
Web Sayfası Kazıyıcılarında Uzmanlaşmak: Yeni Başlayanlar İçin Çevrimiçi Veri Çıkarma Kılavuzu
Yayınlanan: 2024-04-09Web Sayfası Kazıyıcılar nedir?
Web sayfası kazıyıcı, web sitelerinden veri çıkarmak için tasarlanmış bir araçtır. Belirli içeriği toplamak için insan navigasyonunu simüle eder. Yeni başlayanlar genellikle bu kazıyıcılardan pazar araştırması, fiyat izleme ve makine öğrenimi projeleri için veri derleme gibi çeşitli görevler için yararlanır.
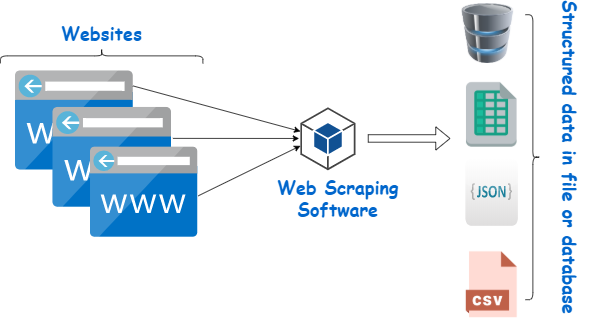
Resim Kaynağı: https://www.webharvy.com/articles/what-is-web-scraping.html
- Kullanım Kolaylığı: Kullanıcı dostudurlar ve minimum düzeyde teknik beceriye sahip kişilerin web verilerini etkili bir şekilde yakalamasına olanak tanırlar.
- Verimlilik: Kazıyıcılar, manuel veri toplama çabalarını çok geride bırakarak büyük miktarda veriyi hızlı bir şekilde toplayabilir.
- Doğruluk: Otomatik kazıma, insan hatası riskini azaltarak veri doğruluğunu artırır.
- Uygun Maliyet: Manuel giriş ihtiyacını ortadan kaldırarak işçilik maliyetlerinden ve zamandan tasarruf sağlarlar.
Web sayfası kazıyıcıların işlevselliğini anlamak, web verilerinin gücünden yararlanmak isteyen herkes için kritik öneme sahiptir.
Python ile Basit Bir Web Sayfası Kazıyıcı Oluşturma
Python'da bir web sayfası kazıyıcı oluşturmaya başlamak için, belirli kütüphanelerin, yani bir web sayfasına HTTP istekleri yapma isteklerinin ve HTML ve XML belgelerini ayrıştırmak için bs4'ten BeautifulSoup'un kurulması gerekir.
- Toplama Araçları:
- Kitaplıklar: Web sayfalarını getirmek için istekleri ve indirilen HTML içeriğini ayrıştırmak için BeautifulSoup'u kullanın.
- Web Sayfasını Hedeflemek:
- Kazımak istediğimiz verileri içeren web sayfasının URL'sini tanımlayın.
- İçeriğin İndirilmesi:
- İstekleri kullanarak web sayfasının HTML kodunu indirin.
- HTML'yi ayrıştırma:
- BeautifulSoup, indirilen HTML'yi kolay gezinme için yapılandırılmış bir formata dönüştürecektir.
- Verilerin Çıkarılması:
- İstediğimiz bilgileri içeren belirli HTML etiketlerini tanımlayın (örneğin, <div> etiketleri içindeki ürün başlıkları).
- BeautifulSoup yöntemlerini kullanarak ihtiyacınız olan verileri çıkarın ve işleyin.
Kazımak istediğiniz bilgilerle alakalı belirli HTML öğelerini hedeflemeyi unutmayın.
