
Data Scraping คืออะไร – เทคนิค เครื่องมือ และกรณีการใช้งาน
เผยแพร่แล้ว: 2023-12-29ในโลกของข้อมูลที่เปลี่ยนแปลงไปอย่างรวดเร็ว ธุรกิจต่างๆ กำลังมุ่งหน้าเข้าสู่ขอบเขตของข้อมูลเชิงลึกที่ขับเคลื่อนด้วยข้อมูล เพื่อกำหนดทิศทางการเคลื่อนไหวเชิงกลยุทธ์ มาสำรวจจักรวาลอันน่าหลงใหลของการขูดข้อมูลซึ่งเป็นกระบวนการอันชาญฉลาดที่ดึงข้อมูลจากเว็บไซต์ ซึ่งเป็นการวางรากฐานสำหรับการรวบรวมข้อมูลที่จำเป็น
มาร่วมสำรวจความซับซ้อนของการขูดข้อมูล เผยให้เห็นเครื่องมือ เทคนิคขั้นสูง และการพิจารณาด้านจริยธรรมที่หลากหลาย ซึ่งเพิ่มความลึกและความหมายให้กับแนวทางปฏิบัติที่เปลี่ยนแปลงเกมนี้
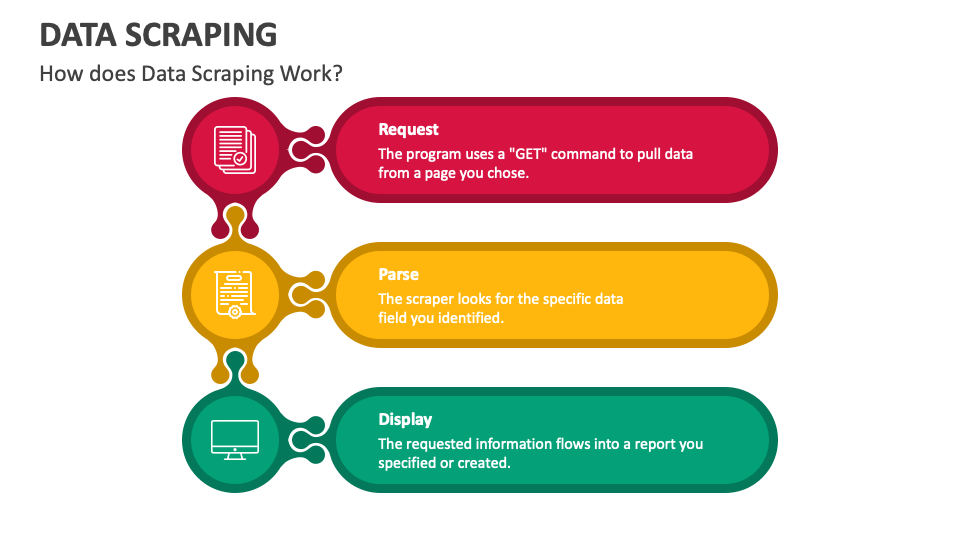
ที่มาของภาพ: https://www.collidu.com/
เครื่องมือขูดข้อมูล
การเริ่มผจญภัยในการขูดข้อมูลจำเป็นต้องทำความคุ้นเคยกับเครื่องมือต่างๆ มากมาย ซึ่งแต่ละอย่างก็มีนิสัยใจคอและการใช้งานของตัวเอง:
- ซอฟต์แวร์ขูดเว็บ: เจาะลึกโปรแกรมอย่าง Octoparse หรือ Import.io ซึ่งมอบพลังในการดึงข้อมูลให้กับผู้ใช้ โดยไม่คำนึงถึงความเชี่ยวชาญด้านเทคนิค
- ภาษาการเขียนโปรแกรม: คู่หูแบบไดนามิกของ Python และ R ควบคู่ไปกับไลบรารีเช่น Beautiful Soup หรือ rvest เป็นศูนย์กลางในการสร้างสคริปต์ขูดแบบกำหนดเอง
- ส่วนขยายเบราว์เซอร์: เครื่องมือเช่น Web Scraper หรือ Data Miner มอบตัวเลือกที่ดีในเบราว์เซอร์สำหรับงานขูดอย่างรวดเร็วเหล่านั้น
- API: เว็บไซต์บางแห่งมี API ให้เลือกมากมาย ซึ่งเพิ่มความคล่องตัวในการเรียกข้อมูลที่มีโครงสร้าง และลดการพึ่งพาเทคนิคการคัดลอกแบบดั้งเดิม
- เบราว์เซอร์แบบไม่มีส่วนหัว: พบกับ Puppeteer และ Selenium ซึ่งเป็นเกจิระบบอัตโนมัติที่จำลองการโต้ตอบของผู้ใช้เพื่อแยกเนื้อหาแบบไดนามิก
