
R ve Python ile BigQuery'ye Veri Yükleme
Yayınlanan: 2023-06-06Web analitiği dünyası, Universal Analytics'in veri işlemeyi durdurduğu ve yerini Google Analytics 4'ün (GA4) aldığı, çok önemli olan 1 Temmuz tarihine doğru hızla ilerliyor. Önemli değişikliklerden biri, GA4'te platformdaki verileri yalnızca maksimum 14 ay tutabilmenizdir. Bu, UA'ya göre büyük bir değişikliktir, ancak bunun karşılığında GA4 verilerini bir sınıra kadar ücretsiz olarak BigQuery'ye aktarabilirsiniz.
BigQuery, GA4'ün ötesinde veri depolama için son derece yararlı bir kaynaktır. Birkaç ay içinde her zamankinden daha önemli hale geldiğinden, onu tüm veri depolama ihtiyaçlarınız için kullanmaya başlamanın tam zamanı. Çoğu zaman, verileri yüklemeden önce bir şekilde değiştirmek tercih edilir. Bunun için, özellikle bu tür bir manipülasyonun tekrar tekrar yapılması gerekiyorsa, R veya Python ile yazılmış bir komut dosyası kullanmanızı öneririz. Ayrıca doğrudan bu komut dizilerinden BigQuery'ye veri yükleyebilirsiniz ve bu blog size tam olarak bu konuda rehberlik edecektir.
R'den BigQuery'ye yükleme
R, veri bilimi için son derece güçlü bir dildir ve BigQuery'ye veri yüklemek için üzerinde çalışılması en kolay dildir. İlk adım, gerekli tüm kitaplıkları içe aktarmaktır. Bu eğitim için aşağıdaki kütüphanelere ihtiyacımız olacak:
library(googleAuthR)
library(bigQueryR)
Bu kitaplıkları daha önce kullanmadıysanız, yüklemek için konsolda install.packages(<PACKAGE NAME>) çalıştırın.
Ardından, API'lerle çalışmanın genellikle en zor ve sürekli olarak en sinir bozucu kısmı olan yetkilendirmeyi ele almalıyız. Neyse ki, R ile bu nispeten basittir. Yetkilendirme kimlik bilgilerini içeren bir JSON dosyasına ihtiyacınız olacak. Bu, BigQuery'nin bulunduğu yer olan Google Cloud Console'da bulunabilir. Öncelikle, Google Bulut Konsoluna gidin ve "API'ler ve Hizmetler"i tıklayın.
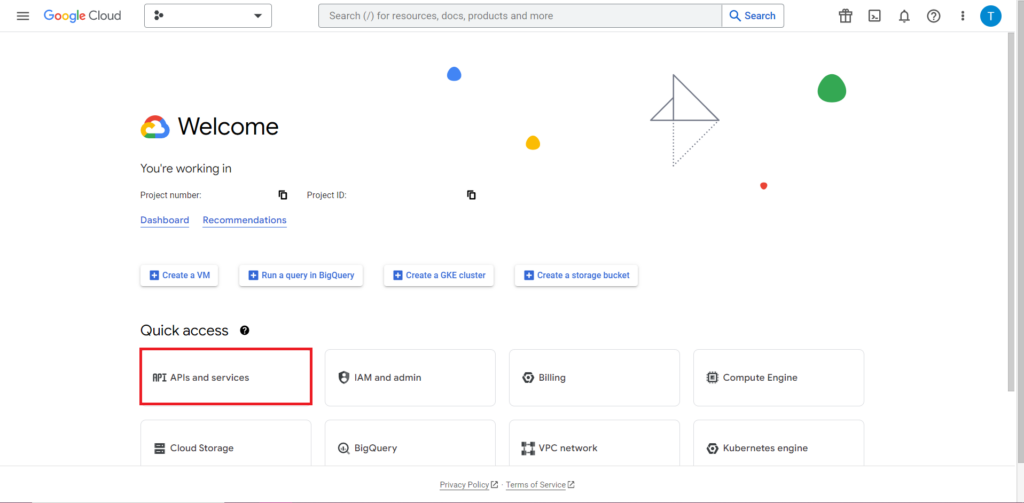
Ardından, kenar çubuğundaki 'Kimlik Bilgileri'ni tıklayın.