Bir Web Sayfasını Kazımak İçin Adım Adım İşlem
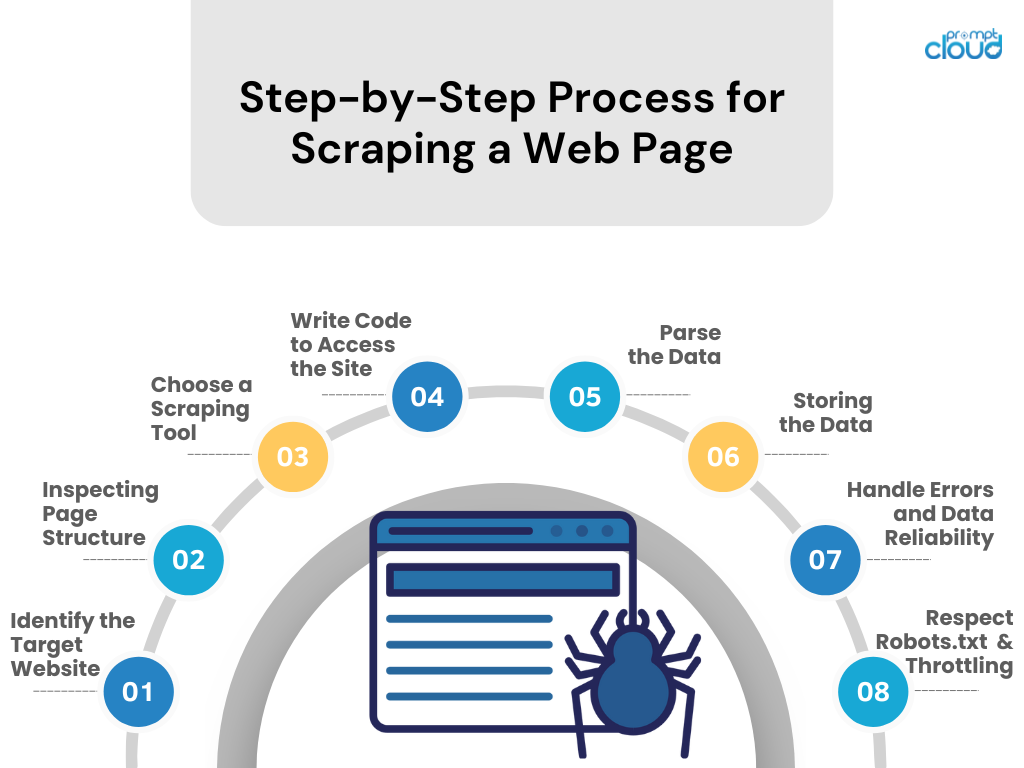
- Hedef Web Sitesini Belirleyin
Kazımak istediğiniz web sitesini araştırın. Bunu yapmanın yasal ve etik olduğundan emin olun. - Sayfa Yapısını İnceleme
HTML yapısını, CSS seçicilerini ve JavaScript odaklı içeriği incelemek için tarayıcının geliştirici araçlarını kullanın. - Bir Kazıma Aracı Seçin
Rahat olduğunuz bir programlama dilinde bir araç veya kitaplık seçin (örneğin, Python's BeautifulSoup veya Scrapy). - Siteye Erişim İçin Kod Yazın
Varsa API çağrılarını veya HTTP isteklerini kullanarak web sitesinden veri isteyen bir komut dosyası oluşturun. - Verileri Ayrıştırma
HTML/CSS/JavaScript'i ayrıştırarak ilgili verileri web sayfasından çıkarın. - Verilerin Saklanması
Kazınmış verileri CSV, JSON gibi yapılandırılmış bir formatta veya doğrudan bir veritabanına kaydedin. - Hataları ve Veri Güvenilirliğini Ele Alın
İstek hatalarını yönetmek ve veri bütünlüğünü korumak için hata işlemeyi uygulayın. - Robots.txt ve Kısıtlamaya Saygı Gösterin
Sitenin robots.txt dosya kurallarına uyun ve istek hızını kontrol ederek sunucunun aşırı yüklenmesini önleyin.
İhtiyaçlarınız İçin İdeal Web Kazıma Araçlarını Seçmek
Web'i kazırken, yeterliliğinize ve hedeflerinize uygun araçları seçmek çok önemlidir. Yeni başlayanlar şunları dikkate almalıdır:
- Kullanım kolaylığı: Görsel yardım ve anlaşılır belgelere sahip sezgisel araçları tercih edin.
- Veri gereksinimleri: Basit bir uzantının mı yoksa sağlam bir yazılımın mı gerekli olduğunu belirlemek için hedef verilerin yapısını ve karmaşıklığını değerlendirin.
- Bütçe: Maliyeti özelliklere göre tartın; birçok etkili kazıyıcı ücretsiz katmanlar sunar.
- Özelleştirme: Aletin belirli kazıma ihtiyaçlarına göre uyarlanabildiğinden emin olun.
- Destek: Yararlı bir kullanıcı topluluğuna erişim, sorun giderme ve iyileştirme konusunda yardımcı olur.
Sorunsuz bir kazıma yolculuğu için akıllıca seçim yapın.
