
Robots.txt ใน SEO คืออะไร: วิธีสร้างและเพิ่มประสิทธิภาพ
เผยแพร่แล้ว: 2022-04-22หัวข้อของวันนี้ไม่เกี่ยวข้องโดยตรงกับการสร้างรายได้จากการเข้าชม แต่ robots.txt สามารถส่งผลกระทบต่อ SEO ของเว็บไซต์ของคุณ และในที่สุด ปริมาณการรับส่งข้อมูลที่ได้รับ ผู้ดูแลเว็บหลายคนทำลายอันดับเว็บไซต์ของตนเนื่องจากรายการ robots.txt ที่ไม่เรียบร้อย คู่มือนี้จะช่วยคุณหลีกเลี่ยงข้อผิดพลาดทั้งหมด อย่าลืมอ่านให้จบ!
- ไฟล์ robots.txt คืออะไร
- ไฟล์ robots.txt มีลักษณะอย่างไร
- วิธีค้นหาไฟล์ robots.txt ของคุณ
- ไฟล์ Robots.txt ทำงานอย่างไร
- ไวยากรณ์ Robots.txt
- คำสั่งที่รองรับ
- ตัวแทนผู้ใช้*
- อนุญาต
- ไม่อนุญาต
- แผนผังเว็บไซต์
- คำสั่งที่ไม่รองรับ
- รวบรวมข้อมูลล่าช้า
- Noindex
- ไม่ปฏิบัติตาม
- คุณต้องการไฟล์ robots.txt หรือไม่?
- การสร้างไฟล์ robots.txt
- ไฟล์ Robots.txt: แนวทางปฏิบัติที่ดีที่สุดสำหรับ SEO
- ใช้บรรทัดใหม่สำหรับแต่ละคำสั่ง
- ใช้สัญลักษณ์แทนเพื่อลดความซับซ้อนของคำแนะนำ
- ใช้เครื่องหมายดอลลาร์ “$” เพื่อระบุส่วนท้ายของ URL
- ใช้แต่ละ user-agent เพียงครั้งเดียว
- ใช้คำแนะนำเฉพาะเพื่อหลีกเลี่ยงข้อผิดพลาดที่ไม่ได้ตั้งใจ
- ป้อนความคิดเห็นในไฟล์ robots.txt ด้วย hash
- ใช้ไฟล์ robots.txt ที่แตกต่างกันสำหรับแต่ละโดเมนย่อย
- อย่าปิดกั้นเนื้อหาที่ดี
- อย่าใช้ความล่าช้าในการรวบรวมข้อมูลมากเกินไป
- ใส่ใจกับความละเอียดอ่อนของตัวพิมพ์
- แนวทางปฏิบัติที่ดีที่สุดอื่นๆ:
- การใช้ robots.txt เพื่อป้องกันการสร้างดัชนีเนื้อหา
- การใช้ robots.txt เพื่อป้องกันเนื้อหาส่วนตัว
- การใช้ robots.txt เพื่อซ่อนเนื้อหาที่ซ้ำกันที่เป็นอันตราย
- เข้าถึงได้ทั้งหมดสำหรับบอททั้งหมด
- ไม่มีการเข้าถึงสำหรับบอททั้งหมด
- บล็อกไดเรกทอรีย่อยหนึ่งรายการสำหรับบอททั้งหมด
- บล็อกไดเรกทอรีย่อยหนึ่งรายการสำหรับบอททั้งหมด (โดยอนุญาตให้มีไฟล์เดียว)
- บล็อกไฟล์เดียวสำหรับบอททั้งหมด
- บล็อกหนึ่งประเภทไฟล์ (PDF) สำหรับบอททั้งหมด
- บล็อก URL ที่มีการกำหนดพารามิเตอร์ทั้งหมดสำหรับ Googlebot เท่านั้น
- วิธีทดสอบไฟล์ robots.txt เพื่อหาข้อผิดพลาด
- URL ที่ส่งถูกบล็อกโดย robots.txt
- ถูกบล็อกโดย robots.txt
- จัดทำดัชนี แม้ว่าจะถูกบล็อกโดย robots.txt
- Robots.txt เทียบกับ meta robots เทียบกับ x-robots
- อ่านเพิ่มเติม
- ห่อ
ไฟล์ robots.txt คืออะไร
robots.txt หรือโปรโตคอลการยกเว้นโรบ็อตคือชุดของมาตรฐานเว็บที่ควบคุมวิธีที่โรบ็อตของเครื่องมือค้นหารวบรวมข้อมูลทุกหน้าเว็บ ไปจนถึงมาร์กอัปสคีมาในหน้านั้น เป็นไฟล์ข้อความมาตรฐานที่สามารถป้องกันไม่ให้โปรแกรมรวบรวมข้อมูลเว็บเข้าถึงเว็บไซต์ทั้งหมดหรือบางส่วนของเว็บไซต์ได้
ในขณะที่ปรับ SEO และแก้ปัญหาทางเทคนิค คุณสามารถเริ่มรับรายได้จากโฆษณาได้ รหัสบรรทัดเดียวในเว็บไซต์ของคุณส่งคืนการจ่ายเงินเป็นประจำ!
