
Yüksek Lisans Verimini Artırmaya Yönelik Gelişmiş Teknikler
Yayınlanan: 2024-04-02Teknolojinin hızlı dünyasında, Büyük Dil Modeli (LLM'ler) dijital bilgilerle nasıl etkileşim kurduğumuzda önemli oyuncular haline geldi. Bu güçlü araçlar makaleler yazabilir, soruları yanıtlayabilir ve hatta sohbetler düzenleyebilir, ancak bunların da zorlukları vardır. Bu modellerden daha fazlasını talep ettikçe engellerle karşılaşıyoruz, özellikle de konu onların daha hızlı ve daha verimli çalışmasını sağlamak olduğunda. Bu blog, bu engellerin doğrudan üstesinden gelmekle ilgilidir.
Bu modellerin çıktılarının kalitesini kaybetmeden çalışma hızını artırmak için tasarlanmış bazı akıllı stratejilere dalıyoruz. Bir yarış arabasının hızını artırırken aynı zamanda dar virajlarda kusursuz bir şekilde ilerleyebilmesini sağlamaya çalıştığınızı hayal edin; büyük dil modelleriyle hedeflediğimiz şey budur. Bilginin daha sorunsuz işlenmesine yardımcı olan Sürekli Toplu İşleme gibi yöntemleri ve Yüksek Lisans'ları dijital akıl yürütmelerinde daha dikkatli ve daha hızlı hale getiren Paged ve Flash Attention gibi yenilikçi yaklaşımları inceleyeceğiz.
Bu yapay zeka devlerinin yapabileceklerinin sınırlarını zorlamayı merak ediyorsanız doğru yerdesiniz. Bu ileri tekniklerin Yüksek Lisans'ların geleceğini nasıl şekillendirdiğini, onları her zamankinden daha hızlı ve daha iyi hale getirdiğini birlikte keşfedelim.
LLM'ler için Daha Yüksek Verime Ulaşmanın Zorlukları
Büyük Dil Modellerinde (LLM'ler) daha yüksek verim elde etmek, her biri bu modellerin çalışabileceği hız ve verimlilik önünde engel oluşturan birçok önemli zorlukla karşı karşıyadır. Başlıca engellerden biri, bu modellerin birlikte çalıştığı büyük miktarda veriyi işlemek ve depolamak için gereken saf bellek gereksinimidir. LLM'lerin karmaşıklığı ve boyutu büyüdükçe, hesaplama kaynaklarına olan talep yoğunlaşıyor ve işlem hızlarını artırmak şöyle dursun, sürdürmeyi bile zorlaştırıyor.
Bir diğer büyük zorluk ise, özellikle metin oluşturmak için kullanılan modellerde, LLM'lerin otomatik gerileyen doğasıdır. Bu, her adımdaki çıktının öncekilere bağlı olduğu ve görevlerin ne kadar hızlı yürütülebileceğini doğası gereği sınırlayan sıralı bir işlem gereksinimi yarattığı anlamına gelir. Bu sıralı bağımlılık genellikle bir darboğazla sonuçlanır; çünkü her adım, ilerleyebilmek için bir önceki adımın tamamlanmasını beklemek zorunda kalır ve bu da daha yüksek verim elde etme çabalarını engeller.
Ayrıca doğruluk ve hız arasındaki denge de hassastır. Çıktının kalitesinden ödün vermeden verimi artırmak, hesaplama verimliliği ve model etkililiğinin karmaşık ortamında gezinebilecek yenilikçi çözümler gerektiren bir ip yürüyüşüdür.
Bu zorluklar, doğal dil işleme alanında ve ötesinde mümkün olanın sınırlarını zorlayarak LLM optimizasyonunda yapılan ilerlemelerin arka planını oluşturur.
Bellek gereksinimi
Kod çözme aşaması, her zaman adımında tek bir jeton üretir, ancak her jeton, önceki tüm jetonların anahtar ve değer tensörlerine bağlıdır (ön doldurmada hesaplanan giriş jetonlarının KV tensörleri ve geçerli zaman adımına kadar hesaplanan tüm yeni KV tensörleri dahil) .
