
การขูดข้อมูลเว็บในยุคของข้อมูลขนาดใหญ่: โอกาสและประเด็นขัดแย้งทางจริยธรรม
เผยแพร่แล้ว: 2024-05-29การขูดข้อมูลเว็บและการวิเคราะห์ข้อมูลขนาดใหญ่
การขูดข้อมูลเว็บกลายเป็นกลไกสำคัญในการรวบรวมข้อมูลออนไลน์ กระบวนการนี้เกี่ยวข้องกับการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติ โดยเปลี่ยนเว็บที่ไม่มีโครงสร้างให้กลายเป็นข้อมูลที่มีโครงสร้างมากมายสำหรับการวิเคราะห์
ที่มาของภาพ: https://www.sas.com/
ในขณะเดียวกัน การวิเคราะห์ข้อมูลขนาดใหญ่ได้เจาะจงรูปแบบ แนวโน้ม และข้อมูลเชิงลึกที่ชาญฉลาดจากชุดข้อมูลขนาดใหญ่ที่สะสมไว้ ซึ่งมักจะผ่านการคัดลอกข้อมูลเว็บ เนื่องจากข้อมูลจำนวนมหาศาล (ประมาณ 2.5 ล้านล้านไบต์ของข้อมูลที่สร้างขึ้นในแต่ละวัน) สามารถเข้าถึงได้มากขึ้น การสังเคราะห์ข้อมูลเว็บที่คัดลอกมาด้วยการวิเคราะห์ข้อมูลขนาดใหญ่จะช่วยปลดล็อกความเป็นไปได้มากมายสำหรับธุรกิจ นักวิจัย และผู้กำหนดนโยบาย
ด้วยการรวมความสามารถทางเทคโนโลยีเหล่านี้อย่างเชี่ยวชาญ พวกเขาวางตำแหน่งตัวเองเพื่อใช้ประโยชน์จากการตัดสินใจโดยอาศัยข้อมูล กระตุ้นนวัตกรรมการบริการ และหล่อหลอมการดำเนินการเชิงกลยุทธ์ที่ปรับให้เหมาะกับวัตถุประสงค์ของพวกเขา อย่างไรก็ตาม จำเป็นต้องรับทราบถึงการเผชิญหน้าของประเด็นขัดแย้งทางจริยธรรมอันเป็นผลมาจากความสัมพันธ์ที่ทำงานร่วมกันระหว่างเครื่องมือขั้นสูงเหล่านี้
เส้นแบ่งจะต้องระมัดระวังเกี่ยวกับความสมดุลที่สำคัญระหว่างการเพิ่มมูลค่าข้อมูลให้สูงสุดและการรักษาสิทธิ์ความเป็นส่วนตัวของแต่ละบุคคล เพื่อให้แน่ใจว่าไม่มีด้านใดมาบดบังอีกด้านหนึ่ง
ประโยชน์ของการขูดข้อมูลเว็บสำหรับโครงการข้อมูลขนาดใหญ่
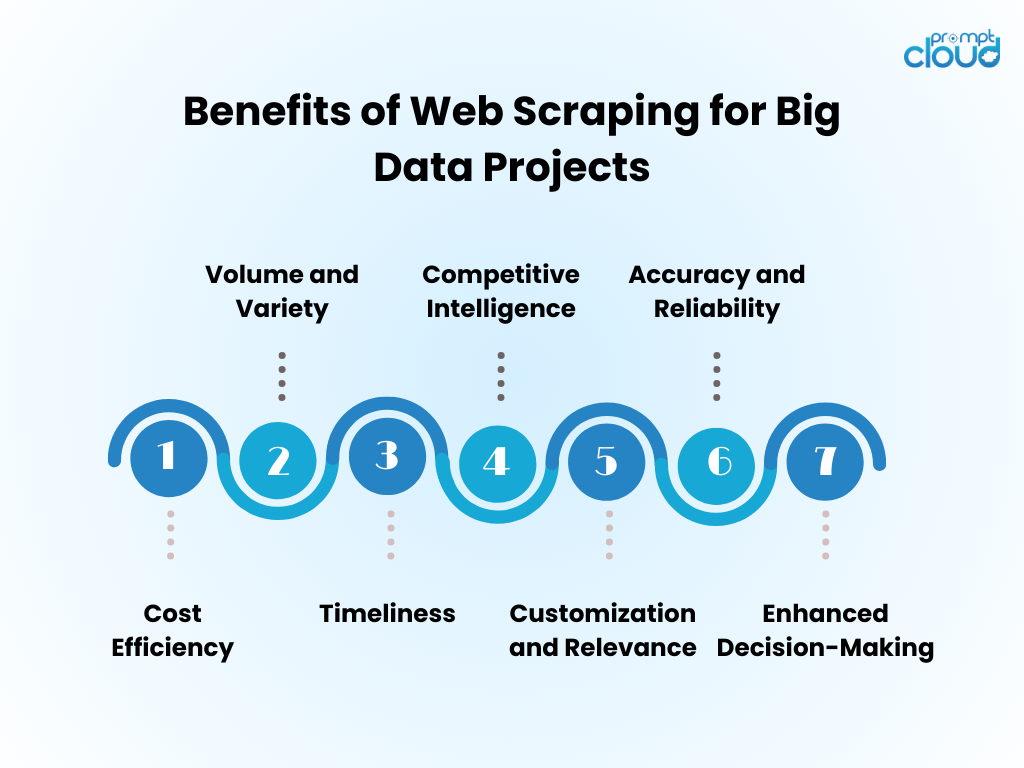
- ประสิทธิภาพด้านต้นทุน : การรวบรวมข้อมูลอัตโนมัติผ่านการขูดเว็บช่วยลดต้นทุนแรงงานมนุษย์ได้อย่างมาก และเร่งเวลาในการทำความเข้าใจให้เร็วขึ้น
- ปริมาณและความหลากหลาย : ช่วยให้สามารถเก็บข้อมูลจำนวนมหาศาลจากแหล่งที่หลากหลาย ซึ่งมีความสำคัญอย่างยิ่งต่อการป้อนการวิเคราะห์ข้อมูลขนาดใหญ่