ไปที่เนื้อหา↑ไฟล์ robots.txt มีลักษณะอย่างไร
ไวยากรณ์เรียบง่าย: คุณกำหนดกฎบอทโดยระบุตัวแทนผู้ใช้และคำสั่ง ไฟล์มีรูปแบบพื้นฐานดังต่อไปนี้:
แผนผังเว็บไซต์: [ตำแหน่ง URL ของแผนผังเว็บไซต์]
User-agent: [ตัวระบุบอท]
[คำสั่ง 1]
[คำสั่ง 2]
[คำสั่ง…]
User-agent: [ตัวระบุบอทอื่น]
[คำสั่ง 1]
[คำสั่ง 2]
[คำสั่ง…]
วิธีค้นหาไฟล์ robots.txt ของคุณ
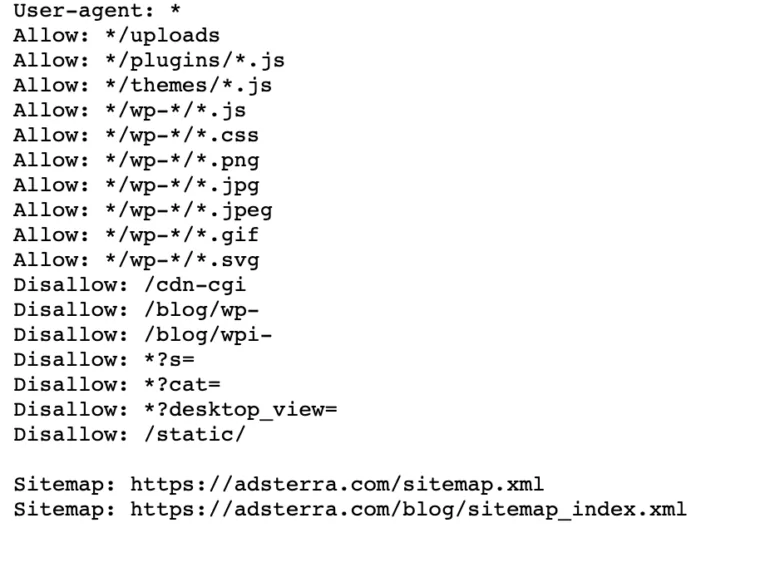
หากเว็บไซต์ของคุณมีไฟล์ robot.txt อยู่แล้ว คุณสามารถค้นหาได้โดยไปที่ URL นี้: https://yourdomainname.com/robots.txt ในเบราว์เซอร์ของคุณ ตัวอย่างเช่น นี่คือไฟล์ของเรา
ไฟล์ Robots.txt ทำงานอย่างไร
ไฟล์ robots.txt เป็นไฟล์ข้อความธรรมดาที่ไม่มีโค้ดมาร์กอัป HTML (จึงเป็นนามสกุล .txt) ไฟล์นี้ เช่นเดียวกับไฟล์อื่นๆ ทั้งหมดบนเว็บไซต์ ถูกจัดเก็บไว้บนเว็บเซิร์ฟเวอร์ ผู้ใช้ไม่น่าจะเข้าชมหน้านี้เนื่องจากไม่ได้เชื่อมโยงกับหน้าเว็บใดๆ ของคุณ แต่บ็อตของโปรแกรมรวบรวมข้อมูลเว็บส่วนใหญ่จะค้นหาหน้านี้ก่อนที่จะรวบรวมข้อมูลเว็บไซต์ทั้งหมด
ไฟล์ robots.txt สามารถให้คำแนะนำบ็อตได้ แต่ไม่สามารถบังคับใช้คำแนะนำเหล่านั้นได้ บอทที่ดี เช่น โปรแกรมรวบรวมข้อมูลเว็บหรือบอทฟีดข่าว จะตรวจสอบไฟล์และปฏิบัติตามคำแนะนำก่อนที่จะไปที่หน้าโดเมนใดๆ แต่บอทที่เป็นอันตรายจะเพิกเฉยหรือประมวลผลไฟล์เพื่อค้นหาหน้าเว็บที่ต้องห้าม
ในสถานการณ์ที่ไฟล์ robots.txt มีคำสั่งที่ขัดแย้งกัน บอทจะใช้ชุดคำสั่งที่เจาะจงที่สุด
ไปที่เนื้อหา↑ไวยากรณ์ Robots.txt
ไฟล์ robots.txt ประกอบด้วย 'คำสั่ง' หลายส่วน โดยแต่ละส่วนเริ่มต้นด้วย user-agent user-agent ระบุบอทการตระเวนที่โค้ดใช้สื่อสาร คุณสามารถระบุเครื่องมือค้นหาทั้งหมดพร้อมกันหรือจัดการเครื่องมือค้นหาแต่ละรายการ
เมื่อใดก็ตามที่บอทรวบรวมข้อมูลเว็บไซต์ บอทจะทำหน้าที่ในส่วนของไซต์ที่เรียกมัน
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /
User-agent: Googlebot
ไม่อนุญาต:
ตัวแทนผู้ใช้: Bingbot
ไม่อนุญาต: /not-for-bing/
คำสั่งที่รองรับ
คำสั่งเป็นแนวทางที่คุณต้องการให้ตัวแทนผู้ใช้ที่คุณประกาศปฏิบัติตาม ปัจจุบัน Google สนับสนุนคำสั่งต่อไปนี้
ตัวแทนผู้ใช้*
เมื่อโปรแกรมเชื่อมต่อกับเว็บเซิร์ฟเวอร์ (หุ่นยนต์หรือเว็บเบราว์เซอร์ทั่วไป) จะส่งส่วนหัว HTTP ที่เรียกว่า "ตัวแทนผู้ใช้" ที่มีข้อมูลพื้นฐานเกี่ยวกับข้อมูลประจำตัว เครื่องมือค้นหาทุกเครื่องมีตัวแทนผู้ใช้ หุ่นยนต์ของ Google เป็นที่รู้จักในชื่อ Googlebot, Yahoo's - ในชื่อ Slurp และ Bing - ในชื่อ BingBot user-agent เริ่มต้นลำดับของคำสั่ง ซึ่งสามารถนำไปใช้กับ user-agent เฉพาะหรือ user-agent ทั้งหมด
อนุญาต
คำสั่ง allow จะบอกเครื่องมือค้นหาให้รวบรวมข้อมูลหน้าหรือไดเรกทอรีย่อย แม้แต่ไดเรกทอรีที่จำกัด ตัวอย่างเช่น หากคุณต้องการให้เสิร์ชเอ็นจิ้นไม่สามารถเข้าถึงโพสต์ทั้งหมดในบล็อกของคุณ ยกเว้นโพสต์เดียว ไฟล์ robots.txt ของคุณอาจมีลักษณะดังนี้:
