
Web Tarayıcısı Oluşturmak İçin Adım Adım Kılavuz
Yayınlanan: 2023-12-05Bilginin sayısız web sitesine dağıldığı internetin karmaşık dokusunda, web tarayıcıları bu veri zenginliğini düzenlemek, indekslemek ve erişilebilir kılmak için özenle çalışan isimsiz kahramanlar olarak ortaya çıkıyor. Bu makale, web tarayıcılarının incelenmesine girişmekte, temel çalışmalarına ışık tutmakta, web taraması ile web kazıma arasındaki ayrımı yapmakta ve basit bir Python tabanlı web tarayıcısı oluşturmaya yönelik adım adım kılavuz gibi pratik bilgiler sağlamaktadır. Daha derine indikçe Scrapy gibi gelişmiş araçların yeteneklerini ortaya çıkaracağız ve PromptCloud'un web taramasını endüstriyel ölçeğe nasıl yükselttiğini keşfedeceğiz.
Web Tarayıcısı Nedir?
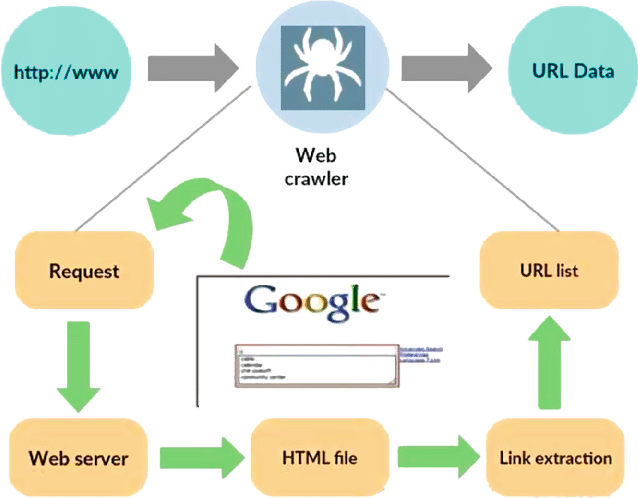
Kaynak: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Örümcek veya bot olarak da bilinen bir web tarayıcısı, World Wide Web'in geniş alanında sistematik ve özerk bir şekilde gezinmek için tasarlanmış özel bir programdır. Birincil işlevi, arama motoru optimizasyonu, içerik indeksleme veya veri çıkarma gibi çeşitli amaçlar için web sitelerinde gezinmek, veri toplamak ve bilgileri indekslemektir.
Bir web tarayıcısı özünde bir insan kullanıcının eylemlerini taklit eder, ancak bunu çok daha hızlı ve daha verimli bir hızda gerçekleştirir. Yolculuğuna, genellikle çekirdek URL olarak adlandırılan belirlenmiş bir başlangıç noktasından başlar ve ardından bir web sayfasından diğerine giden köprüleri takip eder. Bu bağlantıları takip etme süreci yinelemelidir ve tarayıcının internetin önemli bir bölümünü keşfetmesine olanak tanır.
Tarayıcı web sayfalarını ziyaret ederken metin, görseller, meta veriler ve daha fazlasını içerebilen ilgili verileri sistematik olarak çıkarır ve saklar. Çıkarılan veriler daha sonra düzenlenir ve dizine eklenir; bu, arama motorlarının sorgulandığında ilgili bilgileri kullanıcılara sunmasını ve sunmasını kolaylaştırır.
Web tarayıcıları Google, Bing ve Yahoo gibi arama motorlarının işlevselliğinde çok önemli bir rol oynar. Web'i sürekli ve sistematik bir şekilde tarayarak, arama motoru dizinlerinin güncel olmasını sağlayarak kullanıcılara doğru ve alakalı arama sonuçları sunarlar. Ek olarak web tarayıcıları, içerik toplama, web sitesi izleme ve veri madenciliği dahil olmak üzere diğer çeşitli uygulamalarda da kullanılır.
Bir web tarayıcısının etkinliği, çeşitli web sitesi yapılarında gezinme, dinamik içeriği yönetme ve sitenin hangi bölümlerinin taranabileceğini özetleyen robots.txt dosyası aracılığıyla web siteleri tarafından belirlenen kurallara uyma becerisine bağlıdır. Web tarayıcılarının nasıl çalıştığını anlamak, onların geniş bilgi ağını erişilebilir ve düzenli hale getirmedeki önemini anlamak açısından temel önemdedir.
