
การสกัดข้อมูลคืออะไร: คู่มือสำหรับผู้เริ่มต้น
เผยแพร่แล้ว: 2023-11-07ในยุคที่ข้อมูลมีคุณค่าพอๆ กับสกุลเงิน ความสามารถในการดึงข้อมูลนี้อย่างมีประสิทธิภาพสามารถทำให้ธุรกิจของคุณแตกต่างจากคู่แข่งได้ การดึงข้อมูลไม่ใช่แค่กระบวนการทางเทคนิคเท่านั้น เป็นกลยุทธ์ที่เมื่อทำถูกต้องจะสามารถเปิดเผยข้อมูลเชิงลึกที่นำไปสู่การตัดสินใจทางธุรกิจที่ชาญฉลาดยิ่งขึ้นและการเติบโตที่แข็งแกร่ง โพสต์ในบล็อกนี้จะเจาะลึกถึงอะไร ทำไม และวิธีการดึงข้อมูล เพื่อให้คุณมีความรู้ในการควบคุมศักยภาพสูงสุดของมัน
การสกัดข้อมูลคืออะไร
การดึงข้อมูลเป็นกระบวนการดึงข้อมูลที่มีโครงสร้างหรือไม่มีโครงสร้างจากแหล่งต่างๆ เช่น ฐานข้อมูล เว็บไซต์ เอกสาร รูปภาพ ฯลฯ จากนั้นข้อมูลนี้จะถูกแปลงเป็นรูปแบบที่สามารถจัดการและใช้งานได้มากขึ้น เช่น สเปรดชีตหรือฐานข้อมูล เป้าหมายคือการรวบรวมข้อมูลนี้ในลักษณะที่จะรักษาความหมายในขณะที่ทำให้สามารถเข้าถึงได้สำหรับการวิเคราะห์และระบบธุรกิจอัจฉริยะ
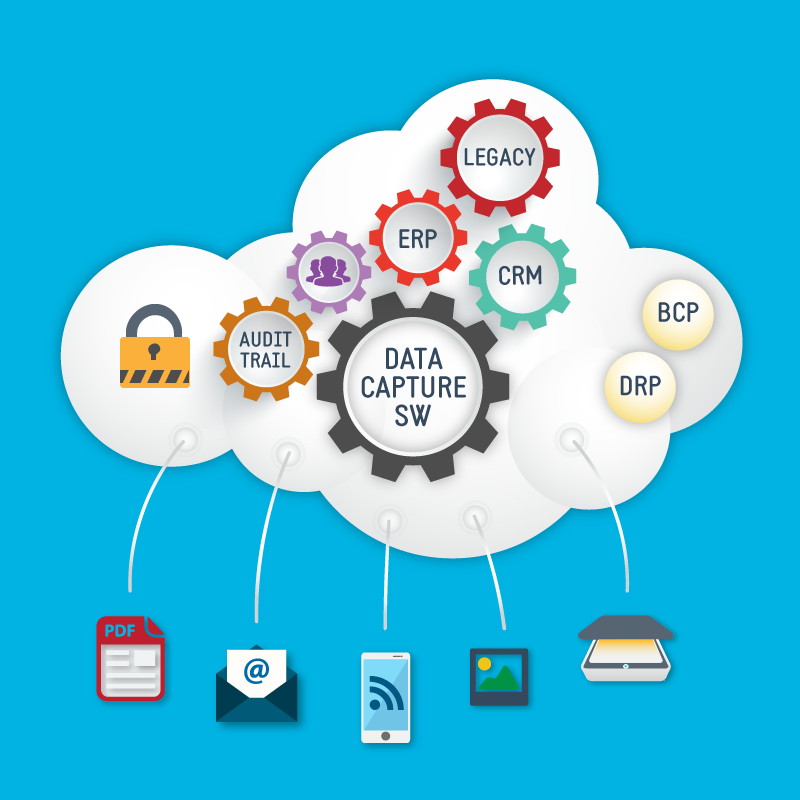
ที่มา: https://papersoft-dms.com/
เหตุใดการสกัดข้อมูลจึงมีความสำคัญ
- การตัดสินใจอย่างมีข้อมูล: ข้อมูลที่แยกออกมาจะเป็นรากฐานสำหรับการวิเคราะห์ที่สามารถเปิดเผยแนวโน้ม คาดการณ์ผลลัพธ์ และเป็นแนวทางในการตัดสินใจเชิงกลยุทธ์
- ประสิทธิภาพ: กระบวนการแยกข้อมูลอัตโนมัติช่วยประหยัดเวลาและทรัพยากร ขจัดข้อผิดพลาดด้วยตนเองและความซ้ำซ้อน
- บูรณาการ: ช่วยให้สามารถรวมข้อมูลจากแหล่งที่แตกต่างกัน ทำให้มีมุมมองการดำเนินงานแบบองค์รวม
- ความได้เปรียบทางการแข่งขัน: การเข้าถึงข้อมูลที่เกี่ยวข้องอย่างรวดเร็วสามารถเป็นข้อได้เปรียบที่ธุรกิจต้องการเพื่อก้าวแซงหน้าการแข่งขัน
ประเภทของการดึงข้อมูล