เครื่องมือแต่ละชิ้นมีข้อได้เปรียบและเส้นโค้งการเรียนรู้ที่เป็นเอกลักษณ์ ทำให้กระบวนการคัดเลือกเป็นกลยุทธ์ที่สอดคล้องกับความต้องการของโครงการและความสามารถทางเทคนิคของผู้ใช้
การเรียนรู้เทคนิคการขูดข้อมูล
การขูดข้อมูลอย่างมีประสิทธิภาพเป็นศิลปะที่เกี่ยวข้องกับเทคนิคหลายประการ เพื่อให้แน่ใจว่ากระบวนการรวบรวมจากแหล่งที่มาที่หลากหลายจะราบรื่น เทคนิคเหล่านี้ได้แก่:
- การขูดเว็บอัตโนมัติ: ปลดปล่อยบอทหรือโปรแกรมรวบรวมข้อมูลเว็บเพื่อรวบรวมข้อมูลจากเว็บไซต์อย่างสวยงาม
- API Scraping: ควบคุมพลังของ Application Programming Interfaces (API) เพื่อดึงข้อมูลในรูปแบบที่มีโครงสร้าง
- การแยกวิเคราะห์ HTML: นำทางแนวนอนของหน้าเว็บโดยการวิเคราะห์โค้ด HTML เพื่อแยกข้อมูลที่จำเป็น
- การดึงจุดข้อมูล: เรื่องความแม่นยำ—ระบุและแยกจุดข้อมูลเฉพาะตามพารามิเตอร์และคำสำคัญที่กำหนดไว้ล่วงหน้า
- การแก้ปัญหาแคปต์ชา: พิชิตแคปต์ชาด้านความปลอดภัยด้วยเทคโนโลยีเพื่อหลีกเลี่ยงอุปสรรคที่ตั้งขึ้นเพื่อปกป้องเว็บไซต์จากการขูดข้อมูลแบบอัตโนมัติ
- พร็อกซีเซิร์ฟเวอร์: บริจาคที่อยู่ IP ที่แตกต่างกันเพื่อหลบเลี่ยงการแบน IP และการจำกัดอัตราในขณะที่ดึงข้อมูลจำนวนมหาศาล
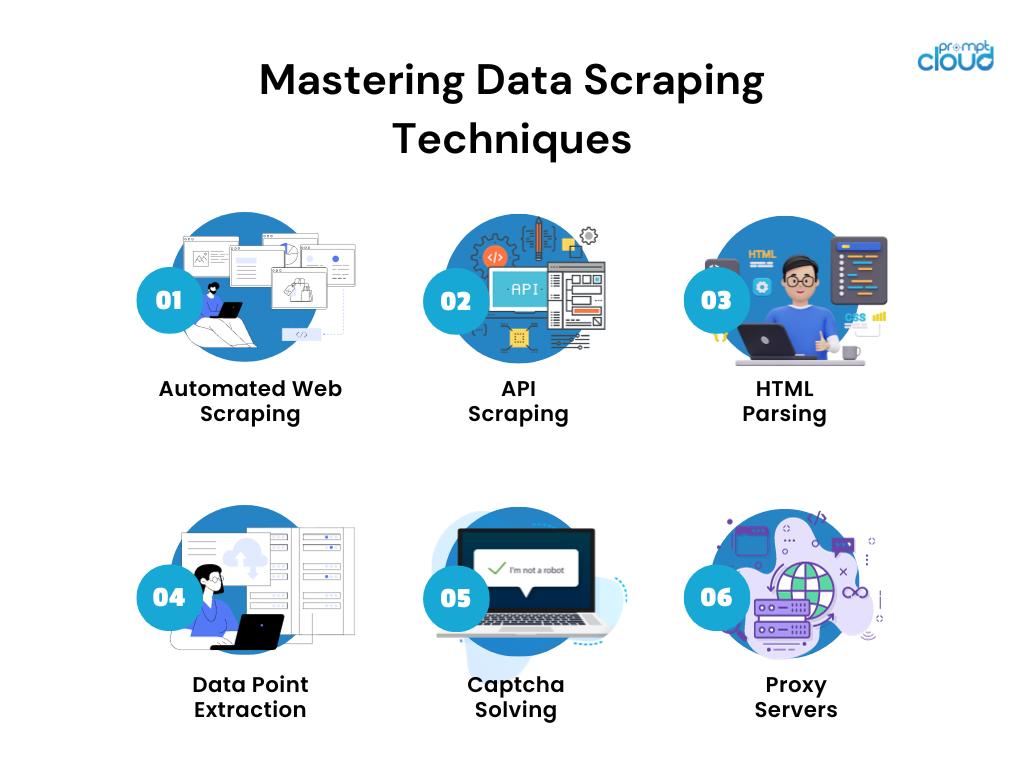
เทคนิคเหล่านี้ช่วยให้มั่นใจได้ว่าจะมีการดึงข้อมูลที่ละเอียดอ่อนและตรงเป้าหมาย โดยคำนึงถึงความสมดุลที่ละเอียดอ่อนระหว่างประสิทธิภาพและขอบเขตทางกฎหมายของการขูดเว็บ
แนวทางปฏิบัติที่ดีที่สุดสำหรับผลลัพธ์ที่มีคุณภาพ
เพื่อให้บรรลุผลลัพธ์ที่ยอดเยี่ยมในการขูดข้อมูล ให้ปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเหล่านี้:
- เคารพ Robots.txt: เล่นตามกฎที่ระบุไว้ในไฟล์ robots.txt ของเว็บไซต์ เข้าถึงได้เฉพาะข้อมูลที่ได้รับอนุญาตเท่านั้น
- สตริงตัวแทนผู้ใช้: แสดงสตริงตัวแทนผู้ใช้ที่ถูกต้องเพื่อหลีกเลี่ยงไม่ให้เว็บเซิร์ฟเวอร์สับสนเกี่ยวกับข้อมูลประจำตัวของเครื่องขูดของคุณ
- คำขอควบคุมปริมาณ: ใช้การหยุดชั่วคราวระหว่างคำขอเพื่อแบ่งเบาภาระเซิร์ฟเวอร์ ป้องกันการบล็อก IP ที่น่ากลัว
- การหลีกเลี่ยงปัญหาทางกฎหมาย: สำรวจภูมิทัศน์ของมาตรฐานทางกฎหมาย กฎหมายความเป็นส่วนตัวของข้อมูล และข้อกำหนดการใช้งานเว็บไซต์อย่างมีชั้นเชิง
- การจัดการข้อผิดพลาด: ออกแบบการจัดการข้อผิดพลาดที่มีประสิทธิภาพเพื่อนำทางการเปลี่ยนแปลงโครงสร้างเว็บไซต์ที่ไม่คาดคิดหรือปัญหาเซิร์ฟเวอร์ขัดข้อง
- การตรวจสอบคุณภาพข้อมูล: ตรวจดูและทำความสะอาดข้อมูลที่คัดลอกมาเป็นประจำเพื่อความถูกต้องและความสมบูรณ์
- การเข้ารหัสที่มีประสิทธิภาพ: ใช้แนวทางปฏิบัติในการเขียนโค้ดที่มีประสิทธิภาพเพื่อสร้างเครื่องขูดที่ปรับขนาดได้และบำรุงรักษาได้
- แหล่งข้อมูลที่หลากหลาย: เพิ่มความสมบูรณ์และความน่าเชื่อถือของชุดข้อมูลของคุณโดยการรวบรวมข้อมูลจากหลายแหล่ง
ข้อพิจารณาทางจริยธรรมในโลกแห่งการขูดข้อมูล
แม้ว่าการขูดข้อมูลจะเผยให้เห็นข้อมูลเชิงลึกอันล้ำค่า แต่ก็ต้องดำเนินการด้วยความรอบคอบทางจริยธรรม:

- การเคารพความเป็นส่วนตัว: ปฏิบัติต่อข้อมูลส่วนบุคคลโดยคำนึงถึงความเป็นส่วนตัวสูงสุด โดยสอดคล้องกับกฎระเบียบ เช่น GDPR
- ความโปร่งใส: แจ้งให้ผู้ใช้ทราบหากมีการรวบรวมข้อมูลของตนและเพื่อวัตถุประสงค์ใด
- ความซื่อสัตย์: หลีกเลี่ยงการล่อลวงเพื่อจัดการข้อมูลที่คัดลอกมาในลักษณะที่ทำให้เข้าใจผิดหรือเป็นอันตราย