Bu nedenle, gereksiz hesaplamaları her seferinde en aza indirmek ve tüm bu tensörlerin her zaman adımında tüm tokenlar için yeniden hesaplanmasını önlemek amacıyla, bunları GPU belleğinde önbelleğe almak mümkündür. Her yinelemede, yeni öğeler hesaplandığında, bunlar bir sonraki yinelemede kullanılmak üzere basitçe çalışan önbelleğe eklenir. Bu aslında KV önbelleği olarak bilinir.
Bu, ihtiyaç duyulan hesaplamayı büyük ölçüde azaltır, ancak büyük dil modelleri için zaten daha yüksek olan bellek gereksinimlerinin yanı sıra bir bellek gereksinimi de getirir ve bu da ticari GPU'larda çalışmayı zorlaştırır. Model parametrelerinin boyutunun artmasıyla (7B'den 33B'ye) ve daha yüksek hassasiyetle (fp16'dan fp32'ye) bellek gereksinimleri de artar. Gerekli hafıza kapasitesi için bir örnek görelim,
Bildiğimiz gibi hafızayı meşgul eden iki önemli kişi şunlardır:
- Modelin hafızasında kendi ağırlıkları yok, bu da beraberinde geliyor. 7B gibi parametreler ve her parametrenin veri tipi örneğin, fp16(2 byte)'da 7B ~= 14GB bellek
- KV önbelleği: Gereksiz hesaplamayı önlemek amacıyla kişisel dikkat aşamasının anahtar değeri için kullanılan önbellek.
Bayt cinsinden simge başına KV önbellek boyutu = 2 * (num_layers) * (hidden_size) * sensitive_in_bytes
İlk faktör 2, K ve V matrislerini açıklar. Bu Hidden_size ve dim_head, modelin kartından veya yapılandırma dosyasından elde edilebilir.
Yukarıdaki formül jeton başınadır, dolayısıyla bir giriş dizisi için seq_len * size_of_kv_per_token olacaktır. Yani yukarıdaki formül şuna dönüşecek:
Bayt cinsinden KV önbelleğinin toplam boyutu = (sequence_length) * 2 * (num_layers) * (hidden_size) * sensitive_in_bytes
Örneğin, fp16'daki LLAMA 2 ile boyut (4096) * 2 * (32) * (4096) * 2 olacaktır, yani ~2GB olacaktır.
Yukarıdakiler tek bir giriş içindir, birden fazla girişle bu hızlı bir şekilde büyür, dolayısıyla bu uçuş sırasında bellek tahsisi ve yönetimi, Bellek Yetersizliği ve parçalanma sorunlarıyla sonuçlanmazsa, optimum performansı elde etmek için çok önemli bir adım haline gelir.
Bazen bellek gereksinimi GPU'muzun kapasitesinden daha fazladır, bu durumlarda model paralelliğine, burada ele alınmayan tensör paralelliğine bakmamız gerekir ancak o yönde keşfedebilirsiniz.
Otomatik gerileme ve belleğe bağlı işlem
Görebildiğimiz gibi, büyük dil modellerinin çıktı üretme kısmı doğası gereği otomatik gerilemelidir. Oluşturulacak herhangi bir yeni jetonun göstergesi, önceki tüm jetonlara ve ara durumlarına bağlıdır. Çıkış aşamasında tüm jetonlar daha fazla hesaplama yapmak için mevcut olmadığından ve yalnızca bir vektöre (sonraki jeton için) ve önceki aşamanın bloğuna sahip olduğundan, bu, GPU hesaplama yeteneğini gereğinden az kullanan bir matris-vektör işlemine benzer. ön doldurma aşamasıyla karşılaştırıldığında. Gecikmeyi, hesaplamaların gerçekte ne kadar hızlı gerçekleştiği değil, verilerin (ağırlıklar, anahtarlar, değerler, aktivasyonlar) bellekten GPU'ya aktarılma hızı belirler. Başka bir deyişle bu, belleğe bağlı bir işlemdir.
