
Python ile Dinamik Web Sayfası Kazıma - Nasıl Yapılır Kılavuzu
Yayınlanan: 2024-06-08Dinamik web kazıma, JavaScript veya Python aracılığıyla gerçek zamanlı içerik üreten web sitelerinden veri almayı içerir. Statik web sayfalarının aksine, dinamik içerik eşzamansız olarak yüklenir ve geleneksel kazıma tekniklerini verimsiz hale getirir.
Dinamik web kazıma şunları kullanır:
- AJAX tabanlı web siteleri
- Tek Sayfalı Uygulamalar (SPA'lar)
- Gecikmeli yükleme öğelerine sahip siteler
Temel araçlar ve teknolojiler:
- Selenyum – Tarayıcı etkileşimlerini otomatikleştirir.
- BeautifulSoup – HTML içeriğini ayrıştırır.
- İstekler – Web sayfası içeriğini getirir.
- lxml – XML ve HTML'yi ayrıştırır.
Dinamik web kazıma pythonu, gerçek zamanlı verileri etkili bir şekilde toplamak için web teknolojilerinin daha derinlemesine anlaşılmasını gerektirir.
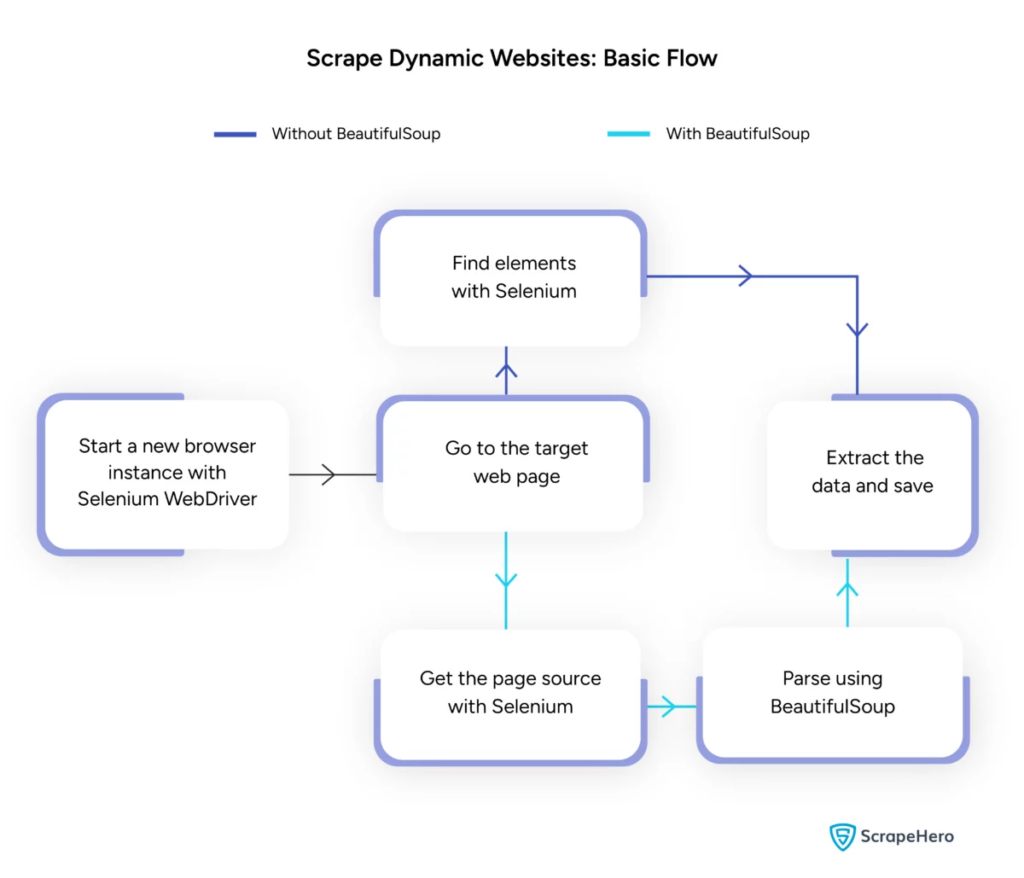
Görüntü Kaynağı: https://www.scrapehero.com/scrape-a-dynamic-website/
Python Ortamını Kurma
Dinamik web kazıma Python'a başlamak için ortamı doğru şekilde ayarlamak önemlidir. Bu adımları takip et:
- Python'u Yükle : Makinede Python'un kurulu olduğundan emin olun. En son sürüm resmi Python web sitesinden indirilebilir.
- Sanal Ortam Oluşturun :