- การใช้ข้อมูล: ใช้ข้อมูลอย่างมีความรับผิดชอบ เพื่อให้มั่นใจว่าจะเป็นประโยชน์ต่อผู้ใช้ และหลีกเลี่ยงแนวทางปฏิบัติที่เป็นการเลือกปฏิบัติ
- การปฏิบัติตามกฎหมาย: ปฏิบัติตามกฎหมายที่ควบคุมกิจกรรมการขูดข้อมูลเพื่อหลีกเลี่ยงผลกระทบทางกฎหมายที่อาจเกิดขึ้น

ที่มาของภาพ: https://dataforest.ai/
กรณีการใช้งานการขูดข้อมูล
สำรวจการใช้งานที่หลากหลายของการขูดข้อมูลในอุตสาหกรรมต่างๆ:
- การเงิน: ค้นพบแนวโน้มของตลาดโดยคัดลอกฟอรั่มทางการเงินและไซต์ข่าว จับตาราคาของคู่แข่งเพื่อหาโอกาสในการลงทุน
- โรงแรม: รวบรวมบทวิจารณ์ของลูกค้าจากแพลตฟอร์มต่างๆ เพื่อวิเคราะห์ความพึงพอใจของแขก ติดตามราคาของคู่แข่งเพื่อดูกลยุทธ์การกำหนดราคาที่เหมาะสมที่สุด
- สายการบิน: รวบรวมและเปรียบเทียบข้อมูลราคาเที่ยวบินเพื่อการวิเคราะห์การแข่งขัน ติดตามที่นั่งว่างเพื่อแจ้งโมเดลราคาแบบไดนามิก
- อีคอมเมิร์ซ: ขูดรายละเอียดผลิตภัณฑ์ รีวิว และราคาจากผู้ขายต่างๆ เพื่อเปรียบเทียบตลาด ตรวจสอบระดับสต็อกข้ามแพลตฟอร์มเพื่อการจัดการห่วงโซ่อุปทานที่มีประสิทธิภาพ
บทสรุป: สร้างสมดุลที่กลมกลืนในการขูดข้อมูล
ขณะที่เราผจญภัยในโลกอันกว้างใหญ่ของการขูดรีดข้อมูล การค้นหาจุดที่น่าสนใจคือกุญแจสำคัญ ด้วยเครื่องมือที่เหมาะสม เทคนิคที่เชี่ยวชาญ และความทุ่มเทในการทำสิ่งที่ถูกต้อง ทั้งธุรกิจและบุคคลจะสามารถเข้าถึงพลังที่แท้จริงของการขูดข้อมูลได้
เมื่อเราจัดการกับแนวทางปฏิบัติที่เปลี่ยนแปลงเกมนี้ด้วยความรับผิดชอบและเปิดกว้าง ไม่เพียงจุดประกายนวัตกรรมเท่านั้น แต่ยังมีบทบาทในการกำหนดระบบนิเวศของข้อมูลที่รอบคอบและเจริญรุ่งเรืองสำหรับทุกคนที่เกี่ยวข้อง
คำถามที่พบบ่อย:
งานขูดข้อมูลคืออะไร?