- Timeliness : Web scraping ให้ข้อมูลแบบเรียลไทม์หรือใกล้เคียงเรียลไทม์ ช่วยให้ตอบสนองต่อแนวโน้มของตลาดได้อย่างคล่องตัวยิ่งขึ้น
- Competitive Intelligence : ช่วยให้องค์กรต่างๆ มีความสามารถในการติดตามคู่แข่งและการเปลี่ยนแปลงของอุตสาหกรรมอย่างใกล้ชิด
- การปรับแต่งและความเกี่ยวข้อง : ข้อมูลสามารถปรับให้เข้ากับความต้องการเฉพาะได้ เพื่อให้มั่นใจว่าการวิเคราะห์มีความเกี่ยวข้องและมุ่งเน้น
- ความแม่นยำและความน่าเชื่อถือ : การขูดแบบอัตโนมัติช่วยลดข้อผิดพลาดของมนุษย์ นำไปสู่ชุดข้อมูลที่แม่นยำยิ่งขึ้น
- การตัดสินใจที่เพิ่มขึ้น : การเข้าถึงข้อมูลที่เกี่ยวข้องทันเวลาสนับสนุนการตัดสินใจอย่างมีข้อมูลและการวางแผนเชิงกลยุทธ์
เทคนิคการขูดเว็บ: ตั้งแต่ขั้นพื้นฐานไปจนถึงขั้นสูง

ที่มาของภาพ: เข้าสู่ระบบงาน
การขูดข้อมูลเว็บได้รับการพัฒนาด้วยเทคโนโลยี โดยเริ่มจากเทคนิคพื้นฐานที่จะก้าวหน้าเมื่อความซับซ้อนของข้อมูลเพิ่มมากขึ้น
- เทคนิคพื้นฐาน : ในขั้นแรก สเครเปอร์จะดึงข้อมูลโดยใช้คำขอ HTTP แบบธรรมดาเพื่อรับหน้า HTML โดยแยกวิเคราะห์เนื้อหาผ่านไลบรารี เช่น Beautiful Soup ใน Python เครื่องมือเหล่านี้สามารถจัดการเว็บไซต์ที่ไม่ซับซ้อนได้อย่างเพียงพอ
- เทคนิคระดับกลาง : สำหรับเนื้อหาไดนามิก เทคนิคต่างๆ จะพัฒนาขึ้นเพื่อรวมเครื่องมืออัตโนมัติ เช่น Selenium ซึ่งสามารถโต้ตอบกับ JavaScript และเลียนแบบพฤติกรรมของเบราว์เซอร์ได้
- เทคนิคขั้นสูง : มุ่งสู่การขูดขั้นสูง วิธีการรวมเบราว์เซอร์ที่ไม่มีส่วนหัวและพร็อกซีเซิร์ฟเวอร์เพื่อนำทางไปตามมาตรการป้องกันการขูด การดึงข้อมูลมีความซับซ้อนมากขึ้นด้วยอัลกอริธึมการเรียนรู้ของเครื่อง การประมวลผลภาษาธรรมชาติและรูปภาพเพื่อดึงข้อมูล
- ข้อพิจารณาด้านจริยธรรม : แม้ว่าเทคนิคจะซับซ้อนก็ตาม ประเด็นขัดแย้งด้านจริยธรรมยังคงมีอยู่ โดยจำเป็นต้องมีความสมดุลระหว่างการเข้าถึงข้อมูลและการเคารพความเป็นส่วนตัวและความเป็นเจ้าของ
การรวมข้อมูลที่คัดลอกมาจากเว็บเข้ากับการวิเคราะห์ข้อมูลขนาดใหญ่
