกแยะสิ่งที่เกี่ยวข้องด้วยความแม่นยำที่น่าทึ่ง และละทิ้งสิ่งที่ไม่เกี่ยวข้องไว้เบื้องหลัง
วิธีการที่ชาญฉลาดและยืดหยุ่นมากขึ้นนี้ได้เปลี่ยนกระบวนการดึงข้อมูล ทำให้อุตสาหกรรมมีเครื่องมือในการตัดสินใจโดยใช้ข้อมูลที่ดีขึ้นโดยอิงจากคุณภาพข้อมูลที่ยอดเยี่ยม ในขณะที่เทคโนโลยี AI ก้าวหน้า การรวม AI เข้ากับเครื่องมือขูดเว็บก็พร้อมที่จะสร้างมาตรฐานใหม่ โดยเปลี่ยนแปลงพื้นฐานหลักในการรวบรวมข้อมูลจากเว็บ
ข้อพิจารณาด้านจริยธรรมและกฎหมายในการขูดเว็บสมัยใหม่
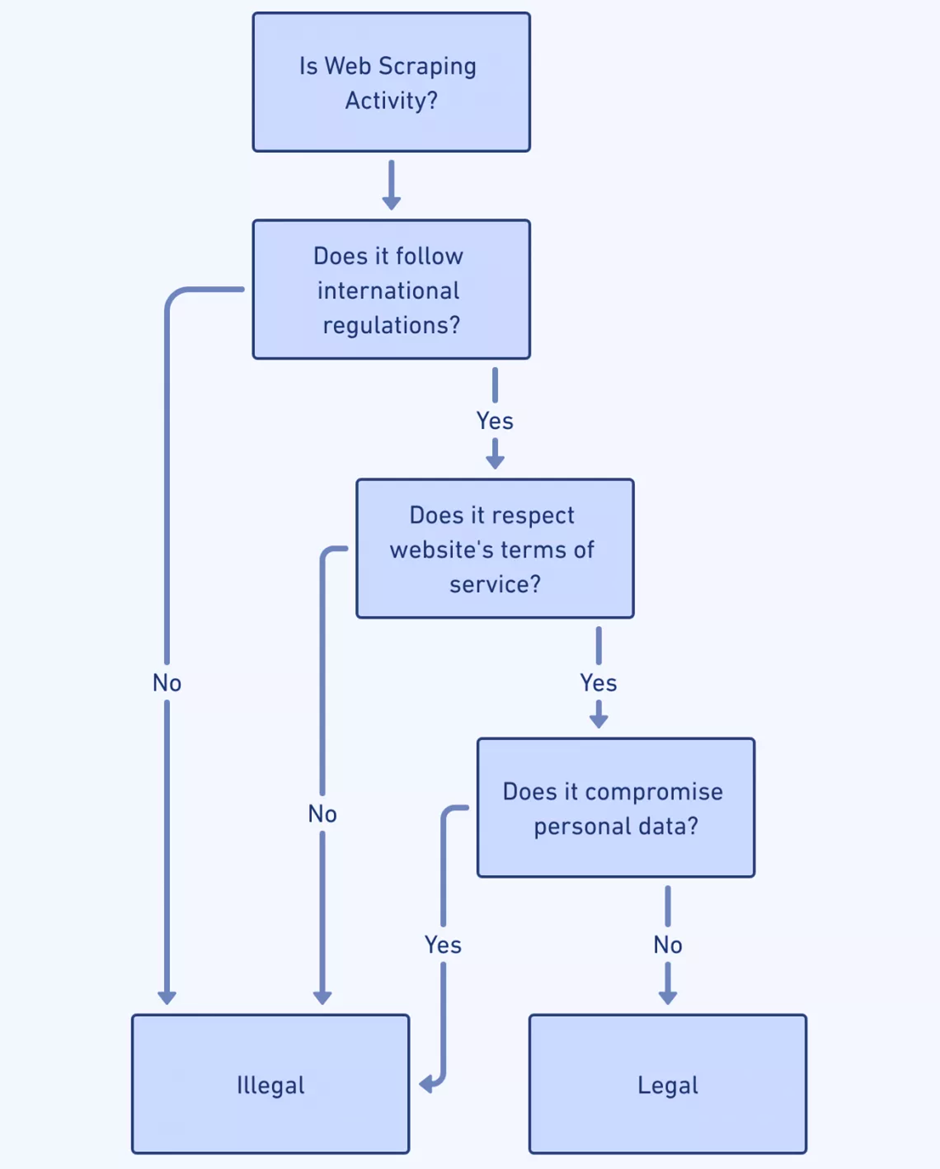
เนื่องจากการขูดเว็บพัฒนาไปพร้อมกับความก้าวหน้าของ AI ผลกระทบด้านจริยธรรมและกฎหมายจึงมีความซับซ้อนมากขึ้น เครื่องขูดเว็บจะต้องนำทาง:
- กฎหมายความเป็นส่วนตัวของข้อมูล : นักพัฒนา Scraper ควรเข้าใจกฎหมายเช่น GDPR และ CCPA เพื่อหลีกเลี่ยงการละเมิดกฎหมายที่เกี่ยวข้องกับข้อมูลส่วนบุคคล
- การปฏิบัติตามข้อกำหนดในการให้บริการ : การเคารพข้อกำหนดในการให้บริการของเว็บไซต์เป็นสิ่งสำคัญ การขูดที่ขัดต่อสิ่งเหล่านี้อาจนำไปสู่การดำเนินคดีหรือการปฏิเสธการเข้าถึง
- เนื้อหาที่มีลิขสิทธิ์ : เนื้อหาที่ได้รับจะต้องไม่ละเมิดลิขสิทธิ์ ทำให้เกิดความกังวลเกี่ยวกับการเผยแพร่และการใช้ข้อมูลที่คัดลอกมา
- มาตรฐานการยกเว้นโรบ็อต : การปฏิบัติตามไฟล์ robots.txt ของเว็บไซต์บ่งบอกถึงการดำเนินการตามหลักจริยธรรมโดยการเคารพการตั้งค่าการคัดลอกของเจ้าของไซต์
- ความยินยอมของผู้ใช้ : เมื่อข้อมูลส่วนบุคคลมีส่วนเกี่ยวข้อง การตรวจสอบให้แน่ใจว่าได้รับความยินยอมจากผู้ใช้จะรักษาความสมบูรณ์ทางจริยธรรม
- ความโปร่งใส : การสื่อสารที่ชัดเจนเกี่ยวกับเจตนาและขอบเขตของการดำเนินการขูดจะส่งเสริมสภาพแวดล้อมของความไว้วางใจและความรับผิดชอบ
ที่มาของภาพ: https://scrape-it.cloud/
การนำข้อพิจารณาเหล่านี้ไปใช้ต้องอาศัยความระมัดระวังและความมุ่งมั่นต่อหลักปฏิบัติด้านจริยธรรม

ความก้าวหน้าในอัลกอริทึม AI สำหรับการดึงข้อมูลที่ได้รับการปรับปรุง
เมื่อเร็วๆ นี้ เราได้สังเกตเห็นวิวัฒนาการที่โดดเด่นในอัลกอริธึม AI ซึ่งได้เปลี่ยนโฉมภูมิทัศน์ของความสามารถในการดึงข้อมูลอย่างมีนัยสำคัญ โมเดลแมชชีนเลิร์นนิงขั้นสูง ซึ่งแสดงให้เห็นถึงความสามารถในการถอดรหัสรูปแบบที่ซับซ้อนได้ดีขึ้น ได้ยกระดับความแม่นยำในการดึงข้อมูลไปสู่ระดับที่ไม่เคยมีมาก่อน