Web Sayfası Kazıyıcınızı Optimize Etmeye Yönelik İpuçları ve Püf Noktaları
- Daha hızlı HTML işleme için Python'da BeautifulSoup veya Lxml gibi verimli ayrıştırma kitaplıklarını kullanın.
- Sayfaların yeniden indirilmesini önlemek ve sunucudaki yükü azaltmak için önbelleğe alma uygulayın.
- Hedef web sitesi tarafından yasaklanmayı önlemek için robots.txt dosyalarına saygı gösterin ve hız sınırlamayı kullanın.
- İnsan davranışını taklit etmek ve tespit edilmekten kaçınmak için kullanıcı aracılarını ve proxy sunucularını değiştirin.
- Web sitesi performansı üzerindeki etkiyi en aza indirmek için kazıyıcıları yoğun olmayan saatlerde planlayın.
- Yapılandırılmış veriler sağladıklarından ve genellikle daha verimli olduklarından, varsa API uç noktalarını tercih edin.
- Sorgularınızda seçici davranarak, gereken bant genişliğini ve depolama alanını azaltarak gereksiz verileri kazımaktan kaçının.
- Web sitesi yapısındaki değişikliklere uyum sağlamak ve veri bütünlüğünü korumak için kazıyıcılarınızı düzenli olarak güncelleyin.
Web Sayfası Kazımada Yaygın Sorunları Ele Alma ve Sorun Giderme
Web sayfası kazıyıcılarla çalışırken yeni başlayanlar birkaç yaygın sorunla karşılaşabilir:

- Seçici Sorunları : Seçicilerin web sayfasının mevcut yapısıyla eşleştiğinden emin olun. Tarayıcı geliştirici araçları gibi araçlar, doğru seçicilerin belirlenmesine yardımcı olabilir.
- Dinamik İçerik : Bazı web sayfaları içeriği JavaScript ile dinamik olarak yükler. Bu gibi durumlarda, başsız tarayıcıları veya JavaScript'i işleyen araçları kullanmayı düşünün.
- Engellenen İstekler : Web siteleri kazıyıcıları engelleyebilir. Engellemeyi azaltmak için kullanıcı aracılarını dönüşümlü kullanmak, proxy kullanmak ve robots.txt dosyasına saygı göstermek gibi stratejiler kullanın.
- Veri Formatı Sorunları : Çıkarılan verilerin temizlenmesi veya formatlanması gerekebilir. Verileri standartlaştırmak için normal ifadeleri ve dize işlemlerini kullanın.
Özel sorun giderme rehberliği için belgelere ve topluluk forumlarına başvurmayı unutmayın.
Çözüm
Yeni başlayanlar artık web sayfası kazıyıcı aracılığıyla web'den verileri rahatlıkla toplayabilir, böylece araştırma ve analiz daha verimli hale gelebilir. Yasal ve etik yönleri göz önünde bulundurarak doğru yöntemleri anlamak, kullanıcıların web kazımanın tüm potansiyelinden yararlanmasına olanak tanır. Değerli bilgiler ve bilinçli karar vermeyle dolu, web sayfası kazıma işlemine sorunsuz bir giriş için bu yönergeleri izleyin.
SSS:
Bir sayfayı kazımak nedir?
Veri kazıma veya web toplama olarak da bilinen web kazıma, insan gezinme davranışlarını taklit eden bilgisayar programları kullanılarak web sitelerinden otomatik olarak veri çıkarılmasından oluşur. Bir web sayfası kazıyıcıyla, büyük miktarlardaki bilgiler hızlı bir şekilde sıralanabilir ve bunları manuel olarak derlemek yerine yalnızca önemli bölümlere odaklanılabilir.
İşletmeler, maliyetleri incelemek, itibarı yönetmek, eğilimleri analiz etmek ve rekabet analizleri yürütmek gibi işlevler için web kazıma uygular. Web kazıma projelerinin uygulanması, ziyaret edilen web sitelerinin ilgili tüm robots.txt ve no-follow protokollerinin eylemini ve bunlara uyulduğunu onayladığını doğrulamayı garanti eder.
Bir sayfanın tamamını nasıl kazıyabilirim?
Bir web sayfasının tamamını kopyalamak için genellikle iki bileşene ihtiyacınız vardır: gerekli verileri web sayfasında bulmanın bir yolu ve bu verileri başka bir yere kaydetme mekanizması. Pek çok programlama dili, özellikle Python ve JavaScript olmak üzere web kazımayı destekler.
