
Çarşı Sesi
Yayınlanan: 2024-04-24Eski sistemlerin modernleştirilmesiyle ilgili bu makale, yakın zamanda Yazılım Şirketleri için AWS Veri Zirvesi'nde sunduğum, makine öğrenimi projelerinde başarıyı garantilemek için en iyi uygulamalarımızdan yararlanarak verilerden değer üretme konulu bir konuşmanın tamamlayıcı parçasıdır. İsterseniz izlemek için hemen aşağıya atlayabilirsiniz.
Şunu kabul edelim: Yazılımı yazmak, sürdürmekten daha kolaydır. Bu nedenle yazılım mühendisleri olarak biz, başka bir geliştiricinin (veya geçmişteki benliğimizin) ne düşündüğünü anlamaya çalışmak yerine, "her şeyi söküp baştan başlamayı" tercih ediyoruz. "Programların insanların okuması için ve tesadüfen makinelerin çalıştırabilmesi için yazılması gerektiğini" topluca unutmuş gibiyiz.
Bunun doğru olduğunu biliyorsunuz - hepimiz bir tabak dolusu spagetti kodunu ve ince, eski dünya tarzı soyutlamaları titizlikle inceleyerek programın içeriğini kazmak zorunda kaldık ve tabaklarımızın dibinde bir karmaşadan başka bir şey bulamadık.
"WTF" diye bağırmak ve önceki geliştiriciyi suçlamak kolaydır, ancak gerçek genellikle daha karmaşıktır. Geleceği göremiyoruz, dolayısıyla yeni bir sistem tasarladığımızda gereksinimlerin, teknolojinin veya iş hedeflerinin nasıl büyüyeceğini anlamak imkansız. Sonuç olarak, kapsamları arttıkça ve işletmenin onlara bağımlılığı arttıkça sistemler okunamaz hale gelebilir. Bu biraz paradokstur: daha eski, bakımı daha zor sistemler genellikle en fazla değeri sağlar. Şirketle birlikte büyüdükleri için üzerinde çalışmak zor, ancak bunu bozmak bir felaket olabileceği için üzerinde çalışmak korkutucu.
İşte size buradan sesleniyorum: Eğer zor, ödüllendirici problemleri seviyorsanız… deneyin. Sahip olduğunuz en eski sistemi alın ve bakımı yapılabilir hale getirin. Bahsettiğim kişiyi biliyorsunuz; kimsenin "sahip olamayacağı" kişi. Diğer departmanların güvendiği ama mühendislerin nefret ettiği bir sistem. İlk önce Log4Shell'i yamalamanız gereken şey. Yap. Yap da görelim.
Geçenlerde Bazaarvoice'da on yıllık bir makine öğrenimi sistemini güncelleme fırsatı buldum. Görünüşte pek heyecan verici gelmiyordu: Bu şeyin sinir ağları bile yoktu! Kimin umurunda! Önemliydi. Bu sistem, Bazaarvoice tarafından alınan neredeyse her kullanıcı tarafından oluşturulan ürün incelemesini (ayda yaklaşık 9 milyon) işliyor ve bunu makine öğrenimi modellerine yapılan 90 milyon çıkarım çağrısıyla gerçekleştiriyor. Evet — 90 milyon çıkarım! Bu çok büyük bir ölçek ve ben de dalmak için sabırsızlanıyordum.
Bu yazıda, bu eski sistemi yeniden yazmak yerine yeniden mimari yoluyla modernleştirmenin, kodun tamamını söküp baştan başlamak zorunda kalmadan onu ölçeklenebilir ve uygun maliyetli hale getirmemize nasıl olanak tanıdığını paylaşacağım. Ortaya çıkan sistem sunucusuz, kapsayıcılı ve bakımı kolay bir sistem olup barındırma maliyetlerimizi yaklaşık %80 oranında azaltır.
Eski sistem nedir?