ในโลกที่เต็มไปด้วยข้อมูลที่เราอาศัยอยู่ ความสามารถในการดึงข้อมูลอย่างมีประสิทธิภาพจากแหล่งที่มาที่หลากหลายนั้นเป็นสิ่งที่ประเมินค่ามิได้ กระบวนการดึงข้อมูลแตกต่างกันไม่เพียงแต่ในวิธีการเท่านั้น แต่ยังรวมถึงการใช้งานด้วย การทำความเข้าใจประเภทของการดึงข้อมูลจะช่วยให้คุณเลือกเทคนิคที่เหมาะสมกับความต้องการข้อมูลของคุณได้
1. การแยกข้อมูลด้วยตนเอง
การดึงข้อมูลด้วยตนเองเป็นรูปแบบพื้นฐานที่สุด ซึ่งเกี่ยวข้องกับการป้อนข้อมูลของมนุษย์เพื่อรวบรวมข้อมูลจากแหล่งข้อมูลทางกายภาพหรือดิจิทัล วิธีนี้มักจะช้าและมีแนวโน้มที่จะเกิดข้อผิดพลาด แต่จะมีประโยชน์เมื่อต้องจัดการกับข้อมูลที่ซับซ้อนซึ่งต้องใช้วิจารณญาณของมนุษย์
2. การแยกข้อมูลอัตโนมัติ
ประเภทนี้ใช้ซอฟต์แวร์และเครื่องมือในการรวบรวมและประมวลผลข้อมูลโดยอัตโนมัติ ช่วยเร่งกระบวนการให้เร็วขึ้นและลดโอกาสที่จะเกิดข้อผิดพลาดได้อย่างมาก
3. การแยกข้อมูลเว็บ (Web Scraping)
การขูดเว็บเป็นเทคนิคที่ใช้ในการดึงข้อมูลจากเว็บไซต์ ซึ่งทำได้ผ่านซอฟต์แวร์ที่เลียนแบบการท่องเว็บของมนุษย์เพื่อรวบรวมข้อมูลเฉพาะจากแหล่งข้อมูลออนไลน์
4. การสกัดข้อมูลที่มีโครงสร้าง
ประเภทนี้หมายถึงการดึงข้อมูลที่จัดอยู่ในรูปแบบที่มีโครงสร้าง เช่น ฐานข้อมูลหรือสเปรดชีต ซึ่งข้อมูลมีความสอดคล้องและเป็นไปตามสคีมาเฉพาะ
5. การแยกข้อมูลแบบไม่มีโครงสร้าง
การดึงข้อมูลแบบไม่มีโครงสร้างเกี่ยวข้องกับข้อมูลที่ไม่เป็นไปตามรูปแบบหรือโครงสร้างเฉพาะ เช่น อีเมล PDF หรือมัลติมีเดีย
6. การแยกข้อมูลแบบกึ่งโครงสร้าง
การดึงข้อมูลแบบกึ่งโครงสร้างมีไว้สำหรับข้อมูลที่ไม่ได้อยู่ในฐานข้อมูลเชิงสัมพันธ์ แต่มีคุณสมบัติขององค์กรบางประการ ทำให้วิเคราะห์ได้ง่ายกว่าข้อมูลที่ไม่มีโครงสร้าง
7. การแยกข้อมูลตามแบบสอบถาม