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /blog
อนุญาต: /blog/allowed-post
อย่างไรก็ตาม เสิร์ชเอ็นจิ้นสามารถเข้าถึง /blog/allowed-post แต่ไม่สามารถเข้าถึง:
/blog/another-post
/blog/yet-another-post
/blog/download-me.pd
ไม่อนุญาต
คำสั่ง disallow (ซึ่งถูกเพิ่มลงในไฟล์ robots.txt ของเว็บไซต์) บอกให้เครื่องมือค้นหาไม่รวบรวมข้อมูลหน้าใดหน้าหนึ่งโดยเฉพาะ ในกรณีส่วนใหญ่ การทำเช่นนี้จะป้องกันไม่ให้หน้าปรากฏในผลการค้นหา
คุณสามารถใช้คำสั่งนี้เพื่อสั่งไม่ให้เครื่องมือค้นหารวบรวมข้อมูลไฟล์และหน้าในโฟลเดอร์เฉพาะที่คุณซ่อนจากบุคคลทั่วไป ตัวอย่างเช่น เนื้อหาที่คุณยังคงทำงานอยู่แต่เผยแพร่ผิดพลาด ไฟล์ robots.txt ของคุณอาจมีลักษณะดังนี้หากคุณต้องการป้องกันไม่ให้เครื่องมือค้นหาทั้งหมดเข้าถึงบล็อกของคุณ:
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /blog
ซึ่งหมายความว่าไดเรกทอรีย่อยทั้งหมดของไดเร็กทอรี /blog จะไม่ถูกรวบรวมข้อมูลด้วย นอกจากนี้ยังจะบล็อก Google ไม่ให้เข้าถึง URL ที่มี /blog
ไปที่เนื้อหา↑แผนผังเว็บไซต์
แผนผังเว็บไซต์คือรายการของหน้าที่คุณต้องการให้เครื่องมือค้นหารวบรวมข้อมูลและจัดทำดัชนี หากคุณใช้คำสั่งแผนผังเว็บไซต์ เครื่องมือค้นหาจะทราบตำแหน่งของแผนผังเว็บไซต์ XML ของคุณ ตัวเลือกที่ดีที่สุดคือการส่งไปยังเครื่องมือของผู้ดูแลเว็บของเครื่องมือค้นหาเพราะแต่ละรายการสามารถให้ข้อมูลที่มีค่าเกี่ยวกับเว็บไซต์ของคุณสำหรับผู้เยี่ยมชม
สิ่งสำคัญที่ควรทราบคือ การทำซ้ำคำสั่งแผนผังเว็บไซต์สำหรับ user-agent แต่ละรายนั้นไม่จำเป็น และไม่ใช้กับตัวแทนการค้นหาเพียงรายเดียว เพิ่มคำสั่งแผนผังเว็บไซต์ที่จุดเริ่มต้นหรือจุดสิ้นสุดของไฟล์ robots.txt
ตัวอย่างของคำสั่งแผนผังเว็บไซต์ในไฟล์:
แผนผังเว็บไซต์: https://www.domain.com/sitemap.xml
User-agent: Googlebot
ไม่อนุญาต: /บล็อก/
อนุญาต: /blog/post-title/
ตัวแทนผู้ใช้: Bingbot
ไม่อนุญาต: /บริการ/
ไปที่เนื้อหา↑คำสั่งที่ไม่รองรับ
ต่อไปนี้คือคำสั่งที่ Google ไม่สนับสนุนอีกต่อไป ซึ่งบางคำสั่งไม่ได้รับการรับรองในทางเทคนิค
รวบรวมข้อมูลล่าช้า
Yahoo, Bing และ Yandex ตอบสนองต่อการสร้างดัชนีของเว็บไซต์อย่างรวดเร็วและตอบสนองต่อคำสั่งการหน่วงเวลาการรวบรวมข้อมูล ซึ่งช่วยให้ตรวจสอบได้ชั่วขณะหนึ่ง
ใช้บรรทัดนี้กับบล็อกของคุณ:
ตัวแทนผู้ใช้: Bingbot
รวบรวมข้อมูลล่าช้า: 10
หมายความว่าเสิร์ชเอ็นจิ้นสามารถรอสิบวินาทีก่อนที่จะรวบรวมข้อมูลเว็บไซต์หรือสิบวินาทีก่อนที่จะเข้าถึงเว็บไซต์อีกครั้งหลังจากรวบรวมข้อมูลซึ่งเป็นสิ่งเดียวกัน แต่แตกต่างกันเล็กน้อยขึ้นอยู่กับตัวแทนผู้ใช้ที่ใช้งาน
Noindex
เมตาแท็ก noindex เป็นวิธีที่ยอดเยี่ยมในการป้องกันไม่ให้เครื่องมือค้นหาจัดทำดัชนีหน้าใดหน้าหนึ่งของคุณ แท็กนี้อนุญาตให้บอทเข้าถึงหน้าเว็บ แต่ยังแจ้งให้โรบ็อตไม่จัดทำดัชนี