Eski sistem, eskiyen bilgi işlem yazılımı ve/veya çalışır durumda kalan donanım anlamına gelir. Her ne kadar orijinal amacını hâlâ yerine getirebilse de gelecekteki büyüme için ölçeklenebilirlikten yoksundur.
Eski eski sistemler
Öncelikle burada neyle karşı karşıya olduğumuza bir bakalım. Ekibimin güncellediği eski sistem, Bazaarvoice'un tamamı için kullanıcı tarafından oluşturulan içeriği yönetiyor. Özellikle her bir içeriğin müşterilerimizin web sitelerine uygun olup olmadığını belirler.

Bu kulağa basit geliyor - nefret söylemi, küfürlü dil veya taciz gibi bariz ihlalleri ortadan kaldırın - ancak pratikte çok daha incelikli. Her müşterinin uygun olduğunu düşündüğü şeyler konusunda kendine özgü gereksinimleri vardır. Örneğin bira markaları alkolün tartışılmasını beklerdi, ancak bir çocuk markası bunu yapmayabilir. Yeni müşteriler eklediğimizde müşteriye özel bu seçenekleri yakalarız ve Müşteri Hizmetleri ekibimiz bunları bir yönetim veritabanına kodlar.
Daha fazla karmaşıklık sağlamak için, içeriğimizin bir alt kümesini de gerçek moderatörler tarafından denetlenecek şekilde örnekliyoruz. Bu, modellerimizin performansını sürekli olarak ölçmemize ve daha fazla model oluşturma fırsatlarını keşfetmemize olanak tanır.
Eski sistemimizin tam mimarisi aşağıda gösterilmektedir:
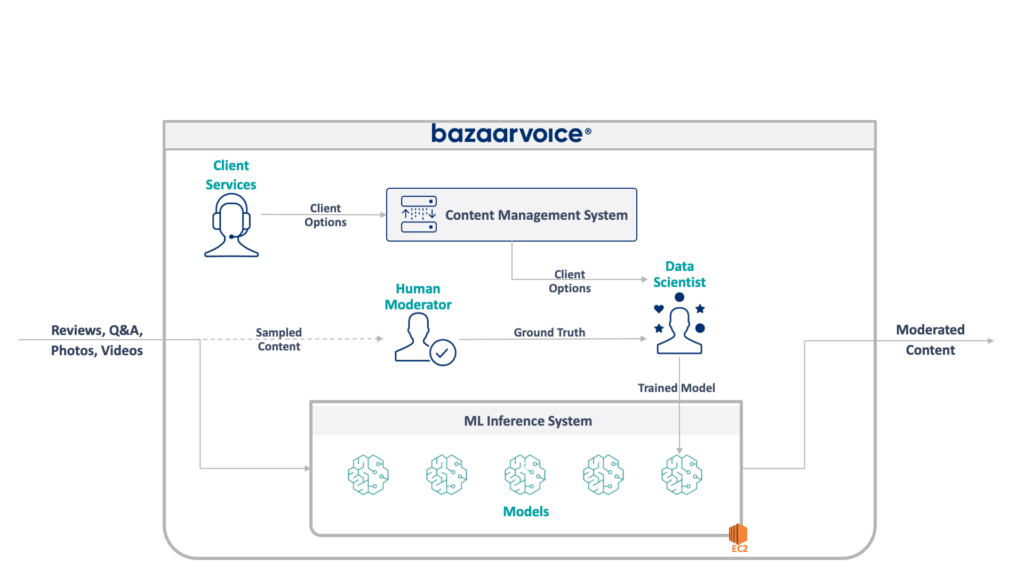
Bu sistemin bazı ciddi dezavantajları vardır. Spesifik olarak tüm modeller tek bir EC2 bulut sunucusunda barındırılıyor. Bunun nedeni kötü mühendislik değildi; yalnızca orijinal programcıların şirketin arzu ettiği ölçeği öngörememesiydi. Hiç kimse bu kadar büyüyeceğini düşünmüyordu.