วิธีนี้เกี่ยวข้องกับการใช้แบบสอบถามเพื่อดึงข้อมูลจากฐานข้อมูล เป็นรูปแบบการดึงข้อมูลที่มีโครงสร้างที่มีประสิทธิภาพสูงและสามารถดึงข้อมูลแบบเรียลไทม์หรือตามกำหนดเวลาได้
เทคนิคการดึงข้อมูล
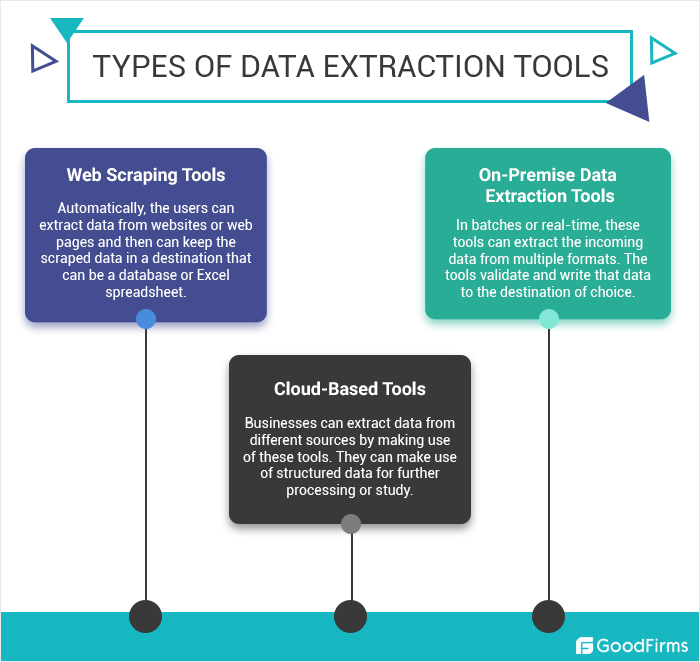
- การบันทึกข้อมูลอัตโนมัติ: เครื่องมือที่ตรวจจับและดึงข้อมูลที่เกี่ยวข้องจากเอกสารหรือเว็บเพจโดยอัตโนมัติ
- Web Scraping: การใช้ซอฟต์แวร์เพื่อจำลองการสำรวจเว็บโดยมนุษย์เพื่อรวบรวมข้อมูลเฉพาะ
- การวิเคราะห์ข้อความ: ใช้การประมวลผลภาษาธรรมชาติเพื่อดึงข้อมูลจากข้อความที่ไม่มีโครงสร้าง
- กระบวนการ ETL: ย่อมาจาก Extract, Transform, Load ซึ่งเป็นระบบบูรณาการที่ดึงข้อมูลจากแหล่งต่างๆ แปลงเป็นรูปแบบที่เป็นประโยชน์ และจัดเก็บไว้ในคลังข้อมูล
แนวทางปฏิบัติที่ดีที่สุดสำหรับการดึงข้อมูลอย่างมีประสิทธิภาพ
- กำหนดวัตถุประสงค์ที่ชัดเจน: รู้ว่าคุณต้องการอะไรจากความพยายามในการดึงข้อมูลเพื่อเลือกเครื่องมือและวิธีการที่เหมาะสม
- มั่นใจในคุณภาพของข้อมูล: ตรวจสอบและล้างข้อมูลของคุณโดยเป็นส่วนหนึ่งของกระบวนการแยกข้อมูลเพื่อรักษาความสมบูรณ์
- ปฏิบัติตามกฎหมาย: ตระหนักถึงกฎหมายและข้อบังคับด้านความเป็นส่วนตัวของข้อมูลเพื่อให้แน่ใจว่าวิธีการดึงข้อมูลของคุณนั้นถูกกฎหมาย
- ความสามารถในการปรับขนาด: เลือกโซลูชันที่สามารถเติบโตไปพร้อมกับความต้องการข้อมูลของคุณเพื่อหลีกเลี่ยงการยกเครื่องในอนาคต
ความท้าทายในการสกัดข้อมูล
แม้ว่าการดึงข้อมูลจะประเมินค่าไม่ได้ แต่ก็นำเสนอความท้าทายมากมายที่อาจทำให้กระบวนการยุ่งยากสำหรับธุรกิจและบุคคลทั่วไป ความท้าทายเหล่านี้สามารถส่งผลกระทบต่อคุณภาพ ความเร็ว และประสิทธิภาพของความคิดริเริ่มที่ขับเคลื่อนด้วยข้อมูล ด้านล่างนี้ เราจะเจาะลึกอุปสรรคทั่วไปที่พบในกระบวนการดึงข้อมูล

- ปัญหาคุณภาพข้อมูล:
- ข้อมูลที่ไม่สอดคล้องกัน: การดึงข้อมูลจากแหล่งต่างๆ มักหมายถึงการจัดการกับความไม่สอดคล้องกันในรูปแบบ โครงสร้าง และคุณภาพ ซึ่งอาจนำไปสู่ชุดข้อมูลที่ไม่ถูกต้องได้
- ข้อมูลที่ไม่สมบูรณ์: ค่าที่หายไปหรือบันทึกที่ไม่สมบูรณ์ระหว่างการดึงข้อมูลอาจทำให้ผลลัพธ์การวิเคราะห์บิดเบือนได้
- ซ้ำซ้อน: ข้อมูลซ้ำซ้อนอาจเกิดขึ้นได้ในระหว่างการแยกข้อมูล ซึ่งนำไปสู่ความไร้ประสิทธิภาพและผลการวิเคราะห์ที่บิดเบี้ยว
- ข้อกังวลเกี่ยวกับความสามารถในการขยายขนาด:
- ปริมาณ: เมื่อปริมาณข้อมูลเพิ่มมากขึ้น การดึงข้อมูลอย่างทันท่วงทีและมีประสิทธิภาพจึงมีความท้าทายเพิ่มมากขึ้น โดยไม่กระทบต่อประสิทธิภาพของระบบ
- การพัฒนาข้อมูล: การพัฒนาอย่างต่อเนื่องของข้อมูลจำเป็นต้องมีกระบวนการแยกข้อมูลที่ปรับขนาดได้ ซึ่งสามารถปรับให้เข้ากับการเปลี่ยนแปลงได้โดยไม่จำเป็นต้องกำหนดค่าใหม่อย่างกว้างขวาง
- แหล่งข้อมูลที่ซับซ้อนและหลากหลาย:
- ความหลากหลาย: การดึงข้อมูลจากแหล่งที่มาที่หลากหลายด้วยรูปแบบที่แตกต่างกัน (PDF, เว็บเพจ, ฐานข้อมูล ฯลฯ) ต้องใช้เครื่องมือการดึงข้อมูลที่หลากหลายและซับซ้อน
- การเข้าถึง: ข้อมูลที่ล็อกอยู่ในระบบเดิมหรือผ่านรูปแบบที่เป็นกรรมสิทธิ์อาจเป็นเรื่องท้าทายอย่างยิ่งในการเข้าถึงและดึงข้อมูล
- ข้อจำกัดทางเทคนิค:
- ความยากลำบากในการบูรณาการ: การรวมข้อมูลที่แยกออกมาเข้ากับระบบที่มีอยู่อาจทำให้เกิดความท้าทายทางเทคนิค โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับเทคโนโลยีที่แตกต่างกันหรือโครงสร้างพื้นฐานที่ล้าสมัย
- การขาดความเชี่ยวชาญ: มักจะมีช่วงการเรียนรู้ที่สูงชันที่เกี่ยวข้องกับเครื่องมือและเทคนิคที่จำเป็นสำหรับการแยกข้อมูลอย่างมีประสิทธิภาพ ซึ่งต้องใช้ความรู้เฉพาะทาง
- ประเด็นทางกฎหมายและการปฏิบัติตามข้อกำหนด:
- กฎระเบียบด้านความเป็นส่วนตัว: การปฏิบัติตามกฎหมายความเป็นส่วนตัวของข้อมูลที่เข้มงวด เช่น GDPR หรือ HIPAA อาจทำให้กระบวนการดึงข้อมูลมีความซับซ้อน เนื่องจากข้อมูลบางอย่างอาจต้องมีโปรโตคอลการจัดการเพิ่มเติม
- ทรัพย์สินทางปัญญา: เมื่อดึงข้อมูลจากแหล่งภายนอก มีความเสี่ยงที่จะละเมิดสิทธิ์ในทรัพย์สินทางปัญญา ซึ่งอาจนำไปสู่ปัญหาทางกฎหมายได้
- การแยกข้อมูลแบบเรียลไทม์:
- ความหน่วง: มีความต้องการเพิ่มขึ้นในการดึงข้อมูลแบบเรียลไทม์ในบางภาคส่วน เช่น การเงินหรือความปลอดภัย ซึ่งความหน่วงอาจส่งผลกระทบอย่างมากต่อการตัดสินใจ
- โครงสร้างพื้นฐาน: การดึงข้อมูลแบบเรียลไทม์ต้องใช้โครงสร้างพื้นฐานที่แข็งแกร่งซึ่งสามารถจัดการกระแสข้อมูลได้อย่างต่อเนื่องโดยไม่มีปัญหาคอขวด
- การแปลงข้อมูล:
- การแปลงรูปแบบ: ข้อมูลที่แยกออกมามักจะต้องแปลงเป็นรูปแบบอื่นเพื่อการวิเคราะห์ ซึ่งอาจเป็นกระบวนการที่ซับซ้อนและเกิดข้อผิดพลาดได้ง่าย
- การรักษาบริบท: การตรวจสอบให้แน่ใจว่าข้อมูลยังคงความหมายไว้หลังจากการแยกและการเปลี่ยนแปลงถือเป็นสิ่งสำคัญแต่ก็ท้าทาย โดยเฉพาะอย่างยิ่งเมื่อต้องรับมือกับข้อมูลที่ไม่มีโครงสร้าง
- ข้อกังวลด้านความปลอดภัย:
- การละเมิดข้อมูล: มีความเสี่ยงต่อการละเมิดข้อมูลเสมอเมื่อดึงข้อมูลที่ละเอียดอ่อนหรือเป็นความลับ ซึ่งต้องใช้มาตรการรักษาความปลอดภัยที่เข้มงวด
- ข้อมูลเสียหาย: ข้อมูลอาจเสียหายระหว่างการแยกข้อมูลเนื่องจากข้อผิดพลาดของซอฟต์แวร์ ปัญหาความเข้ากันได้ หรือความล้มเหลวของฮาร์ดแวร์
บทสรุป
เนื่องจากเป็นเส้นชีวิตของกระบวนการวิเคราะห์ข้อมูล การดึงข้อมูลอาจดูน่ากลัว แต่ด้วยแนวทางที่ถูกต้อง จะกลายเป็นตัวเร่งให้เกิดข้อมูลเชิงลึกและโอกาส ด้วยการทำความเข้าใจหลักการและใช้ประโยชน์จากเทคโนโลยีปัจจุบัน องค์กรใดๆ ก็สามารถปลดล็อกศักยภาพของข้อมูลได้อย่างเต็มที่