ข้อมูลที่คัดลอกมาจากเว็บเมื่อรวมเข้ากับการวิเคราะห์ข้อมูลขนาดใหญ่ จะสามารถเปิดเผยข้อมูลเชิงลึกของตลาดและแนวโน้มของผู้บริโภคได้อย่างครอบคลุม นักวิเคราะห์ผสมผสานข้อมูลที่คัดลอกมาจากเว็บเข้ากับชุดข้อมูลที่มีอยู่ ช่วยเพิ่มความลึกและความกว้างของผลลัพธ์การวิเคราะห์ การควบรวมกิจการนี้ทำให้เกิดแบบจำลองการคาดการณ์ที่ได้รับการปรับปรุง กลยุทธ์การตลาดที่ปรับแต่งให้เหมาะสม และโปรไฟล์ผู้บริโภคที่ได้รับการปรับปรุง

- การล้างข้อมูล: ข้อมูลที่คัดลอกมาต้องมีการล้างอย่างพิถีพิถันเพื่อให้มั่นใจในความแม่นยำในการวิเคราะห์
- การรวมข้อมูล: การรวมข้อมูลที่คัดลอกมาเข้ากับแหล่งข้อมูลอื่นจำเป็นต้องใช้เทคนิคการรวมข้อมูลขั้นสูง
- การเพิ่มประสิทธิภาพการวิเคราะห์: ด้วยข้อมูลเพิ่มเติม อัลกอริธึมการเรียนรู้ของเครื่องสามารถเปิดเผยรูปแบบที่เหมาะสมยิ่งขึ้น
- การพิจารณาด้านจริยธรรม: นักวิเคราะห์จะต้องตรวจสอบให้แน่ใจว่าการใช้ข้อมูลเว็บเป็นไปตามมาตรฐานทางกฎหมายและจริยธรรม
แหล่งรวมข้อมูลเสริมขับเคลื่อนนวัตกรรม แต่ยังต้องการวิธีการที่เข้มงวดและการกำกับดูแลด้านจริยธรรม
แนวทางปฏิบัติที่ดีที่สุดสำหรับการขูดเว็บอย่างมีประสิทธิภาพ
- เคารพโปรโตคอล robots.txt อย่าขูดไซต์ที่ไม่อนุญาตผ่านไฟล์โรบ็อต
- กำหนดเวลากิจกรรมการขูดในช่วงเวลาที่มีการใช้งานน้อยเพื่อลดผลกระทบต่อประสิทธิภาพของเซิร์ฟเวอร์เป้าหมาย
- ใช้แคชเพื่อหลีกเลี่ยงการคัดลอกเนื้อหาเดิมซ้ำ โดยคำนึงถึงข้อมูลของเว็บไซต์และประหยัดแบนด์วิธ
- ใช้การจัดการข้อผิดพลาดที่เหมาะสมเพื่อป้องกันไม่ให้เครื่องขูดของคุณทำงานล้มเหลว และเพื่อหลีกเลี่ยงการส่งคำขอมากเกินไปในกรณีที่เกิดข้อผิดพลาด
- หมุนเวียนตัวแทนผู้ใช้และที่อยู่ IP เพื่อป้องกันการถูกบล็อก จำลองพฤติกรรมการท่องเว็บที่เป็นธรรมชาติมากขึ้น
- รับข่าวสารเกี่ยวกับหลักปฏิบัติทางกฎหมายและจริยธรรมในการขูดเว็บ เพื่อให้มั่นใจว่ากิจกรรมการขูดเว็บของคุณจะไม่ละเมิดลิขสิทธิ์หรือกฎหมายความเป็นส่วนตัว
- เพิ่มประสิทธิภาพโค้ดให้มีประสิทธิภาพและลดภาระทั้งระบบขูดและเว็บไซต์เป้าหมาย