- ส่วนหัว HTTP Response พร้อมแท็ก noindex คุณสามารถใช้แท็กนี้ได้สองวิธี: ส่วนหัวการตอบสนอง HTTP ที่มี X-Robots-Tag หรือแท็ก <meta> ที่วางอยู่ภายในส่วน <head> นี่คือลักษณะที่แท็ก <meta> ของคุณควรมีลักษณะ:
<ชื่อเมตา=”หุ่นยนต์”เนื้อหา=”noindex”>
- รหัสสถานะ HTTP 404 & 410 รหัสสถานะ 404 และ 410 ระบุว่าไม่มีหน้าดังกล่าวแล้ว หลังจากรวบรวมข้อมูลและประมวลผลหน้า 404/410 แล้ว ระบบจะลบออกจากดัชนีของ Google โดยอัตโนมัติ เพื่อลดความเสี่ยงของหน้าข้อผิดพลาด 404 และ 410 ให้รวบรวมข้อมูลเว็บไซต์ของคุณเป็นประจำและใช้การเปลี่ยนเส้นทาง 301 เพื่อนำการเข้าชมไปยังหน้าที่มีอยู่ตามความจำเป็น
ไม่ปฏิบัติตาม
Nofollow สั่งให้เครื่องมือค้นหาไม่ติดตามลิงก์ในหน้าและไฟล์ภายใต้เส้นทางเฉพาะ ตั้งแต่วันที่ 1 มีนาคม 2020 Google จะไม่ถือว่าแอตทริบิวต์ nofollow เป็นคำสั่งอีกต่อไป แต่จะเป็นการบอกใบ้แทน เช่นเดียวกับแท็กบัญญัติ หากคุณต้องการแอตทริบิวต์ "nofollow" สำหรับลิงก์ทั้งหมดบนหน้าเว็บ ให้ใช้เมตาแท็กของโรบ็อต ส่วนหัว x-robots หรือแอตทริบิวต์ลิงก์ rel= "nofollow"
ก่อนหน้านี้ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อป้องกันไม่ให้ Google ติดตามลิงก์ทั้งหมดในบล็อกของคุณ:
User-agent: Googlebot
กดติดตาม: /blog/
คุณต้องการไฟล์ robots.txt หรือไม่?
เว็บไซต์ที่ซับซ้อนน้อยกว่าจำนวนมากไม่จำเป็นต้องมี แม้ว่าโดยปกติ Google จะไม่สร้างดัชนีหน้าเว็บที่ถูกบล็อกโดย robots.txt แต่ก็ไม่มีทางรับประกันได้ว่าหน้าเหล่านี้จะไม่ปรากฏในผลการค้นหา การมีไฟล์นี้จะช่วยให้คุณควบคุมและรักษาความปลอดภัยเนื้อหาบนเว็บไซต์ของคุณได้มากกว่าเครื่องมือค้นหา
ไฟล์ Robots ยังช่วยให้คุณทำสิ่งต่อไปนี้ได้สำเร็จ:
- ป้องกันไม่ให้มีการรวบรวมข้อมูลเนื้อหาที่ซ้ำกัน
- รักษาความเป็นส่วนตัวสำหรับส่วนต่างๆ ของเว็บไซต์
- จำกัดการรวบรวมข้อมูลผลการค้นหาภายใน
- ป้องกันไม่ให้เซิร์ฟเวอร์โอเวอร์โหลด
- ป้องกันไม่ให้ “รวบรวมข้อมูลงบประมาณ” สูญเปล่า
- เก็บรูปภาพ วิดีโอ และไฟล์ทรัพยากรออกจากผลการค้นหาของ Google
มาตรการเหล่านี้ส่งผลต่อกลยุทธ์ SEO ของคุณในที่สุด ตัวอย่างเช่น เนื้อหาที่ซ้ำกันจะสร้างความสับสนให้กับเครื่องมือค้นหาและบังคับให้พวกเขาเลือกว่าจะให้หน้าใดในสองอันดับแรก ไม่ว่าใครเป็นคนสร้างเนื้อหา Google อาจไม่เลือกหน้าเดิมสำหรับผลการค้นหายอดนิยม

ในกรณีที่ Google ตรวจพบเนื้อหาที่ซ้ำกันซึ่งมีจุดประสงค์เพื่อหลอกลวงผู้ใช้หรือบิดเบือนการจัดอันดับ พวกเขาจะปรับการจัดทำดัชนีและการจัดอันดับเว็บไซต์ของคุณ ด้วยเหตุนี้ การจัดอันดับเว็บไซต์ของคุณจึงอาจได้รับผลกระทบหรือถูกลบออกจากดัชนีของ Google โดยสิ้นเชิง และหายไปจากผลการค้นหา
การรักษาความเป็นส่วนตัวสำหรับส่วนต่างๆ ของเว็บไซต์ยังช่วยปรับปรุงความปลอดภัยของเว็บไซต์ของคุณและปกป้องเว็บไซต์จากแฮกเกอร์อีกด้วย ในระยะยาว มาตรการเหล่านี้จะทำให้เว็บไซต์ของคุณปลอดภัย น่าเชื่อถือ และให้ผลกำไรมากขึ้น
คุณเป็นเจ้าของเว็บไซต์ที่ต้องการทำกำไรจากการเข้าชมหรือไม่? ด้วย Adsterra คุณจะได้รับรายได้จากทุกเว็บไซต์!