Buna ek olarak sistem, geliştiricilerin reddetmesinden de zarar gördü: Çok az mühendisin anlayabileceği Scala dilinde yazılmıştı. Bu nedenle, kimse ona dokunmak istemediğinden, genellikle iyileştirme amacıyla gözden kaçırılıyordu.
Sonuç olarak sistem, ışıkları açık tutacak şekilde büyümeye devam etti. Mimarisini yeniden tasarladığımızda tek bir x1e.8xlarge örneğinde çalışıyordu. Bu şeyin neredeyse bir terabaytlık RAM'i vardı ve çalıştırmanın maliyeti ayda (ayrılmamış) yaklaşık 5.000 dolardı. Ancak endişelenmeyin, yedeklilik için ikincisini ve QA için üçüncüsünü başlattık.
Bu sistemin çalıştırılması maliyetliydi ve yüksek başarısızlık riskiyle karşı karşıyaydı (tek bir kötü model tüm hizmeti çökertebilir). Ayrıca kod tabanı aktif olarak geliştirilmemişti ve bu nedenle modern veri bilimi paketleri açısından önemli ölçüde güncelliğini kaybetmişti ve Scala'da yazılan hizmetlere yönelik standart uygulamalarımızı takip etmiyordu.
Yeni bir sistem
Bu sistemi yeniden tasarlarken net bir hedefimiz vardı: onu ölçeklenebilir hale getirmek. Model ve kod yönetimini kolaylaştırmak gibi işletme maliyetlerini azaltmak da ikincil bir hedefti.
Ortaya çıkardığımız yeni tasarım aşağıda gösterilmiştir:


Tüm bunları çözme yaklaşımımız, her makine öğrenimi modelini izole edilmiş bir SageMaker Sunucusuz uç noktasına yerleştirmekti. AWS Lambda işlevleri gibi, sunucusuz uç noktalar da kullanılmadığında kapanıyor; bu da bize sık kullanılmayan modellerde çalışma zamanı maliyetlerinden tasarruf sağlıyor. Ayrıca trafikteki artışlara yanıt olarak hızla ölçeklenebilirler.
Ayrıca istemci seçeneklerini, içeriği uygun modellere yönlendiren tek bir mikro hizmete sunduk. Yazmamız gereken yeni kodun büyük kısmı buydu: bakımı kolay olan ve veri bilimcilerimizin yeni modelleri daha kolay güncelleyip dağıtmasına olanak tanıyan küçük bir API.
Bu yaklaşımın aşağıdaki faydaları vardır:
- Değer kazanma süresi 6 kattan fazla azaldı. Spesifik olarak, trafiğin mevcut modellere yönlendirilmesi anlıktır ve yeni modellerin dağıtımı 30 dakika yerine 5 dakikadan kısa sürede yapılabilir.
- Sınırsız ölçeklendirme – şu anda 400 modelimiz var ancak otomatik olarak denetleyebileceğimiz içerik miktarını artırmaya devam etmek için binlerce modele kadar ölçeklendirmeyi planlıyoruz
- İşlevler kullanılmadığında kapandığından ve yeterince kullanılmayan üst düzey makineler için ödeme yapmadığımızdan EC2'ye geçişte %82'lik bir maliyet düşüşü gördük
Ancak ideal bir mimariyi tasarlamak, eski bir sistemi yeniden inşa etmenin gerçekten ilginç ve zor kısmı değildir; ona geçiş yapmanız gerekir.
Geçişteki ilk sorunumuz, bırakın SageMaker Sunucusuz'u, SageMaker üzerinde çalışacak şekilde bir Java WEKA modelini nasıl taşıyacağımızı bulmaktı.
Neyse ki SageMaker, modelleri Docker kapsayıcılarında dağıtır, böylece en azından Java ve bağımlılık sürümlerini eski kodumuzla eşleşecek şekilde dondurabiliriz. Bu, yeni sistemde barındırılan modellerin eski sistemle aynı sonuçları vermesini sağlamaya yardımcı olacaktır.

