
Python Web Tarayıcı – Adım Adım Eğitim
Yayınlanan: 2023-12-07Web tarayıcıları, veri toplama ve web kazıma dünyasında büyüleyici araçlardır. Arama motoru indeksleme, veri madenciliği veya rekabet analizi gibi çeşitli amaçlarla kullanılabilecek verileri toplamak için web'de gezinme sürecini otomatikleştirirler. Bu eğitimde, basitliği ve web verilerini işlemedeki güçlü yetenekleriyle bilinen bir dil olan Python'u kullanarak temel bir web tarayıcısı oluşturmak için bilgilendirici bir yolculuğa çıkacağız.
Python, zengin kütüphane ekosistemiyle web tarayıcıları geliştirmek için mükemmel bir platform sağlar. İster yeni başlayan bir geliştirici, ister veri meraklısı olun, ister yalnızca web tarayıcılarının nasıl çalıştığını merak ediyor olun, bu adım adım kılavuz size web taramasının temellerini tanıtmak ve kendi tarayıcınızı oluşturma becerileriyle donatmak için tasarlanmıştır. .
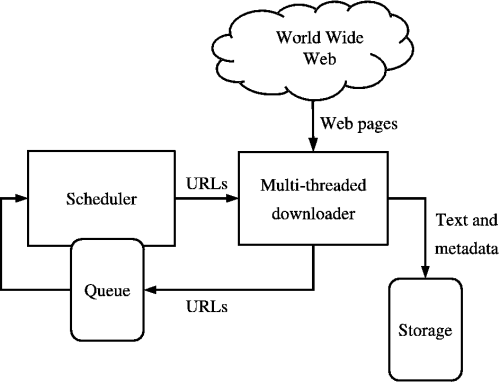
Kaynak: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Tarayıcısı – Web Tarayıcısı Nasıl Oluşturulur
1. Adım: Temelleri Anlamak
Örümcek olarak da bilinen bir web tarayıcısı, World Wide Web'i yöntemli ve otomatik bir şekilde tarayan bir programdır. Tarayıcımız için basitliği ve güçlü kütüphaneleri nedeniyle Python'u kullanacağız.
2. Adım: Ortamınızı Kurun
Python'u Yükleyin : Python'un kurulu olduğundan emin olun. Python.org'dan indirebilirsiniz.
Kütüphaneleri Yükleyin : HTTP istekleri yapmak için isteklere ve HTML'yi ayrıştırmak için bs4'ten BeautifulSoup'a ihtiyacınız olacak. Bunları pip kullanarak yükleyin:
pip kurulum istekleri pip kurulum güzelsoup4
Adım 3: Temel Tarayıcıyı Yazın
Kütüphaneleri İçe Aktar :
bs4'ten içe aktarma istekleri import BeautifulSoup
Bir Web Sayfası Getirin :
Burada bir web sayfasının içeriğini getireceğiz. 'URL'yi taramak istediğiniz web sayfasıyla değiştirin.
url = 'URL' yanıt = request.get(url) içerik = yanıt.content
HTML İçeriğini ayrıştırın :
çorba = BeautifulSoup(içerik, 'html.parser')
Bilgi Çıkart :
Örneğin, tüm köprüleri çıkarmak için şunları yapabilirsiniz:
Sopa.find_all('a') dosyasındaki bağlantı için: print(link.get('href'))
Adım 4: Tarayıcınızı Genişletin
Göreli URL'leri İşleme :
Göreli URL'leri işlemek için urljoin'i kullanın.
urllib.parse'den urljoin'i içe aktar
Aynı Sayfayı İki Kez Taramaktan Kaçının :
Fazlalığı önlemek için bir dizi ziyaret edilen URL'yi koruyun.
Gecikmeler Ekleme :
Saygılı tarama, istekler arasındaki gecikmeleri içerir. time.sleep() işlevini kullanın.
Adım 5: Robots.txt dosyasına saygı gösterin
Tarayıcınızın, sitenin hangi bölümlerinin taranmaması gerektiğini belirten web sitelerinin robots.txt dosyasına saygı gösterdiğinden emin olun.
Adım 6: Hata İşleme
Bağlantı zaman aşımları veya erişimin reddedilmesi gibi olası hataları işlemek için try-hariç blokları uygulayın.
Adım 7: Daha Derine Gitmek
Tarayıcınızı, form gönderimi veya JavaScript oluşturma gibi daha karmaşık görevleri yerine getirecek şekilde geliştirebilirsiniz. JavaScript ağırlıklı web siteleri için Selenium kullanmayı düşünün.