Üretim Zorluklarının Üstesinden Gelmek için Yenilikçi Çözümler
Sürekli harmanlama
Kod çözme aşamasının belleğe bağlı doğasını azaltmanın en basit adımı, girdiyi gruplamak ve birden fazla girdi için aynı anda hesaplamalar yapmaktır. Ancak basit bir sabit gruplandırma, üretilen değişken dizi uzunluklarının doğası nedeniyle düşük performansla sonuçlanmıştır ve burada bir grubun gecikmesi, bir toplu işte üretilen en uzun diziye ve aynı zamanda birden fazla giriş olduğundan artan bellek gereksinimine bağlıdır. artık tek seferde işleniyor.
Bu nedenle basit statik gruplama etkisizdir ve sürekli gruplama söz konusudur. Bunun özü, gelen talep gruplarını dinamik olarak bir araya getirmek, dalgalanan varış oranlarına uyum sağlamak ve mümkün olduğunda paralel işleme fırsatlarından yararlanmaktır. Bu aynı zamanda benzer uzunluktaki dizileri her bir grupta birlikte gruplayarak bellek kullanımını optimize eder, bu da daha kısa diziler için gereken dolgu miktarını en aza indirir ve hesaplama kaynaklarının aşırı doldurma nedeniyle israf edilmesini önler.

Mevcut bellek kapasitesi, hesaplama kaynakları ve giriş dizisi uzunlukları gibi faktörlere dayalı olarak parti boyutunu uyarlanabilir bir şekilde ayarlar. Bu, modelin değişen koşullar altında bellek kısıtlamalarını aşmadan en iyi şekilde çalışmasını sağlar. Bu, sayfalanmış dikkatin sağlanmasına yardımcı olarak (aşağıda açıklanmıştır), gecikmenin azaltılmasına ve verimin arttırılmasına yardımcı olur.
Daha fazlasını okuyun: Sürekli toplu işlem, LLM çıkarımında p50 gecikmesini azaltırken nasıl 23 kat verim sağlar?
Çağrılı Dikkat
Verimi artırmak için toplu işlem yaptığımızda, aynı anda birden fazla girişi işlediğimiz için bu aynı zamanda artan KV önbellek gereksinimine de mal olur. Bu diziler, mevcut hesaplama kaynaklarının bellek kapasitesini aşabilir, bu da bunların bütünüyle işlenmesini kullanışsız hale getirebilir.
Ayrıca, KV önbelleğinin saf bellek tahsisinin, tıpkı bilgisayar sistemlerinde eşit olmayan hafıza tahsisi nedeniyle gözlemlediğimiz gibi, çok fazla hafıza parçalanmasına yol açtığı da gözlemlenmektedir. vLLM, artan KV önbellek gereksinimini verimli bir şekilde karşılamak için işletim sistemi sayfalama ve sanal bellek kavramlarından ilham alan bir bellek yönetimi tekniği olan Paged Attention'ı tanıttı.
Sayfalandırılmış Dikkat, dikkat mekanizmasını her biri giriş dizisinin bir alt kümesini kapsayan daha küçük sayfalara veya bölümlere bölerek bellek kısıtlamalarını giderir. Model, girdi dizisinin tamamı için dikkat puanlarını tek seferde hesaplamak yerine, her seferinde bir sayfaya odaklanarak onu sırayla işliyor.
Çıkarım veya eğitim sırasında model, girdi dizisinin her sayfasında yinelenir, dikkat puanlarını hesaplar ve buna göre çıktı üretir. Bir sayfa işlendikten sonra sonuçları saklanır ve model bir sonraki sayfaya geçer.
Dikkat mekanizmasını sayfalara bölerek, Paged Attention, Büyük dil modelinin, bellek kısıtlamalarını aşmadan isteğe bağlı uzunluktaki giriş dizilerini işlemesine olanak tanır. Uzun dizileri işlemek için gereken bellek alanını etkili bir şekilde azaltarak büyük belgeler ve toplu işlerle çalışmayı mümkün kılar.