ไปที่เนื้อหา↑การสร้างไฟล์ robots.txt
คุณจะต้องใช้โปรแกรมแก้ไขข้อความ เช่น Notepad
- สร้างแผ่นงานใหม่ บันทึกหน้าว่างเป็น 'robots.txt' และเริ่มพิมพ์คำสั่งในเอกสาร .txt เปล่า
- เข้าสู่ระบบ cPanel ของคุณ ไปที่ไดเร็กทอรีรากของไซต์ ค้นหาโฟลเดอร์ public_html
- ลากไฟล์ของคุณไปที่โฟลเดอร์นี้ จากนั้นตรวจสอบอีกครั้งว่าสิทธิ์ของไฟล์นั้นตั้งค่าไว้ถูกต้องหรือไม่
คุณสามารถเขียน อ่าน และแก้ไขไฟล์ได้ในฐานะเจ้าของ แต่ไม่อนุญาตให้บุคคลที่สาม รหัสอนุญาต "0644" ควรปรากฏในไฟล์ หากไม่เป็นเช่นนั้น ให้คลิกขวาที่ไฟล์แล้วเลือก "การอนุญาตไฟล์"
ไฟล์ Robots.txt: แนวทางปฏิบัติที่ดีที่สุดสำหรับ SEO
ใช้บรรทัดใหม่สำหรับแต่ละคำสั่ง
คุณต้องประกาศคำสั่งแต่ละบรรทัดแยกกัน มิฉะนั้น เครื่องมือค้นหาจะสับสน
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /directory/
ไม่อนุญาต: /another-directory/
ใช้สัญลักษณ์แทนเพื่อลดความซับซ้อนของคำแนะนำ
คุณสามารถใช้สัญลักษณ์แทน (*) สำหรับ user-agent ทั้งหมด และจับคู่รูปแบบ URL เมื่อประกาศคำสั่ง Wildcard ทำงานได้ดีกับ URL ที่มีรูปแบบเหมือนกัน ตัวอย่างเช่น คุณอาจต้องการป้องกันไม่ให้มีการรวบรวมข้อมูลหน้าตัวกรองทั้งหมดที่มีเครื่องหมายคำถาม (?) ใน URL
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /*?
ใช้เครื่องหมายดอลลาร์ “$” เพื่อระบุส่วนท้ายของ URL
เครื่องมือค้นหาไม่สามารถเข้าถึง URL ที่ลงท้ายด้วยนามสกุลเช่น .pdf นั่นหมายความว่าพวกเขาจะเข้าถึง /file.pdf ไม่ได้ แต่จะสามารถเข้าถึง /file.pdf?id=68937586 ซึ่งไม่ได้ลงท้ายด้วย “.pdf” ตัวอย่างเช่น หากคุณต้องการป้องกันไม่ให้เครื่องมือค้นหาเข้าถึงไฟล์ PDF ทั้งหมดบนเว็บไซต์ของคุณ ไฟล์ robots.txt ของคุณอาจมีลักษณะดังนี้:
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /*.pdf$
ใช้แต่ละ user-agent เพียงครั้งเดียว
ใน Google ไม่สำคัญว่าคุณจะใช้ user-agent เดียวกันมากกว่าหนึ่งครั้งหรือไม่ มันจะรวบรวมกฎทั้งหมดจากการประกาศต่างๆ ให้เป็นคำสั่งเดียวและปฏิบัติตาม อย่างไรก็ตาม การประกาศ user-agent แต่ละรายการเพียงครั้งเดียวก็สมเหตุสมผลแล้ว เพราะมันทำให้เกิดความสับสนน้อยลง
การรักษาคำสั่งของคุณให้เป็นระเบียบและเรียบง่ายช่วยลดความเสี่ยงของข้อผิดพลาดร้ายแรง ตัวอย่างเช่น หากไฟล์ robots.txt ของคุณมี user-agent และคำสั่งต่อไปนี้
User-agent: Googlebot
ไม่อนุญาต: /a/
User-agent: Googlebot
ไม่อนุญาต: /b/
ใช้คำแนะนำเฉพาะเพื่อหลีกเลี่ยงข้อผิดพลาดที่ไม่ได้ตั้งใจ
เมื่อตั้งค่าคำสั่ง การไม่ให้คำแนะนำที่เฉพาะเจาะจงอาจทำให้เกิดข้อผิดพลาดที่อาจเป็นอันตรายต่อ SEO ของคุณ สมมติว่าคุณมีไซต์หลายภาษาและกำลังทำงานในเวอร์ชันภาษาเยอรมันสำหรับไดเร็กทอรีย่อย /de/