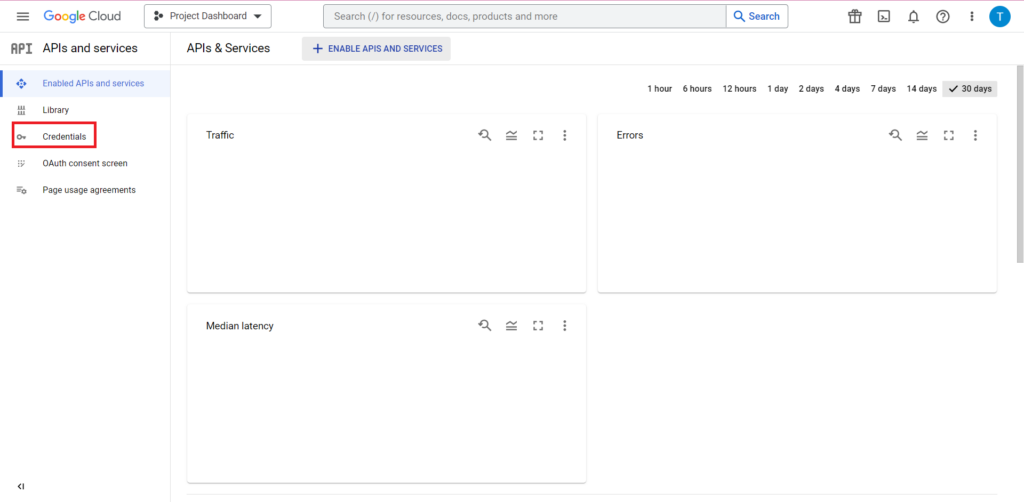
Kimlik Bilgileri sayfasında mevcut API anahtarlarınızı, OAuth 2.0 İstemci Kimliklerinizi ve Hizmet Hesaplarınızı görüntüleyebilirsiniz. Bunun için bir OAuth 2.0 İstemci Kimliği isteyeceksiniz, bu nedenle kimliğiniz için ilgili satırın en sonundaki indirme düğmesine basın veya sayfanın üst kısmındaki 'Kimlik Bilgileri Oluştur' seçeneğine tıklayarak yeni bir kimlik oluşturun. Kimliğinizin ilgili BigQuery projesini görüntüleme ve düzenleme iznine sahip olduğundan emin olun - bunu yapmak için kenar çubuğunu açın, "IAM ve Yönetici"nin üzerine gelin ve "IAM"yi tıklayın. Bu sayfada, sayfanın üst kısmında yer alan 'Grant Access' butonunu kullanarak hizmet hesabınıza ilgili projeye erişim izni verebilirsiniz.
Elde edilen ve kaydedilen JSON dosyası ile, kimlik bilgilerinizi ayarlamak için gar_set_client() işlevi ile ona giden yolu iletebilirsiniz. Yetkilendirme için tam kod aşağıdadır:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Açıkçası, gar_set_client() işlevindeki yolu kendi JSON dosyanızın yolu ile değiştirmek ve BigQuery'ye erişmek için kullandığınız e-posta adresini bqr_auth() işlevine eklemek isteyeceksiniz.
Yetkilendirme ayarlandıktan sonra, BigQuery'ye yüklemek için bazı verilere ihtiyacımız var. Bu verileri bir veri çerçevesine koymamız gerekecek. Bu makalenin amaçları doğrultusunda, birkaç konum ve satış sayısıyla birlikte bazı kurgusal veriler oluşturacağım, ancak büyük olasılıkla bir .csv dosyasından veya elektronik tablodan gerçek verileri okuyacaksınız. Bir .csv dosyasından veri okumak için, dosyanın yolunu argüman olarak ileterek read.csv() işlevini kullanabilirsiniz:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternatif olarak, verileriniz bir elektronik tabloda saklanıyorsa, yönteminiz bu elektronik tablonun bulunduğu yere göre değişir. E-tablonuz Google E-Tablolar'da depolanıyorsa, verilerini googlesheets4 kitaplığını kullanarak R'ye okuyabilirsiniz:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Daha önce olduğu gibi, bu paketi daha önce kullanmadıysanız, kodunuzu çalıştırmadan önce konsolda install.packages(“googlesheets4”) çalıştırmanız gerekir.