Adım 8: Verileri Saklayın
Taradığınız verileri nasıl saklayacağınıza karar verin. Seçenekler arasında basit dosyalar, veritabanları ve hatta verilerin doğrudan bir sunucuya gönderilmesi yer alır.
Adım 9: Etik Olun
- Sunuculara aşırı yükleme yapmayın; isteklerinize gecikmeler ekleyin.
- Web sitesinin hizmet şartlarını takip edin.
- Kişisel verileri izinsiz kazımayın veya saklamayın.
Engellenmek, web taramasında, özellikle de otomatik erişimi tespit etmek ve engellemek için önlemler alan web siteleriyle uğraşırken sık karşılaşılan bir zorluktur. Python'da bu sorunu çözmenize yardımcı olacak bazı stratejiler ve düşünceler şunlardır:
Neden Engellendiğinizi Anlamak
Sık İstekler: Aynı IP'den gelen hızlı, tekrarlanan istekler engellemeyi tetikleyebilir.
İnsan Dışı Desenler: Botlar genellikle sayfalara çok hızlı veya öngörülebilir bir sırayla erişmek gibi, insanların göz atma modellerinden farklı davranışlar sergiler.
Başlıkların Yanlış Yönetimi: Eksik veya yanlış HTTP başlıkları isteklerinizin şüpheli görünmesine neden olabilir.
Robots.txt dosyasının dikkate alınmaması: Bir sitenin robots.txt dosyasındaki yönergelere uyulmaması, blokajlara yol açabilir.
Engellenmeyi Önleme Stratejileri
Robots.txt dosyasına saygı gösterin : Her zaman web sitesinin robots.txt dosyasını kontrol edin ve ona uyun. Bu etik bir uygulamadır ve gereksiz engellemeleri önleyebilir.
Dönüşümlü Kullanıcı Aracıları : Web siteleri sizi kullanıcı aracınız aracılığıyla tanımlayabilir. Döndürerek bot olarak işaretlenme riskini azaltırsınız. Bunu uygulamak için fake_useragent kitaplığını kullanın.

fake_useragent'tan UserAgent'ı içe aktarın ua = UserAgent() başlıkları = {'User-Agent': ua.random}
Gecikme Ekleme : İstekler arasında bir gecikme uygulamak insan davranışını taklit edebilir. Rastgele veya sabit bir gecikme eklemek için time.sleep() işlevini kullanın.
içe aktarma zamanı time.sleep(3) # 3 saniye bekler
IP Rotasyonu : Mümkünse IP adresinizi döndürmek için proxy hizmetlerini kullanın. Bunun için hem ücretsiz hem de ücretli hizmetler mevcuttur.
Oturumları Kullanma : Python'daki bir request.Session nesnesi, tutarlı bir bağlantının korunmasına ve istekler arasında başlıkların, çerezlerin vb. paylaşılmasına yardımcı olarak tarayıcınızın daha normal bir tarayıcı oturumu gibi görünmesini sağlar.
session olarak request.Session() ile: session.headers = {'User-Agent': ua.random} yanıt = session.get(url)
JavaScript'i Kullanma : Bazı web siteleri içerik yüklemek için büyük ölçüde JavaScript'e güvenir. Selenium veya Puppeteer gibi araçlar, JavaScript oluşturma da dahil olmak üzere gerçek bir tarayıcıyı taklit edebilir.
Hata İşleme : Blokları veya diğer sorunları zarif bir şekilde yönetmek ve bunlara yanıt vermek için güçlü hata işleme uygulayın.
Etik Hususlar
- Bir web sitesinin hizmet şartlarına her zaman saygı gösterin. Bir site web kazımayı açıkça yasaklıyorsa buna uymak en iyisidir.
- Tarayıcınızın web sitesinin kaynakları üzerindeki etkisine dikkat edin. Bir sunucunun aşırı yüklenmesi site sahibi için sorunlara neden olabilir.
İleri Teknikler
- Web Scraping Çerçeveleri : Çeşitli tarama sorunlarını çözmek için yerleşik özelliklere sahip olan Scrapy gibi çerçeveleri kullanmayı düşünün.
- CAPTCHA Çözme Hizmetleri : CAPTCHA sorunları yaşayan siteler için, CAPTCHA'ları çözebilecek hizmetler vardır, ancak bunların kullanımı etik kaygılara yol açmaktadır.
