
วิธีอัปโหลดข้อมูลไปยัง BigQuery ด้วย R และ Python
เผยแพร่แล้ว: 2023-06-06โลกของการวิเคราะห์เว็บยังคงดำเนินต่อไปในวันที่ 1 กรกฎาคมอันเป็นโชคชะตา เมื่อ Universal Analytics หยุดประมวลผลข้อมูลและถูกแทนที่ด้วย Google Analytics 4 (GA4) การเปลี่ยนแปลงที่สำคัญประการหนึ่งคือใน GA4 คุณสามารถเก็บข้อมูลในแพลตฟอร์มได้สูงสุด 14 เดือนเท่านั้น นี่เป็นการเปลี่ยนแปลงครั้งสำคัญจาก UA แต่ในทางกลับกัน คุณสามารถพุชข้อมูล GA4 ไปยัง BigQuery ได้ฟรีจนถึงขีดจำกัด
BigQuery เป็นทรัพยากรที่มีประโยชน์อย่างมากสำหรับการจัดเก็บข้อมูลนอกเหนือไปจาก GA4 เมื่อมันมีความสำคัญมากขึ้นกว่าเดิมในอีกไม่กี่เดือน จึงเป็นเวลาที่ดีที่จะเริ่มใช้มันสำหรับทุกความต้องการในการจัดเก็บข้อมูลของคุณ บ่อยครั้ง การจัดการข้อมูลในทางใดทางหนึ่งจะดีกว่าก่อนที่จะอัปโหลด สำหรับสิ่งนี้ เราแนะนำให้ใช้สคริปต์ที่เขียนด้วย R หรือ Python โดยเฉพาะอย่างยิ่งหากจำเป็นต้องทำการปรับเปลี่ยนในลักษณะนี้ซ้ำๆ คุณยังสามารถอัปโหลดข้อมูลไปยัง BigQuery ได้โดยตรงจากสคริปต์เหล่านี้ และนั่นคือสิ่งที่บล็อกนี้จะแนะนำคุณ
การอัปโหลดไปยัง BigQuery จาก R
R เป็นภาษาที่มีประสิทธิภาพอย่างยิ่งสำหรับวิทยาการข้อมูลและเป็นภาษาที่ง่ายที่สุดในการอัปโหลดข้อมูลไปยัง BigQuery ขั้นตอนแรกคือการนำเข้าไลบรารีที่จำเป็นทั้งหมด สำหรับบทช่วยสอนนี้ เราจำเป็นต้องมีไลบรารีต่อไปนี้:
library(googleAuthR)
library(bigQueryR)
หากคุณไม่เคยใช้ไลบรารีเหล่านี้มาก่อน ให้รัน install.packages(<PACKAGE NAME>) ในคอนโซลเพื่อติดตั้ง