คุณไม่ต้องการให้เครื่องมือค้นหาสามารถเข้าถึงได้เนื่องจากยังไม่พร้อม ไฟล์ robots.txt ต่อไปนี้จะป้องกันไม่ให้เครื่องมือค้นหาสร้างดัชนีโฟลเดอร์ย่อยนั้นและเนื้อหา:
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /de
อย่างไรก็ตาม จะจำกัดเครื่องมือค้นหาไม่ให้รวบรวมข้อมูลหน้าหรือไฟล์ใดๆ ที่ขึ้นต้นด้วย /de ในกรณีนี้ การเพิ่มเครื่องหมายทับเป็นวิธีแก้ปัญหาง่ายๆ
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /de/
ไปที่เนื้อหา↑ป้อนความคิดเห็นในไฟล์ robots.txt ด้วย hash
ความคิดเห็นช่วยให้นักพัฒนาและแม้กระทั่งคุณเข้าใจไฟล์ robots.txt ของคุณ ขึ้นต้นบรรทัดด้วยแฮช (#) เพื่อใส่ความคิดเห็น โปรแกรมรวบรวมข้อมูลละเว้นบรรทัดที่ขึ้นต้นด้วยแฮช
# สิ่งนี้สั่งให้บอท Bing ไม่รวบรวมข้อมูลเว็บไซต์ของเรา
ตัวแทนผู้ใช้: Bingbot
ไม่อนุญาต: /
ใช้ไฟล์ robots.txt ที่แตกต่างกันสำหรับแต่ละโดเมนย่อย
Robots.txt มีผลกับการรวบรวมข้อมูลในโดเมนโฮสต์เท่านั้น คุณจะต้องใช้ไฟล์อื่นเพื่อจำกัดการรวบรวมข้อมูลในโดเมนย่อยอื่น ตัวอย่างเช่น หากคุณโฮสต์เว็บไซต์หลักบน example.com และบล็อกของคุณบน blog.example.com คุณจะต้องมีไฟล์ robots.txt สองไฟล์ วางไฟล์หนึ่งไว้ในไดเร็กทอรีรากของโดเมนหลัก ในขณะที่ไฟล์อื่นควรอยู่ในไดเร็กทอรีรากของบล็อก
อย่าปิดกั้นเนื้อหาที่ดี
อย่าใช้ไฟล์ robots.txt หรือแท็ก noindex เพื่อบล็อกเนื้อหาคุณภาพใดๆ ที่คุณต้องการเผยแพร่สู่สาธารณะ เพื่อหลีกเลี่ยงผลกระทบด้านลบต่อผลลัพธ์ SEO ตรวจสอบแท็ก noindex อย่างละเอียดและไม่อนุญาตกฎในหน้าเว็บของคุณ
อย่าใช้ความล่าช้าในการรวบรวมข้อมูลมากเกินไป
เราได้อธิบายความล่าช้าในการรวบรวมข้อมูลแล้ว แต่คุณไม่ควรใช้บ่อย เพราะมันจำกัดบอทจากการรวบรวมข้อมูลทุกหน้า อาจใช้ได้กับบางเว็บไซต์ แต่คุณอาจส่งผลเสียต่ออันดับและการเข้าชมหากคุณมีเว็บไซต์ขนาดใหญ่
ใส่ใจกับความละเอียดอ่อนของตัวพิมพ์
ไฟล์ Robots.txt คำนึงถึงขนาดตัวพิมพ์ ดังนั้นคุณต้องแน่ใจว่าคุณสร้างไฟล์ Robots ในรูปแบบที่ถูกต้อง ไฟล์โรบ็อตควรตั้งชื่อว่า 'robots.txt' โดยใช้อักษรตัวพิมพ์เล็กทั้งหมด มิฉะนั้นมันจะไม่ทำงาน
แนวทางปฏิบัติที่ดีที่สุดอื่นๆ:
- ตรวจสอบให้แน่ใจว่าคุณไม่ได้บล็อกเนื้อหาหรือส่วนต่างๆ ของเว็บไซต์จากการรวบรวมข้อมูล
- อย่าใช้ robots.txt เพื่อเก็บข้อมูลสำคัญ (ข้อมูลผู้ใช้ส่วนตัว) ออกจากผลลัพธ์ SERP ใช้วิธีการอื่น เช่น การเข้ารหัสข้อมูลหรือคำสั่ง meta ของ noindex เพื่อจำกัดการเข้าถึงหากหน้าอื่นลิงก์โดยตรงไปยังหน้าส่วนตัว
- เครื่องมือค้นหาบางตัวมี user-agent มากกว่าหนึ่งตัว ตัวอย่างเช่น Google ใช้ Googlebot สำหรับการค้นหาทั่วไปและ Googlebot-Image สำหรับรูปภาพ ไม่จำเป็นต้องระบุคำสั่งสำหรับโปรแกรมรวบรวมข้อมูลหลายตัวของเครื่องมือค้นหาแต่ละรายการ เนื่องจากตัวแทนผู้ใช้ส่วนใหญ่จากเครื่องมือค้นหาเดียวกันใช้กฎเดียวกัน