E-tablonuz Excel'deyse, benim kullanmanızı tavsiye ettiğim,drideverse kitaplığının bir parçası olan readxl kitaplığını kullanmanız gerekir. R'de veri işlemeyi çok daha kolay hale getiren çok sayıda işlev içerir:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
Ve bir kez daha, daha önce çalıştırmadıysanız install.package(“tidyverse”) programını çalıştırdığınızdan emin olun!
Son adım, verileri BigQuery'ye yüklemektir. Bunu yüklemek için BigQuery'de bir yere ihtiyacınız olacak. Tablonuz, bir proje içinde yer alacak bir veri kümesi içinde yer alacaktır ve bunların üçünün de adlarına aşağıdaki biçimde ihtiyacınız olacaktır:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
Benim durumumda bu, kodumun okuduğu anlamına gelir:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Tablonuz henüz yoksa merak etmeyin, kod sizin için tabloyu oluşturacaktır. Projenizin, veri kümenizin ve tablonuzun adlarını yukarıdaki koda (tırnak işaretleri içinde) eklemeyi unutmayın ve doğru veri çerçevesini yüklediğinizden emin olun! Bu yapıldıktan sonra, verilerinizi BigQuery'de aşağıdaki gibi görmelisiniz:

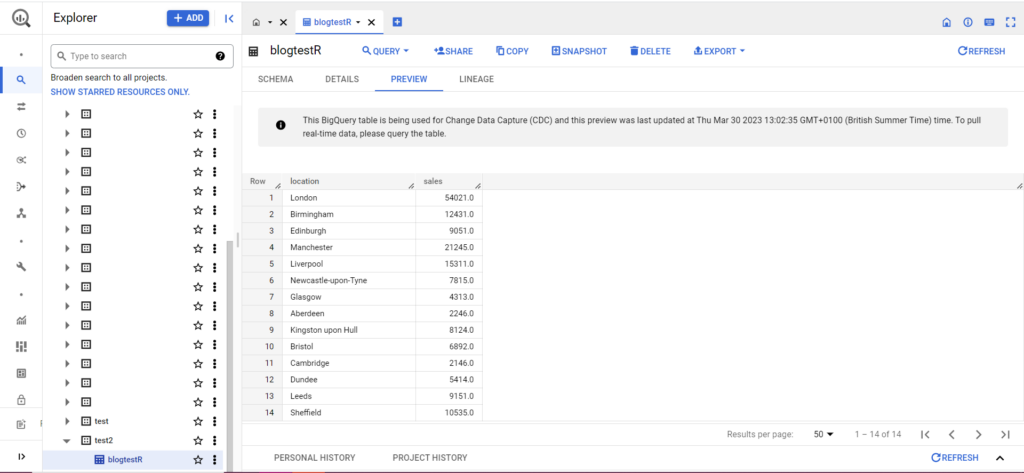