ต่อไป เราต้องจัดการกับสิ่งที่มักจะยุ่งยากที่สุดและมักเป็นส่วนที่น่าหงุดหงิดที่สุดในการทำงานกับ API นั่นก็คือการอนุญาต โชคดีที่ R ทำได้ค่อนข้างง่าย คุณจะต้องมีไฟล์ JSON ที่มีข้อมูลรับรองการให้สิทธิ์ สามารถพบได้ใน Google Cloud Console ซึ่งเป็นที่เดียวกับที่ตั้งของ BigQuery ก่อนอื่น ไปที่ Google Cloud Console แล้วคลิก 'API and Services'
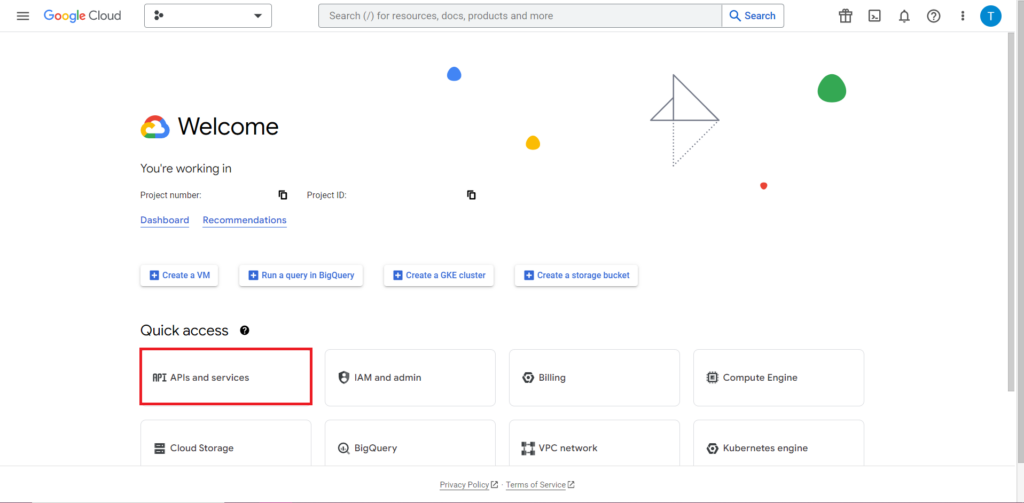
ถัดไป คลิก 'ข้อมูลประจำตัว' ในแถบด้านข้าง
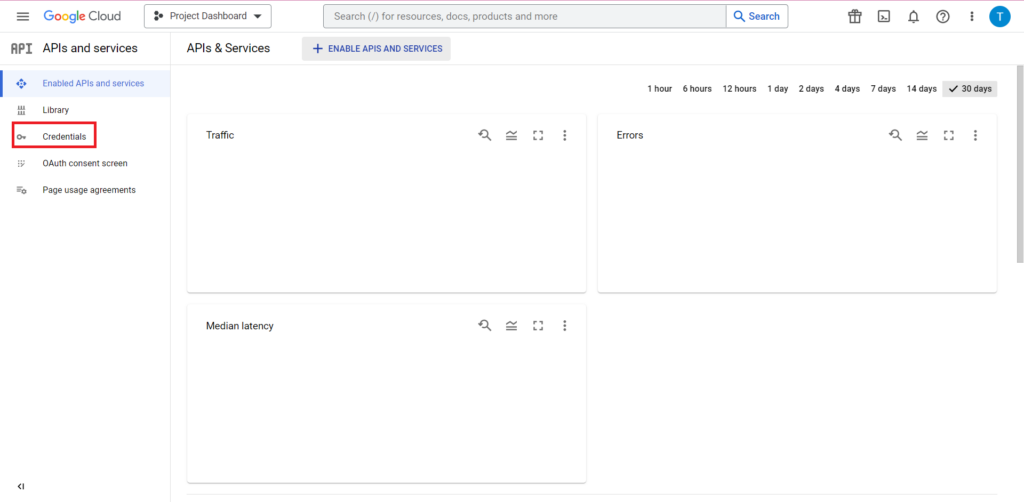
ในหน้าข้อมูลประจำตัว คุณสามารถดูคีย์ API ที่มีอยู่ รหัสลูกค้า OAuth 2.0 และบัญชีบริการ คุณต้องใช้รหัสไคลเอ็นต์ OAuth 2.0 สำหรับสิ่งนี้ ดังนั้นให้กดปุ่มดาวน์โหลดที่ส่วนท้ายสุดของแถวที่เกี่ยวข้องสำหรับรหัสของคุณ หรือสร้างรหัสใหม่โดยคลิก 'สร้างข้อมูลประจำตัว' ที่ด้านบนของหน้า ตรวจสอบว่า ID ของคุณมีสิทธิ์ดูและแก้ไขโครงการ BigQuery ที่เกี่ยวข้อง โดยเปิดแถบด้านข้าง วางเมาส์เหนือ "IAM และผู้ดูแลระบบ" แล้วคลิก "IAM" ในหน้านี้ คุณสามารถให้สิทธิ์บัญชีบริการของคุณในการเข้าถึงโครงการที่เกี่ยวข้องได้โดยใช้ปุ่ม 'ให้สิทธิ์' ที่ด้านบนของหน้า
เมื่อได้รับและบันทึกไฟล์ JSON แล้ว คุณสามารถส่งเส้นทางไปยังไฟล์นั้นด้วยฟังก์ชัน gar_set_client() เพื่อตั้งค่าข้อมูลรับรองของคุณ รหัสเต็มสำหรับการอนุญาตอยู่ด้านล่าง:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