- อัปเดตโค้ดขูดเป็นประจำเพื่อปรับให้เข้ากับการเปลี่ยนแปลงเค้าโครงหรือเทคโนโลยีของเว็บไซต์ โดยคงไว้ซึ่งประสิทธิภาพและความแม่นยำในการดึงข้อมูลของคุณ
- จัดเก็บข้อมูลที่รวบรวมไว้อย่างปลอดภัยและจัดการตามกฎระเบียบการปกป้องข้อมูลที่เกี่ยวข้องทั้งหมด
อนาคตของการขูดเว็บในยุคของข้อมูลขนาดใหญ่
ในขณะที่ Big Data ยังคงขยายตัวอย่างต่อเนื่อง การขูดข้อมูลเว็บก็พร้อมที่จะกลายเป็นส่วนสำคัญในการวิเคราะห์ข้อมูลและระบบธุรกิจอัจฉริยะมากยิ่งขึ้น อนาคตน่าจะได้เห็น:
- โมเดลแมชชีนเลิร์นนิงที่ได้รับการปรับปรุงซึ่งได้รับการฝึกฝนด้วยชุดข้อมูลจำนวนมหาศาลที่ได้รับจากการสแครป ปรับปรุงความแม่นยำและข้อมูลเชิงลึก
- ความต้องการขูดข้อมูลแบบเรียลไทม์เพิ่มขึ้น ช่วยให้ธุรกิจต่างๆ ตัดสินใจได้รวดเร็วยิ่งขึ้นโดยอาศัยข้อมูล
- การพัฒนาเครื่องมือขูดที่ซับซ้อนมากขึ้นเพื่อนำทางเทคโนโลยีป้องกันการขูดและรักษาแนวปฏิบัติในการรวบรวมข้อมูลตามหลักจริยธรรม
- กฎระเบียบที่เข้มงวดและกฎหมายความเป็นส่วนตัวกำหนดวิธีการขูดข้อมูลเว็บ ทำให้มั่นใจได้ว่าข้อมูลจะถูกเก็บรวบรวมอย่างมีความรับผิดชอบและด้วยความยินยอม
- การเกิดขึ้นของแพลตฟอร์ม Scraping-as-a-Service ที่นำเสนอการดึงข้อมูลที่ได้รับการปรับแต่งสำหรับธุรกิจทุกขนาด
ด้วยความก้าวหน้าเหล่านี้ การขูดเว็บจะยังคงเป็นเครื่องมือสำคัญในชุดเครื่องมือ Big Data
หากการขูดเว็บด้วยตนเองเป็นเรื่องที่น่ากังวลหรือหากต้องการความช่วยเหลือเพื่อแก้ปัญหาที่ซับซ้อนที่เกี่ยวข้องกับการได้รับข้อมูลอันมีค่า มั่นใจได้ว่า PromptCloud พร้อมที่จะช่วยเหลือ!
เรามีความเชี่ยวชาญในการนำเสนอโซลูชันการขูดเว็บที่ครอบคลุมซึ่งออกแบบมาโดยเฉพาะสำหรับความคิดริเริ่มด้านข้อมูลขนาดใหญ่ เพื่อให้มั่นใจว่าสามารถดึงข้อมูลขนาดใหญ่ที่เชื่อถือได้
วางใจให้เราจัดการกับแง่มุมที่ต้องการ ช่วยให้คุณมีสมาธิกับการสร้างตัวเลือกที่มีข้อมูลครบถ้วนโดยใช้ชุดข้อมูลที่มีประสิทธิภาพและมีความหมาย ติดต่อเราที่ sales@promptcloud.com เพื่อดูว่าความเชี่ยวชาญของเราสามารถเพิ่มแผนเกมข้อมูลขนาดใหญ่ของคุณได้อย่างไร!