- เครื่องมือค้นหาแคชเนื้อหา robots.txt แต่อัปเดตทุกวัน หากคุณเปลี่ยนไฟล์และต้องการอัปเดตเร็วขึ้น คุณสามารถส่ง URL ของไฟล์ไปยัง Google
การใช้ robots.txt เพื่อป้องกันการสร้างดัชนีเนื้อหา
การปิดใช้งานหน้าเป็นวิธีที่มีประสิทธิภาพมากที่สุดในการป้องกันบอทจากการรวบรวมข้อมูลโดยตรง อย่างไรก็ตาม จะใช้ไม่ได้ในสถานการณ์ต่อไปนี้:
- หากแหล่งที่มาอื่นมีลิงก์ไปยังหน้า บอทจะยังรวบรวมข้อมูลและจัดทำดัชนี
- บอทที่ผิดกฎหมายจะรวบรวมข้อมูลและจัดทำดัชนีเนื้อหาต่อไป
การใช้ robots.txt เพื่อป้องกันเนื้อหาส่วนตัว
เนื้อหาส่วนตัวบางอย่าง เช่น PDF หรือหน้าขอบคุณ ยังสามารถจัดทำดัชนีได้แม้ว่าคุณจะบล็อกบอท การวางหน้าพิเศษทั้งหมดไว้ด้านหลังการเข้าสู่ระบบเป็นวิธีที่ดีที่สุดวิธีหนึ่งในการเสริมความแข็งแกร่งให้กับคำสั่งที่ไม่อนุญาต เนื้อหาของคุณจะยังคงมีอยู่ แต่ผู้เยี่ยมชมของคุณจะใช้ขั้นตอนเพิ่มเติมในการเข้าถึงเนื้อหา
การใช้ robots.txt เพื่อซ่อนเนื้อหาที่ซ้ำกันที่เป็นอันตราย
เนื้อหาที่ซ้ำกันจะเหมือนกันหรือคล้ายกันมากกับเนื้อหาอื่นในภาษาเดียวกัน Google พยายามจัดทำดัชนีและแสดงหน้าเว็บที่มีเนื้อหาเฉพาะ ตัวอย่างเช่น หากไซต์ของคุณมีเวอร์ชัน "ปกติ" และ "เครื่องพิมพ์" ของแต่ละบทความ และแท็ก noindex จะไม่บล็อกทั้งสองรายการ พวกเขาจะแสดงรายการใดเวอร์ชันหนึ่ง
ตัวอย่างไฟล์ robots.txt
ต่อไปนี้คือไฟล์ robots.txt ตัวอย่างบางส่วน สิ่งเหล่านี้มีไว้สำหรับแนวคิดเป็นหลัก แต่ถ้าหนึ่งในนั้นตรงตามความต้องการของคุณ ให้คัดลอกและวางลงในเอกสารข้อความ บันทึกเป็น “robots.txt” แล้วอัปโหลดไปยังไดเร็กทอรีที่เหมาะสม
เข้าถึงได้ทั้งหมดสำหรับบอททั้งหมด
มีหลายวิธีในการบอกให้เสิร์ชเอ็นจิ้นเข้าถึงไฟล์ทั้งหมด รวมถึงการมีไฟล์ robots.txt เปล่าหรือไม่มีเลย
ตัวแทนผู้ใช้: *
ไม่อนุญาต:
ไม่มีการเข้าถึงสำหรับบอททั้งหมด
ไฟล์ robots.txt ต่อไปนี้แนะนำให้เครื่องมือค้นหาทั้งหมดหลีกเลี่ยงการเข้าถึงเว็บไซต์ทั้งหมด:
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /
บล็อกไดเรกทอรีย่อยหนึ่งรายการสำหรับบอททั้งหมด
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /โฟลเดอร์/
บล็อกไดเรกทอรีย่อยหนึ่งรายการสำหรับบอททั้งหมด (โดยอนุญาตให้มีไฟล์เดียว)
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /โฟลเดอร์/
อนุญาต: /folder/page.html
บล็อกไฟล์เดียวสำหรับบอททั้งหมด
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /this-is-a-file.pdf
บล็อกหนึ่งประเภทไฟล์ (PDF) สำหรับบอททั้งหมด
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /*.pdf$
บล็อก URL ที่มีการกำหนดพารามิเตอร์ทั้งหมดสำหรับ Googlebot เท่านั้น
User-agent: Googlebot
ไม่อนุญาต: /*?