Sanal ortamı etkinleştirin:

- Gerekli Kitaplıkları Yükleyin :

- Kod Düzenleyici Ayarlayın : Komut dosyaları yazmak ve çalıştırmak için PyCharm, VSCode veya Jupyter Notebook gibi bir IDE kullanın.
- HTML/CSS'ye aşina olun : Web sayfası yapısını anlamak, etkili bir şekilde gezinmeye ve veri çıkarmaya yardımcı olur.
Bu adımlar dinamik web kazıma python projeleri için sağlam bir temel oluşturur.
HTTP İsteklerinin Temellerini Anlamak
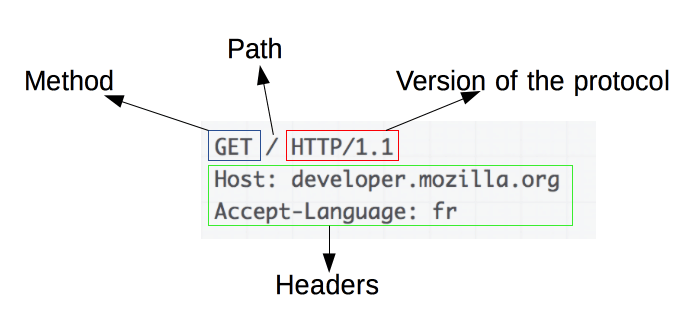
Resim Kaynağı: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP istekleri web kazımanın temelidir. Bir web tarayıcısı veya web kazıyıcı gibi bir istemci, bir sunucudan bilgi almak istediğinde bir HTTP isteği gönderir. Bu istekler belirli bir yapıyı takip eder:
- Yöntem : GET veya POST gibi gerçekleştirilecek eylem.
- URL : Kaynağın sunucudaki adresi.
- Başlıklar : İçerik türü ve kullanıcı aracısı gibi istekle ilgili meta veriler.
- Gövde : İstekle birlikte gönderilen ve genellikle POST ile kullanılan isteğe bağlı veriler.
Bu bileşenlerin nasıl yorumlanacağını ve oluşturulacağını anlamak, etkili web kazıma için çok önemlidir. İstekler gibi Python kitaplıkları bu süreci basitleştirerek istekler üzerinde hassas kontrol sağlar.
Python Kitaplıklarını Yükleme
Görüntü Kaynağı: https://ajaytech.co/what-are-python-libraries/
Python ile dinamik web kazıma için Python'un kurulu olduğundan emin olun. Terminali veya komut istemini açın ve pip kullanarak gerekli kitaplıkları yükleyin:
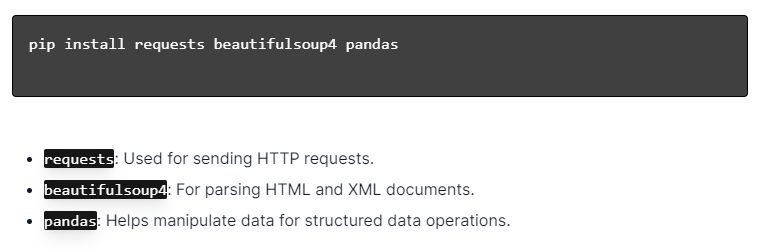
Daha sonra bu kitaplıkları betiğinize aktarın:

Bunu yaparak, her kütüphane istek gönderme, HTML ayrıştırma ve verileri verimli bir şekilde yönetme gibi web kazıma görevleri için kullanılabilir hale getirilecek.
Basit Bir Web Scraping Komut Dosyası Oluşturma
Python'da temel bir dinamik web kazıma betiği oluşturmak için önce gerekli kütüphanelerin kurulması gerekir. "Requests" kütüphanesi HTTP isteklerini yönetirken, "BeautifulSoup" HTML içeriğini ayrıştırır.
Takip edilecek adımlar:
- Bağımlılıkları yükleyin:

- Kütüphaneleri İçe Aktar:

- HTML İçeriğini Alın:
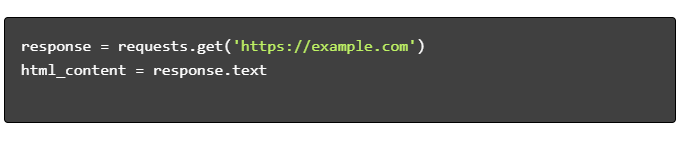
- HTML'yi ayrıştır:

- Verileri Çıkarın:

Python ile Dinamik Web Kazımayı Kullanma
Dinamik web siteleri, genellikle daha karmaşık teknikler gerektiren, anında içerik üretir.

Aşağıdaki adımları göz önünde bulundurun:
- Hedef Öğeleri Tanımlayın : Dinamik içeriği bulmak için web sayfasını inceleyin.
- Bir Python Çerçevesi seçin : Selenium veya Playwright gibi kütüphanelerden yararlanın.
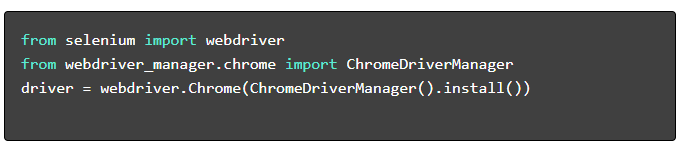
- Gerekli Paketleri Kurun :
- WebDriver'ı Kur :