Konteyneri SageMaker ile uyumlu hale getirmek için tek yapmanız gereken birkaç spesifik HTTP uç noktasını uygulamaktır:
-
POST /invocation— girişi kabul edin, çıkarım yapın ve sonuçları döndürün. -
GET /ping— JVM sunucusu sağlıklıysa 200 değerini döndürür
(BYO çok modelli kaplar ve SageMaker çıkarım araç seti etrafındaki tüm sıkıntıları göz ardı etmeyi seçtik.)
com.sun.net.httpserver.HttpServer ile ilgili birkaç kısa soyutlama ve başlamaya hazırdık.
Ve biliyor musun? Bu aslında oldukça eğlenceliydi. Docker konteynerleriyle oynamak ve 10 yıllık bir şeyi SageMaker Serverless'a zorlamak biraz tamirci bir havaya sahipti. Çalıştırdığımızda oldukça heyecan vericiydi - özellikle de onu maven yerine yeni sbt yığınımızda oluşturmak için eski sistem kodunu aldığımızda.
Yeni sbt yığını üzerinde çalışmayı kolaylaştırdı ve kapsayıcılaştırma, SageMaker ortamında çalışırken doğru davranışı elde edebilmemizi sağladı.
Yeni bir sisteme geçiş
Yani modelleri konteynerlerde tutuyoruz ve bunları SageMaker'a dağıtabiliyoruz; neredeyse bitti, değil mi? Pek değil.
Yeni bir mimariye geçişle ilgili zor ders, sırf geçişi desteklemek için gerçek sisteminizin üç katını oluşturmanız gerektiğidir. Yeni sisteme ek olarak şunları da oluşturmamız gerekiyordu:
- Modelden gelen girdileri ve çıktıları kaydetmek için eski sistemdeki bir veri yakalama hattı. Bunları yeni sistemin aynı sonuçları vereceğini doğrulamak için kullandık
- Sonuçları hesaplamak ve bunları eski sistemdeki verilerle karşılaştırmak için yeni sistemdeki bir veri işleme hattı. Bu, Datadog ile büyük miktarda ölçüm yapılmasını gerektiriyordu ve tutarsızlıklar bulduğumuzda verileri yeniden oynatma olanağı sunması gerekiyordu.
- Eski sistemin (sadece modelleri S3'e yükleyecek olan) kullanıcılarının etkilenmesini önlemek için tam model dağıtım sistemi. Bunları eninde sonunda bir API'ye taşımak istediğimizi biliyorduk ancak ilk sürümde bunu sorunsuz bir şekilde yapmamız gerekiyordu.
Bunların hepsi, tüm kullanıcıları taşımayı bitirdikten sonra atabileceğimizi bildiğimiz tek kullanımlık kodlardı, ancak yine de onu oluşturmamız ve yeni sistemin çıktılarının eskisiyle eşleştiğinden emin olmamız gerekiyordu.
Bunu önceden bekleyin.
Geçiş araçlarını ve sistemlerini oluşturmak bu projedeki mühendislik zamanımızın %60'ından fazlasını alırken, aynı zamanda eğlenceli bir deneyimdi. Birim testi daha çok veri bilimi deneylerine benzemeye başladı: Çıktımızın tam olarak eşleştiğinden emin olmak için tüm paketler yazdık. İşi çok daha eğlenceli hale getiren farklı bir düşünce tarzıydı. Normal kalıplarımızın bir adım dışında, tabiri caizse.
Eski sistemlerin yeniden mimari yoluyla modernleştirilmesi
Bir dahaki sefere bir sistemi baştan sona yeniden inşa etmek istediğinizde, kod yerine mimariyi taşımayı denemenizi tavsiye ederim. İlginç ve ödüllendirici teknik zorluklarla karşılaşacaksınız ve muhtemelen yeni kodunuzda beklenmedik uç durumlarda hata ayıklamaktan çok daha fazla keyif alacaksınız.
Daha fazla öğrenmek ister misiniz? Aşağıda, AWS Veri Zirvesi'nde yaptığım ve MLOps konusunu ele alan konuşmayı izleyin.