
R'de Açımlayıcı Faktör Analizi
Yayınlanan: 2017-02-16R'de açıklayıcı faktör analizi nedir?
Açıklayıcı Faktör Analizi (EFA) veya kabaca R'de faktör analizi olarak bilinen, bir dizi değişken arasındaki gizli ilişkisel yapıyı tanımlamak ve daha az sayıda değişkene daraltmak için kullanılan istatistiksel bir tekniktir. Bu esasen çok sayıda değişkenin varyansının birkaç özet değişkenle, yani faktörlerle tanımlanabileceği anlamına gelir. İşte R'deki açıklayıcı faktör analizine genel bir bakış.
Adından da anlaşılacağı gibi, EFA doğada keşfedicidir - gizli değişkenleri gerçekten bilmiyoruz ve daha az sayıda faktöre ulaşana kadar adımlar tekrarlanır. Bu öğreticide, R kullanarak EFA'ya bakacağız. Şimdi, önce veri kümesinin temel fikrini öğrenelim.
1. Veriler
Bu veri seti, müşterilerin bir araba satın alırken dikkate aldıkları 14 farklı değişken için 90 yanıt içermektedir. Anket soruları, 1 çok düşük ve 5 çok yüksek olmak üzere 5'li Likert ölçeği kullanılarak çerçevelenmiştir. Değişkenler şunlardı:
- Fiyat
- Emniyet
- Dış görünüş
- Alan ve konfor
- teknoloji
- Satış sonrası servis
- Satış değeri
- Yakıt tipi
- Yakıt verimliliği
- Renk
- Bakım onarım
- Test sürüşü
- Ürün incelemeleri
- referanslar
Kodlanmış veri setini indirmek için buraya tıklayın.
2. Web Verilerini İçe Aktarma
Şimdi CSV formatında mevcut olan veri setini R'ye okuyacağız ve onu bir değişken olarak saklayacağız.
[code dili=”r”] data <- read.csv(file.choose( ),başlık=DOĞRU) [/kod]
CSV dosyasını seçmek için bir pencere açacak ve "başlık" seçeneği dosyanın ilk satırının başlık olarak kabul edilmesini sağlayacaktır. Veri çerçevesinin ilk birkaç satırını görmek için aşağıdakini girin ve verilerin doğru şekilde saklandığını onaylayın.
[kod dili=”r”] kafa(veri) [/kod]
3. Paket Kurulumu
Şimdi daha fazla analiz yapmak için gerekli paketleri kuracağız. Bu paketler 'psych' ve 'GPArotation'dır. Aşağıdaki kodda kurulum için `install.packages()` çağırıyoruz.
[kod dili=”r”] install.packages('psych') install.packages('GPArotation') [/kod]
4. Faktör Sayısı
Ardından, faktör analizi için seçeceğimiz faktör sayısını bulacağız. Bu, 'Paralel Analiz' ve 'özdeğer' vb. yöntemlerle değerlendirilir.
Paralel Analiz
Paralel analizi yürütmek için `Psych` paketinin `fa.parallel` fonksiyonunu kullanacağız. Burada veri çerçevesini ve faktör yöntemini belirtiyoruz (bizim durumumuzda `minres`). Kabul edilebilir sayıda faktör bulmak için aşağıdakileri çalıştırın ve "scree grafiği" oluşturun:
[code dil=”r”] paralel <- fa.parallel(veri, fm = 'minres', fa = 'fa') [/kod]
Konsol, dikkate alabileceğimiz maksimum faktör sayısını gösterir. İşte nasıl görüneceği.