Python'da En İyi Web Tarama Uygulamaları
Web tarama faaliyetlerine katılmak, teknik verimlilik ile etik sorumluluk arasında bir denge gerektirir. Python'u web taraması için kullanırken, verilere ve bunların kaynaklandığı web sitelerine saygı duyan en iyi uygulamalara bağlı kalmak önemlidir. Python'da web taramasına ilişkin bazı önemli noktalar ve en iyi uygulamalar şunlardır:
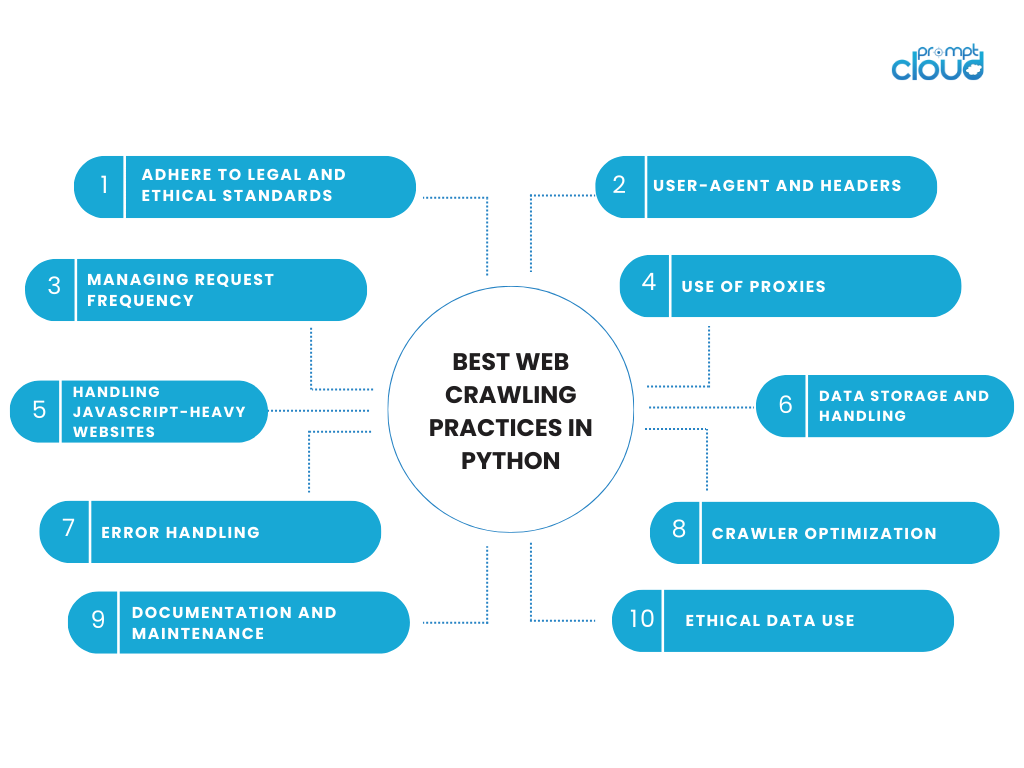
Yasal ve Etik Standartlara Uyun
- Robots.txt dosyasına saygı gösterin: Her zaman web sitesinin robots.txt dosyasını kontrol edin. Bu dosya, web sitesi sahibinin taranmamayı tercih ettiği site alanlarını özetlemektedir.
- Hizmet Şartlarını Takip Edin: Birçok web sitesi, hizmet şartlarında web kazımayla ilgili maddeler içerir. Bu şartlara uymak hem etik hem de yasal açıdan ihtiyatlıdır.
- Sunucuların Aşırı Yüklenmesinden Kaçının: Web sitesinin sunucusuna aşırı yük binmesini önlemek için istekleri makul bir hızda yapın.
Kullanıcı Aracısı ve Başlıklar
- Kendinizi Tanımlayın: İletişim bilgilerinizi veya taramanızın amacını içeren bir kullanıcı aracısı dizesi kullanın. Bu şeffaflık güven oluşturabilir.
- Başlıkları Uygun Şekilde Kullanın: İyi yapılandırılmış HTTP başlıkları, engellenme olasılığını azaltabilir. Kullanıcı aracısı, kabul dili vb. gibi bilgileri içerebilirler.
İstek Sıklığını Yönetme
- Gecikme Ekle: İnsanların göz atma kalıplarını taklit etmek için istekler arasına bir gecikme uygulayın. Python'un time.sleep() fonksiyonunu kullanın.
- Hız Sınırlaması: Belirli bir zaman dilimi içinde bir web sitesine kaç istek gönderdiğinize dikkat edin.
Proxy Kullanımı
- IP Rotasyonu: IP adresinizi döndürmek için proxy kullanmak, IP tabanlı engellemeyi önlemeye yardımcı olabilir, ancak bu, sorumlu ve etik bir şekilde yapılmalıdır.
JavaScript Yoğun Web Sitelerini Yönetme
- Dinamik İçerik: İçeriği JavaScript ile dinamik olarak yükleyen siteler için Selenium veya Puppeteer gibi araçlar (Python için Pyppeteer ile birlikte) sayfaları bir tarayıcı gibi oluşturabilir.