Web Tarayıcıları Nasıl Çalışır?
Örümcekler veya botlar olarak da bilinen web tarayıcıları, web sitelerinden bilgi toplamak için World Wide Web'de sistematik bir şekilde gezinme süreci aracılığıyla çalışır. Aşağıda web tarayıcılarının nasıl çalıştığına dair bir genel bakış verilmiştir:
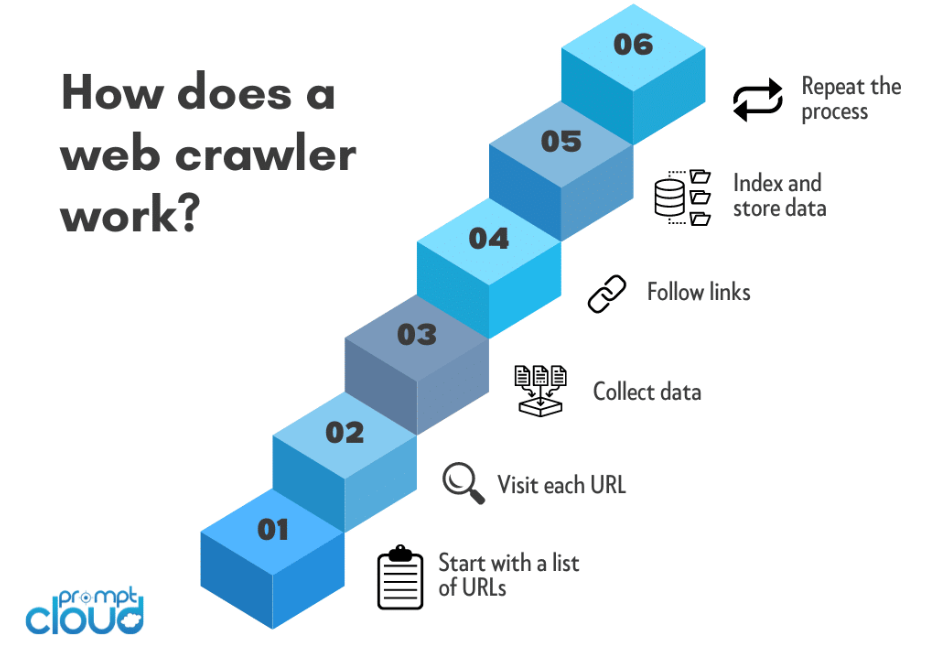
Tohum URL Seçimi:
Web tarama işlemi genellikle bir çekirdek URL ile başlar. Bu, tarayıcının yolculuğuna başladığı ilk web sayfası veya web sitesidir.
HTTP İsteği:
Tarayıcı, web sayfasının HTML içeriğini almak için çekirdek URL'ye bir HTTP isteği gönderir. Bu istek, web tarayıcılarının bir web sitesine erişirken yaptığı isteklere benzer.
HTML Ayrıştırma:
HTML içeriği getirildikten sonra tarayıcı, ilgili bilgileri çıkarmak için onu ayrıştırır. Bu, HTML kodunu tarayıcının gezinebileceği ve analiz edebileceği yapılandırılmış bir biçime ayırmayı içerir.
URL Çıkarma:
Tarayıcı, HTML içeriğinde bulunan köprüleri (URL'ler) tanımlar ve çıkarır. Bu URL'ler, tarayıcının daha sonra ziyaret edeceği diğer sayfalara olan bağlantıları temsil eder.
Kuyruk ve Zamanlayıcı:
Çıkarılan URL'ler bir kuyruğa veya zamanlayıcıya eklenir. Kuyruk, tarayıcının URL'leri belirli bir sırayla ziyaret etmesini ve genellikle yeni veya ziyaret edilmemiş URL'lere öncelik vermesini sağlar.
Özyineleme:
Tarayıcı, HTTP istekleri gönderme, HTML içeriğini ayrıştırma ve yeni URL'ler çıkarma işlemini tekrarlayarak kuyruktaki bağlantıları takip eder. Bu özyinelemeli süreç, tarayıcının birden çok web sayfası katmanında gezinmesine olanak tanır.