ความก้าวหน้าในการประมวลผลภาษาธรรมชาติ (NLP) ทำให้มีความเข้าใจบริบทที่ลึกซึ้งยิ่งขึ้น ไม่เพียงแต่อำนวยความสะดวกในการดึงข้อมูลที่เกี่ยวข้องเท่านั้น แต่ยังช่วยให้สามารถตีความความแตกต่างและความรู้สึกทางความหมายที่ละเอียดอ่อนได้อีกด้วย
การเกิดขึ้นของโครงข่ายประสาทเทียม โดยเฉพาะโครงข่ายประสาทเทียมแบบ Convolutional Neural Networks (CNN) ได้จุดประกายให้เกิดการปฏิวัติในการดึงข้อมูลภาพ ความก้าวหน้าครั้งนี้ช่วยให้ปัญญาประดิษฐ์ไม่เพียงแต่จดจำเท่านั้น แต่ยังช่วยจัดประเภทเนื้อหาภาพที่มาจากอินเทอร์เน็ตอันกว้างใหญ่อีกด้วย
นอกจากนี้ Reinforcement Learning (RL) ยังได้นำเสนอกระบวนทัศน์ใหม่ ซึ่งเครื่องมือ AI จะปรับแต่งกลยุทธ์การขูดที่เหมาะสมที่สุดเมื่อเวลาผ่านไป ซึ่งจะช่วยเพิ่มประสิทธิภาพในการดำเนินงาน การรวมอัลกอริธึมเหล่านี้เข้ากับเครื่องมือขูดเว็บส่งผลให้:
- การตีความและการวิเคราะห์ข้อมูลที่ซับซ้อน
- ปรับปรุงความสามารถในการปรับตัวให้เข้ากับโครงสร้างเว็บที่หลากหลาย
- ลดความจำเป็นในการแทรกแซงของมนุษย์สำหรับงานที่ซับซ้อน
- เพิ่มประสิทธิภาพในการจัดการการแยกข้อมูลขนาดใหญ่
การเอาชนะอุปสรรค: CAPTCHA เนื้อหาแบบไดนามิก และคุณภาพข้อมูล
เทคโนโลยีการขูดเว็บต้องผ่านอุปสรรคหลายประการ:
- CAPTCHA : เครื่องมือขูดเว็บไซต์ AI กำลังใช้อัลกอริธึมการจดจำรูปภาพขั้นสูงและการเรียนรู้ของเครื่องเพื่อแก้ไข CAPTCHA ด้วยความแม่นยำสูงกว่า ทำให้สามารถเข้าถึงได้โดยไม่ต้องมีการแทรกแซงของมนุษย์
- เนื้อหาแบบไดนามิก : เครื่องมือขูดเว็บไซต์ AI ได้รับการออกแบบมาเพื่อตีความ JavaScript และ AJAX ที่สร้างเนื้อหาแบบไดนามิก ทำให้มั่นใจได้ว่าข้อมูลจะถูกบันทึกจากแอปพลิเคชันเว็บอย่างมีประสิทธิภาพพอๆ กับจากเพจคงที่

ที่มาของภาพ: PromptCloud
- คุณภาพของข้อมูล : การนำ AI มาใช้ทำให้เกิดการปรับปรุงในการระบุและจำแนกข้อมูล ทั้งนี้เพื่อให้แน่ใจว่าข้อมูลที่รวบรวมมีความเกี่ยวข้องและมีคุณภาพสูง ซึ่งช่วยลดความจำเป็นในการทำความสะอาดและการตรวจสอบด้วยตนเอง เครื่องมือขูดเว็บไซต์ AI เรียนรู้อย่างต่อเนื่องเพื่อแยกแยะระหว่างสัญญาณรบกวนและข้อมูลอันมีค่า และปรับปรุงกระบวนการแยกข้อมูล