Veri Depolama ve İşleme
- Veri Depolama: Taranan verileri, veri gizliliği yasalarını ve düzenlemelerini dikkate alarak sorumlu bir şekilde saklayın.
- Veri Çıkarmayı En Aza İndirin: Yalnızca ihtiyacınız olan verileri çıkarın. Kesinlikle gerekli ve yasal olmadığı sürece kişisel veya hassas bilgileri toplamaktan kaçının.
Hata yönetimi
- Güçlü Hata İşleme: Zaman aşımları, sunucu hataları veya yüklenemeyen içerik gibi sorunları yönetmek için kapsamlı hata işleme uygulayın.
Tarayıcı Optimizasyonu
- Ölçeklenebilirlik: Tarayıcınızı, hem taranan sayfa sayısı hem de işlenen veri miktarı açısından ölçekteki artışı karşılayacak şekilde tasarlayın.
- Verimlilik: Kodunuzu verimlilik için optimize edin. Verimli kod, hem sisteminizdeki hem de hedef sunucunuzdaki yükü azaltır.
Dokümantasyon ve Bakım
- Belgeleri Saklayın: İleride başvurmak ve bakım yapmak üzere kodunuzu ve tarama mantığınızı belgeleyin.
- Düzenli Güncellemeler: Özellikle hedef web sitesinin yapısı değişirse tarama kodunuzu güncel tutun.
Etik Veri Kullanımı
- Etik Kullanım: Topladığınız verileri, kullanıcı gizliliğine ve veri kullanım normlarına saygı göstererek, etik bir şekilde kullanın.
Sonuç olarak
Python'da bir web tarayıcısı oluşturma araştırmamızı tamamlarken, otomatik veri toplamanın inceliklerini ve bununla birlikte gelen etik hususları inceledik. Bu çaba yalnızca teknik becerilerimizi geliştirmekle kalmıyor, aynı zamanda geniş dijital ortamda sorumlu veri işleme anlayışımızı da derinleştiriyor.
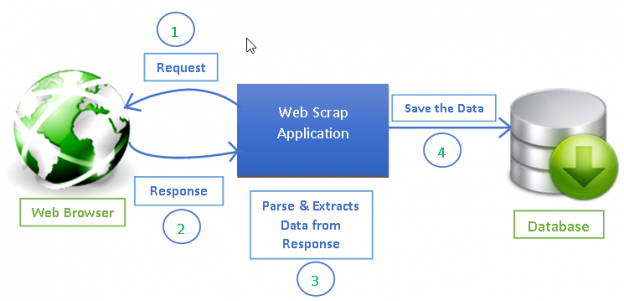
Kaynak: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Ancak bir web tarayıcısı oluşturmak ve sürdürmek, özellikle belirli, büyük ölçekli veri ihtiyaçları olan işletmeler için karmaşık ve zaman alıcı bir görev olabilir. PromptCloud'un özel web kazıma hizmetlerinin devreye girdiği yer burasıdır. Web veri gereksinimlerinize özel, verimli ve etik bir çözüm arıyorsanız PromptCloud, benzersiz ihtiyaçlarınıza uyacak bir dizi hizmet sunar. Karmaşık web sitelerini yönetmekten temiz, yapılandırılmış veriler sağlamaya kadar, web kazıma projelerinizin sorunsuz ve iş hedeflerinizle uyumlu olmasını sağlarlar.
Kendi web tarayıcılarını geliştirmek ve yönetmek için zamanı veya teknik uzmanlığı olmayan işletmeler ve kişiler için, bu görevi PromptCloud gibi uzmanlara dış kaynak olarak vermek oyunun kurallarını değiştirebilir. Hizmetleri yalnızca zamandan ve kaynaklardan tasarruf sağlamakla kalmaz, aynı zamanda yasal ve etik standartlara bağlı kalarak en doğru ve ilgili verileri almanızı sağlar.
PromptCloud'un özel veri ihtiyaçlarınızı nasıl karşılayabileceği hakkında daha fazla bilgi edinmek ister misiniz? Daha fazla bilgi almak ve özel web kazıma çözümlerinin işinizi ileriye taşımaya nasıl yardımcı olabileceğini tartışmak için sales@promptcloud.com adresinden onlara ulaşın.
Web verilerinin dinamik dünyasında, PromptCloud gibi güvenilir bir ortağa sahip olmak işinizi güçlendirebilir ve size veri odaklı karar alma konusunda avantaj sağlayabilir. Veri toplama ve analiz alanında doğru ortağın büyük fark yaratacağını unutmayın.
Mutlu veri avcılığı!