Veri Çıkarma:
Tarayıcı web'de dolaşırken ziyaret edilen her sayfadan ilgili verileri çıkarır. Çıkarılan veri türü tarayıcının amacına bağlıdır ve metin, resim, meta veri veya diğer belirli içerikleri içerebilir.
İçerik İndeksleme:
Toplanan veriler düzenlenir ve indekslenir. Dizin oluşturma, kullanıcılar sorgu gönderdiğinde bilgilerin aranmasını, alınmasını ve sunulmasını kolaylaştıran yapılandırılmış bir veritabanı oluşturmayı içerir.
Robots.txt dosyasına saygı:
Web tarayıcıları genellikle bir web sitesinin robots.txt dosyasında belirtilen kurallara uyar. Bu dosya, sitenin hangi alanlarının taranabileceği ve hangilerinin hariç tutulması gerektiği konusunda yönergeler sağlar.
Tarama Gecikmeleri ve Nezaket:
Sunucuların aşırı yüklenmesini ve kesintilere neden olmasını önlemek için tarayıcılar genellikle tarama gecikmeleri ve nezaket mekanizmaları içerir. Bu önlemler, tarayıcının web siteleriyle saygılı ve rahatsız edici olmayan bir şekilde etkileşimde bulunmasını sağlar.
Web tarayıcıları, bağlantıları takip ederek, verileri çıkararak ve düzenli bir dizin oluşturarak web'de sistematik olarak gezinir. Bu süreç, arama motorlarının kullanıcılara sorgularına dayalı olarak doğru ve alakalı sonuçlar sunmasına olanak tanıyarak web tarayıcılarını modern internet ekosisteminin temel bir bileşeni haline getirir.

Web Taraması ve Web Kazıma Karşılaştırması

Kaynak: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Web taraması ve web kazıma sıklıkla birbirinin yerine kullanılsa da, farklı amaçlara hizmet ederler. Web taraması, bilgileri indekslemek ve toplamak için web'de sistematik olarak gezinmeyi içerirken, web kazıma, web sayfalarından belirli verileri çıkarmaya odaklanır. Özünde, web taraması web'i keşfetmek ve haritalamakla ilgilidir, web kazıma ise hedeflenen bilgilerin toplanmasıyla ilgilidir.
Web Tarayıcısı Oluşturma
Python'da basit bir web tarayıcısı oluşturmak, geliştirme ortamını ayarlamaktan tarayıcı mantığını kodlamaya kadar birkaç adımı içerir. Aşağıda Python kullanarak, HTTP istekleri yapmak için istek kitaplığını ve HTML ayrıştırma için BeautifulSoup'u kullanan temel bir web tarayıcısı oluşturmanıza yardımcı olacak ayrıntılı bir kılavuz bulunmaktadır.
1. Adım: Ortamı Ayarlayın
Sisteminizde Python'un kurulu olduğundan emin olun. Python.org'dan indirebilirsiniz. Ayrıca gerekli kitaplıkları da yüklemeniz gerekir:
pip install requests beautifulsoup4
2. Adım: Kitaplıkları İçe Aktarın
Yeni bir Python dosyası oluşturun (örneğin, simple_crawler.py) ve gerekli kitaplıkları içe aktarın:
import requests from bs4 import BeautifulSoup
Adım 3: Tarayıcı İşlevini Tanımlayın
Giriş olarak URL'yi alan, HTTP isteği gönderen ve HTML içeriğinden ilgili bilgileri çıkaran bir işlev oluşturun:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
4. Adım: Tarayıcıyı Test Edin
Örnek bir URL sağlayın ve tarayıcıyı test etmek için simple_crawler işlevini çağırın:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Adım 5: Tarayıcıyı Çalıştırın
Python betiğini terminalinizde veya komut isteminizde yürütün:
python simple_crawler.py
Tarayıcı, sağlanan URL'nin HTML içeriğini getirecek, ayrıştıracak ve başlığı yazdıracaktır. Farklı türdeki verileri ayıklamak için daha fazla işlevsellik ekleyerek tarayıcıyı genişletebilirsiniz.