Daha fazla bilgi: vLLM ve PagedAttention ile Hızlı LLM Sunumu
Flaş dikkat
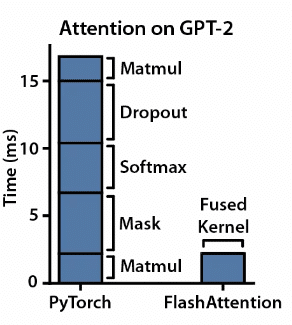
Büyük dil modellerinin temel aldığı dönüştürücü modeller için dikkat mekanizması çok önemli olduğundan, tahminlerde bulunurken modelin giriş metninin ilgili bölümlerine odaklanmasına yardımcı olur. Bununla birlikte, dönüştürücü tabanlı modeller büyüdükçe ve karmaşıklaştıkça, öz-dikkat mekanizması giderek yavaşlar ve bellek yoğun hale gelir, bu da daha önce belirtildiği gibi bellek darboğazı sorununa yol açar. Flash Attention, dikkat işlemlerini optimize ederek daha hızlı eğitim ve çıkarıma olanak tanıyarak bu sorunu azaltmayı amaçlayan başka bir optimizasyon tekniğidir.
Flash Attention'ın Temel Özellikleri:
Çekirdek Füzyonu: Yalnızca GPU bilgi işlem kullanımını en üst düzeye çıkarmak değil, aynı zamanda bunu mümkün olduğunca verimli işlemler yapmak da önemlidir. Flash Attention, birden fazla hesaplama adımını tek bir işlemde birleştirerek tekrarlanan veri aktarım ihtiyacını azaltır. Bu kolaylaştırılmış yaklaşım, uygulama sürecini basitleştirir ve hesaplama verimliliğini artırır.
Döşeme: Flash Attention, yüklenen verileri daha küçük bloklara bölerek paralel işlemeye yardımcı olur. Bu strateji, bellek kullanımını optimize ederek daha büyük giriş boyutlarına sahip modeller için ölçeklenebilir çözümler sağlar.
(Döşeme ve birleştirmenin hesaplama için gereken süreyi nasıl azalttığını gösteren birleştirilmiş CUDA çekirdeği, Görüntü kaynağı: FlashAttention: IO Farkındalığı ile Hızlı ve Bellek Açısından Verimli Tam Dikkat)
Bellek Optimizasyonu: Flash Attention, yakın zamanda hesaplanan belirteçlerin etkinleştirmelerini yeniden kullanarak yalnızca son birkaç belirtecin parametrelerini yükler. Bu kayan pencere yaklaşımı, ağırlık yüklemeye yönelik GÇ isteklerinin sayısını azaltır ve flash bellek verimini en üst düzeye çıkarır.
Azaltılmış Veri Aktarımı: Flash Attention, Yüksek Bant Genişlikli Bellek (HBM) ve SRAM (Statik Rastgele Erişim Belleği) gibi bellek türleri arasındaki ileri geri veri aktarımlarını en aza indirir. Tüm verileri (sorgular, anahtarlar ve değerler) yalnızca bir kez yükleyerek tekrarlanan veri aktarımlarının yükünü azaltır.
Örnek Olay İncelemesi – Spekülatif Kod Çözme ile Çıkarımı Optimize Etme
Otoregresif dil modelinde metin üretimini hızlandırmak için kullanılan diğer bir yöntem spekülatif kod çözmedir. Spekülatif kod çözmenin temel amacı, oluşturulan metnin kalitesini hedef dağıtımla karşılaştırılabilir bir düzeyde korurken metin üretimini hızlandırmaktır.