Her ikisi için de çeşitli açık kaynaklı kütüphaneler mevcuttur ve bu da süreci daha da basitleştirir. Python geliştiricileri arasındaki popüler seçeneklerden bazıları BeautifulSoup, İstekler, LXML ve Scrapy'dir. Alternatif olarak, ParseHub ve Octoparse gibi ticari platformlar, daha az teknik kişinin karmaşık web kazıma iş akışlarını görsel olarak oluşturmasına olanak tanır. Gerekli kitaplıkları kurduktan ve DOM öğelerini seçmenin ardındaki temel kavramları anladıktan sonra, hedef web sayfasındaki ilgi çekici veri noktalarını tanımlayarak başlayın.
HTML etiketlerini ve niteliklerini incelemek için tarayıcı geliştirici araçlarını kullanın, ardından bu bulguları seçilen kitaplık veya platform tarafından desteklenen ilgili sözdizimine çevirin. Son olarak CSV, Excel, JSON, SQL veya başka bir seçenek gibi çıktı formatı tercihlerini ve kayıtlı verilerin bulunduğu hedefleri belirtin.
Google kazıyıcıyı nasıl kullanırım?
Popüler inanışın aksine Google, birden fazla ürünle kusursuz entegrasyonu kolaylaştırmak için API'ler ve SDK'lar sunmasına rağmen, doğrudan genel bir web kazıma aracı sunmamaktadır. Bununla birlikte, yetenekli geliştiriciler, Google'ın temel teknolojilerini temel alan üçüncü taraf çözümler oluşturarak, yetenekleri yerel işlevlerin ötesine etkili bir şekilde genişletti. Örnekler arasında, Google Search Console'un karmaşık yönlerini ortadan kaldıran ve anahtar kelime sıralama takibi, organik trafik tahmini ve geri bağlantı keşfi için kullanımı kolay bir arayüz sunan SerpApi yer almaktadır.
Teknik olarak geleneksel web kazıma işleminden farklı olsa da, bu hibrit modeller geleneksel tanımları ayıran çizgileri bulanıklaştırıyor. Diğer örnekler, Google Haritalar Platformu, YouTube Veri API'si v3 veya Google Alışveriş Hizmetlerini yönlendiren dahili mantığın yeniden yapılandırılmasına yönelik uygulanan tersine mühendislik çabalarını sergiliyor ve değişen derecelerde yasallık ve sürdürülebilirlik risklerine tabi olsa da orijinal emsallerine oldukça yakın işlevsellikler sağlıyor. Sonuçta, istekli web sayfası kazıyıcılarının, belirli bir yola başvurmadan önce çeşitli seçenekleri keşfetmesi ve belirli gereksinimlere göre değerleri değerlendirmesi gerekir.
Facebook kazıyıcı yasal mı?
Facebook Geliştirici Politikalarında belirtildiği gibi, izinsiz web kazıma, topluluk standartlarının açık bir ihlali anlamına gelir. Kullanıcılar, belirlenen API hız sınırlarını aşmak veya aşmak için tasarlanmış uygulamalar, komut dosyaları veya diğer mekanizmaları geliştirmemeyi veya çalıştırmamayı veya Sitenin veya Hizmetin herhangi bir yönünü deşifre etmeye, kaynak koda dönüştürmeye veya tersine mühendislik yapmaya çalışmamayı kabul ederler. Ayrıca, kişisel olarak tanımlanabilir bilgilerin izin verilen bağlamlar dışında paylaşılmasından önce açık kullanıcı onayının gerekli kılınmasını sağlayarak, veri koruma ve gizlilikle ilgili beklentileri vurgulamaktadır.
Belirtilen ilkelere uyulmaması, uyarılarla başlayan ve şiddet düzeylerine bağlı olarak sınırlı erişime veya ayrıcalıkların tamamen iptaline doğru giderek artan disiplin önlemlerini tetikler. Onaylanmış hata ödül programları kapsamında çalışan güvenlik araştırmacıları için oluşturulan istisnalara rağmen, genel fikir birliği, gereksiz komplikasyonları önlemek için onaylanmamış Facebook kazıma girişimlerinden kaçınılmasını savunmaktadır. Bunun yerine, platform tarafından onaylanan geçerli normlar ve sözleşmelerle uyumlu alternatifleri takip etmeyi düşünün.