Scrapy ile Web Taraması
Scrapy ile web taraması, özellikle verimli ve ölçeklenebilir web kazıma için tasarlanmış güçlü ve esnek bir çerçevenin kapısını açar. Scrapy, web tarayıcıları oluşturmanın karmaşıklığını basitleştirerek web sitelerinde gezinebilen, veri çıkarabilen ve bunları sistematik bir şekilde depolayabilen örümcekler oluşturmak için yapılandırılmış bir ortam sunar. Scrapy ile web taramaya daha yakından bakalım:
Kurulum:
Başlamadan önce Scrapy'nin kurulu olduğundan emin olun. Aşağıdakileri kullanarak yükleyebilirsiniz:
pip install scrapy
Scrapy Projesi Oluşturma:
Bir Scrapy Projesi Başlatın:
Bir terminal açın ve Scrapy projenizi oluşturmak istediğiniz dizine gidin. Aşağıdaki komutu çalıştırın:
scrapy startproject your_project_name
Bu, gerekli dosyalar ile temel bir proje yapısı oluşturur.
Örümceği tanımlayın:
Proje dizininin içinde örümcekler klasörüne gidin ve örümceğiniz için bir Python dosyası oluşturun. scrapy.Spider'ı alt sınıflandırarak ve ad, izin verilen alanlar ve başlangıç URL'leri gibi temel ayrıntıları sağlayarak bir örümcek sınıfı tanımlayın.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Veri Çıkarma:
Seçicileri Kullanma:
Scrapy, HTML'den veri çıkarmak için güçlü seçiciler kullanır. Belirli öğeleri yakalamak için örümceğin ayrıştırma yönteminde seçicileri tanımlayabilirsiniz.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Bu örnekte <title> etiketinin metin içeriği çıkarılmaktadır.
Aşağıdaki Bağlantılar:
Scrapy, aşağıdaki bağlantıların sürecini basitleştirir. Diğer sayfalara gitmek için takip yöntemini kullanın.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Örümcek'i Çalıştırmak:
Örümcekinizi proje dizininden aşağıdaki komutu kullanarak yürütün:
scrapy crawl your_spider
Scrapy, örümceği başlatacak, bağlantıları takip edecek ve ayrıştırma yönteminde tanımlanan ayrıştırma mantığını yürütecektir.
Scrapy ile web taraması, karmaşık kazıma görevlerini yerine getirmek için sağlam ve genişletilebilir bir çerçeve sunar. Modüler mimarisi ve yerleşik özellikleri, onu karmaşık web veri çıkarma projeleriyle ilgilenen geliştiriciler için tercih edilen bir seçenek haline getiriyor.
Geniş Ölçekte Web Taraması
Büyük ölçekte web taraması, özellikle çok sayıda web sitesine yayılmış büyük miktarda veriyle uğraşırken benzersiz zorluklar sunar. PromptCloud, web tarama sürecini uygun ölçekte kolaylaştırmak ve optimize etmek için tasarlanmış özel bir platformdur. PromptCloud'un büyük ölçekli web tarama girişimlerini yönetmede nasıl yardımcı olabileceği aşağıda açıklanmıştır:
- Ölçeklenebilirlik
- Veri Çıkarma ve Zenginleştirme
- Veri Kalitesi ve Doğruluğu
- Altyapı Yönetimi
- Kullanım kolaylığı
- Uyum ve Etik
- Gerçek Zamanlı İzleme ve Raporlama
- Destek ve Bakım
PromptCloud, web taramasını geniş ölçekte gerçekleştirmek isteyen kuruluşlar ve bireyler için güçlü bir çözümdür. Platform, büyük ölçekli veri çıkarmayla ilgili temel zorlukları ele alarak web tarama girişimlerinin verimliliğini, güvenilirliğini ve yönetilebilirliğini artırır.
Özetle
Web tarayıcıları, geniş dijital ortamda isimsiz kahramanlar olarak duruyor ve bilgileri indekslemek, toplamak ve düzenlemek için web'de özenle geziniyor. Web tarama projelerinin ölçeği genişledikçe PromptCloud, büyük ölçekli girişimleri kolaylaştırmak için ölçeklenebilirlik, veri zenginleştirme ve etik uyumluluk sunan bir çözüm olarak devreye giriyor. [email protected] adresinden bizimle iletişime geçin