แน่นอน คุณจะต้องแทนที่เส้นทางในฟังก์ชัน gar_set_client() ด้วยเส้นทางไปยังไฟล์ JSON ของคุณเอง และใส่ที่อยู่อีเมลที่คุณใช้เพื่อเข้าถึง BigQuery ลงในฟังก์ชัน bqr_auth()
เมื่อตั้งค่าการให้สิทธิ์ทั้งหมดแล้ว เราต้องการข้อมูลบางส่วนเพื่ออัปโหลดไปยัง BigQuery เราจะต้องใส่ข้อมูลนี้ลงในดาต้าเฟรม สำหรับจุดประสงค์ของบทความนี้ ฉันจะสร้างข้อมูลสมมุติขึ้นด้วยจำนวนสถานที่และจำนวนยอดขาย แต่เป็นไปได้มากว่าคุณจะอ่านข้อมูลจริงจากไฟล์ .csv หรือสเปรดชีต หากต้องการอ่านข้อมูลจากไฟล์ .csv คุณสามารถใช้ฟังก์ชัน read.csv() โดยส่งผ่านเส้นทางไปยังไฟล์เป็นอาร์กิวเมนต์:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
หรือหากคุณมีข้อมูลเก็บไว้ในสเปรดชีต วิธีการของคุณจะแตกต่างกันไปขึ้นอยู่กับตำแหน่งที่ตั้งของสเปรดชีตนี้ หากสเปรดชีตของคุณจัดเก็บไว้ใน Google ชีต คุณสามารถอ่านข้อมูลใน R โดยใช้ไลบรารี googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
เช่นเดียวกับก่อนหน้านี้ หากคุณไม่เคยใช้แพ็คเกจนี้มาก่อน คุณจะต้องเรียกใช้ install.packages(“googlesheets4”) ในคอนโซลก่อนที่จะเรียกใช้โค้ดของคุณ
ถ้าสเปรดชีตของคุณอยู่ใน Excel คุณจะต้องใช้ไลบรารี readxl ซึ่งเป็นส่วนหนึ่งของไลบรารี tidyverse ซึ่งเป็นสิ่งที่ผมแนะนำให้ใช้ ประกอบด้วยฟังก์ชันจำนวนมากที่ทำให้การจัดการข้อมูลใน R ง่ายขึ้นมาก:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
และอีกครั้ง อย่าลืมเรียกใช้ install.package("tidyverse") หากคุณยังไม่เคยทำมาก่อน!