งานขูดข้อมูลเกี่ยวข้องกับการดึงข้อมูลจากเว็บไซต์ ทำให้บุคคลหรือธุรกิจรวบรวมข้อมูลอันมีค่าเพื่อวัตถุประสงค์ต่างๆ เช่น การวิจัยตลาด การวิเคราะห์การแข่งขัน หรือการติดตามแนวโน้ม เหมือนกับการมีนักสืบที่ค้นหาเนื้อหาเว็บเพื่อค้นหาอัญมณีที่ซ่อนอยู่
การขูดข้อมูลถูกกฎหมายหรือไม่?
ความถูกต้องตามกฎหมายของการขูดข้อมูลขึ้นอยู่กับวิธีการดำเนินการและเคารพข้อกำหนดการใช้งานและข้อบังคับความเป็นส่วนตัวของเว็บไซต์เป้าหมายหรือไม่ โดยทั่วไป การคัดลอกข้อมูลสาธารณะเพื่อการใช้งานส่วนบุคคลอาจถูกกฎหมาย แต่การคัดลอกข้อมูลส่วนตัวหรือข้อมูลที่มีลิขสิทธิ์โดยไม่ได้รับอนุญาตมีแนวโน้มว่าจะผิดกฎหมาย สิ่งสำคัญคือต้องตระหนักและปฏิบัติตามขอบเขตทางกฎหมายเพื่อหลีกเลี่ยงผลที่ตามมาที่อาจเกิดขึ้น
เทคนิคการขูดข้อมูลคืออะไร?
เทคนิคการคัดลอกข้อมูลครอบคลุมวิธีการต่างๆ มากมาย ตั้งแต่การคัดลอกเว็บอัตโนมัติโดยใช้บอทหรือโปรแกรมรวบรวมข้อมูล ไปจนถึงการใช้ประโยชน์จาก API สำหรับการดึงข้อมูลที่มีโครงสร้าง การแยกวิเคราะห์ HTML การแยกจุดข้อมูล การแก้ปัญหา captcha และพร็อกซีเซิร์ฟเวอร์ เป็นหนึ่งในเทคนิคต่างๆ ที่ใช้ในการรวบรวมข้อมูลจากแหล่งต่างๆ ได้อย่างมีประสิทธิภาพ การเลือกเทคนิคขึ้นอยู่กับข้อกำหนดเฉพาะของโครงการขูด
การขูดข้อมูลเป็นเรื่องง่ายหรือไม่?
การขูดข้อมูลจะง่ายหรือไม่นั้นขึ้นอยู่กับความซับซ้อนของงานและเครื่องมือหรือเทคนิคที่เกี่ยวข้อง สำหรับผู้ที่ไม่มีความเชี่ยวชาญด้านเทคนิค ซอฟต์แวร์การขูดเว็บที่ใช้งานง่ายหรือการจ้างผู้ให้บริการขูดเว็บจะทำให้กระบวนการง่ายขึ้น การเลือกจ้างบุคคลภายนอกช่วยให้บุคคลหรือธุรกิจสามารถใช้ประโยชน์จากความเชี่ยวชาญของผู้เชี่ยวชาญ ทำให้มั่นใจได้ว่าการดึงข้อมูลที่แม่นยำและมีประสิทธิภาพ โดยไม่ต้องเจาะลึกถึงความซับซ้อนทางเทคนิคของกระบวนการขูด