Spekülatif kod çözme, dizideki sonraki jetonları tahmin eden ve daha sonra önceden tanımlanmış kriterlere göre ana model tarafından kabul edilen/reddedilen küçük/taslak bir model sunar. Daha küçük bir taslak modelinin hedef modelle entegre edilmesi, metin oluşturma hızını önemli ölçüde artırır; bu, bellek gereksiniminin doğasından kaynaklanmaktadır. Taslak model küçük olduğundan daha az hayır gerektirir. yüklenecek nöron ağırlıkları ve no. Ana modelle karşılaştırıldığında artık hesaplama miktarı da daha az; bu, gecikmeyi azaltıyor ve çıktı oluşturma sürecini hızlandırıyor. Ana model daha sonra oluşturulan sonuçları değerlendirir ve bir sonraki olası tokenin hedef dağılımına uymasını sağlar.
Özünde, spekülatif kod çözme, sonraki belirteçleri tahmin etmek için daha küçük, daha hızlı bir taslak modelden yararlanarak metin oluşturma sürecini kolaylaştırır, böylece oluşturulan içeriğin kalitesini hedef dağıtıma yakın tutarken genel metin oluşturma hızını artırır.
Daha küçük modellerin ürettiği tokenlerin her zaman sürekli reddedilmemesi çok önemli, bu durum iyileşme yerine performansın düşmesine neden oluyor. Deneyler ve kullanım durumlarının doğası aracılığıyla daha küçük bir model seçebilir/ çıkarım sürecine spekülatif kod çözmeyi dahil edebiliriz.
Çözüm
Büyük Dil Modeli (LLM) verimini artırmaya yönelik gelişmiş teknikler arasındaki yolculuk, doğal dil işleme alanında ileriye dönük bir yolu aydınlatıyor ve yalnızca zorlukları değil, aynı zamanda bu zorlukları doğrudan aşabilecek yenilikçi çözümleri de sergiliyor. Sürekli Toplu İşlemden Sayfalanmış ve Flash Dikkate kadar bu teknikler ve Spekülatif Kod Çözmenin ilgi çekici yaklaşımı, artan iyileştirmelerden daha fazlasıdır. Bunlar, büyük dil modellerini daha hızlı, daha verimli ve sonuçta geniş bir uygulama yelpazesi için daha erişilebilir hale getirme yeteneğimizde önemli ilerlemeleri temsil ediyor.
Bu ilerlemelerin önemi abartılamaz. Yüksek Lisans verimini optimize ederken ve performansı artırırken, yalnızca bu güçlü modellerin motorlarında ince ayar yapmıyoruz; işlem hızı ve verimlilik açısından neyin mümkün olduğunu yeniden tanımlıyoruz. Bu da, konuşma hızında çalışabilen gerçek zamanlı dil çeviri hizmetlerinden, çok büyük veri kümelerini benzeri görülmemiş bir hızla işleyebilen gelişmiş analitik araçlarına kadar geniş dil modelinin uygulanması için yeni ufuklar açıyor.
Üstelik bu teknikler, büyük dil modeli optimizasyonuna yönelik hız, doğruluk ve hesaplama kaynakları arasındaki etkileşimi dikkatli bir şekilde dikkate alan dengeli bir yaklaşımın öneminin altını çiziyor. Yüksek Lisans yeteneklerinin sınırlarını zorlarken bu dengeyi korumak, bu modellerin çok sayıda sektörde çok yönlü ve güvenilir araçlar olarak hizmet vermeye devam edebilmesini sağlamak açısından hayati önem taşıyacaktır.
Geniş dil modeli çıktısını artırmaya yönelik gelişmiş teknikler, teknik başarılardan daha fazlasıdır; bunlar yapay zekanın devam eden evriminde kilometre taşlarıdır. Yüksek Lisans'ları daha uyarlanabilir, daha verimli ve daha güçlü hale getirerek dijital ortamımızı dönüştürmeye devam edecek gelecekteki yeniliklerin önünü açmayı vaat ediyorlar.
Son blog gönderimizde büyük dil modeli Çıkarım Optimizasyonu için GPU Mimarisi hakkında daha fazla bilgi edinin