การผสมผสานของ AI กับการวิเคราะห์ข้อมูลขนาดใหญ่ใน Web Scraping
การบูรณาการปัญญาประดิษฐ์ (AI) เข้ากับการวิเคราะห์ข้อมูลขนาดใหญ่แสดงให้เห็นถึงการเปลี่ยนแปลงแบบก้าวกระโดดไปข้างหน้าในการขูดเว็บ ในการบูรณาการนี้:
- มีการใช้อัลกอริธึม AI เพื่อตีความและวิเคราะห์ชุดข้อมูลจำนวนมหาศาลที่ควบคุมผ่านการขูด เพื่อให้ได้ข้อมูลเชิงลึกด้วยความเร็วที่ไม่เคยมีมาก่อน
- องค์ประกอบการเรียนรู้ของเครื่องภายใน AI สามารถเพิ่มประสิทธิภาพการดึงข้อมูล การเรียนรู้เพื่อระบุและคาดการณ์รูปแบบและข้อมูลได้อย่างมีประสิทธิภาพ
- การวิเคราะห์ข้อมูลขนาดใหญ่สามารถประมวลผลข้อมูลนี้ ทำให้ธุรกิจต่างๆ ได้รับข้อมูลอัจฉริยะที่สามารถนำไปปฏิบัติได้
- นอกจากนี้ AI ยังช่วยในการทำความสะอาดและจัดโครงสร้างข้อมูล ซึ่งเป็นขั้นตอนสำคัญในการใช้ประโยชน์จากการวิเคราะห์ Big Data อย่างมีประสิทธิภาพ
- การทำงานร่วมกันระหว่าง AI และการวิเคราะห์ข้อมูลขนาดใหญ่ในการขูดเว็บมีความสำคัญอย่างยิ่งต่อการตัดสินใจที่คำนึงถึงเวลาและการรักษาความได้เปรียบทางการแข่งขัน
ภูมิทัศน์แห่งอนาคต: การคาดการณ์และศักยภาพสำหรับผู้ขูดเว็บไซต์ AI
ขอบเขตของการขูดเว็บไซต์ด้วย AI อยู่ที่เกณฑ์สำคัญของการเปลี่ยนแปลง การคาดการณ์ชี้ไปที่:
- ความสามารถด้านการรับรู้ที่เพิ่มขึ้น ช่วยให้เครื่องขูดสามารถตีความข้อมูลที่ซับซ้อนด้วยความเข้าใจแบบมนุษย์
- การบูรณาการกับเทคโนโลยี AI อื่นๆ เช่น การประมวลผลภาษาธรรมชาติ เพื่อการดึงข้อมูลที่เหมาะสมยิ่งขึ้น
- เครื่องขูดแบบเรียนรู้ด้วยตนเองที่ปรับแต่งวิธีการตามอัตราความสำเร็จ ทำให้เกิดโปรโตคอลการเก็บเกี่ยวข้อมูลที่มีประสิทธิภาพมากขึ้น
- การยึดมั่นในมาตรฐานด้านจริยธรรมและกฎหมายมากขึ้นผ่านอัลกอริธึมการปฏิบัติตามข้อกำหนดขั้นสูง
- การทำงานร่วมกันระหว่างเครื่องขูด AI และเทคโนโลยีบล็อกเชนเพื่อการทำธุรกรรมข้อมูลที่ปลอดภัยและโปร่งใส
ติดต่อเราวันนี้ที่ [email protected] เพื่อค้นหาว่าเทคโนโลยีขูดเว็บไซต์ AI ที่ล้ำสมัยของเราสามารถปฏิวัติกระบวนการแยกข้อมูลของคุณและขับเคลื่อนองค์กรของคุณไปสู่ระดับใหม่ได้อย่างไร!