“Paralel analiz, faktör sayısının = 5 ve bileşen sayısının = NA olduğunu gösteriyor”
Yukarıdaki koddan oluşturulan 'kayşat grafiğinde' aşağıda verilmiştir:
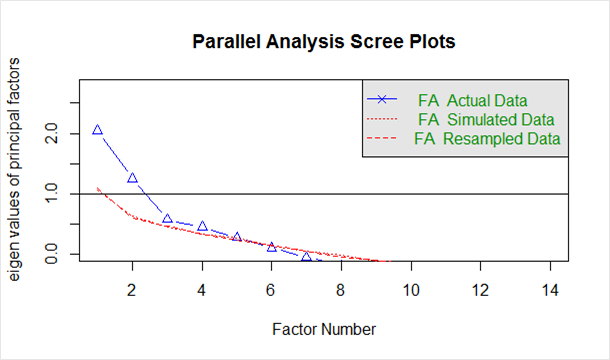
Mavi çizgi, gerçek verilerin özdeğerlerini gösterir ve iki kırmızı çizgi (birbirinin üzerine yerleştirilmiş) simüle edilmiş ve yeniden örneklenmiş verileri gösterir. Burada gerçek verilerdeki büyük düşüşlere bakıyoruz ve sağa doğru düzleştiği noktayı tespit ediyoruz. Ayrıca, bükülme noktasını, simüle edilmiş veriler ile gerçek veriler arasındaki boşluğun minimum olma eğiliminde olduğu noktayı buluruz.

Bu çizime ve paralel analize bakıldığında, 2 ila 5 faktör arasında herhangi bir yer iyi bir seçim olacaktır.
Faktor analizi
Artık olası faktör sayısına ulaştığımıza göre, faktör sayısı olarak 3 ile başlayalım. Faktör analizi yapmak için `psych` paketlerinin`fa() fonksiyonunu kullanacağız. Aşağıda, sağlayacağımız argümanlar verilmiştir:
- r – Ham veri veya korelasyon veya kovaryans matrisi
- nfactors – Çıkarılacak faktör sayısı
- döndürme – Çeşitli döndürme türleri olmasına rağmen, 'Varimax' ve 'Oblimin' en popüler olanlardır.
- fm – `Minimum Residual (OLS)`, `Maximum Liklihood`, `Principal Axis` vb. faktör çıkarma tekniklerinden biridir.
Bu durumda, faktörler arasında bir korelasyon olduğuna inandığımız için eğik döndürmeyi (döndür = “oblimin”) seçeceğiz. Varimax döndürmenin, faktörlerin tamamen ilişkisiz olduğu varsayımı altında kullanıldığına dikkat edin. Çok değişkenli bir normal dağılım varsaymadan "Maksimum Olabilirlik"e benzer sonuçlar sağladığı ve bir ana eksen gibi yinelemeli özbileşim yoluyla çözümler türettiği bilindiği için "Sıradan En Küçük Kareler/Minres" faktoringini (fm = "minres") kullanacağız.
Analizi başlatmak için aşağıdakileri çalıştırın.
[code language=”r”] üç faktörlü <- fa(data,nfaktörler = 3, döndürme = “oblimin”,fm=”minres”) print(üç faktör) [/kod]
İşte faktörleri ve yükleri gösteren çıktı:
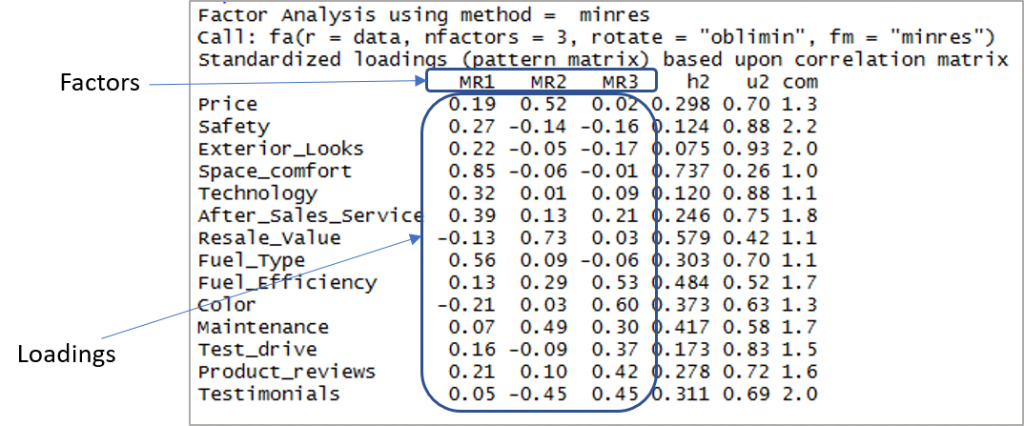
Şimdi 0,3'ten büyük ve birden fazla faktöre yüklenmeyen yüklemeleri dikkate almamız gerekiyor. Negatif değerlerin burada kabul edilebilir olduğunu unutmayın. Öyleyse önce görünürlüğü artırmak için sınırı belirleyelim.