Son adım olarak, BigQuery'ye eklemek istediğiniz ek verileriniz olduğunu varsayalım. Örneğin, yukarıdaki verilerimde, kıtadan birkaç konumu eklemeyi unuttuğumu ve BigQuery'ye yüklemek istediğimi ancak mevcut verilerin üzerine yazmak istemediğimi varsayalım. Bunun için bqr_upload_data, writeDisposition adlı bir parametreye sahiptir. writeDisposition'ın "WRITE_TRUNCATE" ve "WRITE_APPEND" olmak üzere iki ayarı vardır. Birincisi bqr_upload_data()'ya tablodaki mevcut verilerin üzerine yazmasını söylerken, ikincisi ona yeni verileri eklemesini söyler. Böylece, bu yeni verileri yüklemek için şunu yazacağım:
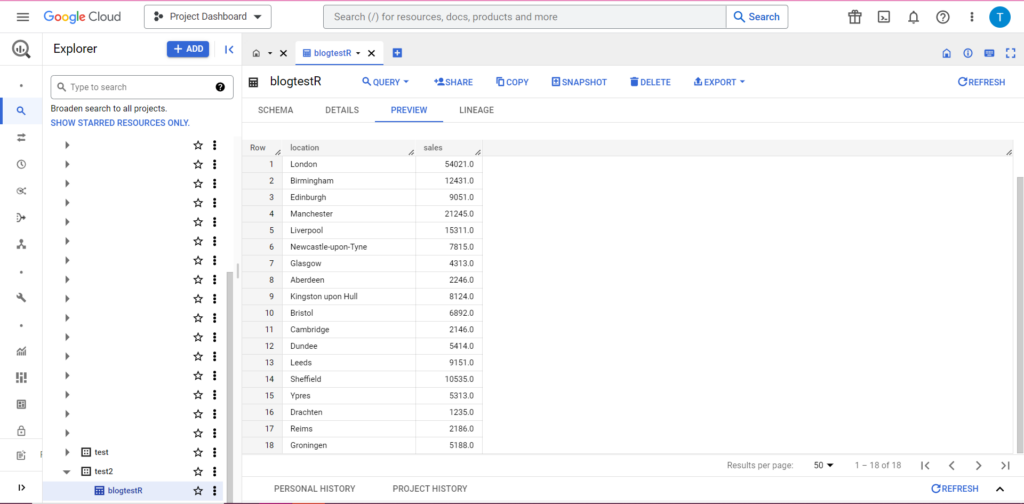
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
Ve elbette, BigQuery'de verilerimizin bazı yeni oda arkadaşları olduğunu görebiliriz:
Python'dan BigQuery'ye yükleme
Python'da işler biraz farklı. Bir kez daha, bazı paketleri içe aktarmamız gerekecek, o yüzden bunlarla başlayalım:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
Yetkilendirme karmaşıktır. Bir kez daha kimlik bilgilerini içeren bir JSON dosyasına ihtiyacımız olacak. Yukarıdaki gibi, Google Bulut Konsoluna gidip 'API'ler ve Hizmetler'i ve ardından kenar çubuğundaki 'Kimlik Bilgileri'ni tıklayacağız. Bu sefer sayfanın en altında 'Hizmet Hesapları' diye bir bölüm olacak.
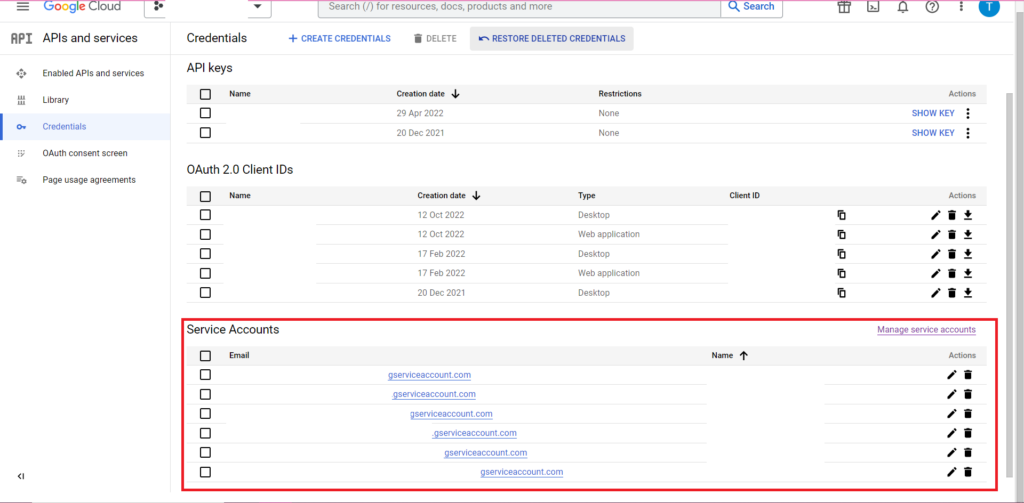
Burada, hizmet hesabınızın anahtarını indirebilir veya 'Hizmet Hesabını Yönet' seçeneğine tıklayarak kimlik bilgilerini indirebileceğiniz yeni bir anahtar veya yeni bir hizmet hesabı oluşturabilirsiniz.