วิธีทดสอบไฟล์ robots.txt เพื่อหาข้อผิดพลาด
ข้อผิดพลาดใน Robots.txt อาจรุนแรงได้ ดังนั้นการตรวจสอบข้อผิดพลาดจึงเป็นเรื่องสำคัญ ตรวจสอบ รายงาน "ความครอบคลุม" ใน Search Console เป็นประจำเพื่อดูปัญหาที่เกี่ยวข้องกับ robot.txt ข้อผิดพลาดบางอย่างที่คุณอาจพบ ความหมาย และวิธีแก้ไขมีดังนี้
URL ที่ส่งถูกบล็อกโดย robots.txt
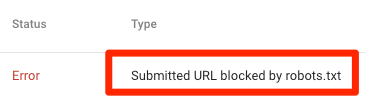
ซึ่งบ่งชี้ว่า robots.txt ได้บล็อก URL อย่างน้อยหนึ่งรายการในแผนผังไซต์ของคุณ หากแผนผังไซต์ของคุณถูกต้องและไม่มีหน้า Canonicalized, noindexed หรือเปลี่ยนเส้นทาง ดังนั้น robots.txt ไม่ควรบล็อกหน้าใดๆ ที่คุณส่ง หากเป็นเช่นนั้น ให้ระบุหน้าที่ได้รับผลกระทบและลบการบล็อกออกจากไฟล์ robots.txt ของคุณ
คุณสามารถใช้เครื่องมือทดสอบ robots.txt ของ Google เพื่อระบุคำสั่งการบล็อก โปรดใช้ความระมัดระวังเมื่อแก้ไขไฟล์ robots.txt เนื่องจากข้อผิดพลาดอาจส่งผลต่อหน้าหรือไฟล์อื่นๆ
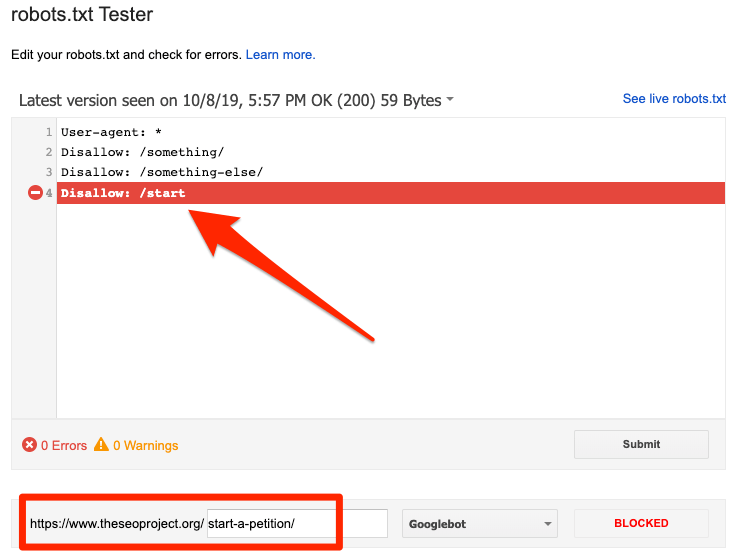
ถูกบล็อกโดย robots.txt
ข้อผิดพลาดนี้บ่งชี้ว่า robots.txt ได้บล็อกเนื้อหาที่ Google ไม่สามารถจัดทำดัชนีได้ ลบบล็อกการรวบรวมข้อมูลใน robots.txt หากเนื้อหานี้มีความสำคัญและควรได้รับการจัดทำดัชนี (นอกจากนี้ ให้ตรวจสอบว่าเนื้อหาไม่ได้มีการจัดทำดัชนีไว้)
หากคุณต้องการแยกเนื้อหาออกจากดัชนีของ Google ให้ใช้เมตาแท็กของโรบ็อตหรือส่วนหัว x-robots และลบบล็อกการรวบรวมข้อมูล นั่นเป็นวิธีเดียวที่จะป้องกันไม่ให้เนื้อหาอยู่ในดัชนีของ Google
จัดทำดัชนี แม้ว่าจะถูกบล็อกโดย robots.txt
หมายความว่า Google ยังคงสร้างดัชนีเนื้อหาบางส่วนที่ถูกบล็อกโดย robots.txt Robots.txt ไม่ใช่วิธีแก้ปัญหาเพื่อป้องกันไม่ให้เนื้อหาของคุณแสดงในผลการค้นหาของ Google
เพื่อป้องกันการสร้างดัชนี ให้ลบบล็อกการรวบรวมข้อมูลและแทนที่ด้วยแท็ก meta robots หรือส่วนหัว HTTP x-robots-tag หากคุณบล็อกเนื้อหานี้โดยไม่ได้ตั้งใจและต้องการให้ Google จัดทำดัชนี ให้ลบบล็อกการรวบรวมข้อมูลใน robots.txt สามารถช่วยในการปรับปรุงการมองเห็นเนื้อหาในการค้นหาของ Google
Robots.txt เทียบกับ meta robots เทียบกับ x-robots
อะไรคือความแตกต่างของคำสั่งหุ่นยนต์ทั้งสามนี้? Robots.txt เป็นไฟล์ข้อความธรรมดา ในขณะที่ meta และ x-robots เป็นคำสั่ง meta นอกเหนือจากบทบาทพื้นฐานแล้ว ทั้งสามยังมีหน้าที่ที่แตกต่างกัน Robots.txt ระบุพฤติกรรมการรวบรวมข้อมูลสำหรับทั้งเว็บไซต์หรือไดเรกทอรี ในขณะที่ meta และ x-robots กำหนดพฤติกรรมการจัดทำดัชนีสำหรับแต่ละหน้า (หรือองค์ประกอบของหน้า)
อ่านเพิ่มเติม
แหล่งข้อมูลที่เป็นประโยชน์
- Wikipedia: Robots Exclusion Protocol
- เอกสารของ Google เกี่ยวกับ Robots.txt
- เอกสารประกอบ Bing (และ Yahoo) บน Robots.txt
- คำสั่งอธิบาย
- เอกสาร Yandex บน Robots.txt
ห่อ
เราหวังว่าคุณจะเข้าใจถึงความสำคัญของไฟล์ robot.txt และการมีส่วนร่วมของไฟล์ในแนวทางปฏิบัติ SEO โดยรวมและผลกำไรของเว็บไซต์ หากคุณยังคงประสบปัญหาในการหารายได้จากเว็บไซต์ของคุณ คุณไม่จำเป็นต้องเขียนโค้ดเพื่อเริ่มสร้างรายได้ด้วยโฆษณา Adsterra วางโค้ดโฆษณาบนเว็บไซต์ HTML, WordPress หรือ Blogger ของคุณแล้วเริ่มสร้างผลกำไรได้เลยวันนี้!