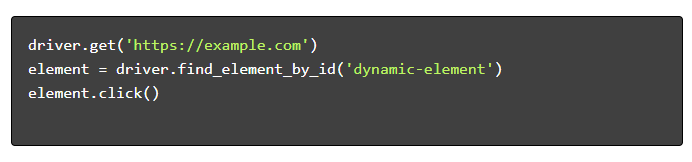
- Gezin ve Etkileşimde Bulunun :
Web Scraping En İyi Uygulamaları
Verimliliği ve yasallığı sağlamak için Web kazımayla ilgili en iyi uygulamaları takip etmeniz önerilir. Aşağıda temel yönergeler ve hata giderme stratejileri verilmiştir:
- Robots.txt dosyasına saygı gösterin : Her zaman hedef sitenin robots.txt dosyasını kontrol edin.
- Kısıtlama : Sunucunun aşırı yüklenmesini önlemek için gecikmeler uygulayın.
- Kullanıcı Aracısı : Potansiyel blokajları önlemek için özel bir Kullanıcı Aracısı dizesi kullanın.
- Yeniden Deneme Mantığı : Sunucu zaman aşımlarını işlemek için try-hariç bloklarını kullanın ve yeniden deneme mantığını ayarlayın.
- Günlüğe kaydetme : Hata ayıklama için kapsamlı günlükleri koruyun.
- İstisna İşleme : Özellikle ağ hatalarını, HTTP hatalarını ve ayrıştırma hatalarını yakalayın.
- Captcha Tespiti : CAPTCHA'ları tespit etmek ve çözmek veya atlamak için stratejiler ekleyin.
Yaygın Dinamik Web Kazıma Zorlukları
Captcha'lar
Birçok web sitesi otomatik botları önlemek için CAPTCHA'ları kullanır. Bunu atlamak için:
- 2Captcha gibi CAPTCHA çözme hizmetlerini kullanın.
- CAPTCHA çözümü için insan müdahalesini uygulayın.
- İstek oranlarını sınırlamak için proxy'leri kullanın.
IP Engelleme
Siteler çok fazla istekte bulunan IP'leri engelleyebilir. Buna şu şekilde karşılık verin:
- Dönen proxy'leri kullanma.
- İstek azaltmanın uygulanması.
- Kullanıcı aracısı rotasyon stratejilerinin kullanılması.
JavaScript Oluşturma
Bazı siteler içeriği JavaScript aracılığıyla yükler. Bu zorluğa şu şekilde çözüm bulun:
- Tarayıcı otomasyonu için Selenium veya Puppeteer'ı kullanma.
- Dinamik içerik oluşturmak için Scrapy-splash'ı kullanma.
- JavaScript ile etkileşime geçmek için başsız tarayıcıları keşfetme.
Yasal sorunlar
Web kazıma bazen hizmet şartlarını ihlal edebilir. Aşağıdakileri yaparak uyumluluğu sağlayın:
- Yasal tavsiyeye danışmak.
- Kamuya açık verilerin kazınması.
- Robots.txt direktiflerine saygı gösterilmesi.
Veri Ayrıştırma
Tutarsız veri yapılarını yönetmek zor olabilir. Çözümler şunları içerir:
- HTML ayrıştırma için BeautifulSoup gibi kitaplıkları kullanma.
- Metin çıkarma için düzenli ifadeler kullanma.
- Yapılandırılmış veriler için JSON ve XML ayrıştırıcılarını kullanma.
Kazınmış Verilerin Saklanması ve Analiz Edilmesi
Kazınmış verileri depolamak ve analiz etmek, web kazımada çok önemli adımlardır. Verilerin nerede saklanacağına karar vermek hacim ve formata bağlıdır. Ortak depolama seçenekleri şunları içerir:
- CSV Dosyaları : Küçük veri kümeleri ve basit analizler için kolaydır.
- Veritabanları : Yapılandırılmış veriler için SQL veritabanları; Yapılandırılmamış için NoSQL.
Veriler depolandıktan sonra Python kütüphaneleri kullanılarak analiz edilebilir:
- Pandalar : Veri işleme ve temizleme için idealdir.
- NumPy : Sayısal işlemler için etkilidir.
- Matplotlib ve Seaborn : Veri görselleştirmeye uygundur.
- Scikit-learn : Makine öğrenimi için araçlar sağlar.
Doğru veri depolama ve analiz, veri erişilebilirliğini ve içgörüleri geliştirir.
Sonuç ve Sonraki Adımlar
Dinamik bir web kazıma Python'u inceledikten sonra, vurgulanan araç ve kitaplıkların anlaşılmasında ince ayar yapmak zorunludur.
- Kodu Gözden Geçirin : Son metne bakın ve yeniden kullanılabilirliği artırmak için mümkün olan yerlerde modüler hale getirin.
- Ek Kütüphaneler : Daha karmaşık ihtiyaçlar için Scrapy veya Splash gibi gelişmiş kütüphaneleri keşfedin.
- Veri Depolama : Büyük veri kümelerini yönetmek için SQL veritabanları veya bulut depolama gibi güçlü depolama seçeneklerini göz önünde bulundurun.
- Yasal ve Etik Hususlar : Olası ihlalleri önlemek için web kazımayla ilgili yasal yönergeler konusunda güncel kalın.
- Sonraki Projeler : Farklı karmaşıklıklara sahip yeni web kazıma projeleriyle uğraşmak bu becerileri daha da güçlendirecektir.
Python ile profesyonel dinamik web kazımayı projenize entegre etmek mi istiyorsunuz? PromptCloud, dahili olarak işleme karmaşıklığı olmadan yüksek ölçekli veri çıkarmaya ihtiyaç duyan ekipler için özel çözümler sunar. Sağlam ve güvenilir bir çözüm için PromptCloud hizmetlerini keşfedin. Bugün bizimle iletişime geçin!