ขั้นตอนสุดท้ายคือการอัปโหลดข้อมูลไปยัง BigQuery สำหรับสิ่งนี้ คุณต้องมีที่ใน BigQuery เพื่ออัปโหลด ตารางของคุณจะอยู่ภายในชุดข้อมูล ซึ่งจะอยู่ภายในโครงการ และคุณจะต้องมีชื่อทั้งสามรายการในรูปแบบต่อไปนี้:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
ในกรณีของฉัน นี่หมายความว่ารหัสของฉันอ่าน:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
ถ้ายังไม่มีตารางของคุณ ไม่ต้องกังวล รหัสจะสร้างตารางให้คุณ อย่าลืมใส่ชื่อโครงการ ชุดข้อมูล และตารางของคุณลงในโค้ดด้านบน (ภายในเครื่องหมายคำพูด) และตรวจสอบให้แน่ใจว่าคุณกำลังอัปโหลด dataframe ที่ถูกต้อง! เมื่อดำเนินการเสร็จแล้ว คุณควรเห็นข้อมูลของคุณใน BigQuery ดังนี้

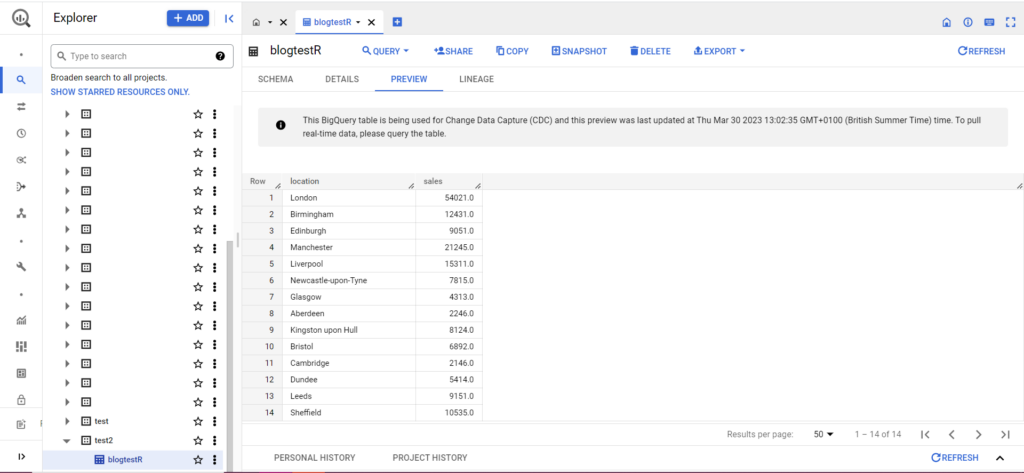
ในขั้นตอนสุดท้าย สมมติว่าคุณมีข้อมูลเพิ่มเติมที่ต้องการเพิ่มใน BigQuery ตัวอย่างเช่น ในข้อมูลของฉันด้านบน สมมติว่าฉันลืมระบุสถานที่สองสามแห่งจากทวีปนี้ และฉันต้องการอัปโหลดไปยัง BigQuery แต่ฉันไม่ต้องการเขียนทับข้อมูลที่มีอยู่ สำหรับสิ่งนี้ bqr_upload_data มีพารามิเตอร์ชื่อ writeDisposition writeDisposition มีการตั้งค่าสองแบบคือ “WRITE_TRUNCATE” และ “WRITE_APPEND” แบบแรกบอกให้ bqr_upload_data() เขียนทับข้อมูลที่มีอยู่ในตาราง ในขณะที่แบบหลังบอกให้ผนวกข้อมูลใหม่ ดังนั้น ในการอัปโหลดข้อมูลใหม่นี้ ฉันจะเขียน:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
และแน่นอนว่าใน BigQuery เราจะเห็นว่าข้อมูลของเรามีเพื่อนร่วมห้องใหม่:
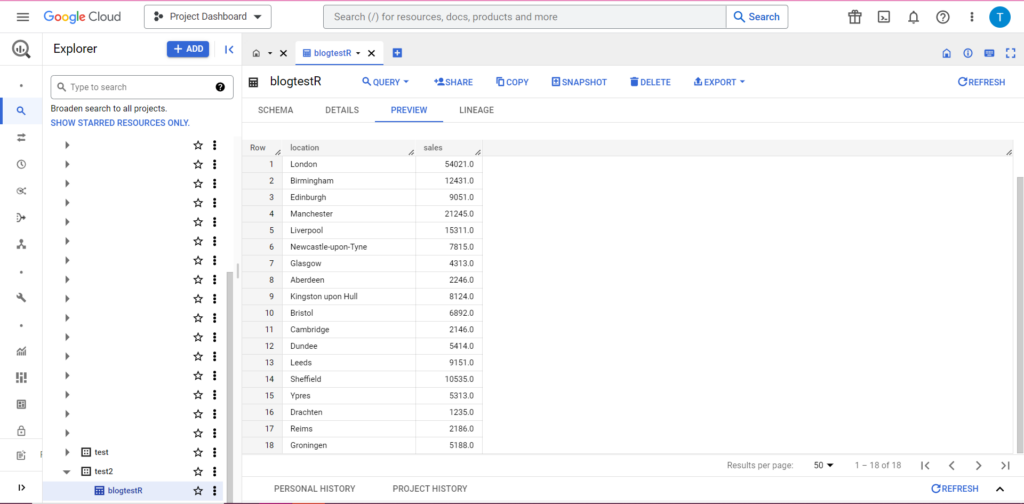
กำลังอัปโหลดไปยัง BigQuery จาก Python
ใน Python สิ่งต่าง ๆ แตกต่างกันเล็กน้อย อีกครั้ง เราจะต้องนำเข้าแพ็คเกจบางอย่าง ดังนั้นเรามาเริ่มกันที่สิ่งเหล่านี้:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
การอนุญาตมีความซับซ้อน อีกครั้งเราต้องการไฟล์ JSON ที่มีข้อมูลรับรอง ตามด้านบน เราจะไปที่ Google Cloud Console และคลิกที่ 'API และบริการ' จากนั้นคลิกที่ 'ข้อมูลประจำตัว' ในแถบด้านข้าง คราวนี้ ที่ด้านล่างของหน้า จะมีส่วนที่เรียกว่า 'บัญชีบริการ'
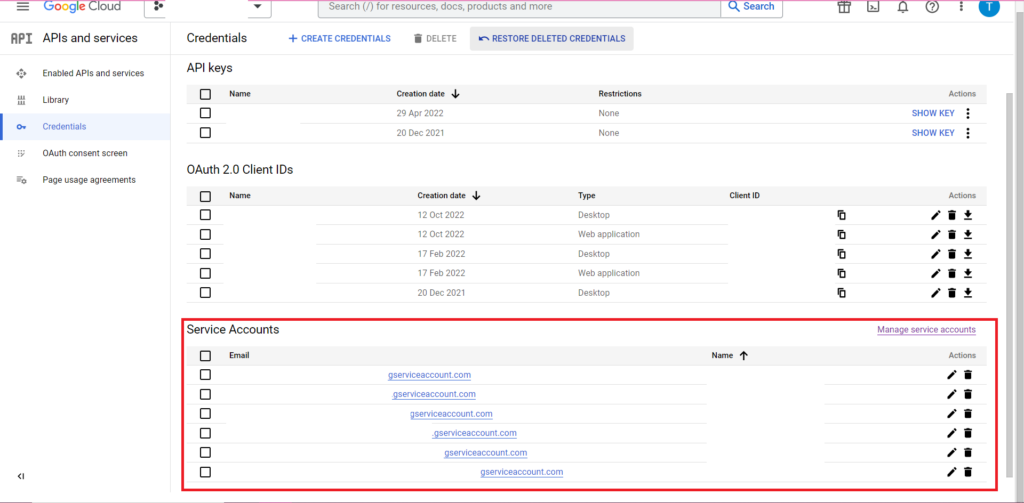
คุณสามารถดาวน์โหลดรหัสไปยังบัญชีบริการของคุณได้จากที่นั่น หรือคลิกที่ 'จัดการบัญชีบริการ' คุณจะสามารถสร้างรหัสใหม่หรือบัญชีบริการใหม่ซึ่งคุณสามารถดาวน์โหลดข้อมูลรับรองได้
จากนั้นคุณจะต้องแน่ใจว่าบัญชีบริการของคุณมีสิทธิ์เข้าถึงและแก้ไขโครงการ BigQuery อีกครั้ง ไปที่หน้า IAM ภายใต้ 'IAM & Admin' ในแถบด้านข้าง จากนั้นคุณสามารถให้สิทธิ์บัญชีบริการของคุณในการเข้าถึงโครงการที่เกี่ยวข้องได้โดยใช้ปุ่ม 'Grant Access' ที่ด้านบนของหน้า
ทันทีที่คุณแยกแยะออก คุณสามารถเขียนรหัสการให้สิทธิ์:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
ถัดไป คุณจะต้องนำข้อมูลของคุณเข้าสู่ดาต้าเฟรม Dataframes เป็นของ pandas package และสร้างง่ายมาก หากต้องการอ่านจาก CSV ให้ทำตามตัวอย่างนี้:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