Ardından, hizmet hesabınızın BigQuery projenize erişme ve bunları düzenleme iznine sahip olduğundan emin olmak isteyeceksiniz. Bir kez daha kenar çubuğundaki 'IAM & Admin' altındaki IAM sayfasına gidin ve orada sayfanın üst kısmındaki 'Grant Access' düğmesini kullanarak hizmet hesabınıza ilgili projeye erişim izni verebilirsiniz.
Bunu halleder çözmez, yetkilendirme kodunu yazabilirsiniz:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Ardından, verilerinizi bir veri çerçevesine almanız gerekecek. Veri çerçeveleri pandas paketine aittir ve oluşturulması çok kolaydır. Bir CSV'den okumak için şu örneği izleyin:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Açıkçası, yukarıdaki yolu kendi CSV dosyanızla değiştirmeniz gerekecek. Bir Excel dosyasından okumak için şu örneği izleyin:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Google E-Tablolardan okumak zordur ve başka bir yetkilendirme aşaması gerektirir. Bazı yeni paketleri içe aktarmamız ve yukarıdaki R öğreticisi sırasında aldığımız JSON kimlik bilgileri dosyasını kullanmamız gerekecek. Verilerinizi yetkilendirmek ve okumak için bu kodu takip edebilirsiniz:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Verilerinizi veri çerçevenize aldıktan sonra, bir kez daha BigQuery'ye yükleme zamanı! Bunu, bu şablonu izleyerek yapabilirsiniz:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Örnek olarak, daha önce yaptığım verileri yüklemek için az önce yazdığım kod:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Bu yapıldıktan sonra, veriler BigQuery'de hemen görünmelidir!
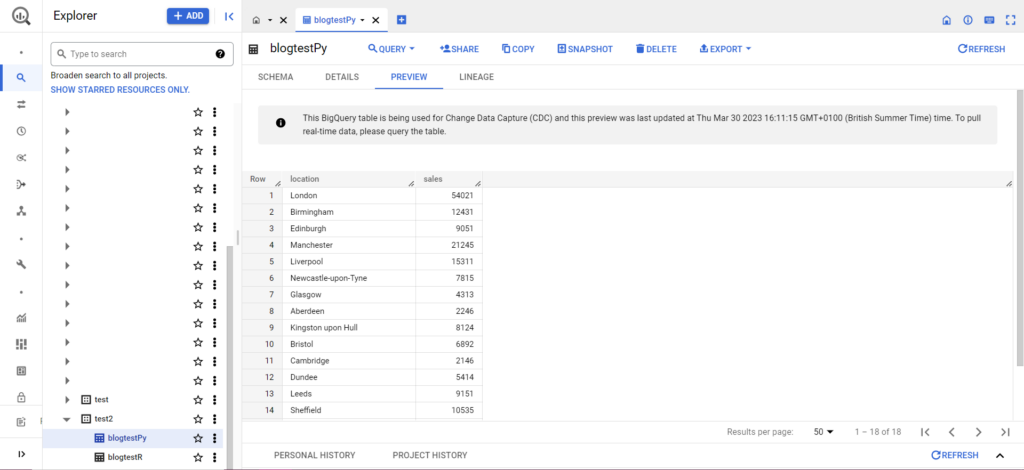
Bir kez alıştıktan sonra bu işlevlerle yapabileceğiniz daha çok şey var. Analitik kurulumunuz üzerinde daha fazla kontrol sahibi olmak istiyorsanız, Semetrical yardıma hazır! Verilerinizden en iyi şekilde nasıl yararlanabileceğiniz hakkında daha fazla bilgi için blogumuza göz atın. Ya da her şey analitiği hakkında daha fazla destek için Web Analytics'e giderek size nasıl yardımcı olabileceğimizi öğrenin.