[kod dili=”r”] print(üç faktör$yükleme,cutoff = 0.3) [/kod]
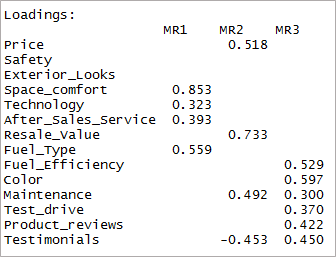
Gördüğünüz gibi iki değişken önemsiz hale geldi ve diğer ikisinde çift yükleme var. Daha sonra, '4' faktörlerini ele alacağız.
[code language=”r”] dört faktörlü <- fa(data,nfaktörler = 4, döndürme = “oblimin”,fm=”minres”) print(fourfactor$loadings,cutoff = 0.3) [/code]
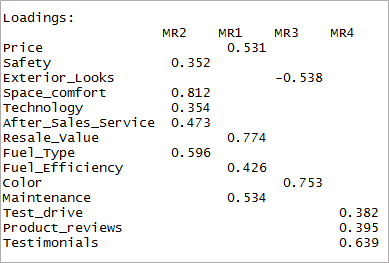
Sadece tek yükleme ile sonuçlandığını görebiliriz. Bu basit yapı olarak bilinir.
Faktör eşlemesine bakmak için aşağıdakilere basın.
[kod dili=”r”] fa.diyagram(dört faktör)[/kod]
Yeterlilik Testi
Şimdi basit bir yapı elde ettiğimize göre, modelimizi doğrulamamızın zamanı geldi. Devam etmek için faktör analizi çıktısına bakalım.

Kök, artıkların karesinin (RMSR) 0,05 olduğu anlamına gelir. Bu değerin 0'a yakın olması gerektiği için bu kabul edilebilir. Daha sonra, RMSEA (kök ortalama kare hatası yaklaşıklık) indeksini kontrol etmeliyiz. 0.001 değeri, 0.05'in altında olduğu için iyi bir model uyumunu göstermektedir. Son olarak, Tucker-Lewis Endeksi (TLI) 0,93'tür – 0,9'un üzerinde olduğu düşünüldüğünde kabul edilebilir bir değerdir.
Faktörleri Adlandırma

Faktörlerin yeterliliğini belirledikten sonra sıra faktörleri isimlendirmeye gelir. Bu, değişken yüklere bağlı olarak faktörleri oluşturduğumuz analizin teorik tarafıdır. Bu durumda, faktörlerin nasıl oluşturulabileceği aşağıda açıklanmıştır.
Çözüm
r'de analiz için bu öğreticide, EFA'nın temel fikrini (R'de açıklayıcı faktör analizi), kapsanan paralel analizi ve dağılma grafiği yorumlamasını tartıştık. Daha sonra basit bir yapı elde etmek ve modelin yeterliliğini sağlamak için aynısını doğrulamak için R'de faktör analizine geçtik. Sonunda değişkenlerden faktörlerin isimlerine ulaştık. Şimdi devam edin, deneyin ve bulgularınızı yorum bölümüne gönderin.