แน่นอน คุณจะต้องแทนที่เส้นทางด้านบนด้วยเส้นทางดังกล่าวเป็นไฟล์ CSV ของคุณเอง หากต้องการอ่านจากไฟล์ Excel ให้ทำตามตัวอย่างนี้:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
การอ่านจาก Google ชีตเป็นเรื่องยุ่งยาก และต้องมีการอนุญาตอีกรอบ เราจะต้องนำเข้าแพ็คเกจใหม่และใช้ไฟล์ข้อมูลรับรอง JSON ที่เราดึงมาระหว่างการสอน R ด้านบน คุณสามารถทำตามรหัสนี้เพื่ออนุญาตและอ่านข้อมูลของคุณ:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
เมื่อคุณมีข้อมูลในดาต้าเฟรมแล้ว ก็ถึงเวลาอัปโหลดไปยัง BigQuery อีกครั้ง คุณสามารถทำได้โดยทำตามเทมเพลตนี้:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
ตัวอย่างเช่น นี่คือโค้ดที่ฉันเพิ่งเขียนเพื่ออัปโหลดข้อมูลที่ฉันสร้างไว้ก่อนหน้านี้:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
เมื่อดำเนินการเสร็จแล้ว ข้อมูลควรปรากฏใน BigQuery ทันที
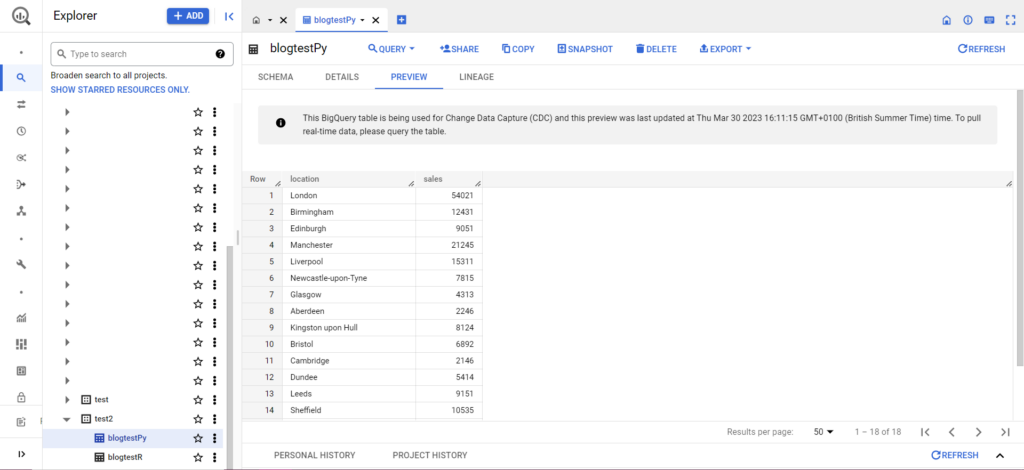
มีอะไรอีกมากมายที่คุณสามารถทำได้ด้วยฟังก์ชันเหล่านี้เมื่อคุณคุ้นเคยกับมันแล้ว หากคุณต้องการควบคุมการตั้งค่าการวิเคราะห์ของคุณให้ดียิ่งขึ้น Semetrical พร้อมให้ความช่วยเหลือ! ตรวจสอบบล็อกของเราสำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้ประโยชน์สูงสุดจากข้อมูลของคุณ หรือหากต้องการความช่วยเหลือเพิ่มเติมเกี่ยวกับการวิเคราะห์ทั้งหมด ให้ไปที่ Web Analytics เพื่อดูว่าเราจะช่วยคุณได้อย่างไร